
Program
AI Temelleri
10 sa
Tescilli LLM’ler yerine açık kaynak LLM’leri seçmenin kısa ve uzun vadeli pek çok faydası vardır. Aşağıda, en güçlü gerekçelerin bir listesini bulabilirsiniz:
Tescilli LLM’leri kullanmanın en büyük endişelerinden biri, LLM sağlayıcısı tarafından veri sızıntısı ya da hassas verilere yetkisiz erişim riskidir. Nitekim, eğitim amaçları için kişisel ve gizli verilerin kullanıldığı iddialarına ilişkin pek çok tartışma yaşandı.
Açık kaynak LLM kullanıldığında, şirketler kişisel verilerin korunmasından tamamen kendileri sorumlu olur, çünkü veriler üzerinde tam denetimi ellerinde tutarlar.
Çoğu tescilli LLM’i kullanmak için lisans gerekir. Uzun vadede bu, özellikle KOBİ’lerin karşılayamayacağı önemli bir gider olabilir. Açık kaynak LLM’lerde ise durum genellikle böyle değildir; bunlar normalde ücretsiz kullanılabilir.
Bununla birlikte, LLM’leri çalıştırmanın, yalnızca çıkarım için bile, ciddi kaynaklar gerektirdiğini unutmamak önemlidir; bu da genellikle bulut hizmetlerini veya güçlü bir altyapıyı kullanmak için ödeme yapmanız gerekeceği anlamına gelir.
Açık kaynak LLM’leri tercih eden şirketler, kaynak kod, mimari, eğitim verileri ve eğitim ile çıkarım mekanizmaları dahil LLM’lerin işleyişine erişim sağlar. Bu şeffaflık, denetim için ilk adımdır; aynı zamanda özelleştirmenin de önünü açar.
Açık kaynak LLM’ler herkesin erişimine açık olduğundan, kaynak kodlarıyla birlikte, onları kullanan şirketler kendi özel kullanım senaryoları için özelleştirme yapabilir.
Açık kaynak hareketi, LLM ve üretken yapay zekâ teknolojilerinin kullanımını ve erişimini demokratikleştirmeyi vaat eder. Geliştiricilerin LLM’lerin iç işleyişini incelemesine izin vermek, bu teknolojinin gelecekteki gelişimi için kilit önemdedir. Dünyanın dört bir yanındaki yazılımcılar için giriş engellerini düşürerek, açık kaynak LLM’ler önyargıları azaltıp doğruluk ve genel performansı artırarak yeniliği teşvik edebilir ve modelleri iyileştirebilir.
LLM’lerin yaygınlaşmasının ardından, araştırmacılar ve çevre kuruluşları bu teknolojileri çalıştırmak için gereken karbon ayak izi ve su tüketimi konusunda endişelerini dile getiriyor. Tescilli LLM’ler, LLM’leri eğitmek ve işletmek için gereken kaynaklar ve bunların çevresel etkisi hakkında nadiren bilgi yayımlar.
Açık kaynak LLM’lerle, araştırmacıların bu bilgilere erişme şansı daha yüksektir; bu da yapay zekânın çevresel ayak izini azaltmaya yönelik yeni iyileştirmelerin önünü açabilir.
GLM-4.6, GLM-4.5’in halefi olan yeni nesil bir büyük dil modelidir. Ajans odaklı iş akışlarını geliştirmek, sağlam kodlama desteği sunmak, gelişmiş akıl yürütmeyi kolaylaştırmak ve yüksek kaliteli doğal dil üretmek üzere tasarlanmıştır. Model, hem araştırma hem de üretim ortamlarını hedefler; daha uzun bağlamı anlama, araç destekli çıkarım ve kullanıcı tercihleriyle daha doğal hizalanan yazım üzerine odaklanır.
Kaynak:zai-org/GLM-4.6
GLM-4.5 ile karşılaştırıldığında GLM-4.6, birkaç önemli iyileştirme sunar: Bağlam penceresi 128K’dan 200K tokene genişletilmiştir; bu da daha karmaşık ajans görevlerine olanak tanır. Kodlama performansı da artırılmış, daha yüksek kıyaslama puanları ve gerçek dünya uygulamalarında daha güçlü sonuçlar elde edilmiştir.
GLM-4.6, ajanlar, akıl yürütme ve kodlamayla ilgili sekiz halka açık kıyaslamada net kazanımlar göstererek GLM-4.5’i geride bırakıyor ve DeepSeek-V3.1-Terminus ile Claude Sonnet 4 gibi önde gelen modellere karşı rekabet avantajı sergiliyor.
gpt-oss-120b, OpenAI’nin gelişmiş akıl yürütme, ajans görevleri ve çok yönlü geliştirici iş akışları için tasarlanmış açık ağırlıklı modelleri olan gpt-oss serisinin zirvesidir. Bu seri iki sürüm içerir: Üretim düzeyinde, yüksek düzeyde akıl yürütme gerektiren genel amaçlı kullanım durumları için tasarlanan ve tek bir 80GB GPU’da çalışabilen (117 milyar parametre, 5,1 milyar etkin) gpt-oss-120b; ve daha düşük gecikme ile yerel veya uzmanlaşmış dağıtımlar için optimize edilen (21 milyar parametre ve 3,6 milyar etkin) gpt-oss-20b. Her iki model de harmony yanıt formatıyla eğitilmiştir ve etkili çalışmaları için harmony çerçevesiyle beraber kullanılmalıdır.
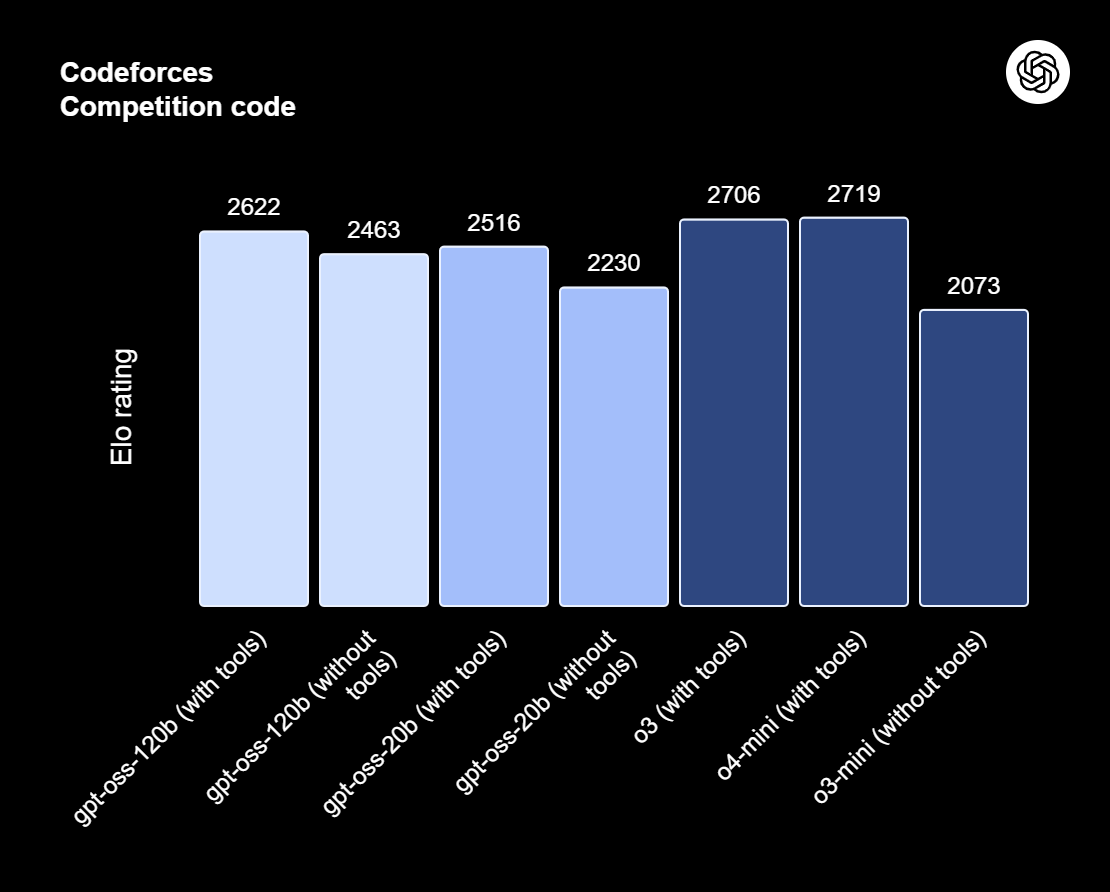
Kaynak: gpt-oss tanıtımı | OpenAI
gpt-oss-120b, derinlik ve gecikme arasında denge kurmak için düşük, orta veya yüksek yapılandırılabilir akıl yürütme çabaları sunar. Hata ayıklama ve denetim amaçları için tam düşünce zinciri erişimi sağlar. Bu modeller ince ayara uygundur ve fonksiyon çağrısı, web’de gezinme, Python kodu çalıştırma ve yapısal çıktılar gibi yerleşik ajans yetenekleriyle birlikte gelir.
MoE ağırlıklarının MXFP4 nicelemesi sayesinde gpt-oss-120b tek bir 80GB GPU’da çalışabilirken gpt-oss-20b 16GB’lık bir ortamda çalışabilir. GPT-OSS 120B’ye ücretsiz erişmenin 10 yolunu anlattığımız makalemizi okuyun.
Qwen3-235B-A22B-Instruct-2507, Qwen3-MoE ailesinin amiral gemisi düşünmeyen (non-thinking) modelidir; yüksek hassasiyetli yönerge izleme, sıkı mantıksal muhakeme, çok dilli metin anlama, matematik, bilim, kodlama, araç kullanımı ve çok uzun bağlam gerektiren görevler için tasarlanmıştır. Toplam 235 milyar parametreye ve 22 milyar etkin parametreye sahip (128 uzmandan 8’i aynı anda etkin) bir uzman karışımı (MoE) nedensel dil modelidir. Model 94 katmandan oluşur, 64 sorgu başlığı ve 4 anahtar-değer başlığı içeren bir GQA mekanizmasına sahiptir ve 262.000 tokenlık yerel bağlam penceresi yaklaşık 1,01 milyon tokena kadar genişletilebilir.
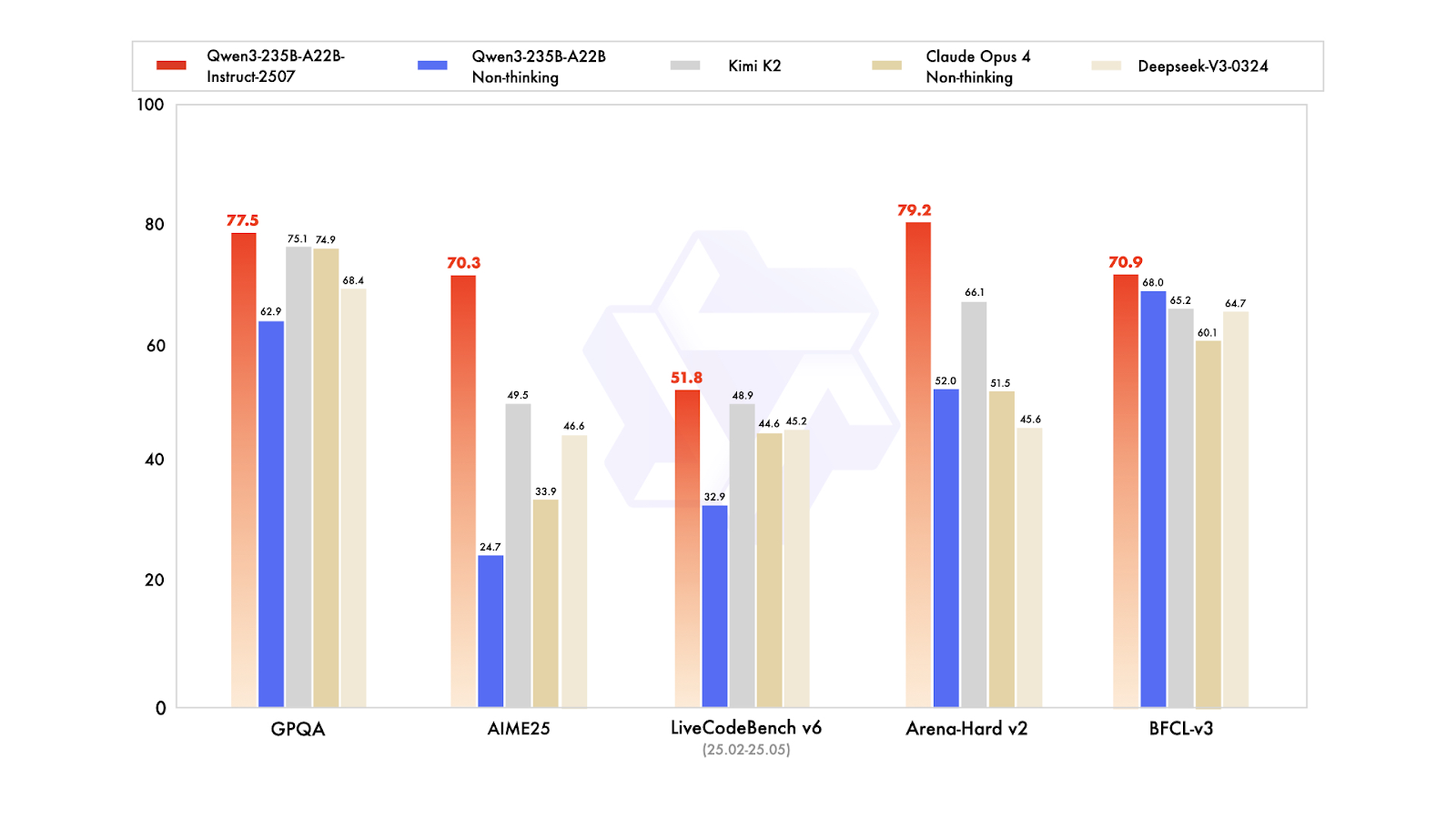
En son Instruct-2507 güncellemesi, genel yeteneklerde önemli iyileştirmeler getirir ve birden fazla dilde uzun kuyruk bilgi kapsamını genişletir. Ayrıca, açık uçlu görevlerde belirgin şekilde daha iyi tercih hizalaması sunar ve özellikle 256.000+ uzun bağlam anlayışında yazım kalitesini artırır.
Kamuya açık kıyaslamalarda olağanüstü sonuçlar sergiler. Pratikte bu, Instruct-2507’yi üst düzey bir düşünmeyen model konumuna getirir; önceki Qwen3-235B-A22B düşünmeyen varyantını ve DeepSeek-V3, GPT-4o, Claude Opus 4 (düşünmeyen) ve Kimi K2 gibi önde gelen rakipleri geride bırakır.
Qwen3 hakkında daha fazla bilgiyi tam makalemizde bulabilirsiniz.
DeepSeek-V3.2-Exp, DeepSeek mimarisinin bir sonraki nesline giden yolda deneysel, ara bir sürümdür. V3.1-Terminus üzerine inşa edilir ve özellikle uzun bağlam senaryolarında eğitim ve çıkarım verimliliğini artırmak için DeepSeek Seyrek Dikkat’i tanıtır. Bu model, Terminus soyundan beklenen çıktı kalitesini korurken uzun diziler için transformer verimliliğini iyileştirmeyi amaçlar.
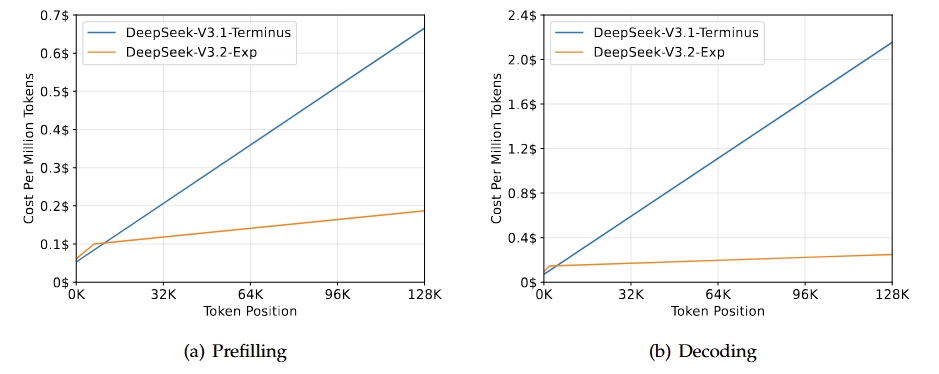
Kaynak: DeepSeek-V3.2-Exp
Bu sürümün başlıca sonucu, uzun bağlam görevleri için önemli verimlilik artışları sağlarken V3.1-Terminus’un genel yeteneklerini yakalamasıdır. Değerlendirmeler ve üçüncü taraf analizleri, performansının Terminus’a denk olduğunu, hesaplama maliyetlerinde belirgin bir azalma bulunduğunu gösteriyor. Bu da, seyrek dikkatin kaliteyi feda etmeden verimliliği artırabildiğini doğrular.
Bir demo projeyi adım adım görmek için DeepSeek-V3.2-Exp için tam rehberimizi okuyun.
DeepSeek-R1, küçük bir sürüm yükseltmesi alarak DeepSeek-R1-0528 sürümüne yükseltildi; bu yükseltme, eğitim sonrası artırılmış hesaplama gücü ve algoritmik optimizasyonlarla muhakeme ve çıkarım yeteneklerini geliştirir. Sonuç olarak, matematik, programlama ve genel mantık dahil çeşitli alanlarda önemli iyileşmeler görülmüştür. Genel performans artık O3 ve Gemini 2.5 Pro gibi önde gelen sistemlere daha yakındır.
Ham yeteneklerin ötesinde, bu güncelleme, daha güvenilir ve üretkenlik odaklı çıktılar üretmeye odaklandığını yansıtarak daha iyi fonksiyon çağrısı ve kodlama iş akışlarıyla pratik faydayı vurgular.
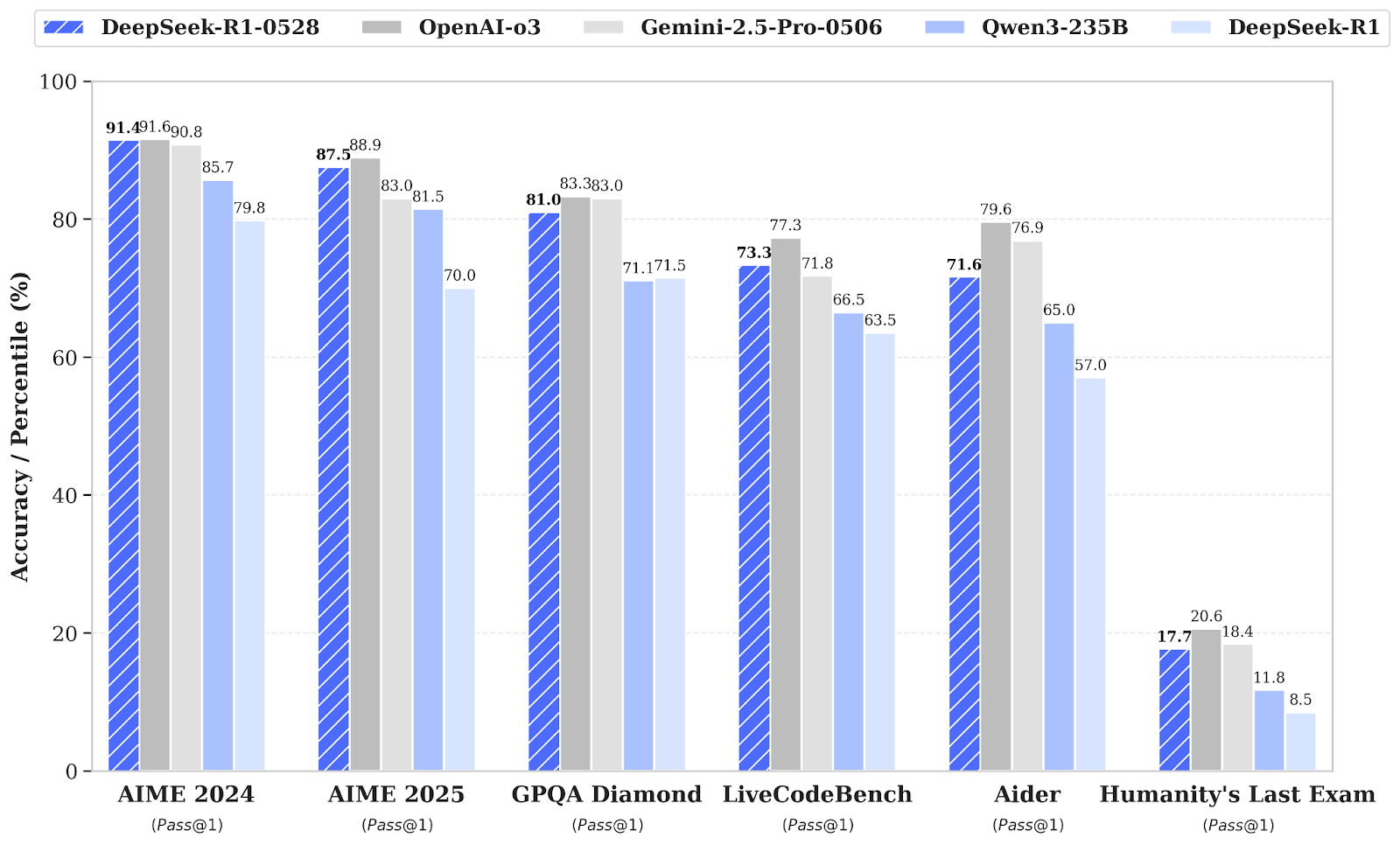
Kaynak: deepseek-ai/DeepSeek-R1-0528
Önceki DeepSeek R1 sürümüyle karşılaştırıldığında, yükseltilen model karmaşık muhakemede kayda değer ilerleme gösteriyor. Örneğin AIME 2025 sınavında doğruluk %70’ten %87,5’e çıktı; bu artış daha derin analitik düşünmeyle desteklendi (soru başına ortalama token sayısı yaklaşık 12.000’den 23.000’e yükseldi).
Daha geniş değerlendirmeler de bilgi, muhakeme ve kodlama performansı gibi alanlarda olumlu eğilimleri gösteriyor. LiveCodeBench, Codeforces dereceleri, SWE Verified ve Aider-Polyglot’taki iyileşmeler örnek teşkil eder; bunlar daha derin problem çözme ve üstün gerçek dünya kodlama yeteneklerine işaret eder.
Apriel-1.5-15b-Thinker, ServiceNow’un Apriel SLM serisindeki çoklu ortamlı muhakeme modelidir. Yalnızca 15 milyar parametreyle rekabetçi performans sunar ve tek GPU bütçesiyle sınır düzeyi sonuçları hedefler. Bu model, önceki yalnızca metin modeline görsel muhakeme yetenekleri eklemekle kalmaz; aynı zamanda metinsel muhakeme yeteneklerini de derinleştirir.
Muhakeme serisinin ikinci modeli olarak, metin ve görsel alanlarda kapsamlı sürekli ön eğitimden geçmiştir. Eğitim sonrası aşama, görsel odaklı herhangi bir SFT veya pekiştirmeli öğrenme olmaksızın yalnızca metin tabanlı denetimli ince ayarı (SFT) içerir. Bu sınırlamalara rağmen, model boyutu için metin ve görsel muhakemede son teknoloji kalitesini hedefler.
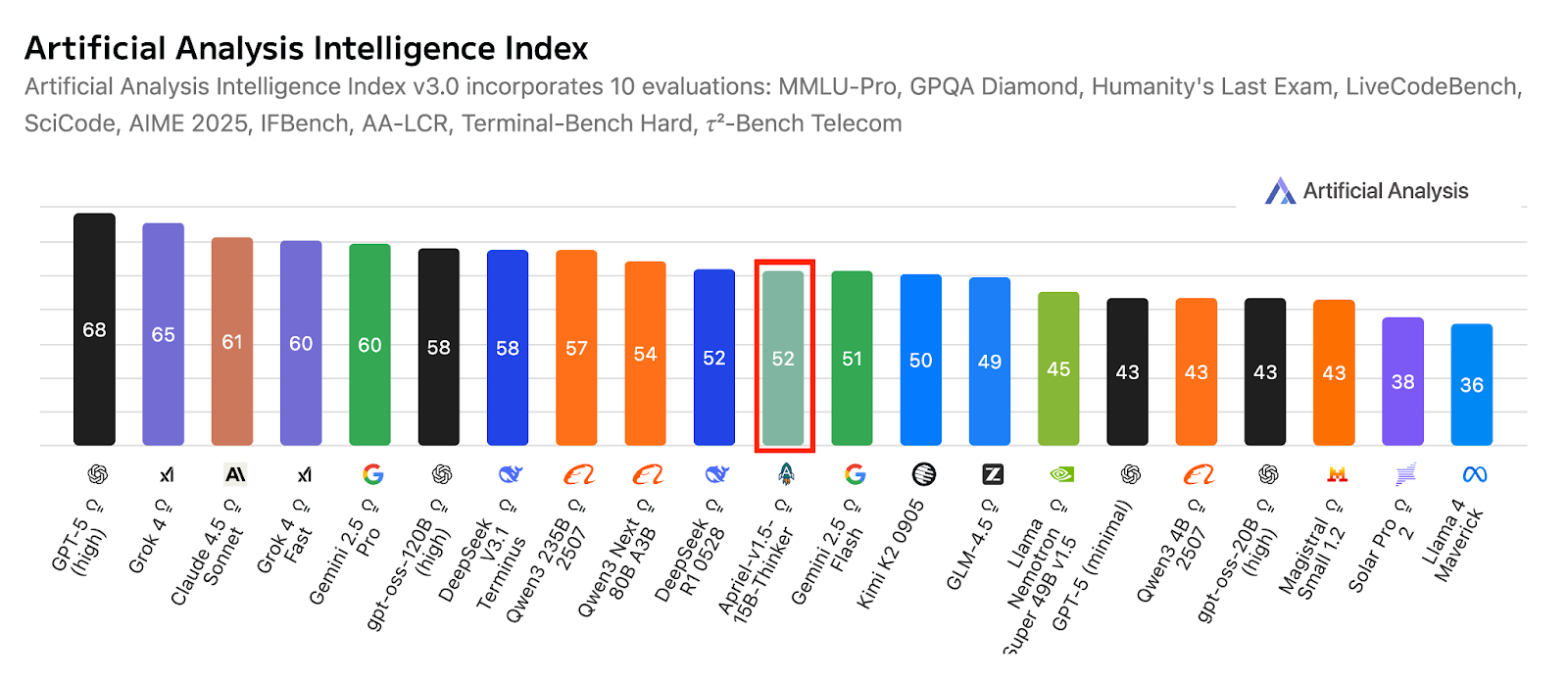
Kaynak: ServiceNow-AI/Apriel-1.5-15b-Thinker
Tek bir GPU’da çalışacak şekilde tasarlanan model, pratik dağıtımı ve verimliliği önceliklendirir. Değerlendirme sonuçları, Yapay Analiz endeksinde 52 puanla güçlü bir gerçek dünya hazırlığını göstermekte ve modeli çok daha büyük sistemlere karşı rekabetçi konumlandırmaktadır. Bu puan, önde gelen kompakt ve sınır düzeyi akranlarına kıyasla kapsamını da yansıtır; tüm bunlar, kurumsal kullanım için küçük model ayak izini korurken elde edilir.
Kimi-K2-Instruct-0905, Kimi K2 serisindeki en yeni ve en gelişmiş modeldir. Toplam 1 trilyon parametre ve 32 milyar etkin parametreye sahip, son teknoloji bir Uzman Karışımı (MoE) dil modelidir. Bu model, özellikle üst düzey muhakeme ve kodlama iş akışları için tasarlanmıştır.
K2-Instruct-0905, önceki 128.000 tokendan 256.000 tokena çıkarılan bağlam penceresiyle K2’nin uzun vadeli görevleri ele alma becerisini önemli ölçüde artırır. Araç destekli sohbet ve kod yardımı gibi güçlü ajans tabanlı kullanım durumlarını desteklemeyi amaçlar. K2 Instruct serisinin amiral gemisi sürümü olarak, geliştirici ergonomisine ve üretim kalitesinde uygulamalar için güvenilirliğe odaklanır.
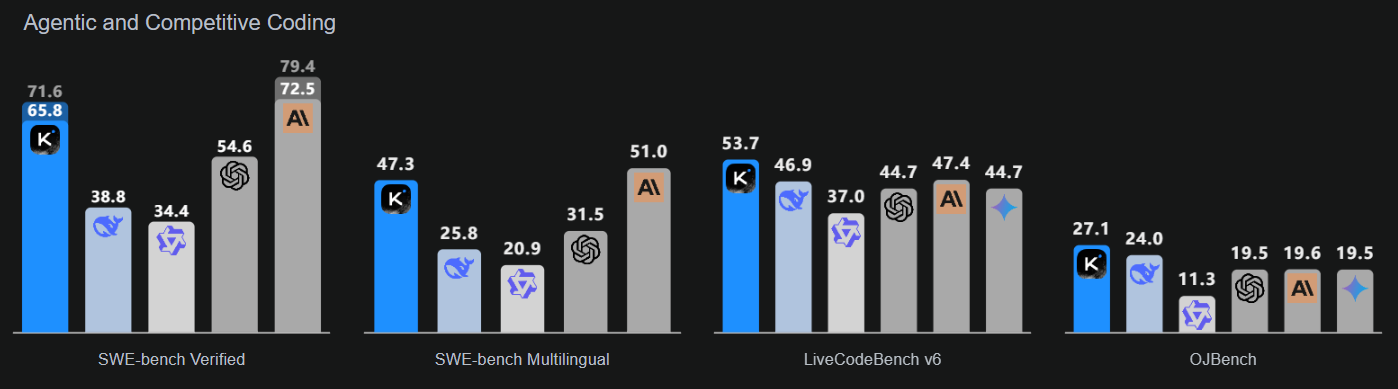
Kaynak: Kimi K2: Açık Ajans Zekâsı
Bu model üç kilit alana vurgu yapar: Ajans tabanlı görevler için geliştirilmiş kodlama zekâsı (kamu kıyaslamalarında ve gerçek dünyada net iyileşmeler gösterir); hem estetiği hem işlevselliği artıran geliştirilmiş kullanıcı arayüzü; ve daha kapsamlı planlama ve düzenleme döngülerine izin veren 256.000 tokenlık genişletilmiş bağlam uzunluğu.
Llama-3_3-Nemotron-Super-49B-v1_5, NVIDIA’nın Nemotron serisinde, Meta’nın Llama-3.3-70B-Instruct modelinden türetilmiş, yükseltilmiş 49 milyar parametreli bir modeldir. İnsana hizalı sohbet ve RAG (geri getirme destekli üretim) ile araç çağrımı gibi ajans görevleri için özel olarak tasarlanmış bir muhakeme modelidir.
Bu model, muhakeme yeteneklerini, tercih hizalamasını ve araç kullanımını güçlendirmek için eğitim sonrası aşamalardan geçmiştir. Ayrıca 128.000 tokene kadar uzun bağlamlı iş akışlarını destekler; bu da onu karmaşık, çok adımlı uygulamalar için uygun kılar.
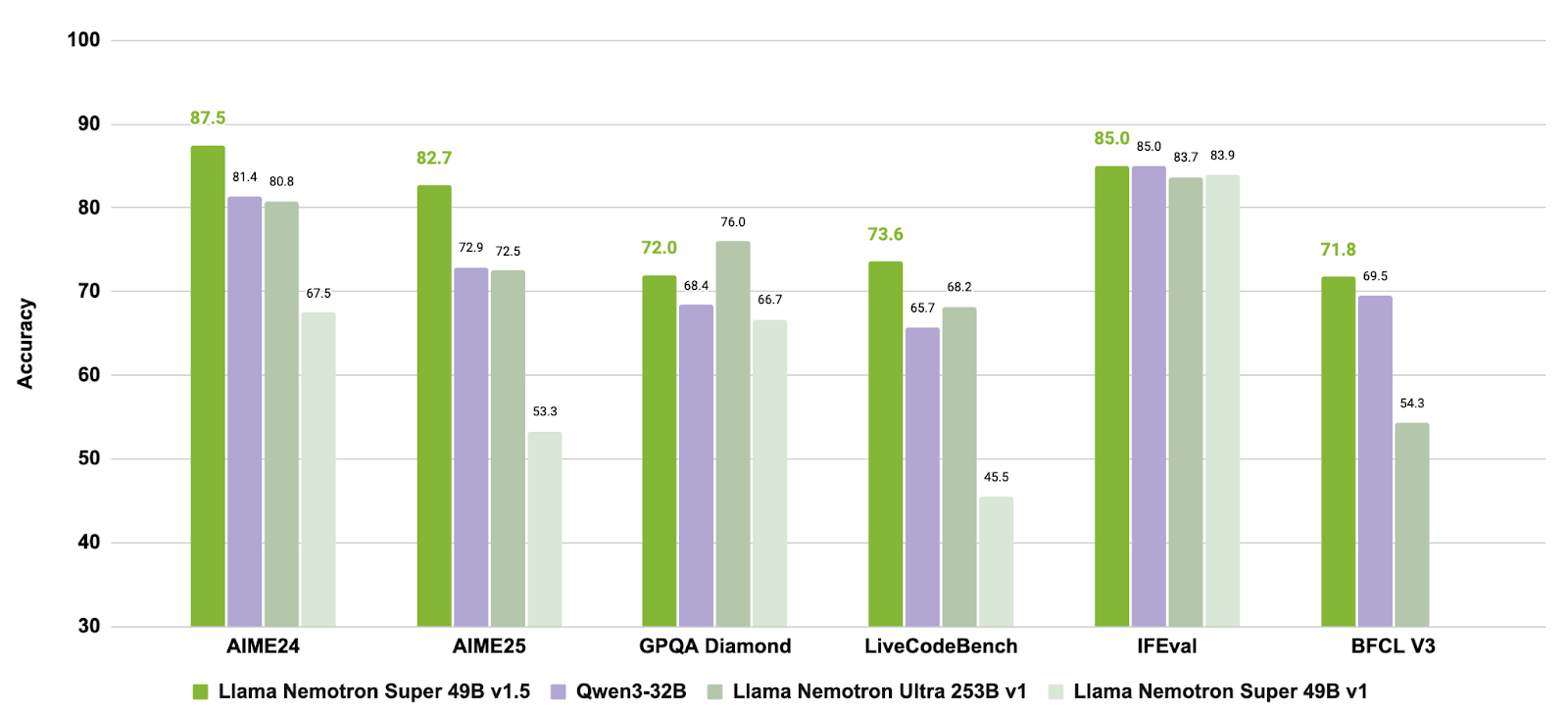
Kaynak: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Muhakeme ve ajans davranışları için hedefli eğitim sonrası aşamaları, uzun bağlamlı görevlere destekle birleştirerek, Llama-3.3-Nemotron-Super-49B-v1.5, gelişmiş muhakeme yeteneklerine ve sağlam araç kullanımına ihtiyaç duyan geliştiriciler için, çalışma zamanı verimliliğinden ödün vermeden dengeli bir çözüm sunar.
Mistral-Small-3.2-24B-Instruct-2506, Mistral-Small-3.1-24B-Instruct-2503’e göre önemli bir yükseltmedir; yönerge izlemeyi geliştirir, tekrar hatalarını azaltır ve daha sağlam bir fonksiyon çağrısı şablonu sağlar; tüm bunları genel yetenekleri korurken veya biraz iyileştirirken yapar. 24B parametreli bir instruct modeli olarak, AWS pazaryerleri de dahil olmak üzere platformlar genelinde yaygın erişilebilirliğe sahiptir ve geliştirilmiş yönerge uyumuyla öne çıkar.
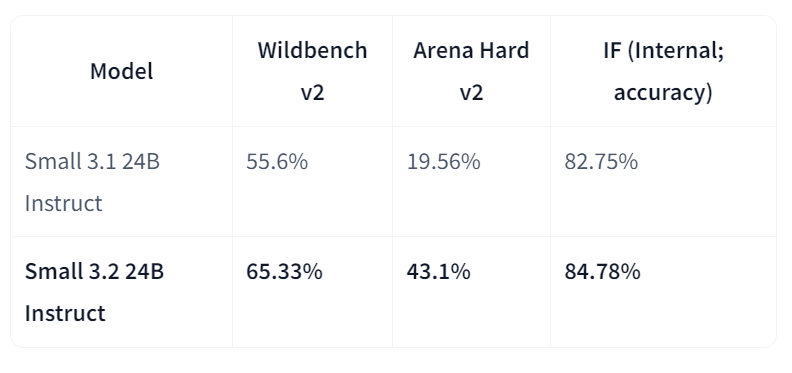
Kaynak: mistralai/Mistral-Small-3.2-24B-Instruct-2506
Sürüm 3.1 ile doğrudan karşılaştırmalarda Small-3.2, asistan kalitesi ve güvenilirliğinde net ilerlemeler gösterir. Wildbench v2’de yönerge izleme performansını %55,6’dan %65,33’e ve Arena Hard v2’de %19,56’dan %43,1’e yükseltirken, dahili yönerge izleme doğruluğu %82,75’ten %84,78’e çıkar. Zor açılımlarda tekrar hataları yarı yarıya azalır (%2,11’den %1,29’a). Bu arada STEM performansı benzer kalır; MATH %69,42, HumanEval+ Pass@5 %92,90’dır.
Aşağıdaki tabloda, en iyi modellerin bir karşılaştırmasını görebilirsiniz:
| Model | Temel Güçler | Dikkate Değer Yükseltmeler / Özellikler |
|---|---|---|
| GLM 4.6 | Güçlü muhakeme, ajans iş akışları ve kodlama yetenekleri | Bağlam penceresi 128K → 200K’a genişletildi; GLM-4.5 ve DeepSeek-V3.1’e kıyasla iyileştirilmiş kıyaslama performansı |
| gpt-oss-120B | Gelişmiş muhakeme ve ajans görevleri için açık ağırlıklı GPT modeli | Yapılandırılabilir muhakeme derinliği, düşünce zinciri erişimi, fonksiyon çağrısı ve harmony yanıt formatı |
| Qwen3-235B-Instruct-2507 | Çok dilli, yüksek hassasiyetli muhakeme ve yönerge izleme | 1M+ token bağlam, tercihe hizalı yazım, GPT-4o ve Claude Opus 4’ü (düşünmeyen) geride bırakır |
| DeepSeek-V3.2-Exp | Seyrek dikkat ile verimli uzun bağlam işleme | Azaltılmış hesaplama ile V3.1 performansını yakalar; optimize edilmiş transformer verimliliği |
| DeepSeek-R1-0528 | İleri düzey muhakeme, matematik ve programlama becerisi | AIME 2025’te %17,5 iyileşme; daha derin analitik düşünme ve daha güvenilir kodlama |
| Apriel-1.5-15B-Thinker | Tek GPU’da çoklu ortam (metin + görsel) muhakeme | Metin ve görsel üzerinde sürekli ön eğitim; kompakt model boyutu için sınır düzeyi muhakeme |
| Kimi-K2-Instruct-0905 | Üst düzey muhakeme ve ajans tabanlı kodlama iş akışları | 256K-token bağlam, geliştirilmiş geliştirici ergonomisi ve araç destekli görev desteği |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Dengeli muhakeme ve araç kullanımı modeli | RAG ve ajans uygulamaları için NVIDIA tarafından ayarlandı; 128K tokene kadar uzun bağlam desteği |
| Mistral-Small-3.2-24B-Instruct-2506 | Kompakt ve güvenilir yönerge izleme | Tekrar hatalarında azalma (%50) ve WildBench v2 ile Arena Hard v2’de büyük kazanımlar |
Açık kaynak LLM alanı hızla genişliyor. Bugün, tescilli olanlardan çok daha fazla açık kaynak LLM var ve dünya çapında geliştiriciler mevcut LLM’leri yükseltmek ve daha optimize modeller tasarlamak için birlikte çalıştıkça performans farkı yakında kapanabilir.
Bu dinamik ve heyecan verici bağlamda, amaçlarınıza uygun doğru açık kaynak LLM’yi seçmek zor olabilir. Belirli bir açık kaynak LLM’ye yönelmeden önce düşünmeniz gereken bazı faktörlerin listesi aşağıdadır:
Açık kaynak LLM’ler yalnızca bireysel projeler veya ilgi alanları için değildir. Üretken yapay zekâ devrimi hızlanmaya devam ettikçe, işletmeler bu araçları anlamanın ve uygulamanın kritik önemini fark ediyor. LLM’ler, sohbet botlarından karmaşık veri işleme görevlerine kadar gelişmiş yapay zekâ uygulamalarını çalıştırmada zaten temel hâline geldi. Ekibinizin yapay zekâ ve LLM teknolojilerinde yetkin olmasını sağlamak artık sadece rekabet avantajı değil — işletmenizi geleceğe hazırlamak için bir gereklilik.
Ekip lideri veya işletme sahibiyseniz ve ekibinizi yapay zekâ ve LLM uzmanlığıyla güçlendirmek istiyorsanız, DataCamp for Business, çalışanlarınızın bu güçlü araçlardan yararlanmak için ihtiyaç duyduğu becerileri kazanmasına yardımcı olabilecek kapsamlı eğitim programları sunar. Aşağıdakileri sağlıyoruz:
Yapay zekâ ve LLM becerilerine yatırım yapmak, yalnızca ekibinizin yeteneklerini artırmakla kalmaz; işletmenizi inovasyonun ön saflarına taşır ve bu dönüştürücü teknolojilerin tüm potansiyelinden yararlanmanızı sağlar. Ekibimizle iletişime geçerek bir demo talep edin ve bugün yapay zekâya hazır iş gücünüzü oluşturmaya başlayın.
Açık kaynak LLM’ler heyecan verici bir hareketin içinde. Hızlı evrimleriyle, üretken yapay zekâ alanının bu güçlü araçları inşa edip kullanma gücüne sahip büyük oyuncular tarafından tekelleştirilmeyeceği anlaşılıyor.
Burada yalnızca sekiz açık kaynak LLM’e baktık; ancak sayı çok daha yüksek ve hızla artıyor. DataCamp olarak LLM alanındaki en son gelişmeler hakkında bilgi sağlamaya; LLM’lere yönelik kurslar, makaleler ve eğitimler sunmaya devam edeceğiz. Şimdilik, seçtiğimiz materyal listemize göz atın:
Yapay Zekâ Yolculuğunuza Bugün Başlayın!
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
