
Lernpfad
Grundlagen der KI
10 Std.
Die Entscheidung für Open-Source-LLMs anstelle von proprietären LLMs bringt mehrere kurz- und langfristige Vorteile mit sich. Hier findest du eine Liste der wichtigsten Gründe:
Eines der größten Probleme bei der Nutzung proprietärer LLMs ist das Risiko von Datenlecks oder unbefugtem Zugriff auf sensible Daten durch den LLM-Anbieter. Es gab schon ein paar Diskussionen darüber, dass persönliche und vertrauliche Daten angeblich für Trainingszwecke genutzt werden.
Durch die Nutzung von Open-Source-LLM sind die Unternehmen allein für den Schutz personenbezogener Daten verantwortlich, da sie die volle Kontrolle darüber behalten.
Die meisten proprietären LLMs brauchen eine Lizenz, damit man sie nutzen kann. Auf lange Sicht kann das echt teuer werden, was sich manche Firmen, vor allem KMU, vielleicht nicht leisten können. Bei Open-Source-LLMs ist das nicht so, weil man sie normalerweise kostenlos nutzen kann.
Man muss aber bedenken, dass der Betrieb von LLMs ziemlich viele Ressourcen braucht, selbst nur für die Inferenz. Das heißt, dass man normalerweise für die Nutzung von Cloud-Diensten oder einer starken Infrastruktur bezahlen muss.
Firmen, die sich für Open-Source-LLMs entscheiden, können die Funktionsweise von LLMs checken, zum Beispiel den Quellcode, die Architektur, die Trainingsdaten und den Mechanismus für Training und Inferenz. Diese Transparenz ist der erste Schritt für eine genaue Prüfung, aber auch für die Anpassung.
Da Open-Source-LLMs für alle zugänglich sind, auch ihr Quellcode, können Firmen, die sie nutzen, sie für ihre speziellen Anwendungsfälle anpassen.
Die Open-Source-Bewegung will die Nutzung und den Zugang zu LLM- und generativen KI-Technologien für alle zugänglich machen. Entwicklern die Möglichkeit zu geben, die inneren Abläufe von LLMs zu checken, ist super wichtig für die weitere Entwicklung dieser Technologie. Durch den Abbau von Einstiegshürden für Programmierer auf der ganzen Welt können Open-Source-LLMs Innovationen fördern und die Modelle verbessern, indem sie Verzerrungen reduzieren und die Genauigkeit sowie die Gesamtleistung steigern.
Seitdem diese großen Sprachmodelle immer beliebter werden, machen sich Forscher und Umweltschützer Gedanken über den CO2-Fußabdruck und den Wasserverbrauch, die nötig sind, um diese Technologien zu betreiben. Proprietäre LLMs geben selten Infos darüber raus, welche Ressourcen man braucht, um sie zu trainieren und zu betreiben, oder wie groß ihr ökologischer Fußabdruck ist.
Mit Open-Source-LLM haben Forscher mehr Möglichkeiten, sich über diese Infos zu informieren, was den Weg für neue Verbesserungen ebnen kann, die darauf abzielen, den ökologischen Fußabdruck von KI zu verringern.
GLM-4.6 ist ein großes Sprachmodell der nächsten Generation, das GLM-4.5 ablöst. Es soll Arbeitsabläufe verbessern, bei der Programmierung helfen, komplexe Überlegungen erleichtern und hochwertige natürliche Sprache erzeugen. Das Modell ist sowohl für Forschungs- als auch für Produktionsumgebungen gedacht und konzentriert sich auf das Verstehen längerer Zusammenhänge, das Schließen mit Hilfsmitteln und das Schreiben, das besser zu den Vorlieben der Nutzer passt.
Quelle:zai-org/GLM-4.6
Im Vergleich zu GLM-4.5 hat GLM-4.6 ein paar wichtige Verbesserungen: Das Kontextfenster wurde von 128K auf 200K Token erweitert, was komplexere agentenbasierte Aufgaben ermöglicht. Die Codierungsleistung wurde auch verbessert, was zu höheren Benchmark-Ergebnissen und stärkeren Ergebnissen in echten Anwendungen führt.
GLM-4.6 zeigt deutliche Verbesserungen bei acht öffentlichen Benchmarks in den Bereichen Agenten, Schlussfolgerungen und Codierung, übertrifft GLM-4.5 und zeigt Wettbewerbsvorteile gegenüber führenden Modellen wie DeepSeek-V3.1-Terminus und Claude Sonnet 4.
gpt-oss-120b ist das Topmodell der gpt-oss-Serie – die offenen Modelle von OpenAI, die für anspruchsvolles Denken, agentenbasierte Aufgaben und vielseitige Entwickler-Workflows entwickelt wurden. Diese Serie hat zwei Versionen: gpt-oss-120b, das für produktionsreife, allgemeine Anwendungsfälle gedacht ist, die ein hohes Maß an logischem Denken erfordern und auf einer einzigen 80-GB-GPU laufen können (mit 117 Milliarden Parametern, davon 5,1 Milliarden aktiv); und gpt-oss-20b, die für geringere Latenzzeiten und lokale oder spezialisierte Einsätze optimiert ist (mit 21 Milliarden Parametern und 3,6 Milliarden aktiven Parametern). Beide Modelle sind mit dem Harmony-Response-Format trainiert und sollten mit dem Harmony-Framework zusammen genutzt werden, damit sie richtig funktionieren.
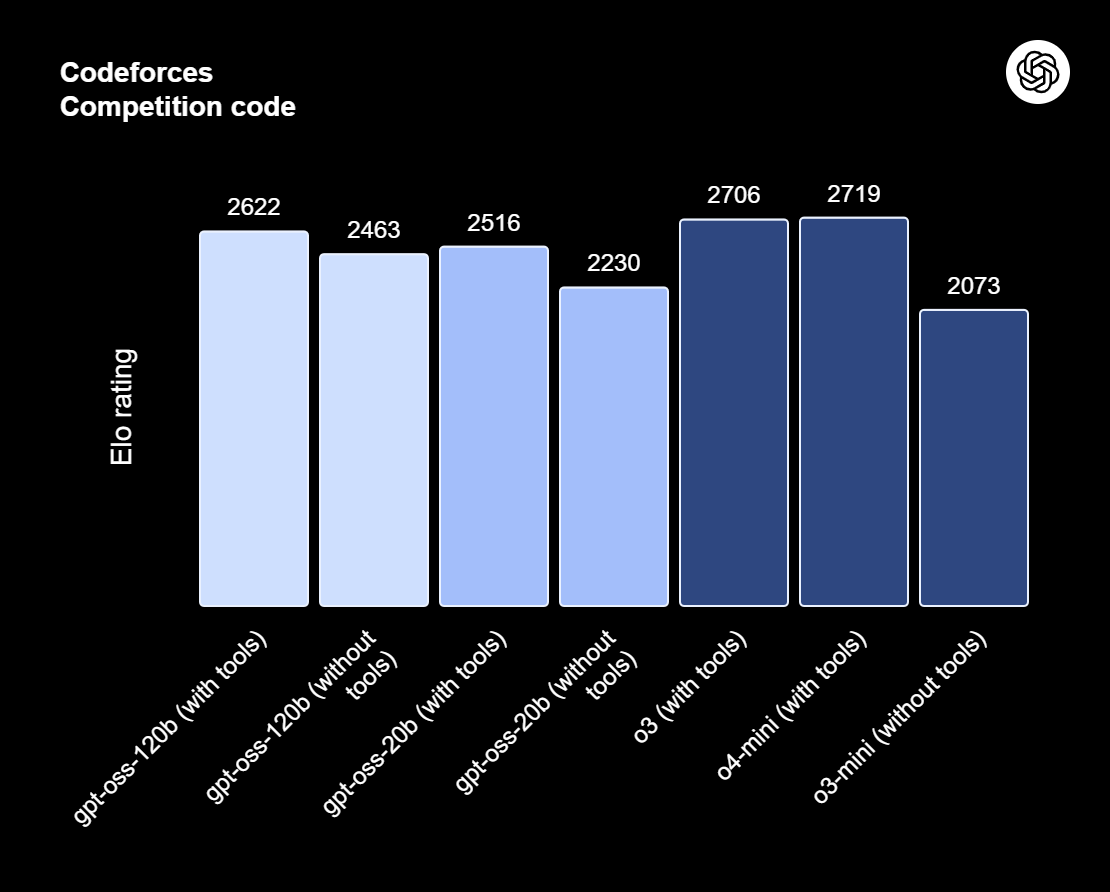
Quelle: Wir stellen vor: gpt-oss | OpenAI
Der gpt-oss-120b hat auch einstellbare Rechenleistungen: niedrig, mittel oder hoch, um Tiefe und Latenz auszugleichen. Es bietet vollen Zugriff auf die Gedankenkette für Debugging- und Audit-Zwecke. Diese Modelle können fein abgestimmt werden und haben eingebaute Funktionen, wie zum Beispiel Funktionsaufrufe, Webbrowsing, Python-Codeausführung und strukturierte Ausgaben.
Dank der MXFP4-Quantisierung der MoE-Gewichte kann gpt-oss-120b auf einer einzigen 80-GB-GPU laufen, während gpt-oss-20b in einer 16-GB-Umgebung funktioniert. Schau dir unseren Artikel über 10 Möglichkeiten an, wie du kostenlos auf GPT-OSS 120B zugreifen kannst.
Qwen3-235B-A22B-Instruct-2507 ist das Topmodell ohne Denkfunktion in der Qwen3-MoE-Familie. Es ist für supergenaues Befolgen von Anweisungen, strenges logisches Denken, mehrsprachiges Textverständnis, Mathe, Naturwissenschaften, Programmieren, Werkzeuggebrauch und Aufgaben mit echt langen Zusammenhängen gemacht. Es ist ein gemischtes kausales Sprachmodell von Experten (MoE) mit insgesamt 235 Milliarden Parametern, davon 22 Milliarden aktive Parameter (mit 128 Experten, von denen jeweils 8 aktiv sind). Das Modell hat 94 Schichten, einen GQA-Mechanismus mit 64 Abfrage-Heads und 4 Schlüsselwert-Heads und ein natives Kontextfenster von 262.000 Tokens, das auf ungefähr 1,01 Millionen Tokens erweitert werden kann.
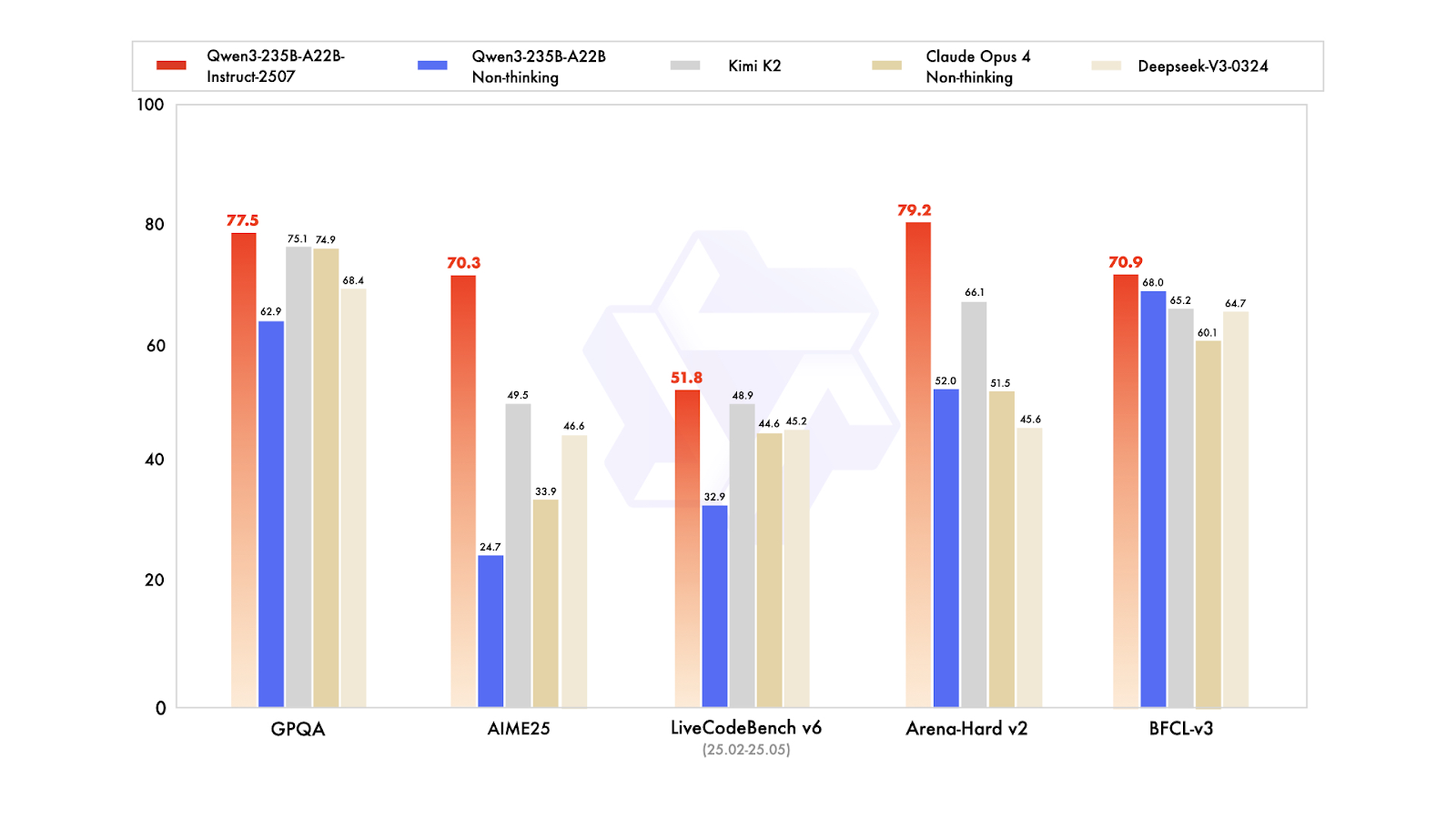
Das neueste Update von Instruct-2507 bringt echt coole Verbesserungen bei den allgemeinen Funktionen und erweitert das Wissen über Long-Tail-Begriffe in mehreren Sprachen. Es passt sich auch viel besser an offene Aufgaben an und macht die Schreibqualität besser, vor allem bei über 256.000 Wörtern, die im Kontext verstanden werden.
Bei öffentlichen Benchmarks zeigt es echt gute Ergebnisse. In der Praxis macht das Instruct-2507 zu einem Top-Modell ohne Denkfunktion, das sowohl die alte Variante Qwen3-235B-A22B ohne Denkfunktion als auch die führenden Konkurrenten wie DeepSeek-V3, GPT-4o, Claude Opus 4 (ohne Denkfunktion) und Kimi K2 übertrifft.
Mehr über Qwen3 erfährst du in unserem ganzen Artikel.
DeepSeek-V3.2-Exp ist eine experimentelle Zwischenversion, die zur nächsten Generation der DeepSeek-Architektur führt. Es baut auf V3.1-Terminus auf und bringt DeepSeek Sparse Attention mit, um das Training und die Inferenz-Effizienz zu verbessern, vor allem in Szenarien mit langem Kontext. Dieses Modell soll die Effizienz des Transformators für längere Sequenzen verbessern und gleichzeitig die von der Terminus-Reihe erwartete Ausgabequalität beibehalten.
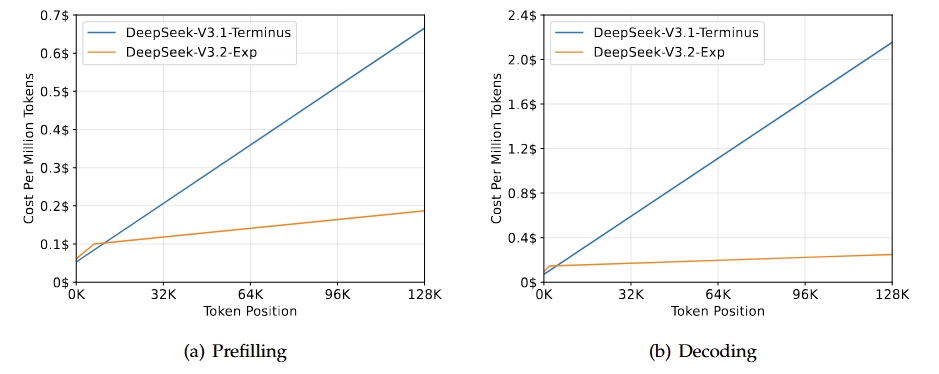
Quelle: DeepSeek-V3.2-Exp
Das Wichtigste an dieser Version ist, dass sie die gleichen Funktionen wie V3.1-Terminus hat und gleichzeitig bei Aufgaben mit langem Kontext viel effizienter ist. Bewertungen und Analysen von anderen zeigen, dass es genauso gut wie Terminus ist, aber viel weniger Rechenaufwand braucht. Das zeigt, dass man mit weniger Aufwand effizienter arbeiten kann, ohne dass die Qualität leidet.
Schau dir unseren kompletten Leitfaden zu DeppSeek-V3.2-Exp an, um ein Demo-Projekt durchzuarbeiten.
DeepSeek-R1 hat ein kleines Versions-Upgrade auf DeepSeek-R1-0528, das die Fähigkeiten zur Schlussfolgerung und Inferenz durch mehr Rechenleistung und Optimierungen der Algorithmen nach dem Training verbessert. Deshalb gibt's in verschiedenen Bereichen, wie Mathe, Programmieren und allgemeiner Logik, echt gute Fortschritte. Die Gesamtleistung ist jetzt näher dran an den führenden Systemen wie O3 und Gemini 2.5 Pro.
Neben den reinen Funktionen legt dieses Update den Fokus auf praktische Anwendbarkeit mit besseren Funktionsaufrufen und Codierungsabläufen, was zeigt, dass es darum geht, zuverlässigere und produktivitätsorientierte Ergebnisse zu erzielen.
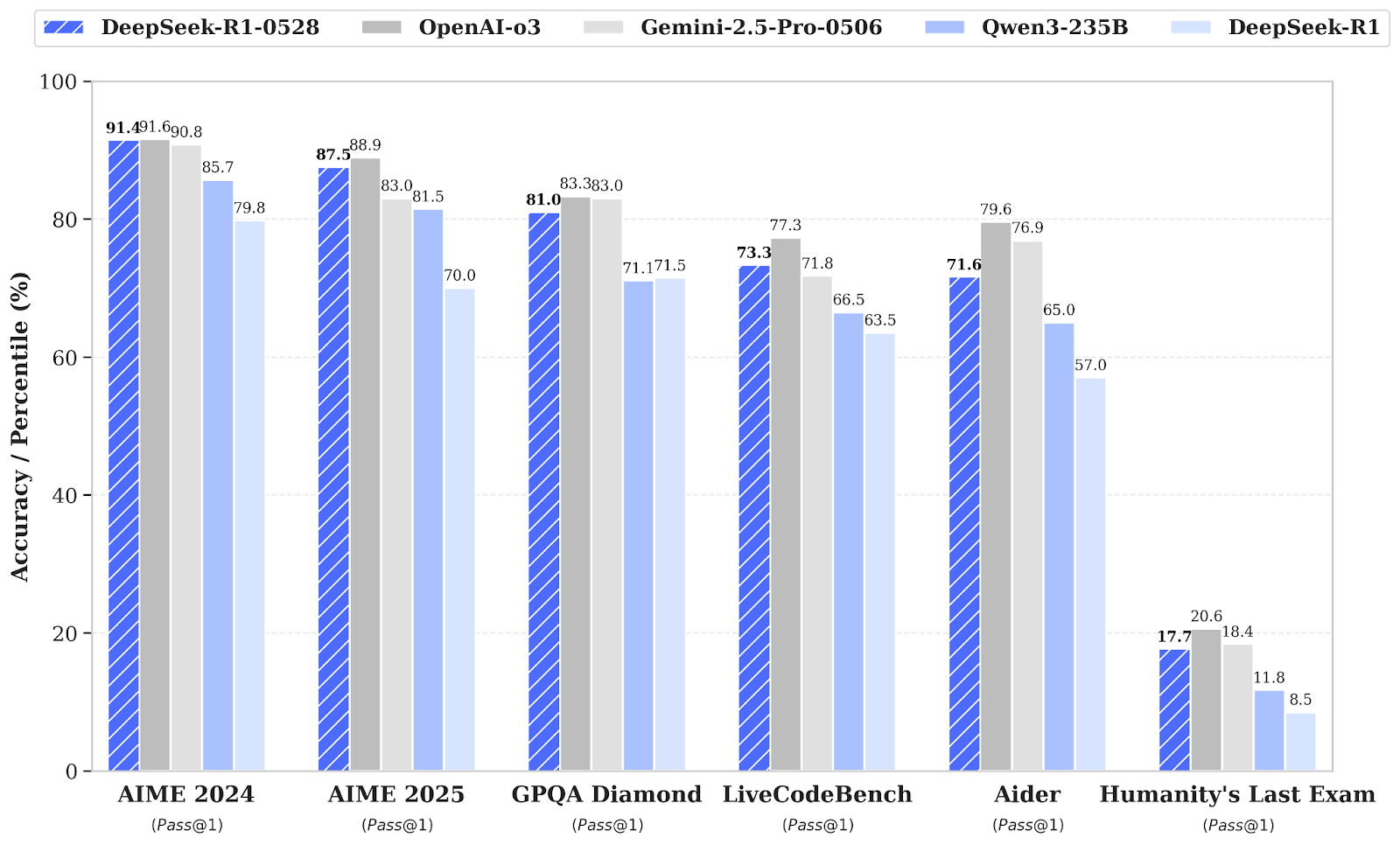
Quelle: deepseek-ai/DeepSeek-R1-0528
Im Vergleich zur alten DeepSeel R1 -Version macht das neue Modell echt große Fortschritte beim komplexen Denken. Bei der AIME-Prüfung 2025 hat sich die Genauigkeit zum Beispiel von 70 % auf 87,5 % verbessert, weil das analytische Denken besser geworden ist (die durchschnittliche Anzahl der Tokens pro Frage ist von etwa 12.000 auf 23.000 gestiegen).
Umfassendere Bewertungen zeigen auch positive Trends in Bereichen wie Wissen, logisches Denken und Programmierfähigkeiten. Beispiele dafür sind Verbesserungen bei LiveCodeBench, Codeforces-Bewertungen, SWE Verified und Aider-Polyglot, die auf eine verbesserte Problemlösungstiefe und überlegene praktische Programmierfähigkeiten hindeuten.
Apriel-1.5-15b-Thinker ist ein multimodales Schlussfolgerungsmodell aus der Apriel SLM-Serie von ServiceNow. Es bietet eine konkurrenzfähige Leistung mit nur 15 Milliarden Parametern und zielt darauf ab, innerhalb der Grenzen eines Single-GPU-Budgets Ergebnisse auf Spitzenniveau zu erzielen. Dieses Modell erweitert das bisherige reine Textmodell nicht nur um Bildverarbeitungsfunktionen, sondern verbessert auch seine Fähigkeiten zur Textverarbeitung.
Als zweites Modell in der Reasoning-Serie hat es ein umfangreiches kontinuierliches Vortraining sowohl im Text- als auch im Bildbereich durchlaufen. Nach dem Training gibt's nur noch eine textbasierte überwachte Feinabstimmung (SFT), ohne bildspezifische SFT oder verstärktes Lernen. Trotz dieser Einschränkungen zielt das Modell auf modernste Qualität bei der Text- und Bildinterpretation für seine Größe ab.
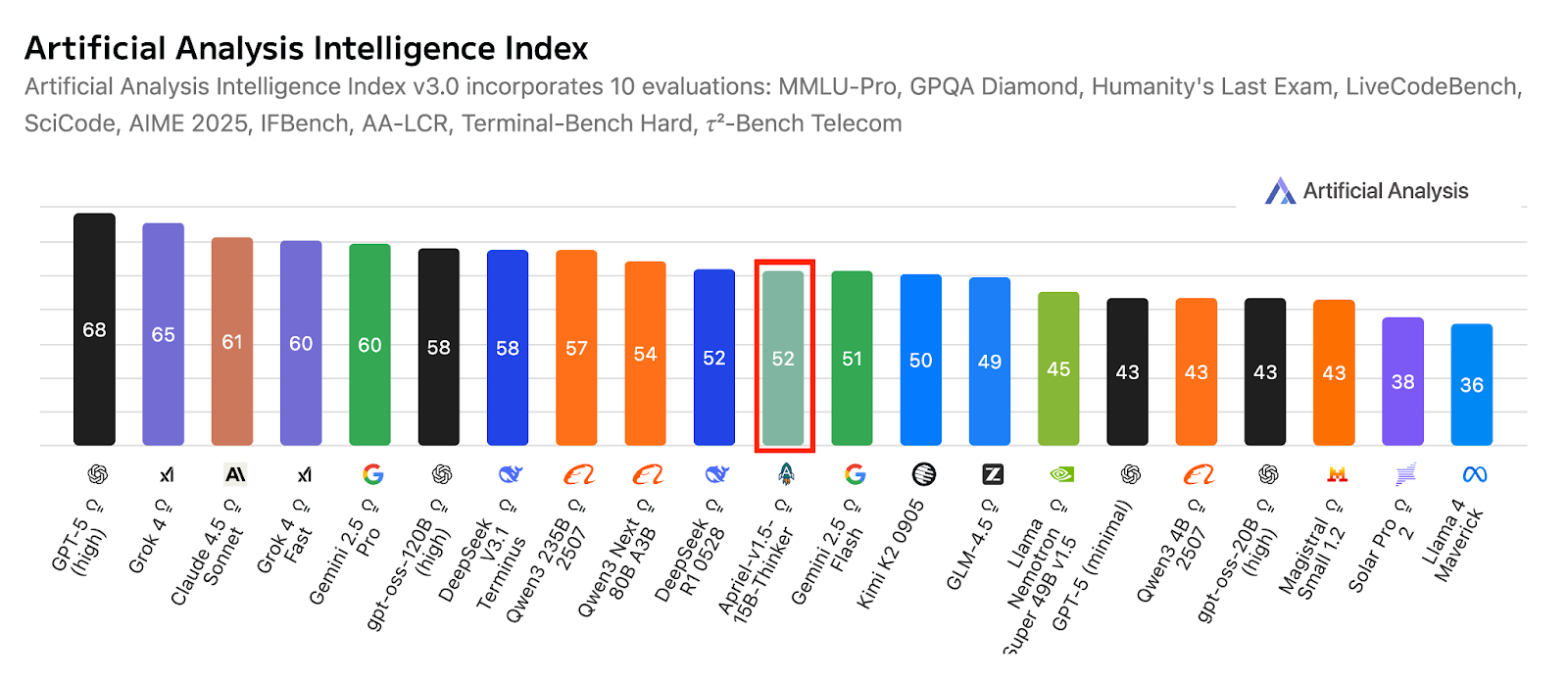
Quelle: ServiceNow-AI/Apriel-1.5-15b-Thinker
Entwickelt für den Betrieb auf einer einzigen GPU, setzt es auf praktische Einsatzmöglichkeiten und Effizienz. Die Ergebnisse zeigen, dass das Modell echt bereit für den Einsatz in der Praxis ist. Mit einem Artificial Analysis Index von 52 kann es locker mit viel größeren Systemen mithalten. Diese Punktzahl zeigt auch, wie gut es im Vergleich zu den führenden Kompakt- und Frontier-Modellen abschneidet, und das bei einer kompakten Bauweise, die perfekt für den Einsatz in Unternehmen ist.
Kimi-K2-Instruct-0905 ist das neueste und modernste Modell der Kimi K2-Reihe. Es ist ein topaktuelles Mixture-of-Experts-Sprachmodell mit insgesamt 1 Billion Parametern und 32 Milliarden aktivierten Parametern. Dieses Modell ist extra für anspruchsvolle Denk- und Programmieraufgaben gemacht.
K2-Instruct-0905 macht K2 viel besser darin, langfristige Aufgaben zu erledigen, mit einem Kontextfenster von 256.000 Token, was eine Steigerung gegenüber den vorherigen 128.000 Token ist. Es soll robuste agentenbasierte Anwendungsfälle unterstützen, darunter toolgestützte Chat- und Code-Unterstützung. Als Flaggschiff der K2 Instruct-Serie legt es den Fokus auf eine starke Entwicklerergonomie und Zuverlässigkeit für Anwendungen in Produktionsqualität.
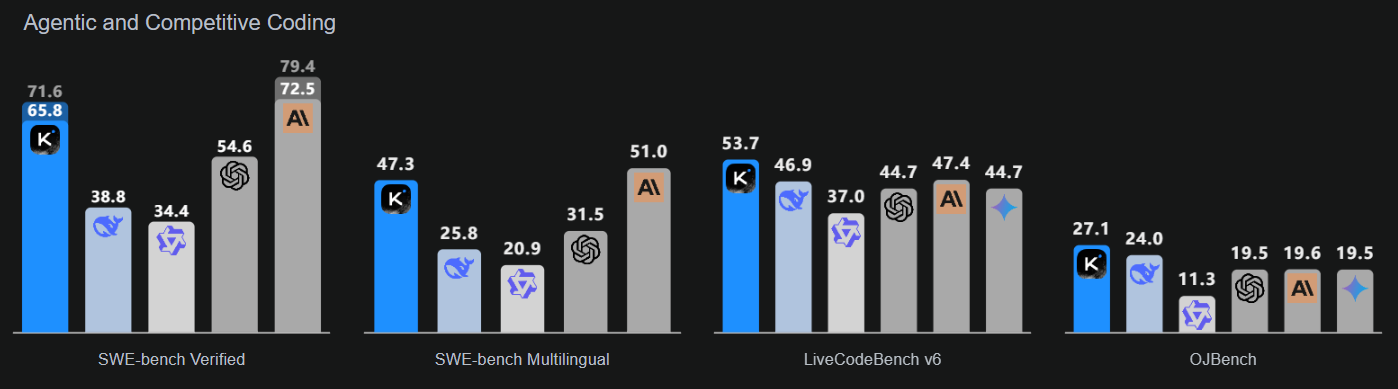
Quelle: Kimi K2: Offene künstliche Intelligenz
Dieses Modell konzentriert sich auf drei wichtige Bereiche: verbesserte Codierungsintelligenz für agentenbasierte Aufgaben, die deutliche Verbesserungen in öffentlichen Benchmarks und realen Anwendungen zeigt; eine verbesserte Benutzeroberfläche, die sowohl die Ästhetik als auch die Funktionalität verbessert; und eine erweiterte Kontextlänge von 256.000 Token, die umfangreichere Planungs- und Bearbeitungsschleifen ermöglicht.
Llama-3_3-Nemotron-Super-49B-v1_5 ist ein verbessertes Modell mit 49 Milliarden Parametern aus der Nemotron-Reihe von NVIDIA, das von Meta's Llama-3.3-70B-Instruct abgeleitet ist. Es ist speziell als Denkmodell für menschenorientierte Chat- und Agentenaufgaben entwickelt worden, wie zum Beispiel die suchgestützte Generierung (RAG) und das Aufrufen von Tools.
Dieses Modell hat ein Nach-Training durchlaufen, um seine Fähigkeiten im Bereich des logischen Denkens, der Präferenzanpassung und der Werkzeugnutzung zu verbessern. Es unterstützt auch Workflows mit langem Kontext von bis zu 128.000 Tokens und eignet sich daher für komplexe Anwendungen mit mehreren Schritten.
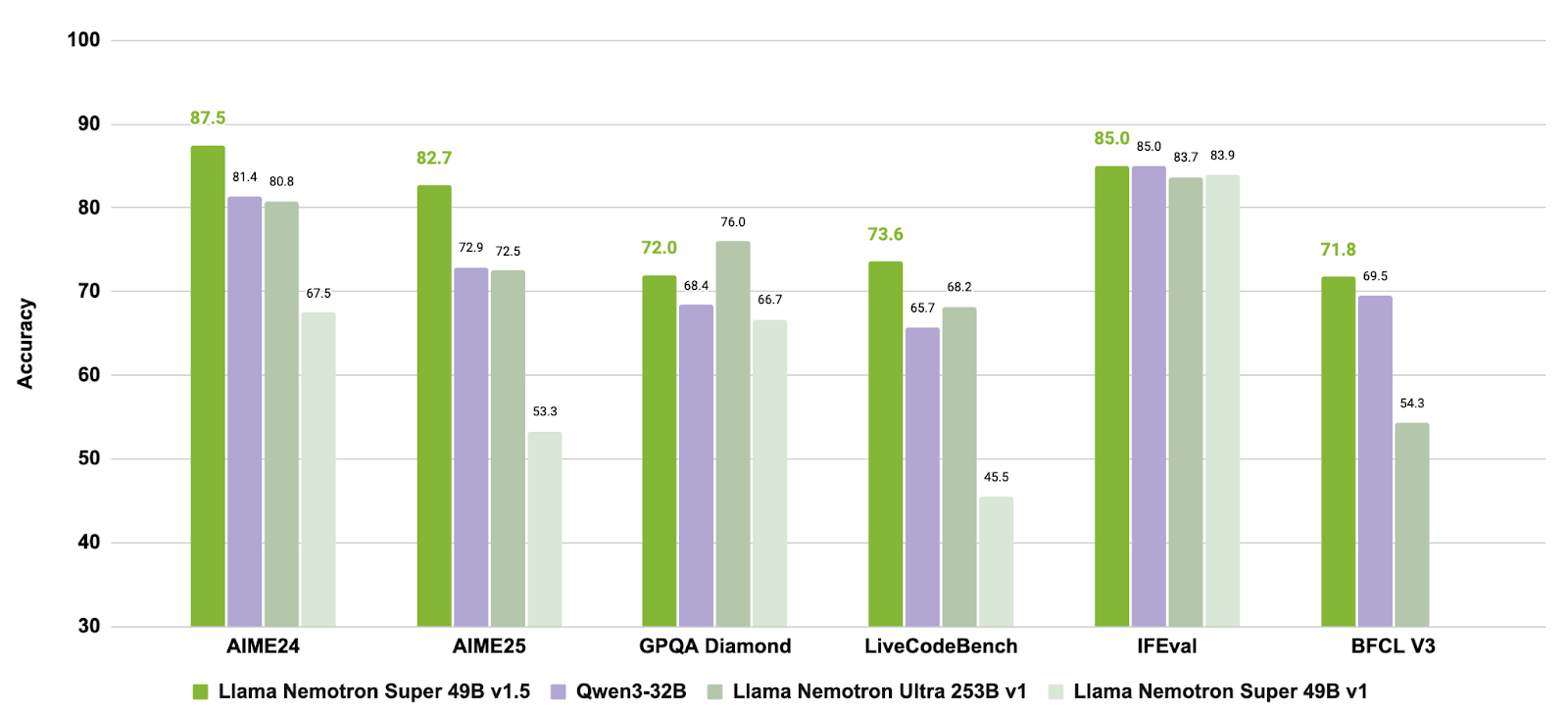
Quelle: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Durch die Kombination von gezieltem Post-Training für Schlussfolgerungen und Agentenverhalten mit Unterstützung für Aufgaben mit langem Kontext bietet Llama-3.3-Nemotron-Super-49B-v1.5 eine ausgewogene Lösung für Entwickler, die fortgeschrittene Schlussfolgerungsfähigkeiten und robuste Tools brauchen, ohne dabei die Laufzeiteffizienz zu beeinträchtigen.
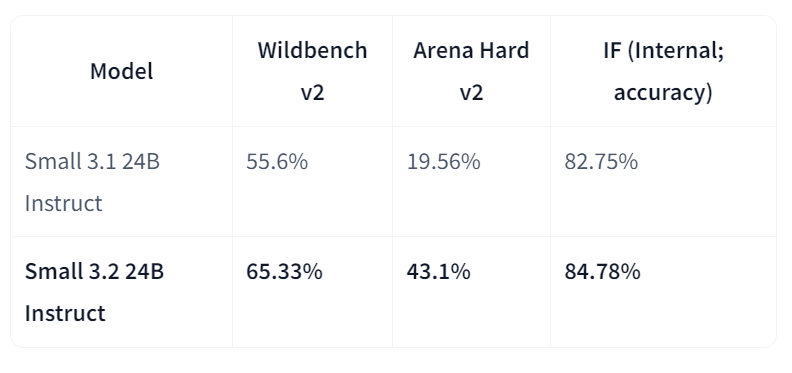
Mistral-Small-3.2-24B-Instruct-2506 ist eine bedeutende Verbesserung gegenüber Mistral-Small-3.1-24B-Instruct-2503, da es die Befehlsausführung verbessert, Wiederholungsfehler reduziert und eine robustere Funktion aufrufvorlage bietet, während die Gesamtfunktionen beibehalten oder leicht verbessert werden. Als 24B-Parameter-Instruct-Modell ist es auf vielen Plattformen verfügbar, zum Beispiel auf AWS-Marktplätzen, wo es für seine verbesserte Einhaltung von Anweisungen bekannt ist.
Quelle: mistralai/Mistral-Small-3.2-24B-Instruct-2506
Im direkten Vergleich zu Version 3.1 zeigt Small-3.2 deutliche Verbesserungen bei der Qualität und Zuverlässigkeit des Assistenten. Es verbessert die Leistung beim Befolgen von Anweisungen auf Wildbench v2 (von 55,6 % auf 65,33 %) und Arena Hard v2 (von 19,56 % auf 43,1 %), während die interne Genauigkeit beim Befolgen von Anweisungen von 82,75 % auf 84,78 % steigt. Die Wiederholungsfehler bei schwierigen Eingabeaufforderungen sind um die Hälfte weniger geworden (von 2,11 % auf 1,29 %). In der Zwischenzeit sind die STEM-Leistungen immer noch vergleichbar, mit MATH bei 69,42 % und HumanEval+ Pass@5 bei 92,90 %.
In der Tabelle unten findest du einen Vergleich der Top-Modelle:
| Modell | Wichtigste Stärken | Wichtige Verbesserungen / Funktionen |
|---|---|---|
| GLM 4.6 | Starke Argumentation, agentenbasierte Arbeitsabläufe und Programmierfähigkeiten | Das Kontextfenster wurde von 128 KB auf 200 KB vergrößert; die Benchmark-Leistung wurde im Vergleich zu GLM-4.5 und DeepSeek-V3.1 |
| gpt-oss-120B | Offenes GPT-Modell für fortgeschrittenes Denken und agentenbasierte Aufgaben | Einstellbare Argumentationstiefe, Zugriff auf Gedankengänge, Funktionsaufrufe und harmonisches Antwortformat |
| Qwen3-235B-Instruct-2507 | Mehrsprachiges, supergenaues Denken und Befolgen von Anweisungen | 1 Million+ Token-Kontext, präferenzorientiertes Schreiben, übertrifft GPT-4o und Claude Opus 4 (nicht denkend) |
| DeepSeek-V3.2-Exp | Effiziente Verarbeitung langer Kontexte durch spärliche Aufmerksamkeit | Bietet die Leistung von V3.1 mit weniger Rechenaufwand; optimierte Transformator-Effizienz |
| DeepSeek-R1-0528 | Fortgeschrittene Fähigkeiten in logischem Denken, Mathe und Programmieren | 17,5 % Verbesserung des AIME 2025; mehr analytische Tiefe und zuverlässigere Kodierung |
| Apriel-1.5-15B-Thinker | Multimodales Denken (Text + Bild) auf einer einzigen GPU | Kontinuierliches Vortraining mit Text und Bildern; hochmoderne Schlussfolgerungen für kompakte Modellgröße |
| Kimi-K2-Instruct-0905 | Hochwertige Argumentation und agentenbasierte Codierungsabläufe | 256K-Token-Kontext, bessere Entwickler-Ergonomie und Tool-gestützte Aufgabenunterstützung |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Ausgewogenes Modell für Argumentation und Werkzeugnutzung | Von NVIDIA für RAG- und agentenbasierte Anwendungen optimiert; Unterstützung für lange Kontexte mit bis zu 128.000 Tokens |
| Mistral-Small-3.2-24B-Instruct-2506 | Kompakt und zuverlässig beim Befolgen von Anweisungen | Weniger Wiederholungsfehler (−50 %) und echt gute Verbesserungen bei WildBench v2 und Arena Hard v2 |
Der Open-Source-LLM-Bereich wächst echt schnell. Heutzutage gibt's viel mehr Open-Source-LLMs als proprietäre, und der Leistungsunterschied könnte bald ausgeglichen werden, weil Entwickler weltweit zusammenarbeiten, um die aktuellen LLMs zu verbessern und optimiertere zu entwickeln.
In diesem lebhaften und spannenden Umfeld kann es schwierig sein, das richtige Open-Source-LLM für deine Zwecke zu finden. Hier ist eine Liste mit ein paar Dingen, die du bedenken solltest, bevor du dich für ein bestimmtes Open-Source-LLM entscheidest:
Open-Source-LLMs sind nicht nur für einzelne Projekte oder Interessen gedacht. Da die Revolution der generativen KI immer schneller wird, merken Unternehmen, wie wichtig es ist, diese Tools zu verstehen und einzusetzen. LLMs sind schon jetzt super wichtig für die Nutzung von fortschrittlichen KI-Anwendungen, von Chatbots bis hin zu komplizierten Datenverarbeitungsaufgaben. Sicherzustellen, dass dein Team sich mit KI- und LLM-Technologien auskennt, ist nicht mehr nur ein Wettbewerbsvorteil – es ist ein Muss, um dein Unternehmen für die Zukunft fit zu machen.
Wenn du ein Teamleiter oder Unternehmer bist und dein Team mit KI- und LLM-Know-how ausstatten willst, bietet DataCamp for Business umfassende Schulungsprogramme, mit denen deine Mitarbeiter die nötigen Fähigkeiten erwerben können, um diese leistungsstarken Tools zu nutzen. Wir bieten:
Wenn du in KI und LLM-Weiterbildungen investierst, machst du dein Team nicht nur besser, sondern bringst dein Unternehmen auch an die Spitze der Innovation. So kannst du das ganze Potenzial dieser transformativen Technologien nutzen. Sprich einfach mit unserem Team, um eine Demo anzufordern und noch heute mit dem Aufbau deiner KI-fähigen Belegschaft zu beginnen.
Open-Source-LLMs sind gerade voll im Trend. Angesichts ihrer schnellen Entwicklung sieht es so aus, als würde der Bereich der generativen KI nicht unbedingt von den großen Unternehmen dominiert werden, die es sich leisten können, diese leistungsstarken Tools zu entwickeln und zu nutzen.
Wir haben erst acht Open-Source-LLMs gesehen, aber es gibt viel mehr und es werden immer mehr. Wir bei DataCamp werden weiterhin Infos zu den neuesten Entwicklungen im Bereich LLM liefern und Kurse, Artikel und Tutorials zu LLMs anbieten. Schau dir erstmal unsere Liste mit ausgewählten Materialien an:
Starte noch heute deine KI-Reise!
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree