
Tracks
Cơ bản về Trí tuệ Nhân tạo
10 giờ
Có nhiều lợi ích ngắn hạn và dài hạn khi chọn LLM mã nguồn mở thay vì LLM độc quyền. Dưới đây là danh sách những lý do thuyết phục nhất:
Một trong những lo ngại lớn nhất khi dùng LLM độc quyền là rủi ro rò rỉ dữ liệu hoặc nhà cung cấp LLM truy cập trái phép vào dữ liệu nhạy cảm. Thực tế đã có nhiều tranh cãi về việc bị cáo buộc sử dụng dữ liệu cá nhân và bí mật cho mục đích huấn luyện.
Bằng cách dùng LLM mã nguồn mở, các công ty sẽ hoàn toàn chịu trách nhiệm bảo vệ dữ liệu cá nhân, vì họ giữ toàn quyền kiểm soát dữ liệu đó.
Hầu hết LLM độc quyền yêu cầu giấy phép để sử dụng. Về dài hạn, đây có thể là khoản chi đáng kể mà một số công ty, đặc biệt là SME, có thể không kham nổi. Điều này không xảy ra với LLM mã nguồn mở, vì chúng thường miễn phí sử dụng.
Tuy nhiên, cần lưu ý rằng vận hành LLM đòi hỏi tài nguyên đáng kể, ngay cả chỉ để suy luận, đồng nghĩa bạn thường sẽ phải trả phí cho dịch vụ đám mây hoặc hạ tầng mạnh.
Các công ty chọn LLM mã nguồn mở sẽ có quyền truy cập vào cách thức hoạt động của LLM, gồm mã nguồn, kiến trúc, dữ liệu huấn luyện, và cơ chế huấn luyện lẫn suy luận. Tính minh bạch này là bước đầu cho việc thẩm định, nhưng cũng là nền tảng để tùy biến.
Vì LLM mã nguồn mở ai cũng tiếp cận được, bao gồm mã nguồn, nên các công ty có thể tùy biến chúng cho các bài toán riêng.
Phong trào mã nguồn mở hứa hẹn dân chủ hóa việc sử dụng và tiếp cận công nghệ LLM và AI sinh sinh. Cho phép nhà phát triển quan sát hoạt động bên trong của LLM là chìa khóa cho sự phát triển tương lai của công nghệ này. Bằng cách hạ thấp rào cản gia nhập cho lập trình viên toàn cầu, LLM mã nguồn mở có thể thúc đẩy đổi mới và cải thiện mô hình bằng cách giảm thiên lệch, tăng độ chính xác và hiệu năng tổng thể.
Theo sau sự phổ biến của LLM, các nhà nghiên cứu và tổ chức môi trường đang lo ngại về dấu chân carbon và mức tiêu thụ nước cần thiết để vận hành các công nghệ này. LLM độc quyền hiếm khi công bố thông tin về tài nguyên cần để huấn luyện và vận hành, cũng như dấu chân môi trường liên quan.
Với LLM mã nguồn mở, các nhà nghiên cứu có nhiều cơ hội biết được thông tin này, từ đó mở ra các cải tiến mới nhằm giảm dấu chân môi trường của AI.
GLM-4.6 là mô hình ngôn ngữ lớn thế hệ mới kế nhiệm GLM-4.5. Nó được thiết kế để tăng cường quy trình tác tử, cung cấp hỗ trợ lập trình mạnh, tạo thuận lợi cho suy luận nâng cao và sinh ngôn ngữ tự nhiên chất lượng cao. Mô hình nhắm tới cả môi trường nghiên cứu và sản xuất, tập trung vào hiểu ngữ cảnh dài hơn, suy luận tăng cường công cụ và văn phong phù hợp tự nhiên hơn với sở thích người dùng.
Nguồn:zai-org/GLM-4.6
So với GLM-4.5, GLM-4.6 mang đến một số cải tiến then chốt: cửa sổ ngữ cảnh được mở rộng từ 128K lên 200K token, cho phép các tác vụ tác tử phức tạp hơn. Hiệu năng lập trình cũng được nâng cấp, đem lại điểm benchmark cao hơn và kết quả mạnh mẽ hơn trong các ứng dụng thực tế.
GLM-4.6 cho thấy mức tăng rõ rệt trên tám benchmark công khai liên quan đến tác tử, suy luận và lập trình, vượt GLM-4.5 và thể hiện lợi thế cạnh tranh so với các mô hình dẫn đầu như DeepSeek-V3.1-Terminus và Claude Sonnet 4.
gpt-oss-120b là đỉnh cao của dòng gpt-oss—các mô hình open-weight của OpenAI được thiết kế cho suy luận nâng cao, tác vụ tác tử và quy trình làm việc linh hoạt cho nhà phát triển. Dòng này gồm hai phiên bản: gpt-oss-120b, dành cho các trường hợp sử dụng đa mục đích cấp sản xuất đòi hỏi suy luận cấp cao và có thể chạy trên một GPU 80GB (117 tỷ tham số, 5,1 tỷ tham số hoạt động); và gpt-oss-20b, tối ưu cho độ trễ thấp hơn và triển khai cục bộ hoặc chuyên biệt (21 tỷ tham số, 3,6 tỷ tham số hoạt động). Cả hai mô hình được huấn luyện theo định dạng phản hồi harmony và nên được dùng cùng framework harmony để hoạt động hiệu quả.
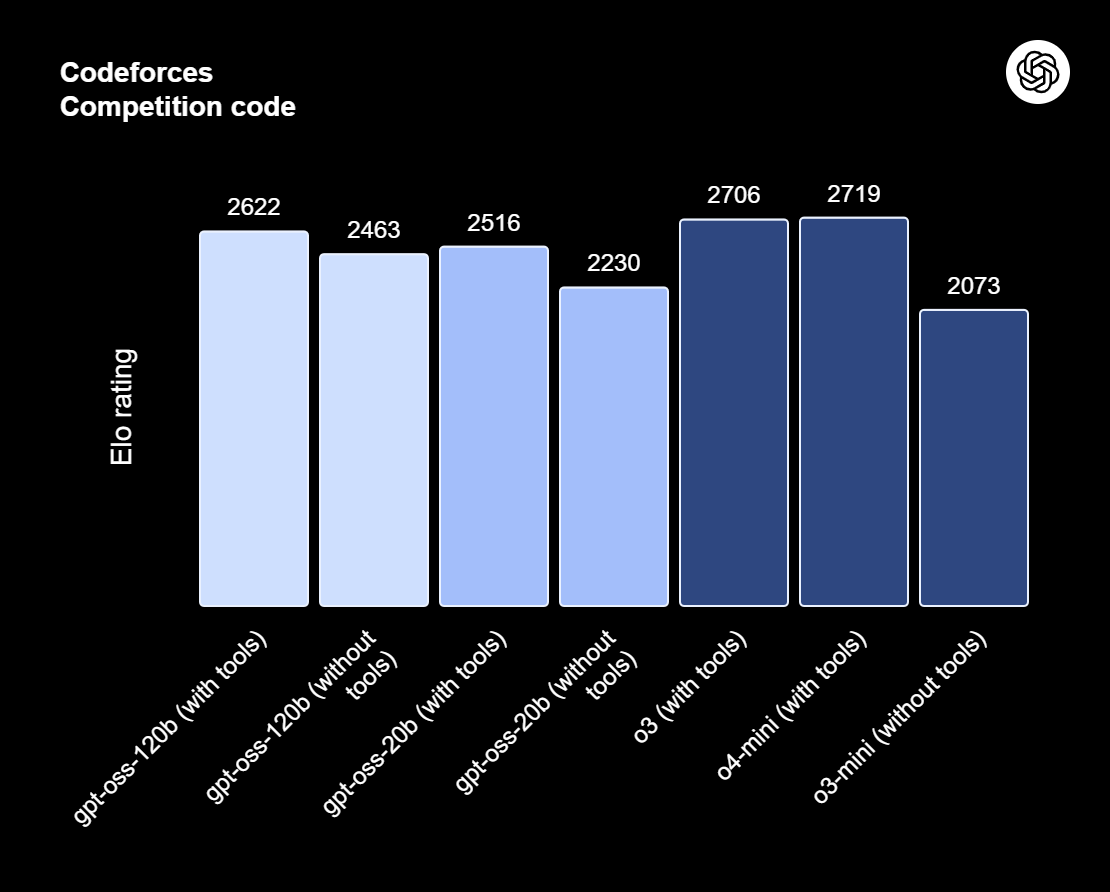
Nguồn: Introducing gpt-oss | OpenAI
gpt-oss-120b cũng cung cấp mức độ nỗ lực suy luận có thể cấu hình: thấp, trung bình hoặc cao, để cân bằng độ sâu và độ trễ. Nó cung cấp quyền truy cập đầy đủ vào chain-of-thought để gỡ lỗi và kiểm tra. Các mô hình này có thể fine-tune và đi kèm khả năng tác tử tích hợp như gọi hàm, duyệt web, thực thi mã Python và xuất đầu ra có cấu trúc.
Nhờ lượng tử hóa MXFP4 cho trọng số MoE, gpt-oss-120b có thể chạy trên một GPU 80GB, trong khi gpt-oss-20b có thể hoạt động trong môi trường 16GB. Đọc bài viết của chúng tôi về 10 cách truy cập GPT-OSS 120B miễn phí.
Qwen3-235B-A22B-Instruct-2507 là mô hình không-thinking chủ lực trong họ Qwen3-MoE, được thiết kế để tuân thủ hướng dẫn chính xác cao, suy luận logic nghiêm ngặt, hiểu văn bản đa ngôn ngữ, toán học, khoa học, lập trình, sử dụng công cụ và các tác vụ đòi hỏi ngữ cảnh rất dài. Đây là mô hình ngôn ngữ nhân quả kiểu mixture of experts (MoE) với tổng 235 tỷ tham số, 22 tỷ tham số hoạt động (dùng 128 expert, kích hoạt 8 mỗi lần). Mô hình gồm 94 lớp, có cơ chế GQA với 64 đầu truy vấn và 4 đầu khóa-giá trị, cửa sổ ngữ cảnh gốc 262.000 token, có thể mở rộng lên khoảng 1,01 triệu token.
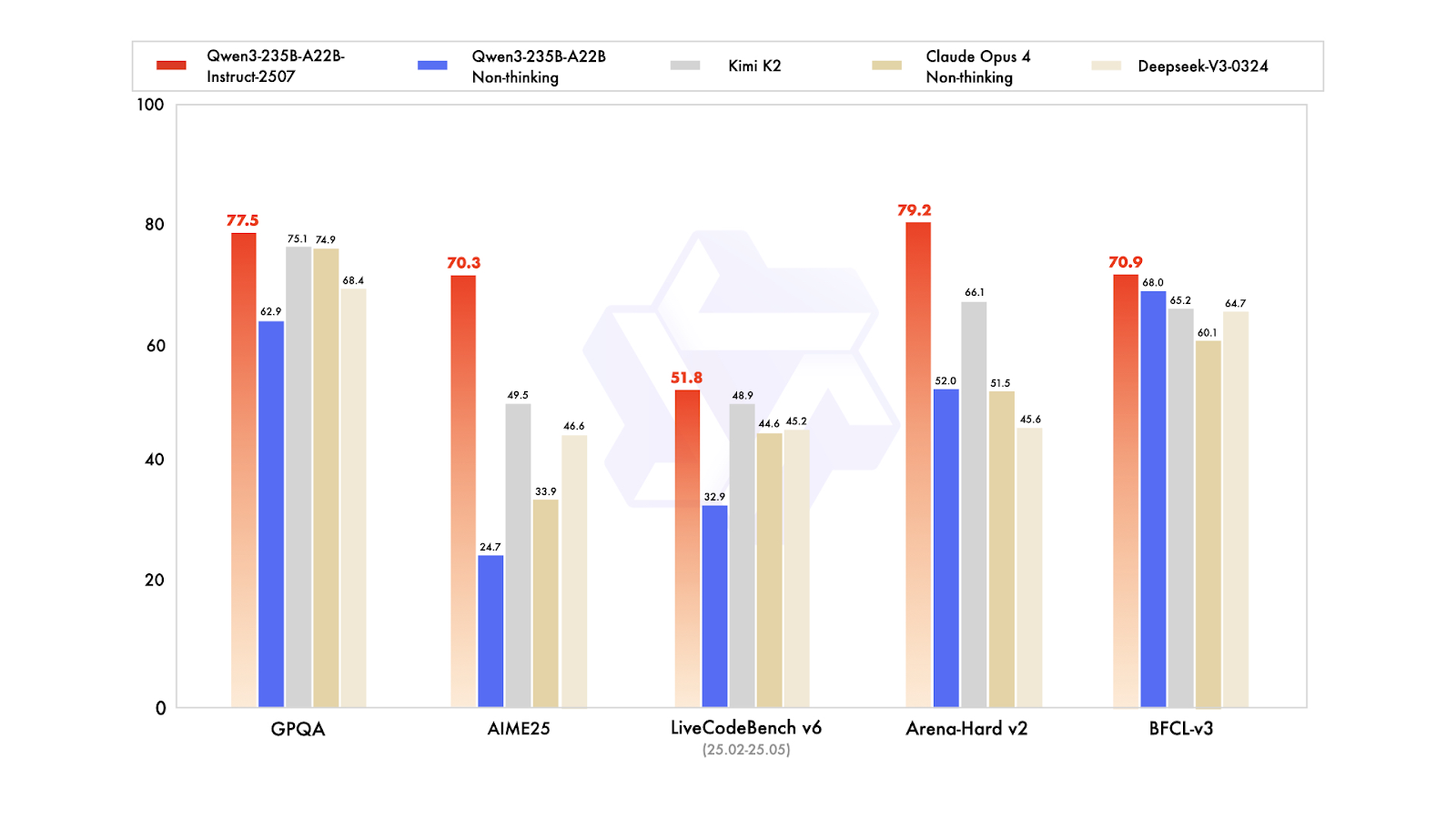
Bản cập nhật Instruct-2507 mới nhất mang đến cải thiện đáng kể về năng lực tổng quát và mở rộng phạm vi kiến thức hiếm gặp trên nhiều ngôn ngữ. Nó cũng cải thiện rõ rệt khả năng căn chỉnh sở thích cho các tác vụ mở và nâng cao chất lượng viết, đặc biệt cho hiểu ngữ cảnh dài trên 256.000 token.
Trên các benchmark công khai, mô hình thể hiện kết quả xuất sắc. Trên thực tế, điều này đưa Instruct-2507 vào nhóm mô hình không-thinking hàng đầu, vượt cả biến thể Qwen3-235B-A22B không-thinking trước đó và các đối thủ dẫn đầu như DeepSeek-V3, GPT-4o, Claude Opus 4 (không-thinking) và Kimi K2.
Bạn có thể tìm hiểu thêm về Qwen3 trong bài viết đầy đủ của chúng tôi.
DeepSeek-V3.2-Exp là phiên bản thử nghiệm, trung gian hướng tới thế hệ tiếp theo của kiến trúc DeepSeek. Nó xây dựng trên V3.1-Terminus và giới thiệu DeepSeek Sparse Attention để tăng hiệu quả huấn luyện và suy luận, đặc biệt trong các kịch bản ngữ cảnh dài. Mục tiêu là cải thiện hiệu suất transformer cho chuỗi kéo dài đồng thời duy trì chất lượng đầu ra theo dòng Terminus.
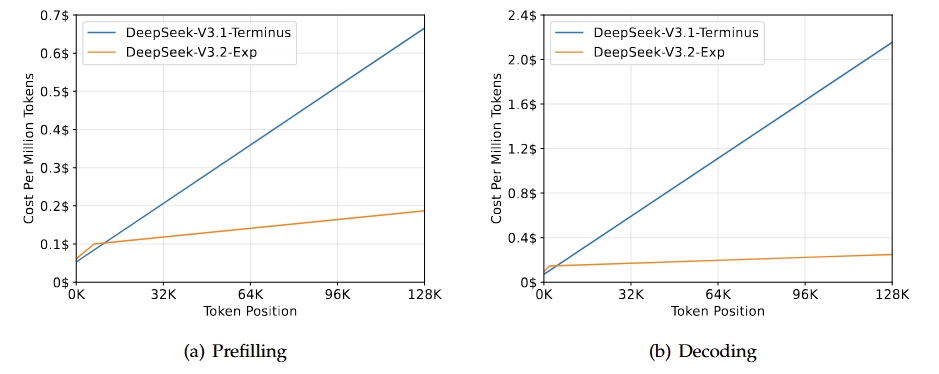
Nguồn: DeepSeek-V3.2-Exp
Kết quả chính của bản phát hành này là nó sánh ngang năng lực tổng thể của V3.1-Terminus đồng thời mang lại cải thiện hiệu quả đáng kể cho các tác vụ ngữ cảnh dài. Đánh giá và phân tích bên thứ ba cho thấy hiệu năng tương đương Terminus, với mức giảm đáng kể chi phí tính toán. Điều này khẳng định attention thưa có thể nâng cao hiệu quả mà không làm suy giảm chất lượng.
Đọc hướng dẫn đầy đủ về DeppSeek-V3.2-Exp của chúng tôi để thực hành một dự án demo.
DeepSeek-R1 đã nhận bản nâng cấp phiên bản nhỏ lên DeepSeek-R1-0528, nâng cao khả năng suy luận và suy diễn thông qua tăng công suất tính toán và tối ưu thuật toán sau huấn luyện. Nhờ đó, có cải thiện đáng kể trên nhiều lĩnh vực, gồm toán học, lập trình và logic tổng quát. Hiệu năng tổng thể nay tiệm cận các hệ thống hàng đầu như O3 và Gemini 2.5 Pro.
Ngoài năng lực thuần túy, bản cập nhật này nhấn mạnh tính hữu dụng thực tiễn với khả năng gọi hàm và quy trình lập trình tốt hơn, phản ánh trọng tâm tạo ra đầu ra đáng tin cậy và hướng tới năng suất.
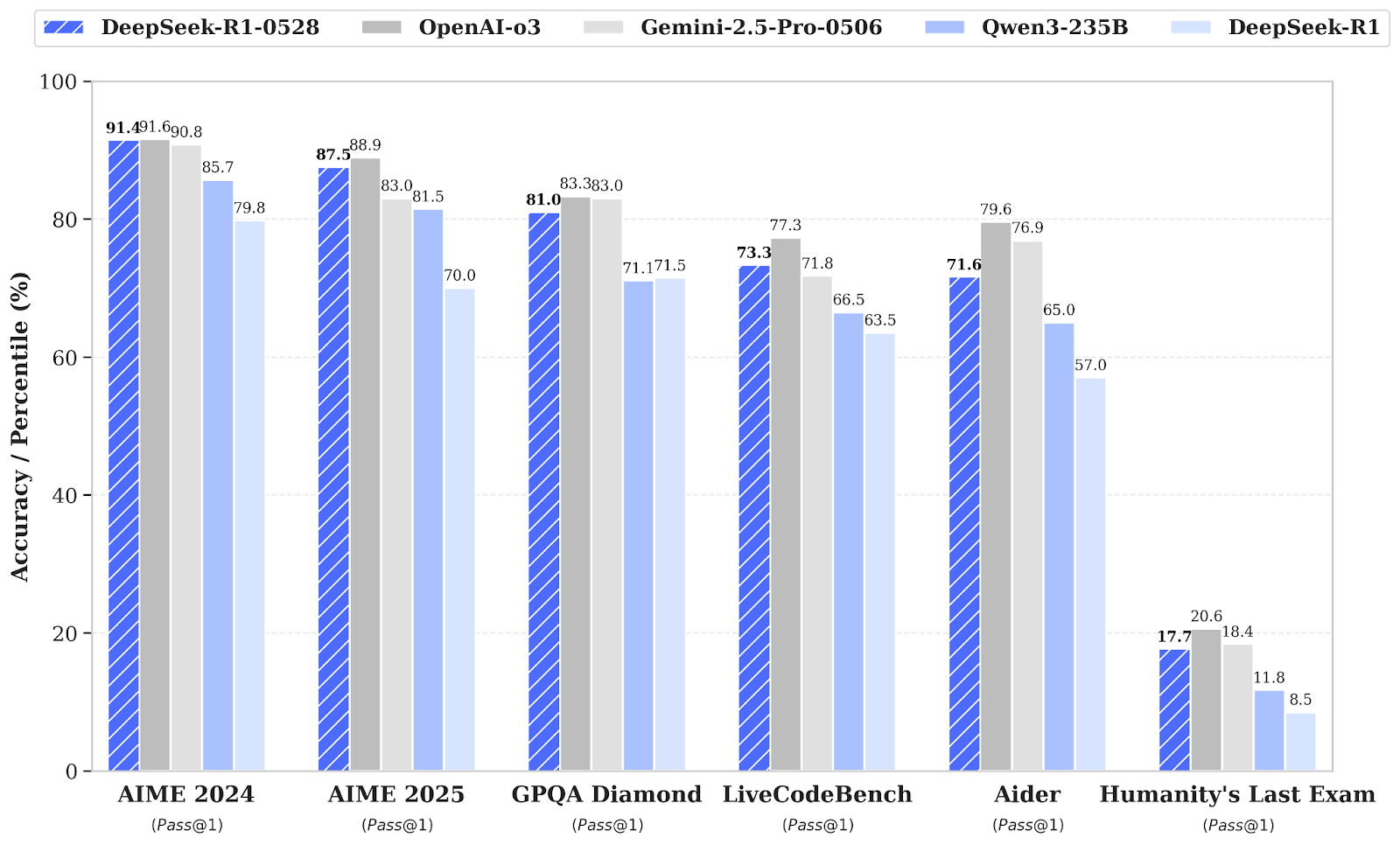
Nguồn: deepseek-ai/DeepSeek-R1-0528
So với phiên bản DeepSeel R1 trước đây, mô hình nâng cấp cho thấy tiến bộ đáng kể trong suy luận phức tạp. Ví dụ, ở kỳ thi AIME 2025, độ chính xác tăng từ 70% lên 87,5%, được hỗ trợ bởi tư duy phân tích sâu hơn (với số token trung bình trên mỗi câu hỏi tăng từ khoảng 12.000 lên 23.000).
Các đánh giá rộng hơn cũng cho thấy xu hướng tích cực ở các lĩnh vực như kiến thức, suy luận và hiệu năng lập trình. Ví dụ gồm cải thiện trên LiveCodeBench, xếp hạng Codeforces, SWE Verified và Aider-Polyglot, cho thấy chiều sâu giải quyết vấn đề tăng và năng lực lập trình thực tế vượt trội.
Apriel-1.5-15b-Thinker là mô hình suy luận đa phương thức trong dòng Apriel SLM của ServiceNow. Nó mang lại hiệu năng cạnh tranh chỉ với 15 tỷ tham số, hướng tới kết quả mức tiên phong trong giới hạn ngân sách một GPU. Mô hình không chỉ bổ sung khả năng suy luận hình ảnh cho phiên bản trước chỉ-văn-bản mà còn đào sâu năng lực suy luận ngôn ngữ.
Là mô hình thứ hai trong chuỗi suy luận, nó đã trải qua quá trình tiền huấn luyện liên tục trên cả miền văn bản và hình ảnh. Giai đoạn sau huấn luyện gồm SFT chỉ-văn-bản, không có SFT riêng cho hình ảnh hay tăng cường học tăng cường. Dù có các hạn chế này, mô hình vẫn đặt mục tiêu chất lượng hàng đầu về suy luận văn bản và hình ảnh trong tầm kích thước của mình.
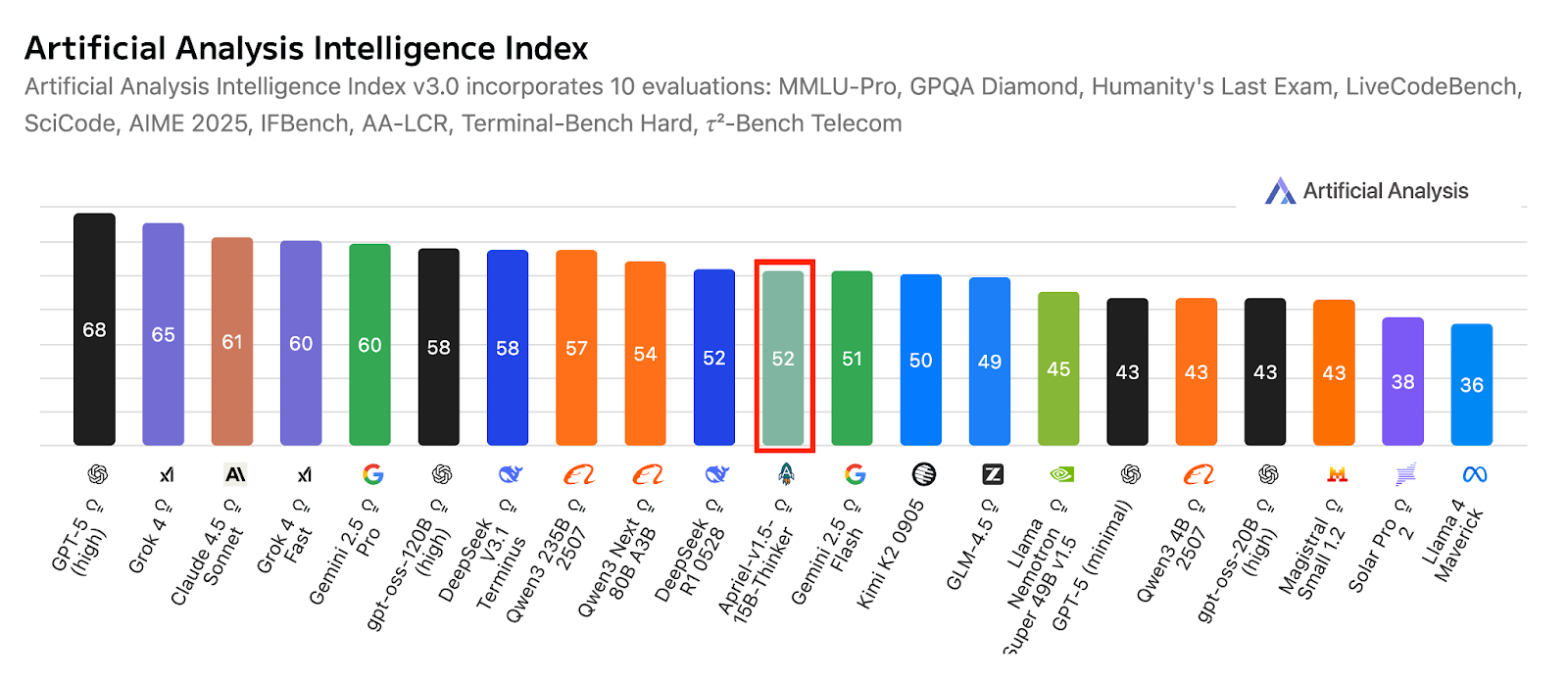
Nguồn: ServiceNow-AI/Apriel-1.5-15b-Thinker
Được thiết kế để chạy trên một GPU, mô hình ưu tiên triển khai thực tế và hiệu quả. Kết quả đánh giá cho thấy mức độ sẵn sàng mạnh mẽ cho ứng dụng thực tế, với điểm chỉ số Artificial Analysis là 52, đưa mô hình vào vị thế cạnh tranh so với các hệ thống lớn hơn nhiều. Điểm số này cũng phản ánh độ bao phủ so với các đối thủ gọn nhẹ và tiên phong hàng đầu, đồng thời duy trì dấu chân mô hình nhỏ phù hợp doanh nghiệp.
Kimi-K2-Instruct-0905 là mô hình mới nhất và tiên tiến nhất trong dòng Kimi K2. Đây là mô hình ngôn ngữ Mixture-of-Experts tiên tiến, với tổng 1 nghìn tỷ tham số và 32 tỷ tham số kích hoạt. Mô hình được thiết kế riêng cho quy trình suy luận cao cấp và lập trình.
K2-Instruct-0905 tăng đáng kể khả năng xử lý tác vụ dài hạn của K2 với cửa sổ ngữ cảnh 256.000 token, tăng từ 128.000 token trước đó. Nó nhằm hỗ trợ các trường hợp tác tử mạnh mẽ, bao gồm chat tăng cường công cụ và trợ lý lập trình. Là bản phát hành chủ lực của dòng K2 Instruct, mô hình tập trung vào trải nghiệm nhà phát triển mạnh và độ tin cậy cho ứng dụng chất lượng sản xuất.
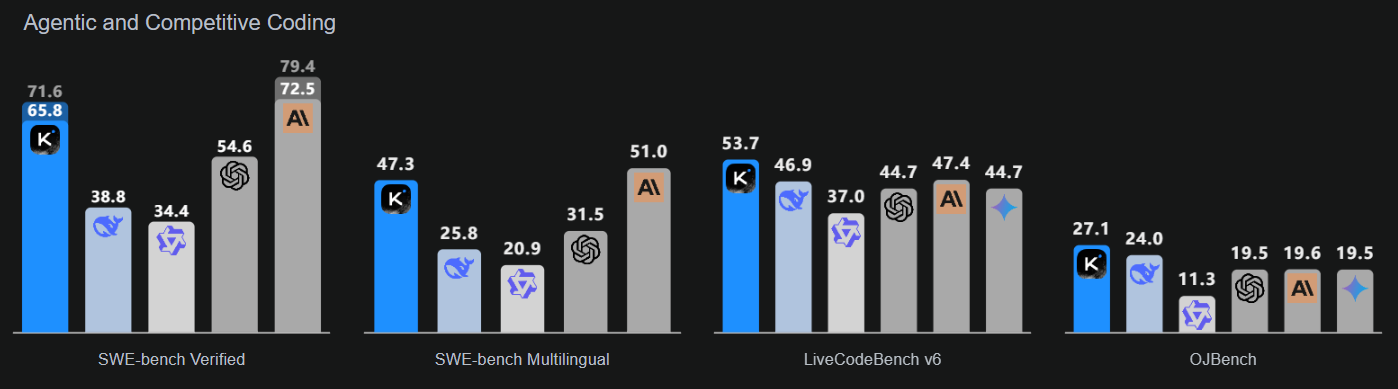
Nguồn: Kimi K2: Open Agentic Intelligence
Mô hình nhấn mạnh ba lĩnh vực chính: trí tuệ lập trình nâng cao cho tác vụ dựa trên tác tử, thể hiện cải thiện rõ rệt trên các benchmark công khai và ứng dụng thực tế; giao diện người dùng cải tiến, nâng cao cả thẩm mỹ và chức năng; và độ dài ngữ cảnh 256.000 token cho phép lập kế hoạch và vòng lặp chỉnh sửa mở rộng hơn.
Llama-3_3-Nemotron-Super-49B-v1_5 là mô hình 49 tỷ tham số nâng cấp trong dòng Nemotron của NVIDIA, được dẫn xuất từ Llama-3.3-70B-Instruct của Meta. Nó được thiết kế chuyên biệt như một mô hình suy luận cho chat căn chỉnh với con người và các tác vụ tác tử, như tạo sinh tăng cường truy xuất (RAG) và gọi công cụ.
Mô hình đã trải qua giai đoạn sau huấn luyện để tăng cường khả năng suy luận, căn chỉnh sở thích và sử dụng công cụ. Nó cũng hỗ trợ quy trình ngữ cảnh dài lên tới 128.000 token, phù hợp với các ứng dụng phức tạp, nhiều bước.
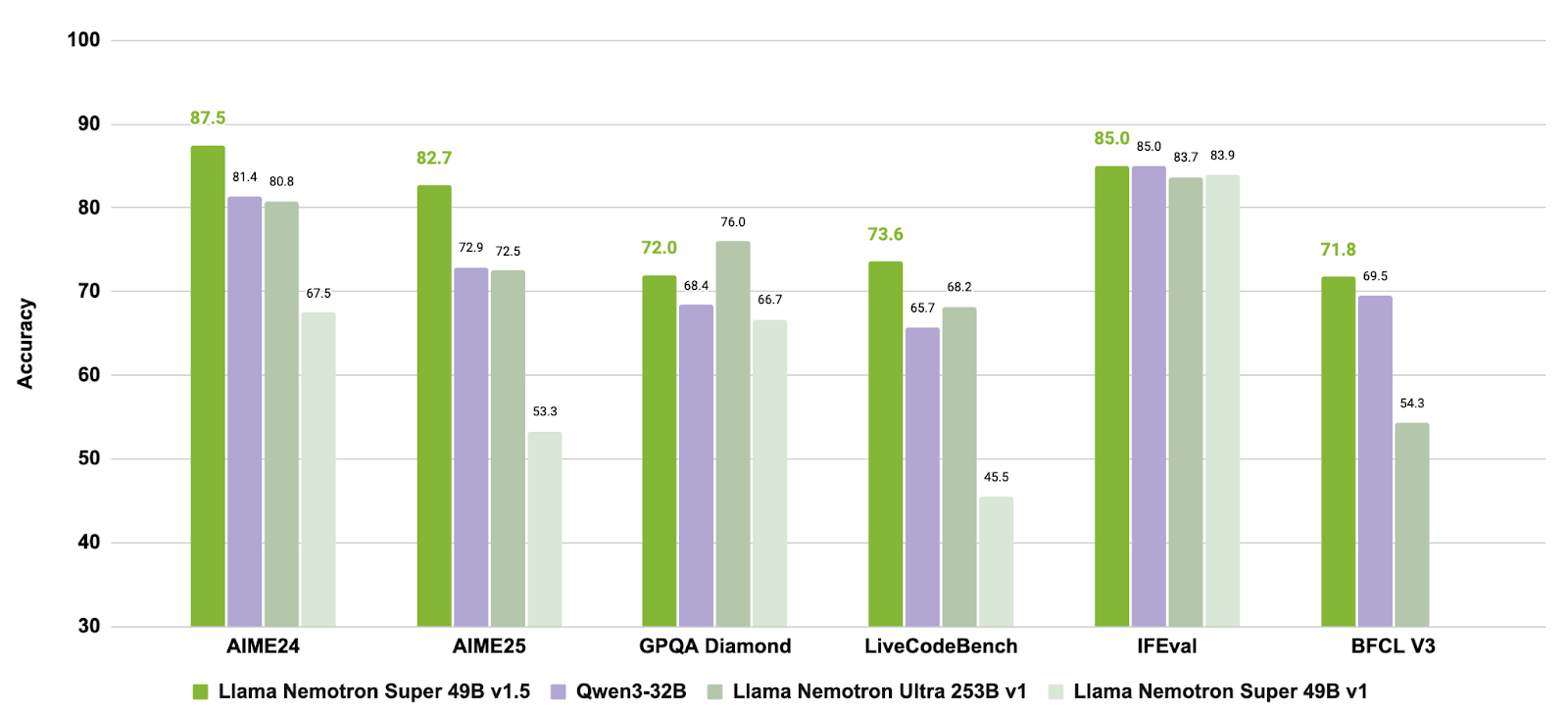
Nguồn: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Bằng cách kết hợp giai đoạn sau huấn luyện nhắm mục tiêu cho suy luận và hành vi tác tử với hỗ trợ tác vụ ngữ cảnh dài, Llama-3.3-Nemotron-Super-49B-v1.5 mang lại giải pháp cân bằng cho nhà phát triển cần năng lực suy luận tiên tiến và sử dụng công cụ vững vàng mà không đánh đổi hiệu suất chạy.
Mistral-Small-3.2-24B-Instruct-2506 là bản nâng cấp đáng kể so với Mistral-Small-3.1-24B-Instruct-2503, cải thiện tuân thủ hướng dẫn, giảm lỗi lặp và cung cấp mẫu gọi hàm vững hơn, đồng thời duy trì hoặc hơi cải thiện năng lực tổng thể. Là mô hình chỉ dẫn 24B tham số, nó được hỗ trợ rộng rãi trên nhiều nền tảng, bao gồm marketplace của AWS, nơi ghi nhận khả năng tuân thủ hướng dẫn tốt hơn.
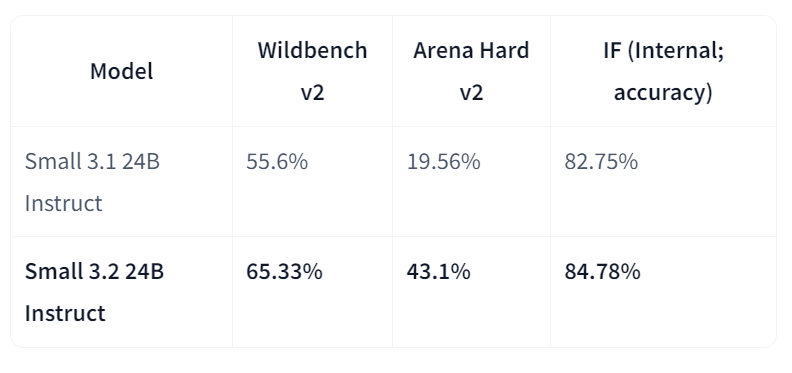
Nguồn: mistralai/Mistral-Small-3.2-24B-Instruct-2506
Trong so sánh trực tiếp với phiên bản 3.1, Small-3.2 cho thấy tiến bộ rõ rệt về chất lượng và độ tin cậy của trợ lý. Nó tăng hiệu năng tuân thủ hướng dẫn trên Wildbench v2 (từ 55,6% lên 65,33%) và Arena Hard v2 (từ 19,56% lên 43,1%), trong khi độ chính xác tuân thủ hướng dẫn nội bộ tăng từ 82,75% lên 84,78%. Lỗi lặp trên các prompt khó giảm một nửa (từ 2,11% xuống 1,29%). Trong khi đó, hiệu năng STEM vẫn tương đương, với MATH ở mức 69,42% và HumanEval+ Pass@5 ở 92,90%.
Trong bảng dưới đây, bạn có thể xem so sánh các mô hình hàng đầu:
| Mô hình | Thế mạnh chính | Nâng cấp / Tính năng đáng chú ý |
|---|---|---|
| GLM 4.6 | Suy luận mạnh, quy trình tác tử và khả năng lập trình | Mở rộng cửa sổ ngữ cảnh từ 128K → 200K; cải thiện benchmark so với GLM-4.5 và DeepSeek-V3.1 |
| gpt-oss-120B | Mô hình GPT open-weight cho suy luận nâng cao và tác vụ tác tử | Độ sâu suy luận cấu hình được, truy cập chain-of-thought, gọi hàm và định dạng phản hồi harmony |
| Qwen3-235B-Instruct-2507 | Đa ngôn ngữ, suy luận và tuân thủ hướng dẫn chính xác cao | Ngữ cảnh 1M+ token, văn phong căn chỉnh sở thích, vượt GPT-4o và Claude Opus 4 (không-thinking) |
| DeepSeek-V3.2-Exp | Xử lý ngữ cảnh dài hiệu quả nhờ attention thưa | Đạt hiệu năng V3.1 với chi phí tính toán giảm; tối ưu hiệu suất transformer |
| DeepSeek-R1-0528 | Suy luận, toán và lập trình nâng cao | Cải thiện 17,5% trên AIME 2025; tăng chiều sâu phân tích và độ tin cậy lập trình |
| Apriel-1.5-15B-Thinker | Suy luận đa phương thức (văn bản + hình ảnh) trên một GPU | Tiền huấn luyện liên tục trên văn bản và hình ảnh; suy luận mức tiên phong cho kích thước gọn |
| Kimi-K2-Instruct-0905 | Suy luận cao cấp và quy trình lập trình dựa trên tác tử | Ngữ cảnh 256K token, trải nghiệm nhà phát triển tốt hơn và hỗ trợ tác vụ tăng cường công cụ |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Mô hình cân bằng giữa suy luận và sử dụng công cụ | NVIDIA tinh chỉnh cho RAG và ứng dụng tác tử; hỗ trợ ngữ cảnh dài tới 128K token |
| Mistral-Small-3.2-24B-Instruct-2506 | Tuân thủ hướng dẫn gọn nhẹ và đáng tin cậy | Giảm lỗi lặp (−50%) và tăng mạnh trên WildBench v2 và Arena Hard v2 |
Không gian LLM mã nguồn mở đang mở rộng nhanh chóng. Ngày nay, có nhiều LLM mã nguồn mở hơn LLM độc quyền, và khoảng cách hiệu năng có thể sớm được thu hẹp khi các nhà phát triển trên toàn cầu cùng hợp tác để nâng cấp các LLM hiện tại và thiết kế những mô hình tối ưu hơn.
Trong bối cảnh sôi động và thú vị này, có thể khó chọn đúng LLM mã nguồn mở cho mục đích của bạn. Dưới đây là một số yếu tố bạn nên cân nhắc trước khi chọn một LLM mã nguồn mở cụ thể:
LLM mã nguồn mở không chỉ dành cho dự án cá nhân hay sở thích. Khi cuộc cách mạng AI sinh sinh tiếp tục tăng tốc, các doanh nghiệp đang nhận ra tầm quan trọng sống còn của việc hiểu và triển khai những công cụ này. LLM đã trở thành nền tảng cho các ứng dụng AI tiên tiến, từ chatbot đến các tác vụ xử lý dữ liệu phức tạp. Đảm bảo đội ngũ của bạn thành thạo công nghệ AI và LLM không còn chỉ là lợi thế cạnh tranh—mà là điều cần thiết để bảo đảm tương lai cho doanh nghiệp.
Nếu bạn là trưởng nhóm hoặc chủ doanh nghiệp muốn trao quyền cho đội ngũ với chuyên môn AI và LLM, DataCamp for Business cung cấp các chương trình đào tạo toàn diện giúp nhân viên của bạn đạt được kỹ năng cần thiết để tận dụng những công cụ mạnh mẽ này. Chúng tôi cung cấp:
Đầu tư vào nâng cao kỹ năng AI và LLM không chỉ tăng cường năng lực đội ngũ mà còn đặt doanh nghiệp bạn ở tuyến đầu đổi mới, cho phép khai thác trọn vẹn tiềm năng của các công nghệ mang tính chuyển đổi này. Liên hệ với đội ngũ của chúng tôi để yêu cầu bản demo và bắt đầu xây dựng lực lượng lao động sẵn sàng cho AI ngay hôm nay.
LLM mã nguồn mở đang ở một làn sóng đầy phấn khích. Với tốc độ tiến hóa nhanh, dường như không gian AI sinh sinh sẽ không nhất thiết bị độc chiếm bởi những “ông lớn” có đủ khả năng xây dựng và vận hành các công cụ mạnh mẽ này.
Chúng ta mới chỉ xem tám LLM mã nguồn mở, nhưng con số thực tế lớn hơn nhiều và đang tăng nhanh. Tại DataCamp, chúng tôi sẽ tiếp tục cung cấp thông tin về tin tức mới nhất trong lĩnh vực LLM, mang đến các khóa học, bài viết và hướng dẫn về LLM. Trước mắt, hãy xem danh sách tài liệu đã chọn của chúng tôi:
Bắt đầu hành trình AI của bạn ngay hôm nay!
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút