
Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
Ada banyak manfaat jangka pendek dan jangka panjang saat memilih LLM open-source dibandingkan LLM proprietari. Di bawah ini, Anda dapat menemukan daftar alasan paling meyakinkan:
Salah satu kekhawatiran terbesar saat menggunakan LLM proprietari adalah risiko kebocoran data atau akses tidak sah ke data sensitif oleh penyedia LLM. Memang, sudah ada beberapa kontroversi terkait dugaan penggunaan data pribadi dan rahasia untuk tujuan pelatihan.
Dengan menggunakan LLM open-source, perusahaan akan sepenuhnya bertanggung jawab atas perlindungan data pribadi, karena kendali penuh tetap berada pada mereka.
Kebanyakan LLM proprietari memerlukan lisensi untuk menggunakannya. Dalam jangka panjang, ini bisa menjadi pengeluaran besar yang mungkin tidak terjangkau bagi sebagian perusahaan, terutama UKM. Hal ini tidak berlaku pada LLM open-source, karena biasanya gratis digunakan.
Namun, penting dicatat bahwa menjalankan LLM membutuhkan sumber daya besar, bahkan hanya untuk inferensi, yang berarti Anda umumnya harus membayar layanan cloud atau infrastruktur yang bertenaga.
Perusahaan yang memilih LLM open-source akan memiliki akses ke cara kerja LLM, termasuk kode sumber, arsitektur, data pelatihan, serta mekanisme pelatihan dan inferensi. Transparansi ini adalah langkah awal untuk penelaahan sekaligus kustomisasi.
Karena LLM open-source dapat diakses semua orang, termasuk kode sumbernya, perusahaan yang menggunakannya dapat menyesuaikan model untuk kasus penggunaan spesifik mereka.
Gerakan open-source menjanjikan demokratisasi penggunaan dan akses terhadap teknologi LLM dan AI generatif. Memungkinkan pengembang menelaah cara kerja internal LLM adalah kunci bagi pengembangan teknologi ini ke depan. Dengan menurunkan hambatan masuk bagi coder di seluruh dunia, LLM open-source dapat mendorong inovasi dan menyempurnakan model dengan mengurangi bias serta meningkatkan akurasi dan performa keseluruhan.
Seiring populernya LLM, para peneliti dan pengawas lingkungan mengangkat kekhawatiran tentang jejak karbon dan konsumsi air yang diperlukan untuk menjalankan teknologi ini. LLM proprietari jarang memublikasikan informasi tentang sumber daya yang dibutuhkan untuk melatih dan mengoperasikan LLM, maupun jejak lingkungan yang terkait.
Dengan LLM open-source, peneliti memiliki lebih banyak peluang untuk mengetahui informasi ini, yang dapat membuka pintu bagi perbaikan baru yang dirancang untuk mengurangi jejak lingkungan AI.
GLM-4.6 adalah large language model generasi berikutnya, penerus GLM-4.5. Model ini dirancang untuk meningkatkan alur kerja agentik, menyediakan bantuan coding yang tangguh, memfasilitasi penalaran tingkat lanjut, dan menghasilkan bahasa alami berkualitas tinggi. Model ini ditujukan untuk lingkungan riset dan produksi, dengan fokus pada pemahaman konteks panjang, inferensi berbantuan alat, dan penulisan yang lebih selaras dengan preferensi pengguna.
Sumber:zai-org/GLM-4.6
Dibanding GLM-4.5, GLM-4.6 memperkenalkan beberapa peningkatan kunci: jendela konteks diperluas dari 128K menjadi 200K token, memungkinkan tugas agentik yang lebih kompleks. Performa coding juga ditingkatkan, menghasilkan skor benchmark lebih tinggi dan hasil yang lebih kuat dalam aplikasi dunia nyata.
GLM-4.6 menunjukkan peningkatan jelas pada delapan benchmark publik terkait agen, penalaran, dan coding, melampaui GLM-4.5, dan menunjukkan keunggulan kompetitif atas model terkemuka seperti DeepSeek-V3.1-Terminus dan Claude Sonnet 4.
gpt-oss-120b adalah puncak seri gpt-oss—model open-weight dari OpenAI yang dirancang untuk penalaran tingkat lanjut, tugas agentik, dan alur kerja pengembang yang serbaguna. Seri ini mencakup dua versi: gpt-oss-120b, yang ditujukan untuk kasus penggunaan general-purpose setingkat produksi yang memerlukan penalaran tingkat tinggi dan dapat berjalan pada satu GPU 80GB (menampilkan 117 miliar parameter, dengan 5,1 miliar aktif); dan gpt-oss-20b, yang dioptimalkan untuk latensi lebih rendah dan deployment lokal atau spesialis (dengan 21 miliar parameter dan 3,6 miliar aktif). Kedua model dilatih menggunakan format respons harmony dan sebaiknya digunakan dengan kerangka kerja harmony agar berfungsi efektif.
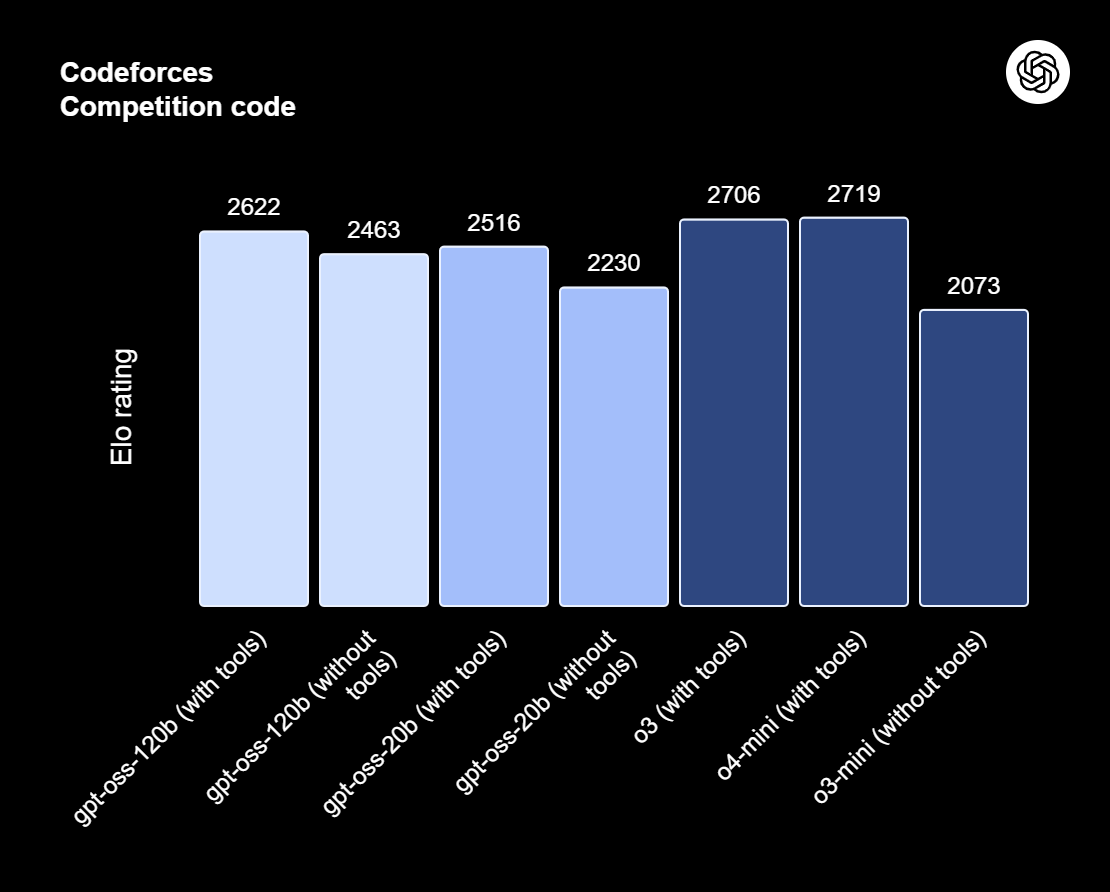
Sumber: Introducing gpt-oss | OpenAI
gpt-oss-120b juga menawarkan upaya penalaran yang dapat dikonfigurasi: rendah, sedang, atau tinggi, untuk menyeimbangkan kedalaman dan latensi. Model ini menyediakan akses penuh chain-of-thought untuk debugging dan audit. Model dapat di-fine-tune dan hadir dengan kapabilitas agentik bawaan, seperti function calling, penelusuran web, eksekusi kode Python, dan keluaran terstruktur.
Berkat kuantisasi MXFP4 pada bobot MoE, gpt-oss-120b dapat dijalankan pada satu GPU 80GB, sementara gpt-oss-20b dapat berjalan dalam lingkungan 16GB. Baca artikel kami tentang 10 cara mengakses GPT-OSS 120B secara gratis.
Qwen3-235B-A22B-Instruct-2507 adalah model andalan non-thinking dalam keluarga Qwen3-MoE, dirancang untuk kepatuhan instruksi presisi tinggi, penalaran logis yang ketat, pemahaman teks multibahasa, matematika, sains, coding, penggunaan alat, dan tugas yang memerlukan konteks sangat panjang. Ini adalah model bahasa kausal Mixture of Experts (MoE) dengan total 235 miliar parameter, 22 miliar parameter aktif (menggunakan 128 expert dengan 8 aktif sekaligus). Model terdiri dari 94 layer, menyertakan mekanisme GQA dengan 64 query head dan 4 key-value head, serta memiliki jendela konteks native 262.000 token, yang dapat diperluas hingga sekitar 1,01 juta token.
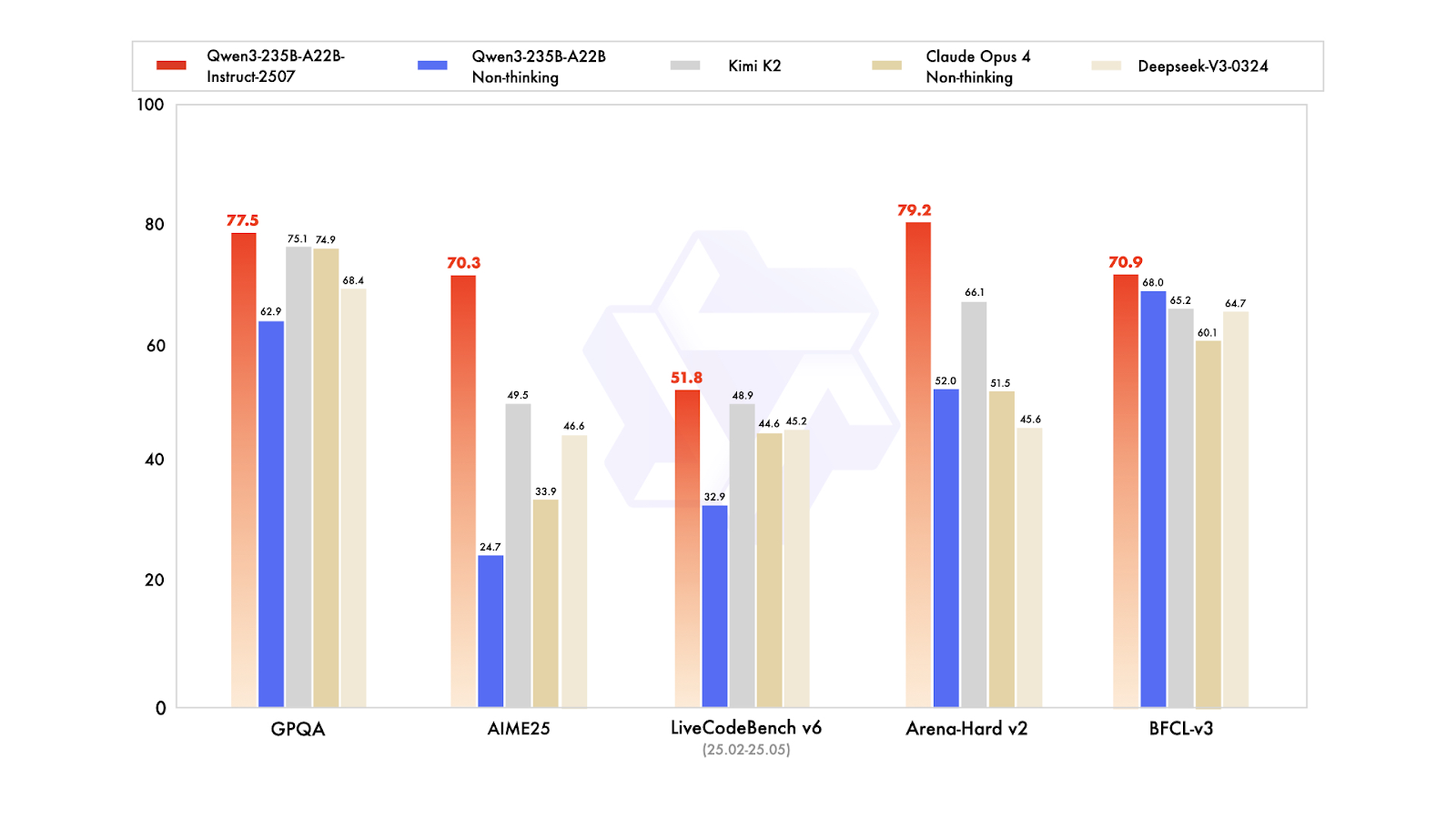
Pembaruan Instruct-2507 terbaru menghadirkan peningkatan signifikan pada kapabilitas umum dan memperluas cakupan pengetahuan long-tail di berbagai bahasa. Model ini juga menawarkan penyelarasan preferensi yang jauh lebih baik untuk tugas terbuka dan meningkatkan kualitas penulisan, terutama untuk pemahaman konteks panjang 256.000+.
Pada benchmark publik, performanya luar biasa. Dalam praktik, ini menempatkan Instruct-2507 sebagai model non-thinking papan atas, melampaui varian non-thinking Qwen3-235B-A22B sebelumnya dan para pesaing utama seperti DeepSeek-V3, GPT-4o, Claude Opus 4 (non-thinking), dan Kimi K2.
Anda bisa mempelajari lebih lanjut tentang Qwen3 di artikel lengkap kami.
DeepSeek-V3.2-Exp adalah versi eksperimental menengah yang mengarah ke generasi berikutnya dari arsitektur DeepSeek. Model ini dibangun di atas V3.1-Terminus dan memperkenalkan DeepSeek Sparse Attention untuk meningkatkan efisiensi pelatihan dan inferensi, khususnya pada skenario konteks panjang. Model ini bertujuan meningkatkan efisiensi transformer untuk urutan panjang sekaligus mempertahankan kualitas keluaran yang diharapkan dari lini Terminus.
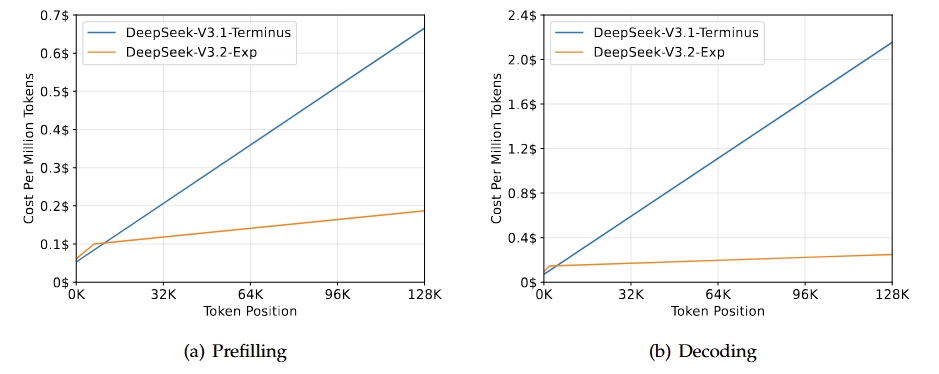
Sumber: DeepSeek-V3.2-Exp
Hasil utama rilis ini adalah kesepadanan kapabilitas keseluruhan dengan V3.1-Terminus sambil memberikan peningkatan efisiensi signifikan untuk tugas konteks panjang. Evaluasi dan analisis pihak ketiga menunjukkan performa yang sebanding dengan Terminus, dengan pengurangan biaya komputasi yang nyata. Ini menegaskan bahwa sparse attention dapat meningkatkan efisiensi tanpa mengorbankan kualitas.
Baca panduan lengkap DeepSeek-V3.2-Exp kami untuk mengerjakan proyek demo.
DeepSeek-R1 menerima peningkatan versi minor menjadi DeepSeek-R1-0528, yang meningkatkan kemampuan penalaran dan inferensinya melalui peningkatan daya komputasi dan optimasi algoritmik pasca-pelatihan. Hasilnya, terjadi peningkatan signifikan di berbagai area, termasuk matematika, pemrograman, dan logika umum. Performa keseluruhan kini lebih mendekati sistem terdepan seperti O3 dan Gemini 2.5 Pro.
Selain kapabilitas mentah, pembaruan ini menekankan kegunaan praktis dengan function calling dan alur kerja coding yang lebih baik, mencerminkan fokus pada keluaran yang lebih andal dan berorientasi produktivitas.
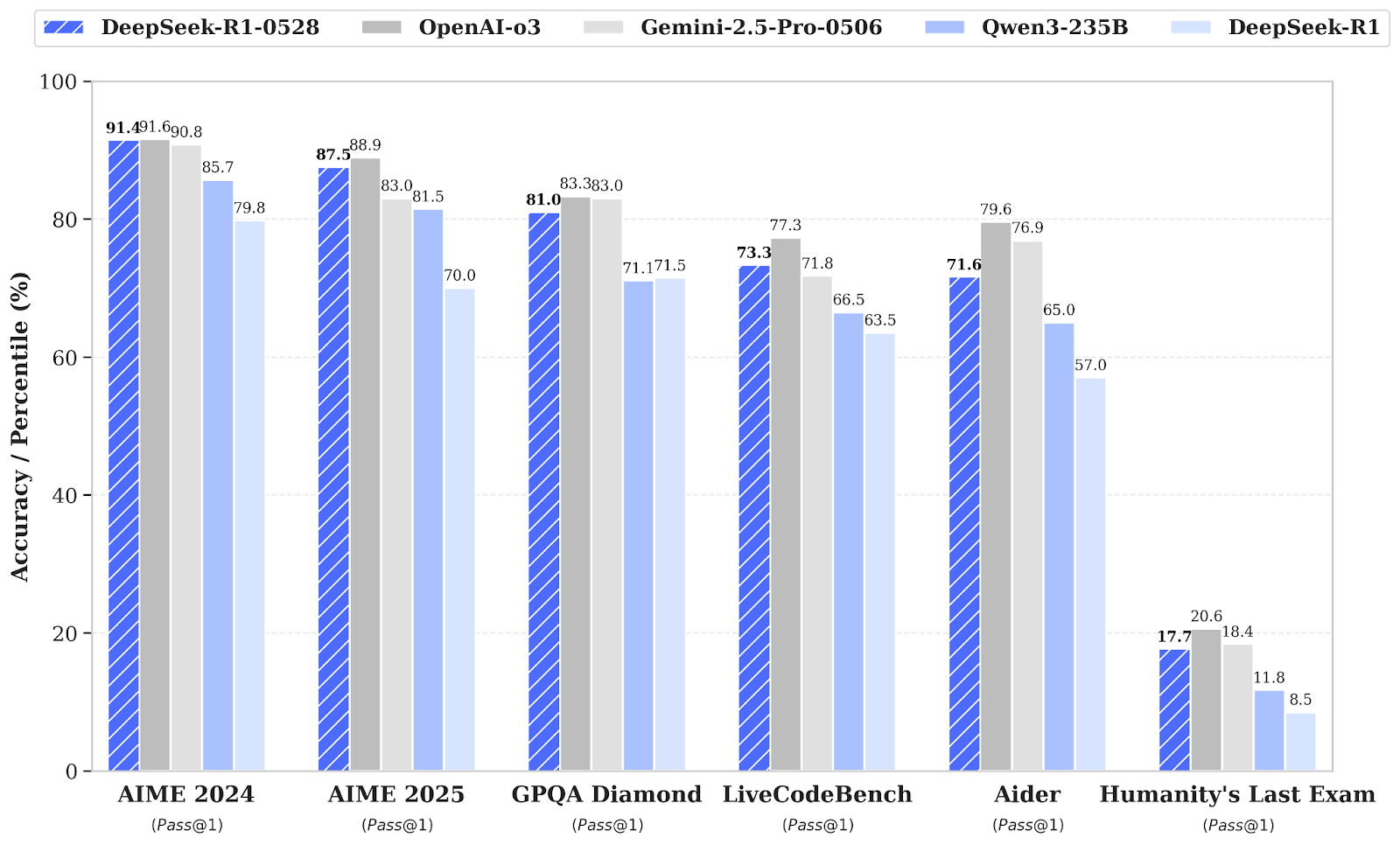
Sumber: deepseek-ai/DeepSeek-R1-0528
Dibanding versi DeepSeek R1 sebelumnya, model yang ditingkatkan menunjukkan kemajuan substansial dalam penalaran kompleks. Misalnya, pada ujian AIME 2025, akurasi meningkat dari 70% menjadi 87,5%, didukung pemikiran analitis yang lebih dalam (dengan rata-rata jumlah token per pertanyaan naik dari sekitar 12.000 menjadi 23.000).
Evaluasi yang lebih luas juga menunjukkan tren positif di area seperti pengetahuan, penalaran, dan performa coding. Contohnya termasuk peningkatan pada LiveCodeBench, peringkat Codeforces, SWE Verified, dan Aider-Polyglot, yang menunjukkan kedalaman pemecahan masalah yang lebih baik dan kapabilitas coding dunia nyata yang unggul.
Apriel-1.5-15b-Thinker adalah model penalaran multimodal dalam seri Apriel SLM milik ServiceNow. Model ini memberikan performa kompetitif hanya dengan 15 miliar parameter, menargetkan hasil setara frontier dalam batas anggaran satu GPU. Model ini tidak hanya menambahkan kapabilitas penalaran gambar ke model teks-saja sebelumnya, tetapi juga memperdalam kemampuan penalaran tekstualnya.
Sebagai model kedua dalam seri penalaran, model ini menjalani continual pretraining ekstensif pada domain teks dan gambar. Tahap pasca-pelatihan melibatkan supervised fine-tuning (SFT) khusus teks, tanpa SFT khusus gambar atau reinforcement learning. Meski ada keterbatasan ini, model menargetkan kualitas tertinggi dalam penalaran teks dan gambar untuk ukurannya.
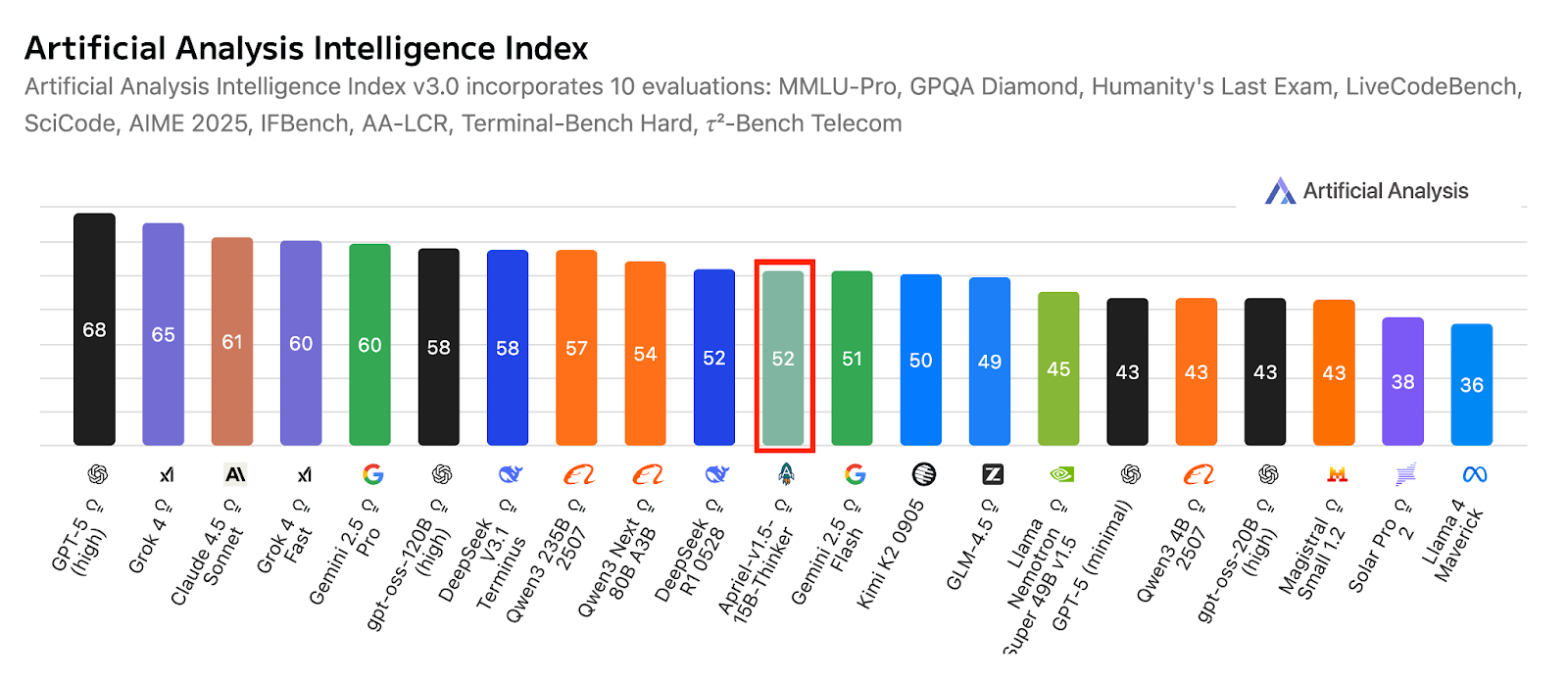
Sumber: ServiceNow-AI/Apriel-1.5-15b-Thinker
Dirancang untuk berjalan pada satu GPU, model ini memprioritaskan deployment praktis dan efisiensi. Hasil evaluasi menunjukkan kesiapan kuat untuk aplikasi dunia nyata, dengan skor indeks Artificial Analysis sebesar 52, menempatkan model ini kompetitif melawan sistem yang jauh lebih besar. Skor ini juga mencerminkan cakupannya dibandingkan rekan ringkas dan frontier terkemuka, sembari mempertahankan jejak model kecil yang cocok untuk kebutuhan enterprise.
Kimi-K2-Instruct-0905 adalah model terbaru dan tercanggih dalam jajaran Kimi K2. Ini adalah model bahasa Mixture-of-Experts mutakhir dengan total 1 triliun parameter dan 32 miliar parameter aktif. Model ini dirancang khusus untuk alur kerja penalaran tingkat tinggi dan coding.
K2-Instruct-0905 secara signifikan meningkatkan kemampuan K2 dalam menangani tugas jangka panjang dengan jendela konteks 256.000 token, meningkat dari 128.000 token sebelumnya. Model ini bertujuan mendukung kasus penggunaan berbasis agen yang kuat, termasuk chat berbantuan alat dan bantuan kode. Sebagai rilis andalan seri K2 Instruct, model ini berfokus pada ergonomi pengembang yang baik dan keandalan untuk aplikasi berkualitas produksi.
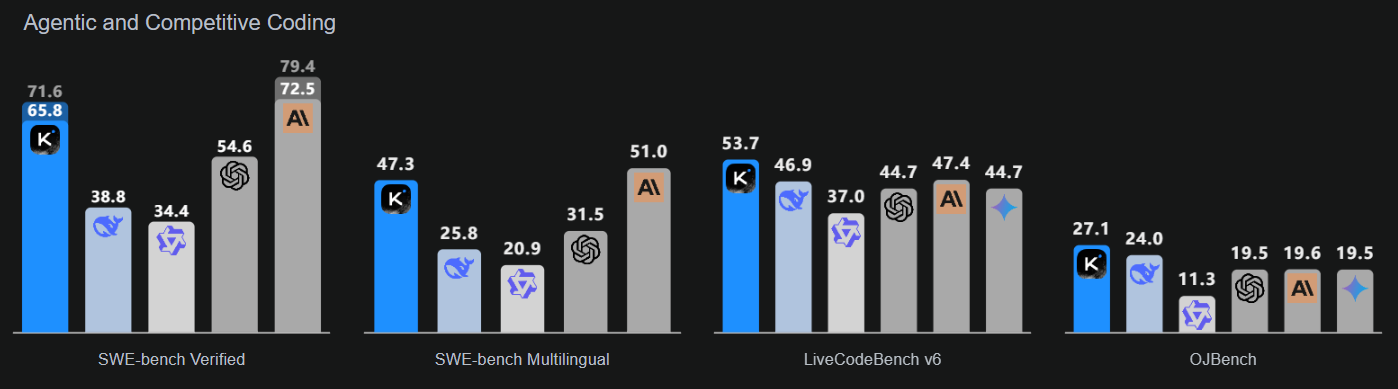
Sumber: Kimi K2: Open Agentic Intelligence
Model ini menekankan tiga area kunci: kecerdasan coding yang ditingkatkan untuk tugas berbasis agen, yang menunjukkan peningkatan jelas pada benchmark publik dan aplikasi dunia nyata; antarmuka pengguna yang lebih baik yang meningkatkan estetika dan fungsionalitas; serta panjang konteks 256.000 token yang diperluas yang memungkinkan perencanaan dan siklus penyuntingan yang lebih luas.
Llama-3_3-Nemotron-Super-49B-v1_5 adalah model 49 miliar parameter yang ditingkatkan dalam lini Nemotron NVIDIA, diturunkan dari Llama-3.3-70B-Instruct milik Meta. Model ini secara khusus dirancang sebagai model penalaran untuk chat sejalan preferensi manusia dan tugas agentik, seperti retrieval-augmented generation (RAG) dan pemanggilan alat.
Model ini menjalani pasca-pelatihan untuk meningkatkan kemampuan penalaran, penyelarasan preferensi, dan penggunaan alat. Model juga mendukung alur kerja konteks panjang hingga 128.000 token, sehingga cocok untuk aplikasi kompleks bertahap banyak.
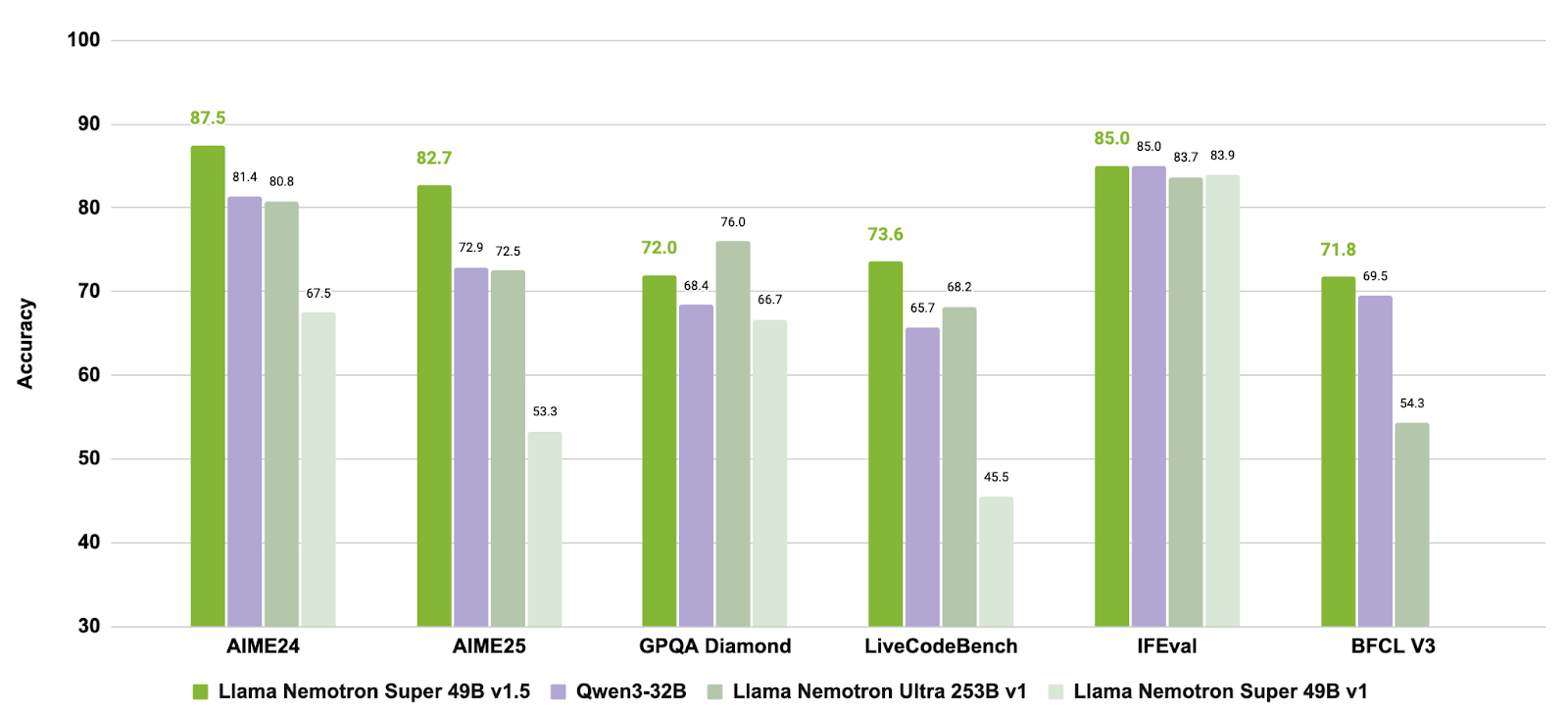
Sumber: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Dengan menggabungkan pasca-pelatihan terarah untuk penalaran dan perilaku agen serta dukungan tugas konteks panjang, Llama-3.3-Nemotron-Super-49B-v1.5 menyediakan solusi seimbang bagi pengembang yang membutuhkan kapabilitas penalaran tingkat lanjut dan penggunaan alat yang tangguh tanpa mengorbankan efisiensi runtime.
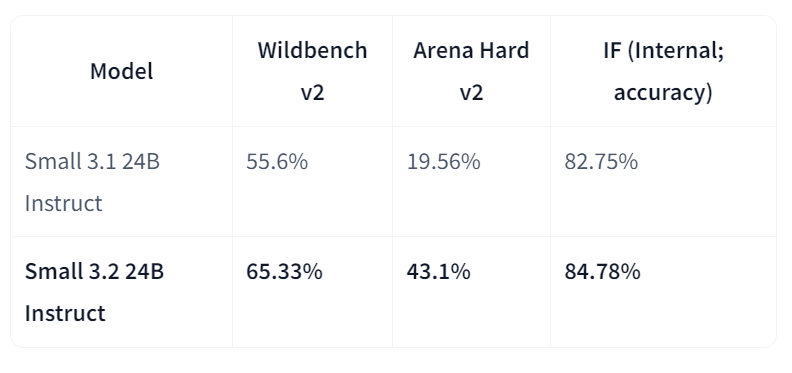
Mistral-Small-3.2-24B-Instruct-2506 adalah peningkatan signifikan atas Mistral-Small-3.1-24B-Instruct-2503, meningkatkan kepatuhan instruksi, mengurangi kesalahan repetisi, dan menyediakan templat function calling yang lebih andal, sembari mempertahankan atau sedikit meningkatkan kapabilitas keseluruhan. Sebagai model instruct 24B parameter, model ini mudah diakses di berbagai platform, termasuk marketplace AWS, yang menyoroti peningkatan kepatuhan instruksi.
Sumber: mistralai/Mistral-Small-3.2-24B-Instruct-2506
Dalam perbandingan langsung dengan versi 3.1, Small-3.2 menunjukkan peningkatan jelas pada kualitas dan keandalan asisten. Performa mengikuti instruksi naik pada Wildbench v2 (dari 55,6% menjadi 65,33%) dan Arena Hard v2 (dari 19,56% menjadi 43,1%), sementara akurasi internal mengikuti instruksi meningkat dari 82,75% menjadi 84,78%. Kegagalan repetisi pada prompt yang menantang berkurang setengahnya (dari 2,11% menjadi 1,29%). Sementara itu, performa STEM tetap sebanding, dengan MATH di 69,42%, dan HumanEval+ Pass@5 di 92,90%.
Pada tabel di bawah, Anda dapat melihat perbandingan model-model teratas:
| Model | Keunggulan Utama | Pembaruan / Fitur Menonjol |
|---|---|---|
| GLM 4.6 | Penalaran kuat, alur kerja agentik, dan kapabilitas coding | Jendela konteks diperluas dari 128K → 200K; performa benchmark membaik vs. GLM-4.5 dan DeepSeek-V3.1 |
| gpt-oss-120B | Model GPT open-weight untuk penalaran lanjut dan tugas agentik | Kedalaman penalaran yang dapat dikonfigurasi, akses chain-of-thought, function calling, dan format respons harmony |
| Qwen3-235B-Instruct-2507 | Penalaran multibahasa presisi tinggi dan kepatuhan instruksi | Konteks 1M+ token, penulisan selaras preferensi, melampaui GPT-4o dan Claude Opus 4 (non-thinking) |
| DeepSeek-V3.2-Exp | Pemrosesan konteks panjang yang efisien lewat sparse attention | Menyamai performa V3.1 dengan komputasi berkurang; efisiensi transformer dioptimalkan |
| DeepSeek-R1-0528 | Penalaran lanjut, kemampuan matematika dan pemrograman | Peningkatan 17,5% pada AIME 2025; kedalaman analitis dan keandalan coding yang ditingkatkan |
| Apriel-1.5-15B-Thinker | Penalaran multimodal (teks + gambar) pada satu GPU | Continual pretraining lintas teks dan gambar; penalaran setara frontier untuk ukuran model ringkas |
| Kimi-K2-Instruct-0905 | Penalaran tingkat tinggi dan alur kerja coding berbasis agen | Konteks 256K token, ergonomi pengembang yang lebih baik, dan dukungan tugas berbantuan alat |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Model seimbang untuk penalaran dan penggunaan alat | Disetel NVIDIA untuk aplikasi RAG dan agentik; dukungan konteks panjang hingga 128K token |
| Mistral-Small-3.2-24B-Instruct-2506 | Kepatuhan instruksi yang ringkas dan andal | Kesalahan repetisi berkurang (−50%) dan peningkatan besar pada WildBench v2 dan Arena Hard v2 |
Ranah LLM open-source berkembang pesat. Saat ini, ada jauh lebih banyak LLM open-source dibandingkan yang proprietari, dan kesenjangan performa mungkin segera terjembatani ketika pengembang di seluruh dunia berkolaborasi untuk meningkatkan LLM saat ini dan merancang model yang lebih optimal.
Dalam konteks yang dinamis dan menarik ini, mungkin sulit memilih LLM open-source yang tepat untuk tujuan Anda. Berikut adalah daftar beberapa faktor yang perlu Anda pertimbangkan sebelum memilih satu LLM open-source tertentu:
LLM open-source bukan hanya untuk proyek atau minat individu. Seiring revolusi AI generatif yang terus melaju, bisnis menyadari pentingnya memahami dan menerapkan alat ini. LLM telah menjadi fondasi dalam mendukung aplikasi AI lanjutan, mulai dari chatbot hingga tugas pemrosesan data yang kompleks. Memastikan tim Anda mahir dalam teknologi AI dan LLM bukan lagi sekadar keunggulan kompetitif—ini adalah keharusan untuk mempersiapkan bisnis menghadapi masa depan.
Jika Anda adalah pemimpin tim atau pemilik bisnis yang ingin memberdayakan tim dengan keahlian AI dan LLM, DataCamp for Business menawarkan program pelatihan komprehensif yang dapat membantu karyawan Anda memperoleh keterampilan untuk memanfaatkan alat yang kuat ini. Kami menyediakan:
Investasi dalam peningkatan keahlian AI dan LLM tidak hanya meningkatkan kapabilitas tim Anda tetapi juga menempatkan bisnis Anda di garis depan inovasi, memungkinkan Anda memanfaatkan sepenuhnya potensi teknologi transformatif ini. Hubungi tim kami untuk meminta demo dan mulai membangun tenaga kerja yang siap AI hari ini.
LLM open-source berada dalam pergerakan yang menarik. Dengan evolusi yang cepat, tampaknya ranah AI generatif tidak serta-merta dimonopoli oleh para pemain besar yang mampu membangun dan menggunakan alat yang kuat ini.
Kami baru melihat delapan LLM open-source, namun jumlahnya jauh lebih banyak dan terus bertambah. Kami di DataCamp akan terus menyediakan informasi tentang berita terbaru di ranah LLM, menyediakan kursus, artikel, dan tutorial tentang LLM. Untuk saat ini, cek daftar materi kurasi kami:
Mulai Perjalanan AI Anda Hari Ini!
Program
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
