
Programma
Nozioni di base sull'intelligenza artificiale
10 h
Ci sono molteplici vantaggi, a breve e lungo termine, nello scegliere LLM open source invece di LLM proprietari. Qui sotto trovi un elenco dei motivi più convincenti:
Una delle maggiori preoccupazioni nell’uso di LLM proprietari è il rischio di fughe di dati o di accessi non autorizzati a dati sensibili da parte del fornitore dell’LLM. In effetti, ci sono già state diverse controversie riguardo al presunto uso di dati personali e confidenziali per scopi di training.
Usando LLM open source, le aziende saranno le uniche responsabili della protezione dei dati personali, poiché ne manterranno il pieno controllo.
La maggior parte degli LLM proprietari richiede una licenza per essere utilizzati. Nel lungo periodo, questo può rappresentare una spesa importante che alcune aziende, soprattutto le PMI, potrebbero non potersi permettere. Non è il caso degli LLM open source, che di norma sono gratuiti.
Tuttavia, è importante notare che eseguire LLM richiede risorse considerevoli, anche solo per l’inferenza, il che significa che di solito dovrai pagare per l’uso di servizi cloud o di un’infrastruttura potente.
Le aziende che scelgono LLM open source avranno accesso al funzionamento degli LLM, incluso il codice sorgente, l’architettura, i dati di training e i meccanismi di training e inferenza. Questa trasparenza è il primo passo sia per l’analisi critica sia per la personalizzazione.
Poiché gli LLM open source sono accessibili a tutti, incluso il codice sorgente, le aziende che li usano possono personalizzarli per i propri casi d’uso specifici.
Il movimento open source promette di democratizzare l’uso e l’accesso alle tecnologie LLM e di AI generativa. Consentire agli sviluppatori di ispezionare il funzionamento interno degli LLM è fondamentale per il futuro sviluppo di questa tecnologia. Abbassando le barriere d’ingresso per i coder in tutto il mondo, gli LLM open source possono favorire l’innovazione e migliorare i modelli, riducendo i bias e aumentando accuratezza e prestazioni complessive.
Con la diffusione degli LLM, ricercatori e osservatori ambientali sollevano preoccupazioni sull’impronta di carbonio e il consumo d’acqua necessari per far funzionare queste tecnologie. Gli LLM proprietari raramente pubblicano informazioni sulle risorse necessarie per addestrare e far funzionare gli LLM, né sull’impronta ambientale associata.
Con gli LLM open source, i ricercatori hanno più possibilità di conoscere queste informazioni, aprendo la strada a nuovi miglioramenti progettati per ridurre l’impronta ambientale dell’AI.
GLM-4.6 è un large language model di nuova generazione, successore di GLM-4.5. È progettato per potenziare i workflow agentici, fornire un supporto solido al coding, facilitare il ragionamento avanzato e generare linguaggio naturale di alta qualità. Il modello è pensato sia per ambienti di ricerca sia di produzione, con focus su comprensione di contesti più lunghi, inferenza con strumenti e scrittura più allineata alle preferenze dell’utente.
Fonte:zai-org/GLM-4.6
Rispetto a GLM-4.5, GLM-4.6 introduce diversi miglioramenti chiave: la finestra di contesto è stata ampliata da 128K a 200K token, consentendo compiti agentici più complessi. Anche le prestazioni nel coding sono state migliorate, con punteggi più alti nei benchmark e risultati più solidi nelle applicazioni reali.
GLM-4.6 mostra progressi netti su otto benchmark pubblici relativi ad agenti, ragionamento e coding, superando GLM-4.5 e dimostrando vantaggi competitivi rispetto a modelli leader come DeepSeek-V3.1-Terminus e Claude Sonnet 4.
gpt-oss-120b è l’apice della serie gpt-oss: i modelli open-weight di OpenAI progettati per ragionamento avanzato, compiti agentici e workflow versatili per sviluppatori. La serie include due versioni: gpt-oss-120b, pensata per casi d’uso generali di livello production che richiedono ragionamento avanzato e possono operare su una singola GPU da 80GB (con 117 miliardi di parametri, di cui 5,1 miliardi attivi); e gpt-oss-20b, ottimizzata per bassa latenza e deployment locali o specializzati (con 21 miliardi di parametri e 3,6 miliardi attivi). Entrambi i modelli sono addestrati con il formato di risposta harmony e dovrebbero essere usati con il framework harmony per funzionare efficacemente.
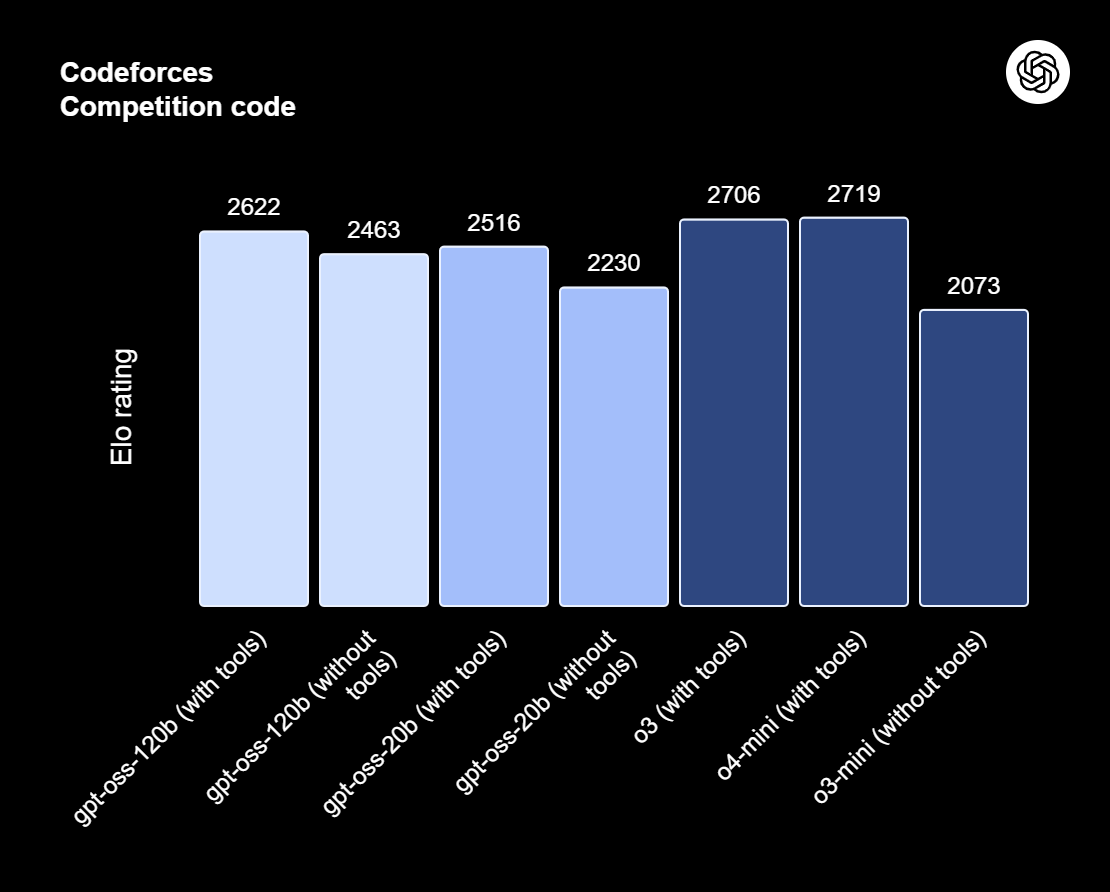
Fonte: Introducing gpt-oss | OpenAI
gpt-oss-120b offre anche sforzi di ragionamento configurabili: basso, medio o alto, per bilanciare profondità e latenza. Fornisce pieno accesso alla chain-of-thought per il debugging e l’audit. Questi modelli sono finetunabili e includono capacità agentiche integrate, come function calling, web browsing, esecuzione di codice Python e output strutturati.
Grazie alla quantizzazione MXFP4 dei pesi MoE, gpt-oss-120b può girare su una singola GPU da 80GB, mentre gpt-oss-20b può operare in un ambiente da 16GB. Leggi il nostro articolo su 10 modi per accedere a GPT-OSS 120B gratis.
Qwen3-235B-A22B-Instruct-2507 è il modello di punta non-thinking della famiglia Qwen3-MoE, progettato per follow-up istruzioni ad alta precisione, rigoroso ragionamento logico, comprensione multilingue del testo, matematica, scienza, coding, uso di strumenti e compiti che richiedono contesti molto lunghi. È un language model causale Mixture of Experts (MoE) con un totale di 235 miliardi di parametri e 22 miliardi di parametri attivi (utilizza 128 esperti con 8 attivi alla volta). Il modello comprende 94 layer, include un meccanismo GQA con 64 query head e 4 key-value head, e ha una finestra di contesto nativa di 262.000 token, estendibile fino a circa 1,01 milioni di token.
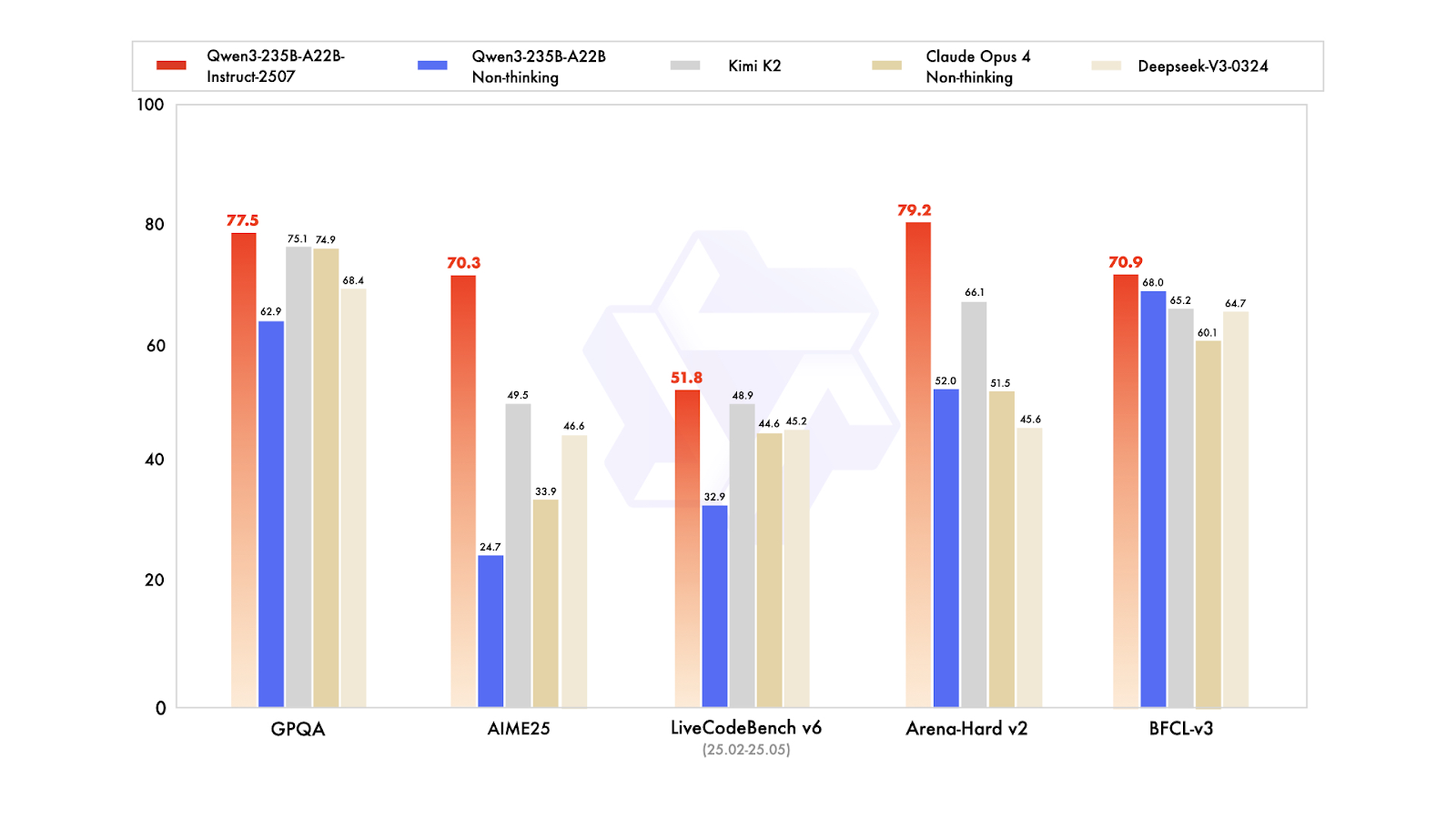
L’ultimo aggiornamento Instruct-2507 introduce miglioramenti significativi nelle capacità generali ed espande la copertura delle conoscenze long-tail in più lingue. Offre inoltre un allineamento delle preferenze nettamente migliore per i compiti aperti e migliora la qualità della scrittura, in particolare per comprensioni a lungo contesto oltre i 256.000 token.
Sui benchmark pubblici, mostra risultati eccezionali. In pratica, questo colloca Instruct-2507 tra i modelli non-thinking di fascia alta, superando sia il precedente Qwen3-235B-A22B non-thinking sia concorrenti di punta come DeepSeek-V3, GPT-4o, Claude Opus 4 (non-thinking) e Kimi K2.
Puoi saperne di più su Qwen3 nel nostro articolo completo.
DeepSeek-V3.2-Exp è una versione sperimentale e intermedia che porta alla prossima generazione dell’architettura DeepSeek. Si basa su V3.1-Terminus e introduce la DeepSeek Sparse Attention per migliorare l’efficienza di training e inferenza, in particolare negli scenari a lungo contesto. Questo modello mira a migliorare l’efficienza dei transformer per sequenze estese mantenendo la qualità dell’output attesa dalla linea Terminus.
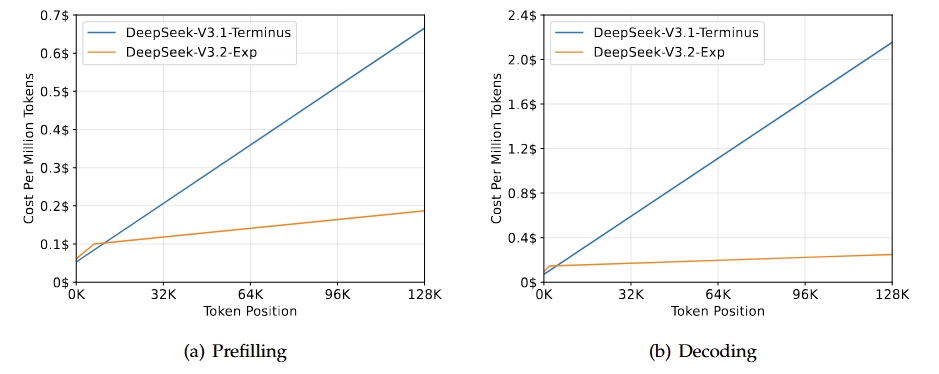
Fonte: DeepSeek-V3.2-Exp
Il risultato principale di questo rilascio è che eguaglia le capacità complessive di V3.1-Terminus offrendo notevoli miglioramenti di efficienza per compiti a lungo contesto. Valutazioni e analisi di terze parti mostrano che le sue prestazioni sono paragonabili a Terminus, con una riduzione significativa dei costi computazionali. Ciò conferma che l’attenzione sparsa può aumentare l’efficienza senza compromettere la qualità.
Leggi la nostra guida completa a DeepSeek-V3.2-Exp per seguire un progetto demo.
DeepSeek-R1 ha ricevuto un aggiornamento di versione minore a DeepSeek-R1-0528, che ne migliora le capacità di ragionamento e inferenza grazie a maggiore potenza computazionale e ottimizzazioni algoritmiche post-training. Il risultato è un miglioramento significativo in varie aree, tra cui matematica, programmazione e logica generale. Le prestazioni complessive sono ora più vicine a sistemi leader come O3 e Gemini 2.5 Pro.
Oltre alle capacità grezze, questo aggiornamento enfatizza l’utilità pratica con un function calling migliore e workflow di coding più efficaci, riflettendo l’attenzione a produrre output più affidabili e orientati alla produttività.
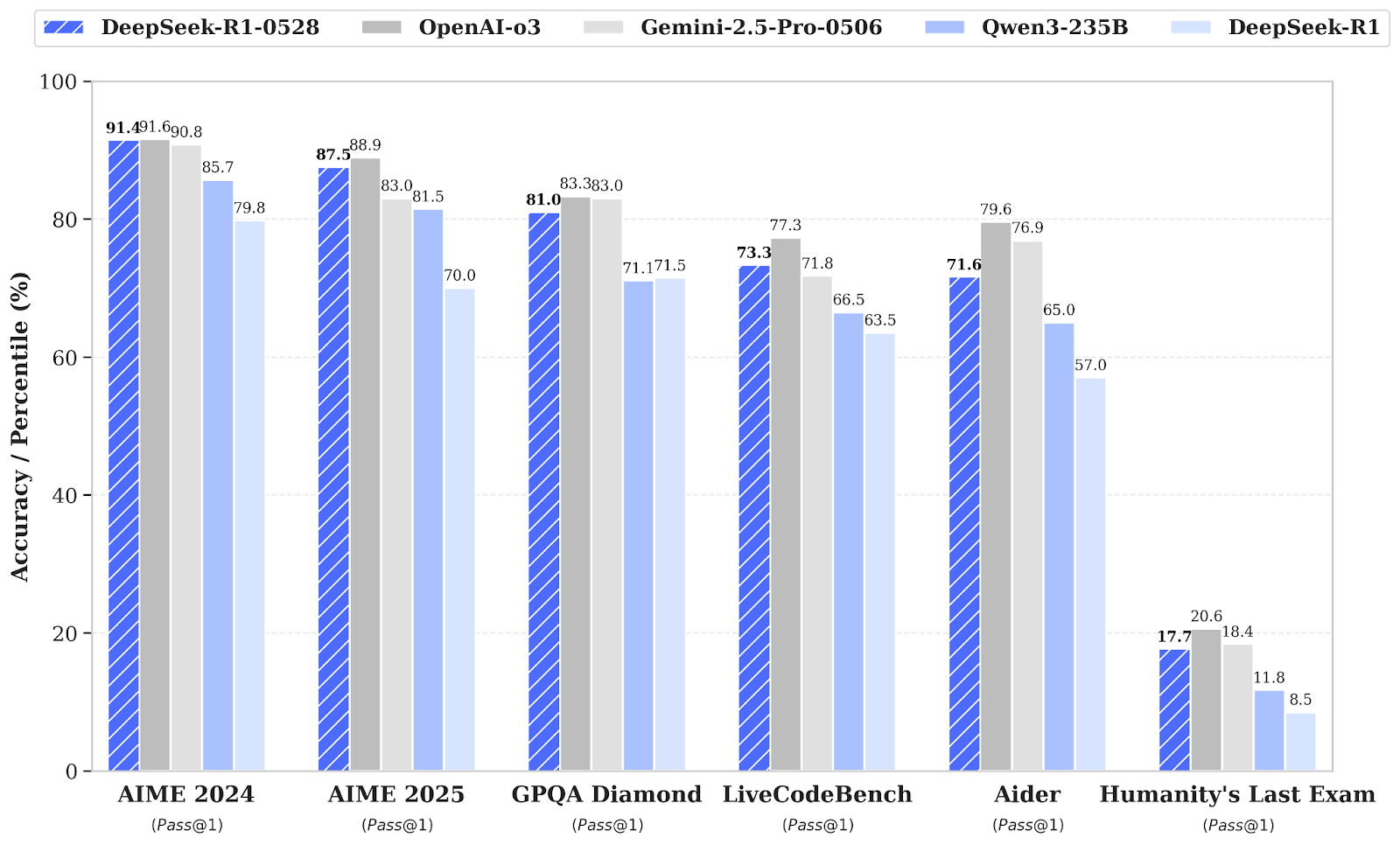
Fonte: deepseek-ai/DeepSeek-R1-0528
Rispetto alla precedente versione DeepSeek R1, il modello aggiornato mostra progressi sostanziali nel ragionamento complesso. Ad esempio, all’esame AIME 2025, l’accuratezza è passata dal 70% all’87,5%, supportata da un pensiero analitico più profondo (con il numero medio di token per domanda aumentato da circa 12.000 a 23.000).
Valutazioni più ampie mostrano tendenze positive anche in aree come conoscenza, ragionamento e prestazioni nel coding. Esempi includono miglioramenti in LiveCodeBench, rating Codeforces, SWE Verified e Aider-Polyglot, a indicare una maggiore profondità nella risoluzione dei problemi e capacità di coding nel mondo reale superiori.
Apriel-1.5-15b-Thinker è un modello di ragionamento multimodale della serie Apriel SLM di ServiceNow. Offre prestazioni competitive con soli 15 miliardi di parametri, puntando a risultati di frontiera entro i limiti di un budget a singola GPU. Questo modello non solo aggiunge capacità di ragionamento sulle immagini al precedente modello solo testo, ma approfondisce anche le sue abilità di ragionamento testuale.
Come secondo modello della serie di ragionamento, ha subito un ampio pretraining continuo su domini sia testuali sia visivi. Il post-training prevede un SFT (supervised fine-tuning) solo testo, senza SFT specifico per immagini o reinforcement learning. Nonostante questi limiti, il modello punta a una qualità allo stato dell’arte nel ragionamento su testo e immagini per la sua dimensione.
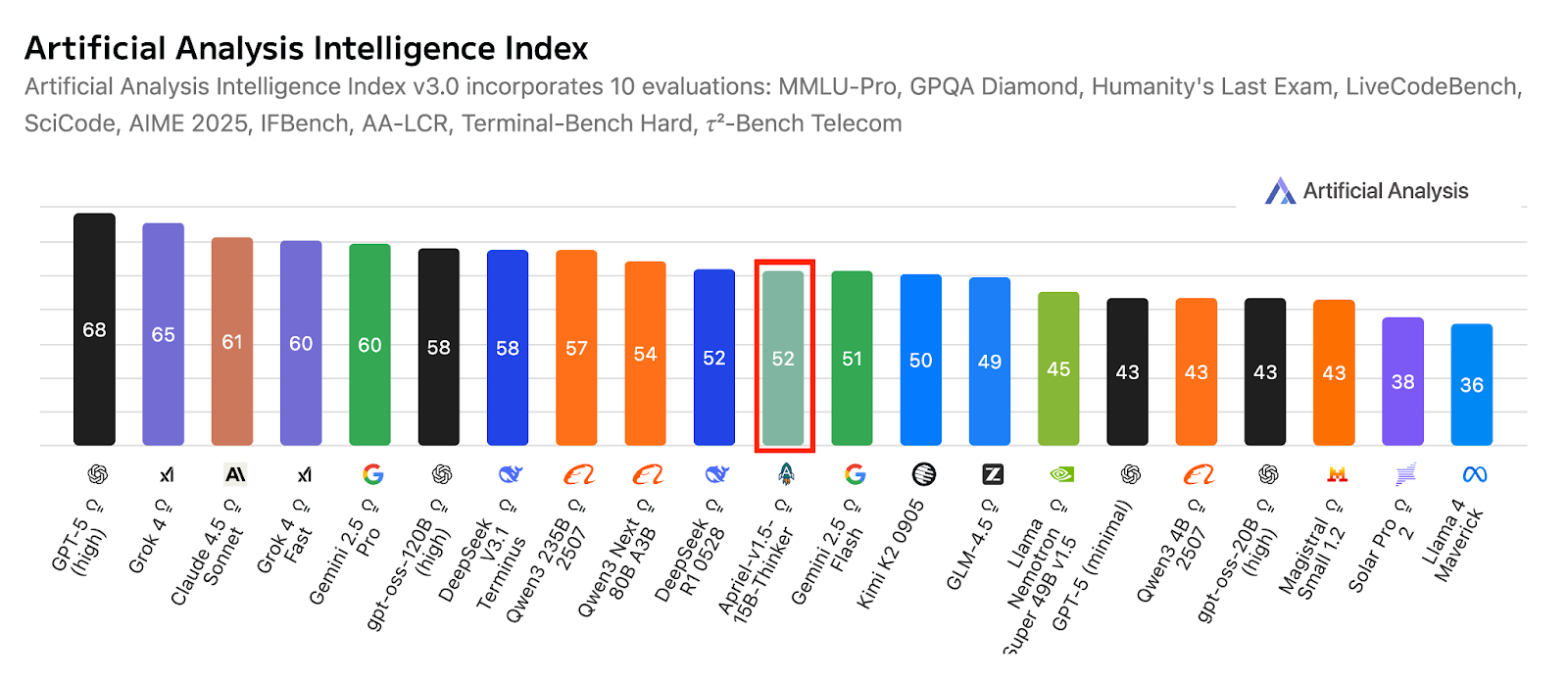
Fonte: ServiceNow-AI/Apriel-1.5-15b-Thinker
Progettato per girare su una singola GPU, privilegia il deployment pratico e l’efficienza. I risultati di valutazione indicano una forte prontezza per applicazioni reali, con un punteggio Artificial Analysis Index di 52, che posiziona il modello in modo competitivo rispetto a sistemi molto più grandi. Questo punteggio riflette anche la sua copertura rispetto a pari compatti e di frontiera, mantenendo al contempo un footprint da modello piccolo adatto all’uso enterprise.
Kimi-K2-Instruct-0905 è il modello più recente e avanzato della linea Kimi K2. È un language model Mixture-of-Experts all’avanguardia, con un totale di 1 trilione di parametri e 32 miliardi di parametri attivati. È progettato specificamente per workflow di ragionamento di alto livello e coding.
K2-Instruct-0905 migliora significativamente la capacità di K2 di gestire compiti di lungo periodo con una finestra di contesto da 256.000 token, rispetto ai precedenti 128.000. Mira a supportare casi d’uso agentici robusti, tra cui chat con strumenti e assistenza al codice. Come rilascio di punta della serie K2 Instruct, si concentra su un’ergonomia per sviluppatori solida e affidabilità per applicazioni di qualità production.
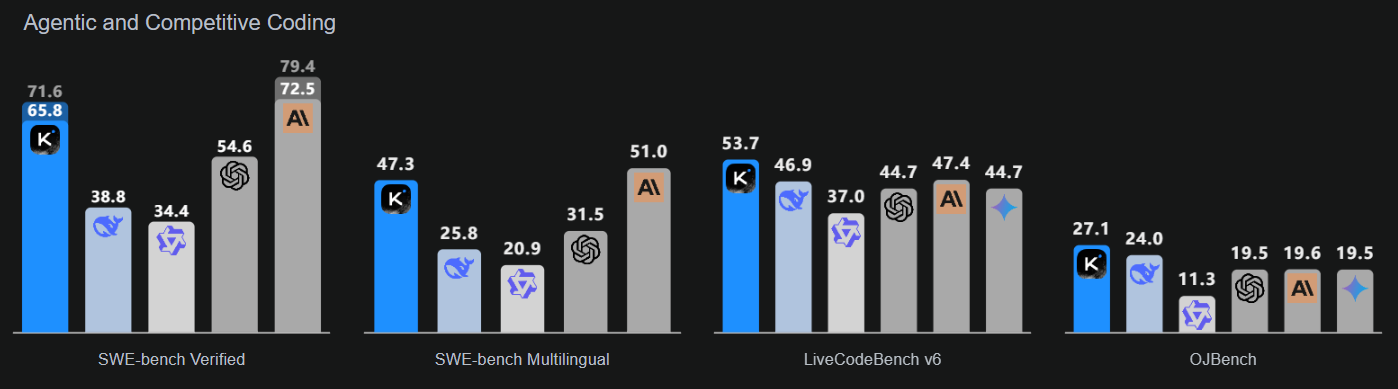
Fonte: Kimi K2: Open Agentic Intelligence
Questo modello enfatizza tre aree chiave: intelligenza di coding potenziata per compiti agentici, con chiari miglioramenti nei benchmark pubblici e nelle applicazioni reali; un’interfaccia utente migliorata che esalta estetica e funzionalità; e un contesto esteso a 256.000 token che consente cicli di pianificazione e modifica più ampi.
Llama-3_3-Nemotron-Super-49B-v1_5 è un modello aggiornato da 49 miliardi di parametri della linea Nemotron di NVIDIA, derivato da Llama-3.3-70B-Instruct di Meta. È specificamente progettato come modello di ragionamento per chat allineate all’umano e compiti agentici, come retrieval-augmented generation (RAG) e tool calling.
Questo modello ha subito un post-training per potenziare le capacità di ragionamento, l’allineamento alle preferenze e l’uso degli strumenti. Supporta anche workflow a lungo contesto fino a 128.000 token, rendendolo adatto ad applicazioni complesse e multi-step.
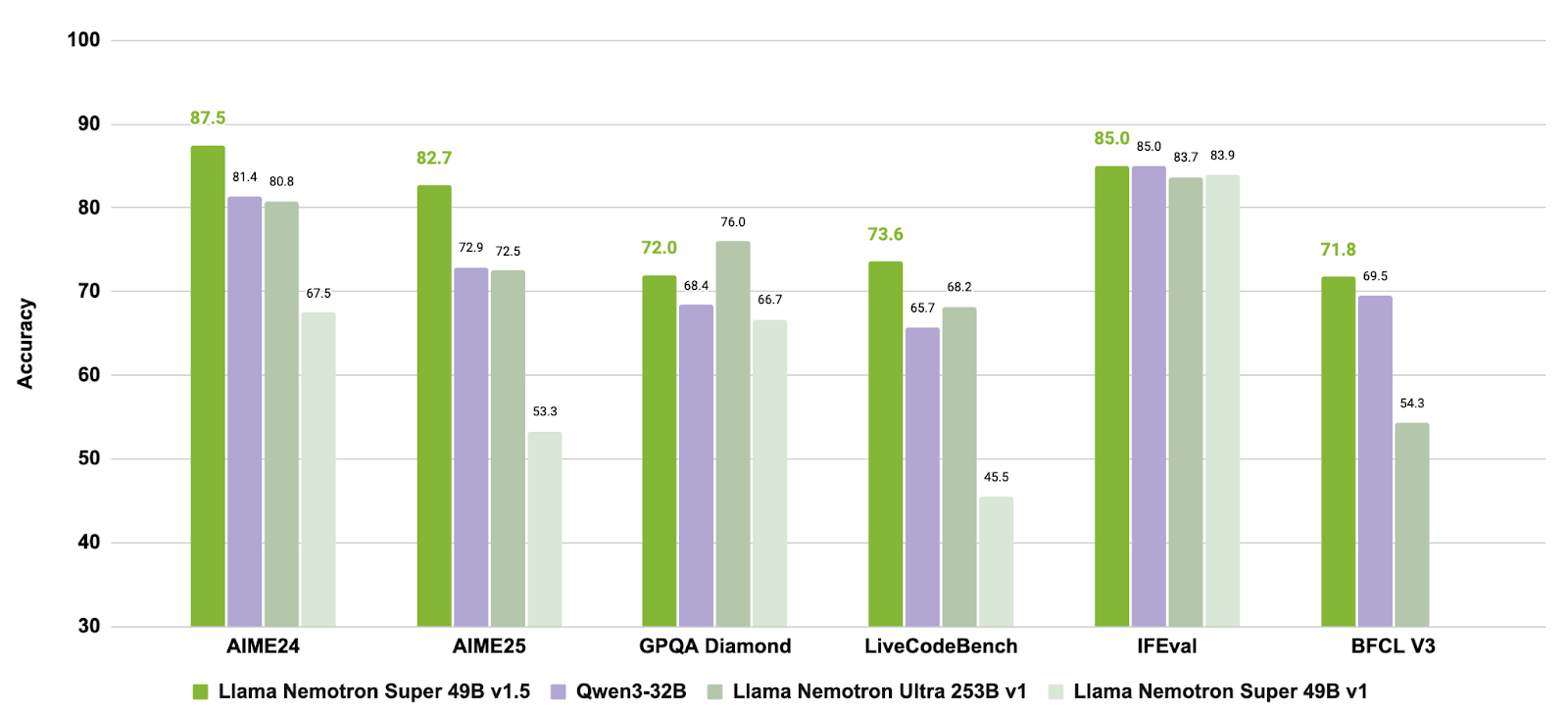
Fonte: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Combinando un post-training mirato per ragionamento e comportamenti agentici con il supporto per compiti a lungo contesto, Llama-3.3-Nemotron-Super-49B-v1.5 offre una soluzione equilibrata per gli sviluppatori che necessitano di capacità di ragionamento avanzate e uso robusto di strumenti senza sacrificare l’efficienza in runtime.
Mistral-Small-3.2-24B-Instruct-2506 è un aggiornamento significativo rispetto a Mistral-Small-3.1-24B-Instruct-2503: migliora il follow-up delle istruzioni, riduce gli errori di ripetizione e offre un template di function calling più robusto, mantenendo o leggermente migliorando le capacità complessive. Come modello instruct da 24B parametri, è ampiamente accessibile su varie piattaforme, inclusi i marketplace AWS, dove si distingue per una migliore aderenza alle istruzioni.
Fonte: mistralai/Mistral-Small-3.2-24B-Instruct-2506
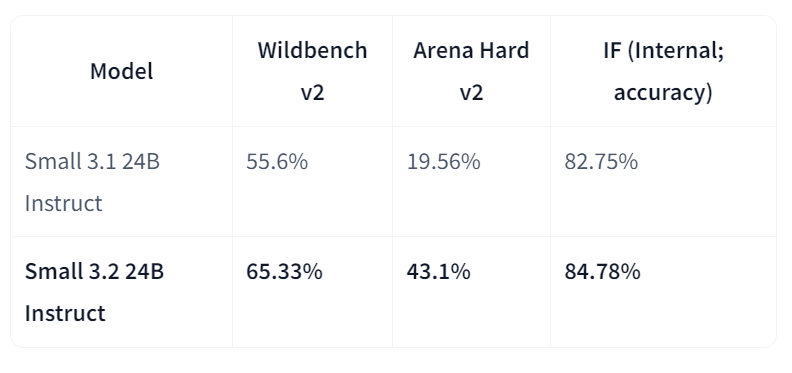
Nel confronto diretto con la versione 3.1, Small-3.2 mostra progressi evidenti nella qualità e affidabilità dell’assistant. Aumenta le prestazioni nel follow-up istruzioni su Wildbench v2 (dal 55,6% al 65,33%) e Arena Hard v2 (dal 19,56% al 43,1%), mentre l’accuratezza interna nel follow-up passa dall’82,75% all’84,78%. I fallimenti di ripetizione su prompt impegnativi si dimezzano (dal 2,11% all’1,29%). Nel frattempo, le prestazioni STEM restano comparabili, con MATH al 69,42% e HumanEval+ Pass@5 al 92,90%.
Nella tabella seguente trovi un confronto tra i modelli principali:
| Modello | Punti di forza | Upgrade / caratteristiche notevoli |
|---|---|---|
| GLM 4.6 | Ragionamento solido, workflow agentici e capacità di coding | Finestra di contesto ampliata da 128K → 200K; performance benchmark migliorate vs. GLM-4.5 e DeepSeek-V3.1 |
| gpt-oss-120B | Modello GPT open-weight per ragionamento avanzato e compiti agentici | Profondità di ragionamento configurabile, accesso alla chain-of-thought, function calling e formato di risposta harmony |
| Qwen3-235B-Instruct-2507 | Multilingue, ragionamento ad alta precisione e follow-up istruzioni | Contesto oltre 1M di token, scrittura allineata alle preferenze, supera GPT-4o e Claude Opus 4 (non-thinking) |
| DeepSeek-V3.2-Exp | Elaborazione efficiente di lunghi contesti tramite attenzione sparsa | Eguaglia le prestazioni di V3.1 con minore compute; efficienza del transformer ottimizzata |
| DeepSeek-R1-0528 | Ragionamento avanzato, matematica e programmazione | Miglioramento AIME 2025 del 17,5%; maggiore profondità analitica e affidabilità nel coding |
| Apriel-1.5-15B-Thinker | Ragionamento multimodale (testo + immagine) su una singola GPU | Pretraining continuo su testo e immagine; ragionamento di frontiera per dimensioni compatte |
| Kimi-K2-Instruct-0905 | Ragionamento di fascia alta e workflow di coding agentici | Contesto da 256K token, migliore ergonomia per sviluppatori e supporto a compiti con strumenti |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Modello bilanciato per ragionamento e uso di strumenti | Ottimizzato da NVIDIA per RAG e applicazioni agentiche; supporto a lunghi contesti fino a 128K token |
| Mistral-Small-3.2-24B-Instruct-2506 | Follow-up istruzioni compatto e affidabile | Errori di ripetizione ridotti (−50%) e grandi progressi su WildBench v2 e Arena Hard v2 |
Lo spazio degli LLM open source si sta espandendo rapidamente. Oggi ci sono molti più LLM open source che proprietari e il divario di prestazioni potrebbe colmarsi presto, man mano che gli sviluppatori di tutto il mondo collaborano per aggiornare gli LLM attuali e progettarne di più ottimizzati.
In questo contesto vivace ed entusiasmante, può essere difficile scegliere l’LLM open source giusto per i tuoi scopi. Ecco alcuni fattori da considerare prima di optare per un LLM open source specifico:
Gli LLM open source non sono solo per progetti o interessi individuali. Con l’accelerazione della rivoluzione dell’AI generativa, le aziende stanno riconoscendo l’importanza cruciale di comprendere e implementare questi strumenti. Gli LLM sono già diventati fondamentali per alimentare applicazioni di AI avanzate, dai chatbot all’elaborazione complessa dei dati. Assicurarti che il tuo team sia competente nelle tecnologie di AI e LLM non è più solo un vantaggio competitivo: è una necessità per mettere al riparo il tuo business in futuro.
Se sei un team leader o un imprenditore e vuoi dare al tuo team competenze in AI e LLM, DataCamp for Business offre programmi di formazione completi che possono aiutare i tuoi dipendenti ad acquisire le skill necessarie per sfruttare questi potenti strumenti. Offriamo:
Investire nell’upskilling in AI e LLM non solo migliora le capacità del tuo team, ma posiziona anche la tua azienda all’avanguardia dell’innovazione, permettendoti di sfruttare appieno il potenziale di queste tecnologie trasformative. Mettiti in contatto con il nostro team per richiedere una demo e iniziare a costruire oggi la tua forza lavoro pronta per l’AI.
Gli LLM open source stanno vivendo un momento entusiasmante. Con la loro rapida evoluzione, sembra che lo spazio dell’AI generativa non sarà necessariamente monopolizzato dai grandi player che possono permettersi di costruire e usare questi potenti strumenti.
Abbiamo visto solo otto LLM open source, ma il numero è molto più alto e in rapida crescita. Noi di DataCamp continueremo a fornire informazioni sulle ultime novità nel mondo degli LLM, offrendo corsi, articoli e tutorial dedicati. Per ora, dai un’occhiata alla nostra lista di materiali selezionati:
Inizia oggi il tuo percorso nell’AI!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

