
Leerpad
AI-basisprincipes
10 Hr
Er zijn meerdere korte- en langetermijnvoordelen bij het kiezen voor open-source LLM’s in plaats van proprietaire LLM’s. Hieronder vind je de meest overtuigende redenen:
Een van de grootste zorgen bij het gebruik van proprietaire LLM’s is het risico op datalekken of ongeautoriseerde toegang tot gevoelige data door de LLM-aanbieder. Er zijn al meerdere controverses geweest over het vermeende gebruik van persoonlijke en vertrouwelijke data voor trainingsdoeleinden.
Door open-source LLM’s te gebruiken, zijn bedrijven zelf volledig verantwoordelijk voor de bescherming van persoonsgegevens, omdat ze de volledige controle behouden.
Voor de meeste proprietaire LLM’s is een licentie vereist. Op de lange termijn kan dit een forse kostenpost zijn die sommige bedrijven, vooral mkb’ers, zich niet kunnen veroorloven. Bij open-source LLM’s is dit meestal niet het geval, omdat ze doorgaans gratis te gebruiken zijn.
Het is echter belangrijk op te merken dat LLM’s aanzienlijke resources vereisen, zelfs alleen voor inferentie, wat betekent dat je meestal moet betalen voor cloudservices of krachtige infrastructuur.
Bedrijven die voor open-source LLM’s kiezen, krijgen inzicht in de werking van LLM’s, inclusief broncode, architectuur, trainingsdata en de mechanismen voor training en inferentie. Deze transparantie is de eerste stap richting controle, maar ook richting maatwerk.
Omdat open-source LLM’s voor iedereen toegankelijk zijn, inclusief de broncode, kunnen bedrijven ze aanpassen aan hun specifieke use-cases.
De open-source beweging belooft het gebruik en de toegang tot LLM- en generatieve AI-technologie te democratiseren. Ontwikkelaars laten meekijken onder de motorkap van LLM’s is cruciaal voor de toekomstige ontwikkeling van deze technologie. Door de instapdrempels voor coders wereldwijd te verlagen, kunnen open-source LLM’s innovatie stimuleren en de modellen verbeteren door vooringenomenheid te verminderen en nauwkeurigheid en algehele prestaties te verhogen.
Sinds de popularisering van LLM’s maken onderzoekers en milieuwaakhonden zich zorgen over de CO₂-voetafdruk en het waterverbruik die nodig zijn om deze technologieën te draaien. Proprietaire LLM’s publiceren zelden informatie over de resources die nodig zijn om LLM’s te trainen en te gebruiken, noch over de bijbehorende milieu-impact.
Met open-source LLM’s is de kans groter dat onderzoekers toegang krijgen tot deze informatie, wat de deur kan openen naar nieuwe verbeteringen die zijn ontworpen om de ecologische voetafdruk van AI te verkleinen.
GLM-4.6 is een next-gen large language model als opvolger van GLM-4.5. Het is ontworpen om agentische workflows te verbeteren, robuuste codeerhulp te bieden, geavanceerde redenering te faciliteren en natuurlijke taal van hoge kwaliteit te genereren. Het model is gericht op zowel onderzoek als productie, met focus op begrip van langere context, tool-augmented inferentie en tekst die natuurlijker aansluit bij gebruikersvoorkeuren.
Bron:zai-org/GLM-4.6
Vergeleken met GLM-4.5 introduceert GLM-4.6 verschillende belangrijke verbeteringen: het contextvenster is uitgebreid van 128K naar 200K tokens, wat complexere agentische taken mogelijk maakt. De codeerprestaties zijn ook verbeterd, met hogere benchmarkscores en sterkere resultaten in praktijktoepassingen.
GLM-4.6 laat duidelijke winst zien op acht publieke benchmarks rond agents, redenering en coderen, presteert beter dan GLM-4.5 en toont concurrentievoordelen ten opzichte van toonaangevende modellen zoals DeepSeek-V3.1-Terminus en Claude Sonnet 4.
gpt-oss-120b is het summum van de gpt-oss-serie—OpenAI’s open-weight modellen ontworpen voor geavanceerde redenering, agentische taken en veelzijdige developer-workflows. Deze serie omvat twee versies: gpt-oss-120b, bedoeld voor productieklare, algemene use-cases die hoogstaande redenering vereisen en op een enkele 80GB GPU kan draaien (met 117 miljard parameters, waarvan 5,1 miljard actief); en gpt-oss-20b, geoptimaliseerd voor lagere latentie en lokale of gespecialiseerde implementaties (met 21 miljard parameters en 3,6 miljard actief). Beide modellen zijn getraind met het harmony response format en moeten met het harmony framework gebruikt worden om effectief te functioneren.
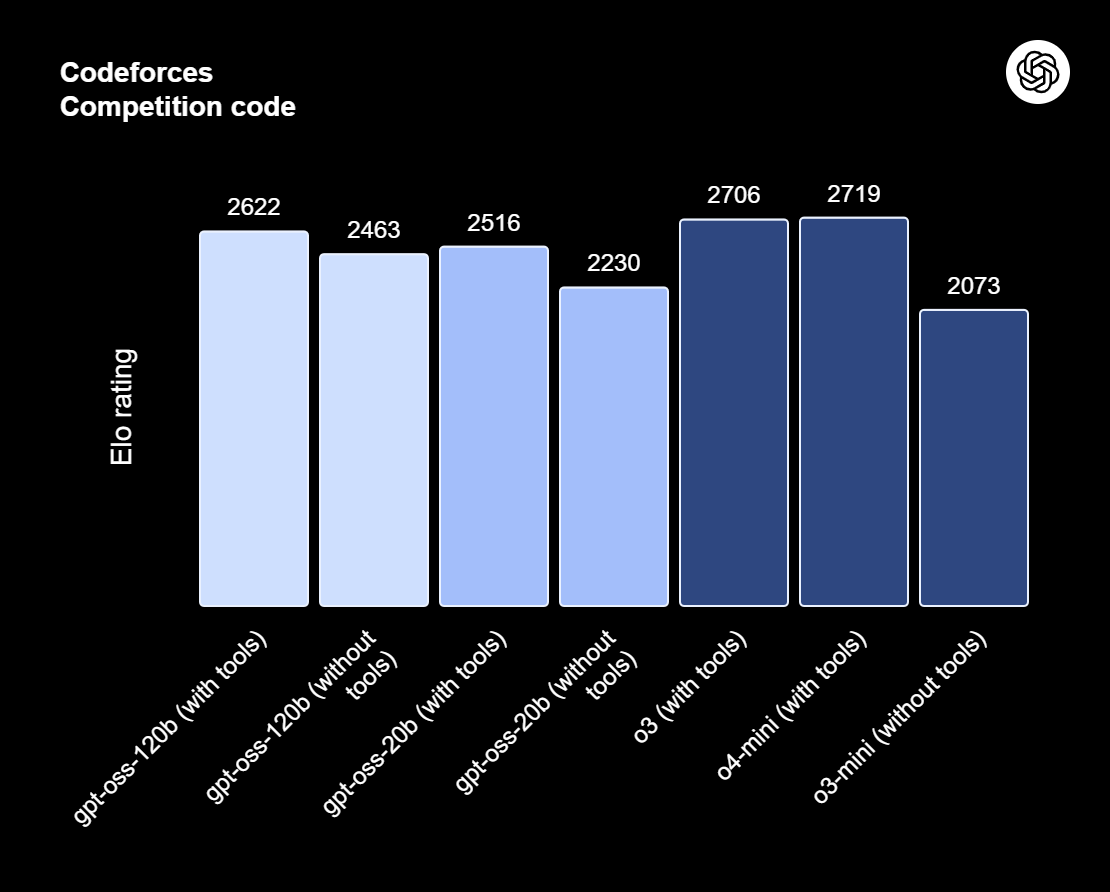
Bron: Introducing gpt-oss | OpenAI
De gpt-oss-120b biedt ook instelbare redeneerinspanning: laag, middel of hoog, om diepgang en latentie in balans te brengen. Het biedt volledige chain-of-thought-toegang voor debuggen en auditen. Deze modellen zijn te fine-tunen en hebben ingebouwde agentische mogelijkheden zoals function calling, web-browsen, Python-code uitvoeren en gestructureerde output.
Dankzij MXFP4-kwantisatie van MoE-gewichten kan gpt-oss-120b op een enkele 80GB GPU draaien, terwijl gpt-oss-20b kan werken binnen 16GB. Lees ons artikel over 10 manieren om GPT-OSS 120B gratis te gebruiken.
Qwen3-235B-A22B-Instruct-2507 is het vlaggenschip ‘non-thinking’ model binnen de Qwen3-MoE-familie, ontworpen voor zeer precieze instructie-opvolging, strikte logische redenering, meertalige tekstbegrip, wiskunde, wetenschap, coderen, toolgebruik en taken die zeer lange context vereisen. Het is een mixture-of-experts (MoE) causaal taalmodel met in totaal 235 miljard parameters en 22 miljard actieve parameters (128 experts waarvan er 8 tegelijk actief zijn). Het model heeft 94 lagen, bevat een GQA-mechanisme met 64 query heads en 4 key-value heads, en heeft een native contextvenster van 262.000 tokens, uitbreidbaar tot circa 1,01 miljoen tokens.
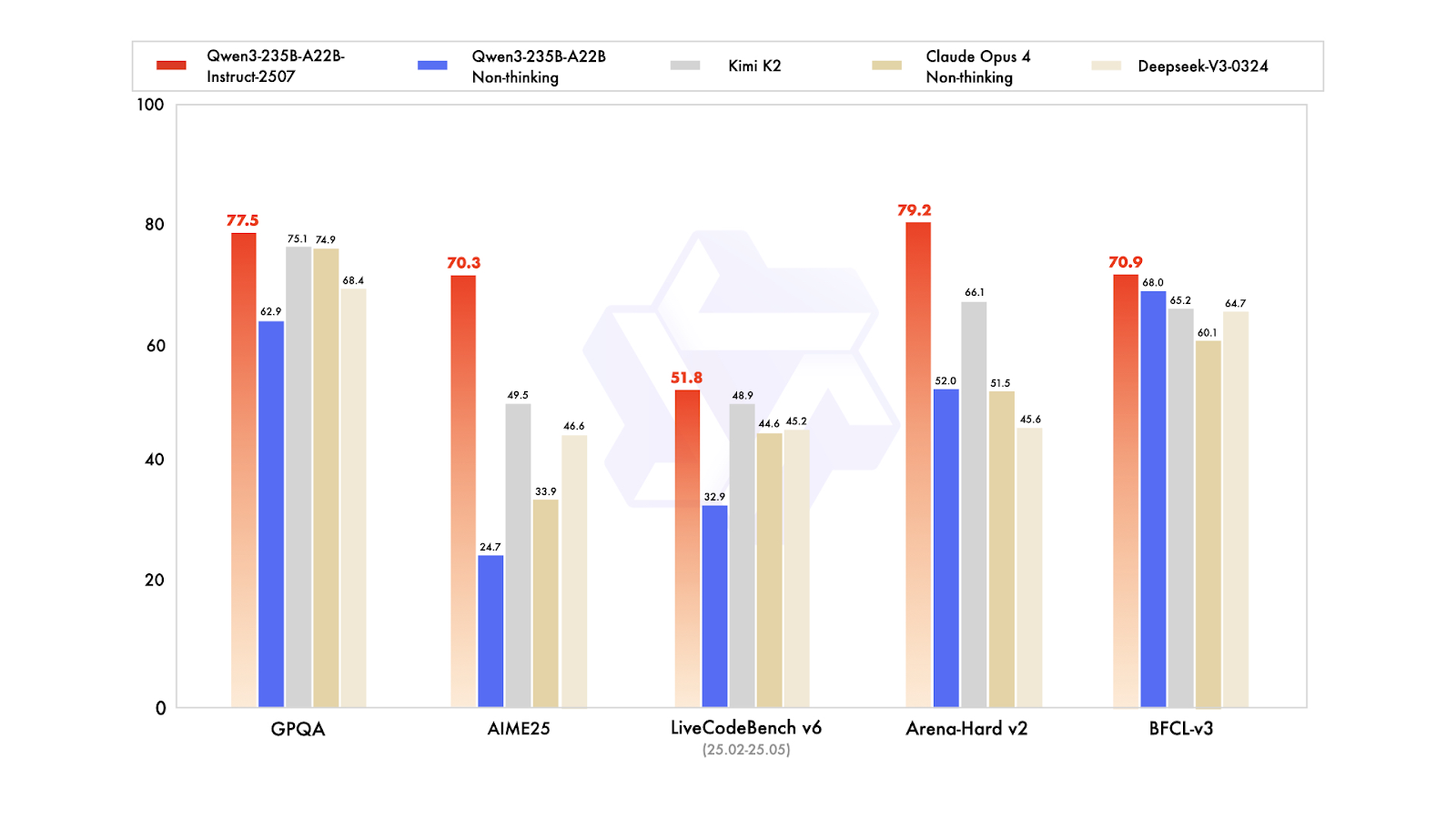
De nieuwste Instruct-2507-update brengt aanzienlijke verbeteringen in algemene capaciteiten en vergroot de dekking van long-tail kennis in meerdere talen. Ook biedt het merkbaar betere voorkeur-afstemming voor open-ended taken en verbetert het de schrijfkwaliteit, met name voor begrip van lange contexten van 256.000+ tokens.
Op publieke benchmarks laat het uitzonderlijke resultaten zien. In de praktijk positioneert dit Instruct-2507 als een topklasse non-thinking model, beter dan zowel de eerdere Qwen3-235B-A22B non-thinking variant als toonaangevende concurrenten zoals DeepSeek-V3, GPT-4o, Claude Opus 4 (non-thinking) en Kimi K2.
Lees meer over Qwen3 in ons volledige artikel.
DeepSeek-V3.2-Exp is een experimentele, tussentijdse versie die de weg bereidt voor de volgende generatie van de DeepSeek-architectuur. Het bouwt voort op V3.1-Terminus en introduceert DeepSeek Sparse Attention om training en inferentie efficiënter te maken, met name in lang-contextscenario’s. Dit model beoogt de transformer-efficiëntie te verbeteren voor langere reeksen, terwijl de outputkwaliteit van de Terminus-lijn behouden blijft.
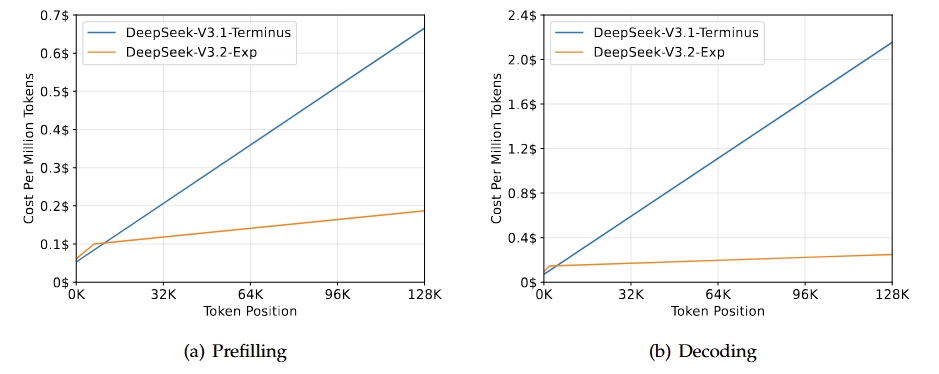
Bron: DeepSeek-V3.2-Exp
De belangrijkste uitkomst van deze release is dat hij de algehele capaciteiten van V3.1-Terminus evenaart, terwijl hij aanzienlijke efficiëntiewinsten biedt voor lang-contexttaken. Evaluaties en analyses door derden tonen prestaties vergelijkbaar met Terminus, met een opvallende vermindering van de rekenkosten. Dit bevestigt dat sparse attention de efficiëntie kan verhogen zonder in te leveren op kwaliteit.
Lees onze volledige gids voor DeepSeek-V3.2-Exp en werk een demoproject door.
DeepSeek-R1 heeft een kleine versie-update gekregen naar DeepSeek-R1-0528, dat de redeneer- en inferentiecapaciteiten verbetert via meer rekenkracht en algoritmische optimalisaties na training. Daardoor zijn er significante verbeteringen in onder meer wiskunde, programmeren en algemene logica. De algehele prestaties liggen nu dichter bij leidende systemen zoals O3 en Gemini 2.5 Pro.
Naast ruwe capaciteiten legt deze update nadruk op praktische bruikbaarheid met betere function calling en code-workflows, wat de focus weerspiegelt op betrouwbaardere en productiviteitsgerichte output.
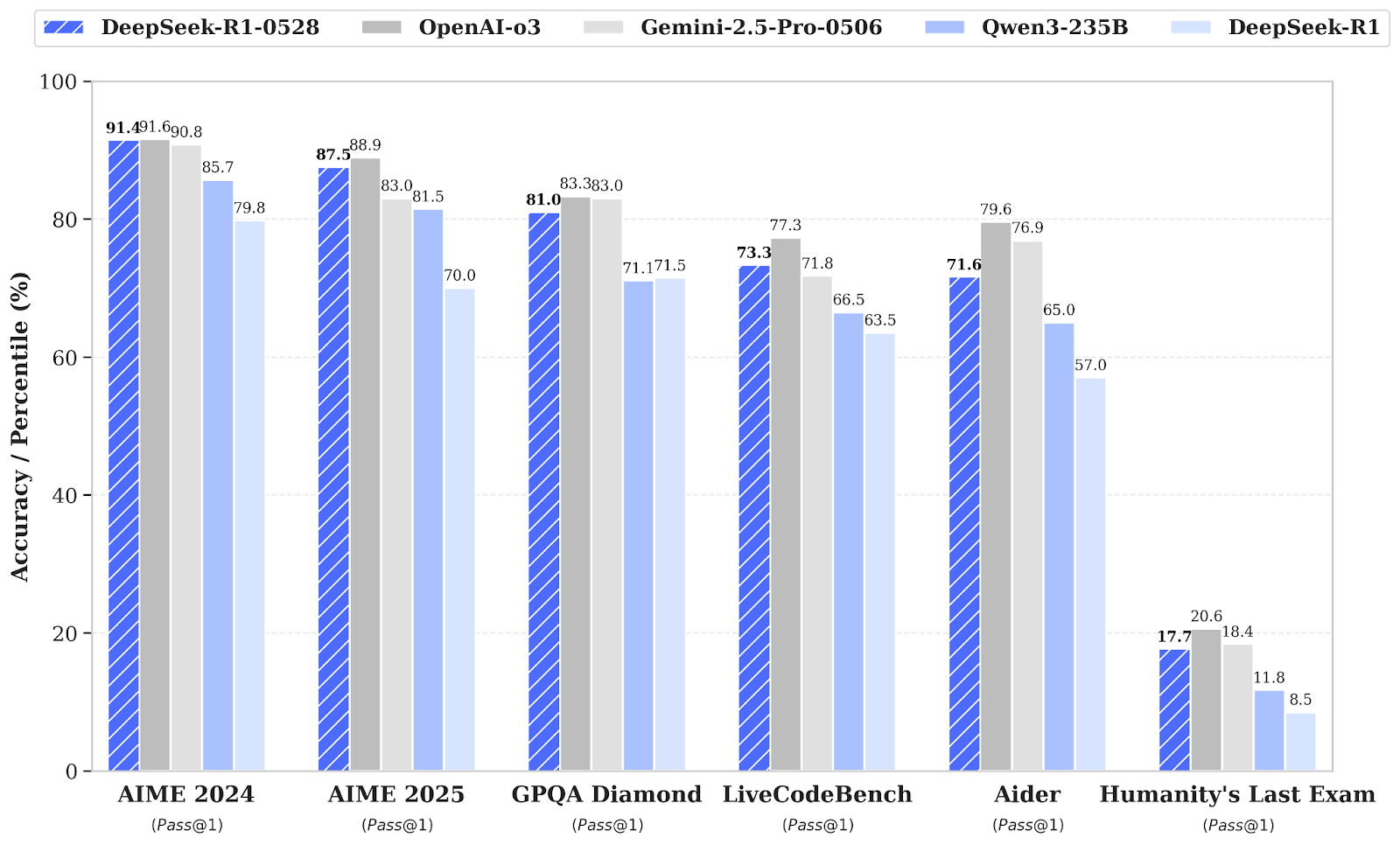
Bron: deepseek-ai/DeepSeek-R1-0528
Vergeleken met de vorige versie DeepSeek R1 laat het ge»ruade model aanzienlijke vooruitgang zien in complexe redenering. Zo steeg op het AIME 2025-examen de nauwkeurigheid van 70% naar 87,5%, ondersteund door diepere analytische denkstappen (met het gemiddeld aantal tokens per vraag van circa 12.000 naar 23.000).
Brede evaluaties tonen eveneens positieve trends in kennis, redenering en codeerprestaties. Voorbeelden zijn verbeteringen in LiveCodeBench, Codeforces-ratings, SWE Verified en Aider-Polyglot, wat duidt op meer probleemoplossende diepgang en superieure codeercapaciteiten in de praktijk.
Apriel-1.5-15b-Thinker is een multimodaal redeneermodel in ServiceNow’s Apriel SLM-serie. Het levert concurrerende prestaties met slechts 15 miljard parameters en mikt op frontier-niveau resultaten binnen het budget van een enkele GPU. Dit model voegt niet alleen beeldredenering toe aan het eerdere tekst-only model, maar verdiept ook de tekstuele redeneerkwaliteiten.
Als tweede model in de redeneerreeks heeft het uitgebreide continue pretraining ondergaan in zowel tekst- als beeldmodaliteiten. De post-training omvat tekst-only supervised fine-tuning (SFT), zonder beeldspecifieke SFT of reinforcement learning. Ondanks deze beperkingen mikt het model op state-of-the-art kwaliteit in tekst- en beeldredenering voor zijn formaat.
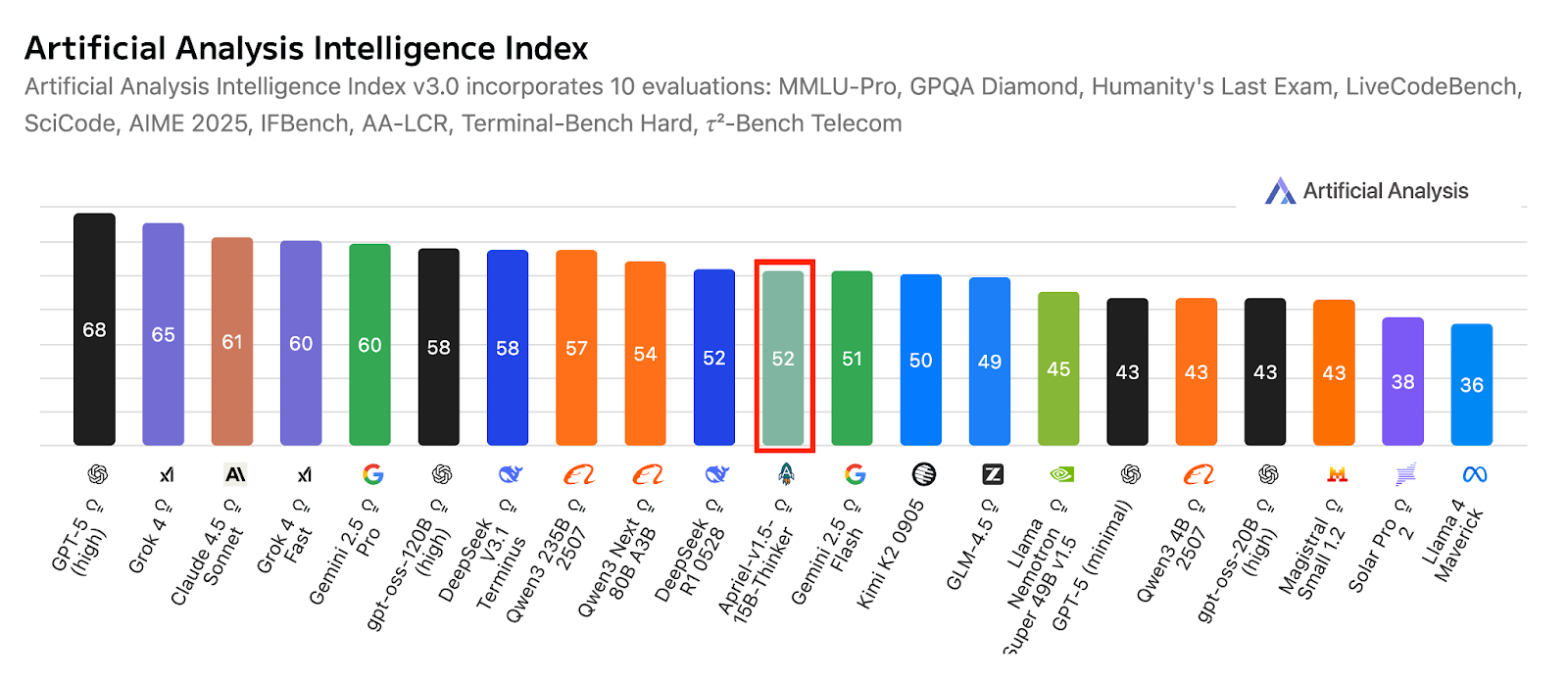
Bron: ServiceNow-AI/Apriel-1.5-15b-Thinker
Ontworpen om op een enkele GPU te draaien, geeft het prioriteit aan praktische inzet en efficiëntie. Evaluatieresultaten duiden op sterke gereedheid voor real-world toepassingen, met een Artificial Analysis-indexscore van 52, waarmee het model concurrerend staat tegenover veel grotere systemen. Deze score weerspiegelt ook de dekking in vergelijking met toonaangevende compacte en frontier-peers, terwijl het een klein modelprofiel behoudt dat geschikt is voor enterprise-gebruik.
Kimi-K2-Instruct-0905 is het nieuwste en meest geavanceerde model in de Kimi K2-lijn. Het is een state-of-the-art Mixture-of-Experts taalmodel met in totaal 1 biljoen parameters en 32 miljard geactiveerde parameters. Dit model is specifiek ontworpen voor hoogwaardige redenerings- en code-workflows.
K2-Instruct-0905 verbetert K2’s vermogen om langetermijntaken aan te kunnen aanzienlijk met een contextvenster van 256.000 tokens, een verdubbeling ten opzichte van de eerdere 128.000 tokens. Het is gericht op robuuste agentgebaseerde use-cases, waaronder tool-augmented chat en code-assistentie. Als vlaggenschip van de K2 Instruct-serie focust het op sterke ontwikkelaarservaring en betrouwbaarheid voor productiegrade toepassingen.
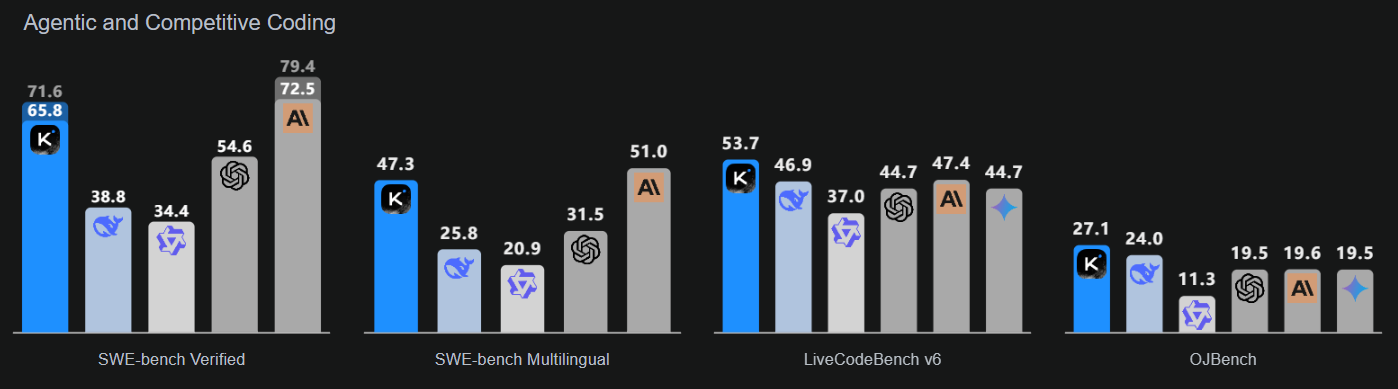
Bron: Kimi K2: Open Agentic Intelligence
Dit model legt de nadruk op drie kerngebieden: verbeterde codeerintelligentie voor agentgebaseerde taken, met duidelijke verbeteringen op publieke benchmarks en in praktijksituaties; een verbeterde gebruikersinterface die zowel esthetiek als functionaliteit ten goede komt; en een verlengde contextlengte van 256.000 tokens die uitgebreidere plannings- en bewerkingslussen mogelijk maakt.
Llama-3_3-Nemotron-Super-49B-v1_5 is een verbeterd model met 49 miljard parameters in NVIDIA’s Nemotron-lijn, afgeleid van Meta’s Llama-3.3-70B-Instruct. Het is specifiek ontworpen als redeneermodel voor mens-gealigneerde chat en agentische taken, zoals retrieval-augmented generation (RAG) en tool calling.
Dit model heeft post-training ondergaan om de redeneercapaciteiten, voorkeur-afstemming en toolgebruik te versterken. Het ondersteunt ook lang-contextworkflows tot 128.000 tokens, wat het geschikt maakt voor complexe, meerstaps toepassingen.
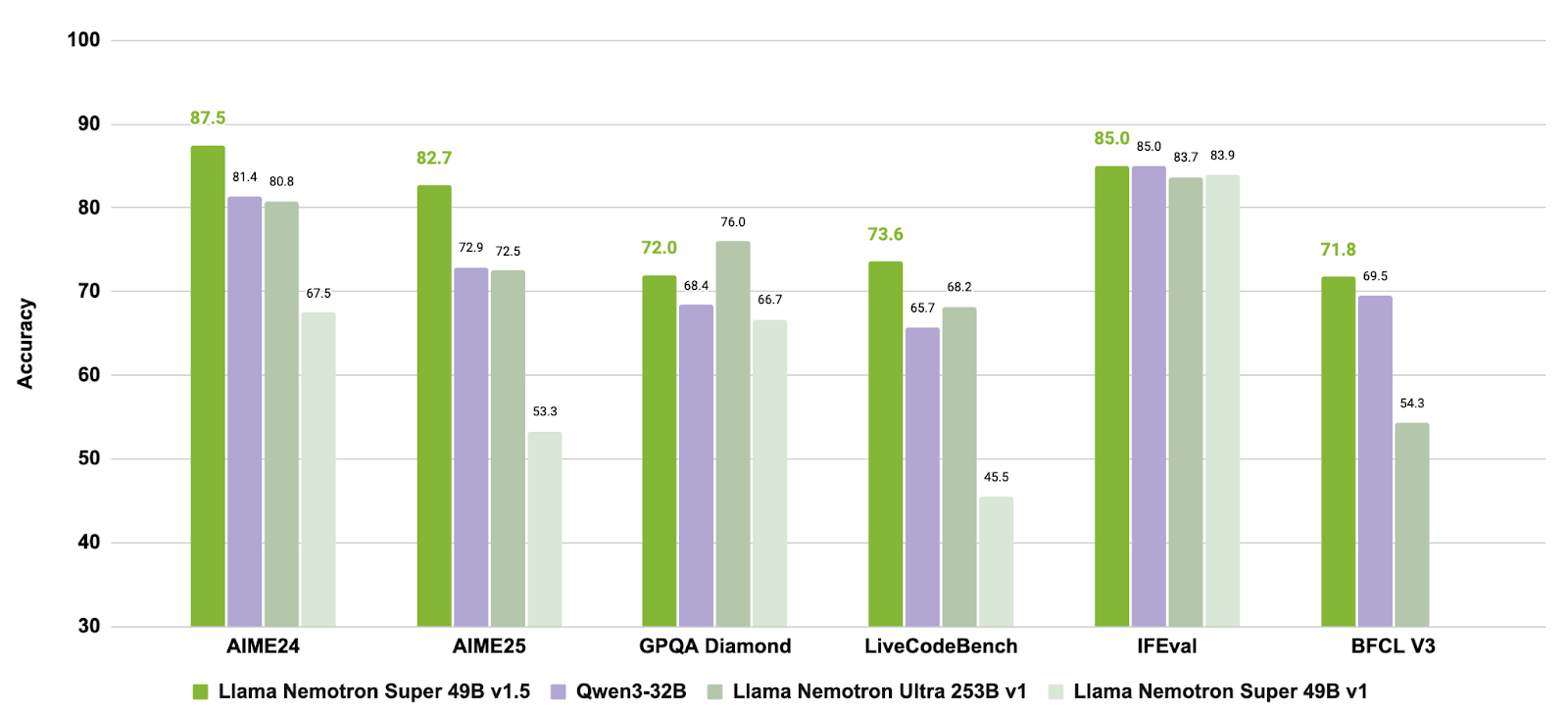
Bron: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Door gerichte post-training voor redenering en agentgedrag te combineren met ondersteuning voor lang-contexttaken, biedt Llama-3.3-Nemotron-Super-49B-v1.5 een uitgebalanceerde oplossing voor developers die geavanceerde redeneercapaciteiten en robuust toolgebruik nodig hebben zonder runtime-efficiëntie op te offeren.
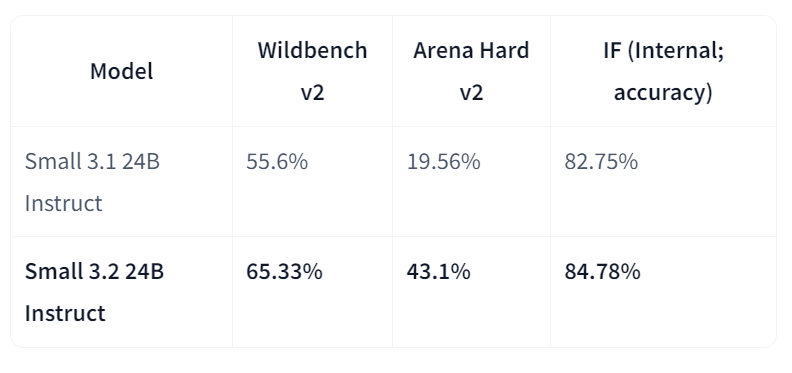
Mistral-Small-3.2-24B-Instruct-2506 is een aanzienlijke upgrade ten opzichte van Mistral-Small-3.1-24B-Instruct-2503, met betere instructie-opvolging, minder herhalingsfouten en een robuuster function-calling-sjabloon, terwijl de algehele capaciteiten behouden blijven of licht verbeteren. Als een instructiemodel met 24B parameters is het breed beschikbaar op verschillende platforms, inclusief AWS-marktplaatsen, waar het bekendstaat om verbeterde instructietrouw.
Bron: mistralai/Mistral-Small-3.2-24B-Instruct-2506
In directe vergelijking met versie 3.1 toont Small-3.2 duidelijke vooruitgang in assistentkwaliteit en betrouwbaarheid. De prestatie in instructie-opvolging stijgt op Wildbench v2 (van 55,6% naar 65,33%) en Arena Hard v2 (van 19,56% naar 43,1%), terwijl de interne instructienauwkeurigheid toeneemt van 82,75% naar 84,78%. Herhalingsfouten op uitdagende prompts halveren (van 2,11% naar 1,29%). Ondertussen blijven STEM-prestaties vergelijkbaar, met MATH op 69,42% en HumanEval+ Pass@5 op 92,90%.
In de onderstaande tabel zie je een vergelijking van de topmodellen:
| Model | Belangrijkste sterke punten | Opvallende upgrades / functies |
|---|---|---|
| GLM 4.6 | Sterke redenering, agentische workflows en codeercapaciteiten | Contextvenster uitgebreid van 128K → 200K; verbeterde benchmarkprestaties t.o.v. GLM-4.5 en DeepSeek-V3.1 |
| gpt-oss-120B | Open-weight GPT-model voor geavanceerde redenering en agentische taken | Instelbare redeneerdiepte, chain-of-thought-toegang, function calling en harmony response format |
| Qwen3-235B-Instruct-2507 | Meertalig, zeer precieze redenering en instructie-opvolging | 1M+ tokencontext, voorkeur-gealigneerd schrijven, beter dan GPT-4o en Claude Opus 4 (non-thinking) |
| DeepSeek-V3.2-Exp | Efficiënte lang-contextverwerking via sparse attention | Evenaart V3.1-prestaties met minder compute; geoptimaliseerde transformer-efficiëntie |
| DeepSeek-R1-0528 | Geavanceerde redenering, wiskunde en programmeervermogen | 17,5% verbetering op AIME 2025; grotere analytische diepte en betrouwbaarder coderen |
| Apriel-1.5-15B-Thinker | Multimodale (tekst + beeld) redenering op een enkele GPU | Continue pretraining op tekst en beeld; frontier-niveau redenering voor compact model |
| Kimi-K2-Instruct-0905 | High-end redenering en agentgebaseerde code-workflows | 256K-tokencontext, betere ontwikkelaarservaring en ondersteuning voor tool-augmented taken |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Gebalanceerd model voor redenering en toolgebruik | Door NVIDIA getuned voor RAG en agentische toepassingen; lang-contextondersteuning tot 128K tokens |
| Mistral-Small-3.2-24B-Instruct-2506 | Compact en betrouwbaar in instructie-opvolging | Minder herhalingsfouten (−50%) en grote winst op WildBench v2 en Arena Hard v2 |
Het open-source LLM-landschap groeit razendsnel. Vandaag de dag zijn er veel meer open-source LLM’s dan proprietaire, en het prestatienadeel kan snel verdwijnen naarmate ontwikkelaars wereldwijd samenwerken om huidige LLM’s te upgraden en meer geoptimaliseerde te ontwerpen.
In deze levendige en spannende context kan het lastig zijn om de juiste open-source LLM te kiezen voor jouw doeleinden. Hier is een lijst met factoren om over na te denken voordat je voor een specifiek open-source LLM kiest:
Open-source LLM’s zijn niet alleen voor individuele projecten of interesses. Nu de revolutie rond generatieve AI verder versnelt, erkennen bedrijven hoe belangrijk het is om deze tools te begrijpen en toe te passen. LLM’s zijn al fundamenten geworden voor geavanceerde AI-toepassingen, van chatbots tot complexe dataverwerking. Zorgen dat je team vaardig is in AI- en LLM-technologieën is niet langer alleen een concurrentievoordeel—het is een noodzaak om je bedrijf toekomstbestendig te maken.
Ben je teamleider of ondernemer en wil je je team versterken met AI- en LLM-expertise, dan biedt DataCamp for Business uitgebreide trainingsprogramma’s waarmee je medewerkers de vaardigheden opdoen om deze krachtige tools in te zetten. We bieden:
Investeren in AI- en LLM-upskilling vergroot niet alleen de capaciteiten van je team, maar positioneert je bedrijf ook aan de frontlinie van innovatie, zodat je het volledige potentieel van deze transformatieve technologieën kunt benutten. Neem contact op met ons team om een demo aan te vragen en vandaag nog te beginnen met het bouwen van je AI-ready workforce.
Open-source LLM’s zitten in een spannende beweging. Met hun snelle evolutie lijkt het generatieve AI-domein niet per se te worden gemonopoliseerd door de grote spelers die zich deze krachtige tools kunnen veroorloven.
We hebben hier acht open-source LLM’s gezien, maar het werkelijke aantal is veel hoger en groeit snel. Wij bij DataCamp blijven informatie bieden over het laatste nieuws in het LLM-domein, met cursussen, artikelen en tutorials over LLM’s. Bekijk voorlopig onze lijst met zorgvuldig geselecteerd materiaal:
Begin vandaag nog met je AI-reis!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
