
Cursus
Principes fondamentaux de l'IA
10 h
Le choix de modèles linguistiques open source plutôt que propriétaires présente de nombreux avantages à court et à long terme. Vous trouverez ci-dessous une liste des raisons les plus convaincantes :
L'une des principales préoccupations liées à l'utilisation de modèles linguistiques propriétaires est le risque de fuite de données ou d'accès non autorisé à des données sensibles par le fournisseur du modèle linguistique. En effet, plusieurs controverses ont déjà eu lieu concernant l'utilisation présumée de données personnelles et confidentielles à des fins de formation.
En utilisant un LLM open source, les entreprises seront seules responsables de la protection des données personnelles, car elles en conserveront le contrôle total.
La plupart des LLM propriétaires nécessitent une licence pour être utilisés. À long terme, cela peut représenter une dépense importante que certaines entreprises, en particulier les PME, pourraient ne pas être en mesure de supporter. Ce n'est pas le cas des LLM open source, qui sont généralement gratuits.
Il est toutefois important de noter que l'exécution des LLM nécessite des ressources considérables, même pour la seule inférence, ce qui signifie que vous devrez généralement payer pour l'utilisation de services cloud ou d'une infrastructure puissante.
Les entreprises qui choisissent les LLM open source auront accès au fonctionnement des LLM, y compris leur code source, leur architecture, leurs données d'entraînement et leur mécanisme d'entraînement et d'inférence. Cette transparence constitue la première étape pour un examen minutieux, mais également pour la personnalisation.
Étant donné que les LLM open source sont accessibles à tous, y compris leur code source, les entreprises qui les utilisent peuvent les personnaliser en fonction de leurs besoins spécifiques.
Le mouvement open source vise à démocratiser l'utilisation et l'accès aux technologies LLM et d'IA générative. Permettre aux développeurs d'examiner le fonctionnement interne des LLM est essentiel pour le développement futur de cette technologie. En réduisant les obstacles à l'entrée pour les codeurs du monde entier, les LLM open source peuvent favoriser l'innovation et améliorer les modèles en réduisant les biais et en augmentant la précision et les performances globales.
Suite à la popularisation des LLM, les chercheurs et les organismes de surveillance environnementale expriment leurs préoccupations concernant l'empreinte carbone et la consommation d'eau nécessaires au fonctionnement de ces technologies. Les LLM propriétaires publient rarement des informations sur les ressources nécessaires à leur formation et à leur fonctionnement, ni sur leur empreinte environnementale.
Grâce au LLM open source, les chercheurs ont davantage de possibilités d'accéder à ces informations, ce qui peut ouvrir la voie à de nouvelles améliorations visant à réduire l'empreinte environnementale de l'IA.
GLM-4.6 est un modèle linguistique de nouvelle génération qui succède au GLM-4.5. Il est conçu pour améliorer les flux de travail des agents, fournir une assistance solide en matière de codage, faciliter le raisonnement avancé et générer un langage naturel de haute qualité. Ce modèle est destiné à la fois aux environnements de recherche et de production. Il se concentre sur la compréhension dans un contexte plus large, l'inférence assistée par des outils et une rédaction qui s'aligne plus naturellement sur les préférences des utilisateurs.
Source :zai-org/GLM-4.6
Par rapport à GLM-4.5, GLM-4.6 apporte plusieurs améliorations significatives : la fenêtre contextuelle a été étendue de 128 000 à 200 000 tokens, ce qui permet d'effectuer des tâches agentives plus complexes. Les performances de codage ont également été améliorées, ce qui se traduit par des scores de référence plus élevés et des résultats plus solides dans les applications concrètes.
GLM-4.6 affiche des gains significatifs dans huit benchmarks publics liés aux agents, au raisonnement et au codage, surpassant GLM-4.5 et démontrant des avantages concurrentiels par rapport à des modèles de premier plan tels que DeepSeek-V3.1-Terminus et Claude Sonnet 4.
gpt-oss-120b est le modèle phare de la série gpt-oss, les modèles à poids ouvert d'OpenAI conçus pour le raisonnement avancé, les tâches agentives et les workflows de développement polyvalents. Cette série comprend deux versions : gpt-oss-120b, destinée à des cas d'utilisation généraux de niveau production qui nécessitent un raisonnement de haut niveau et peuvent fonctionner sur un seul GPU de 80 Go (avec 117 milliards de paramètres, dont 5,1 milliards actifs) ; et gpt-oss-20b, optimisée pour une latence réduite et des déploiements locaux ou spécialisés (avec 21 milliards de paramètres et 3,6 milliards actifs). Les deux modèles sont formés à l'aide du format Harmony Response et doivent être utilisés avec le cadre Harmony pour fonctionner efficacement.
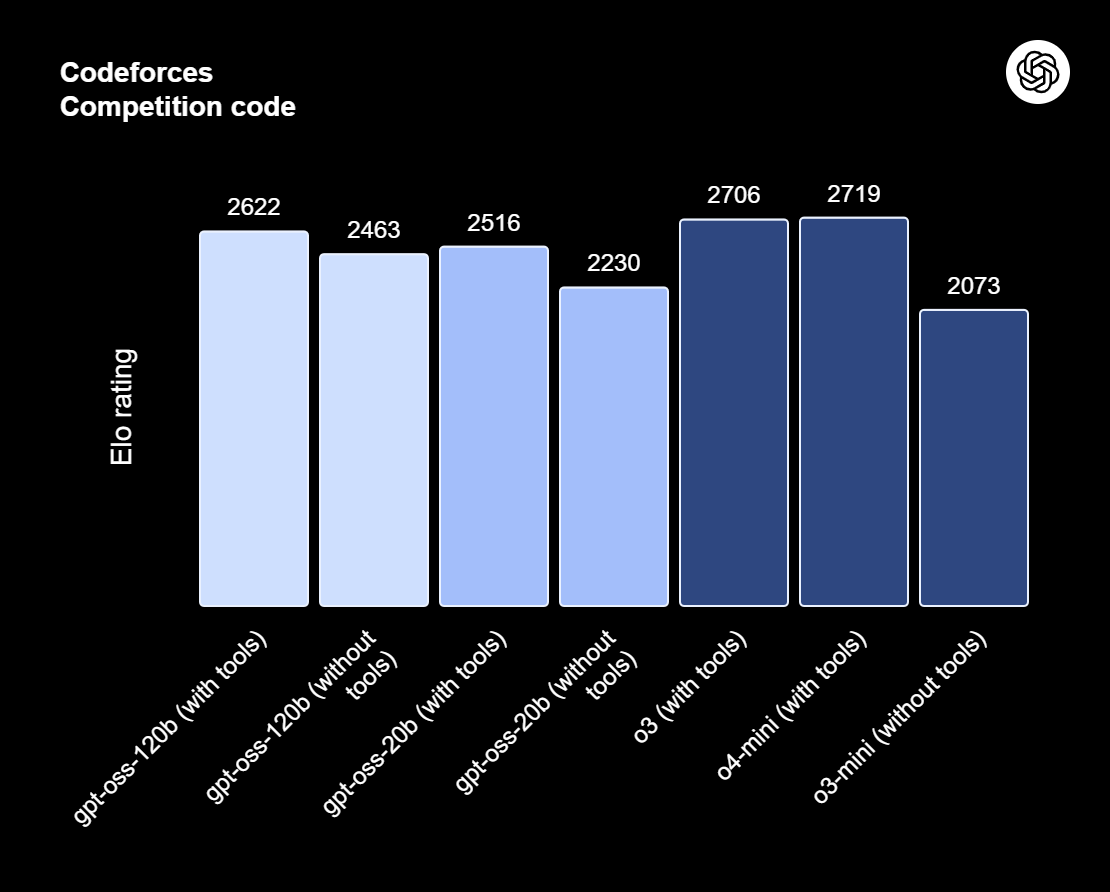
Source : Présentation de gpt-oss | OpenAI
Le gpt-oss-120b offre également des efforts de raisonnement configurables : faible, moyen ou élevé, afin d'équilibrer la profondeur et la latence. Il offre un accès complet à la chaîne de pensée à des fins de débogage et d'audit. Ces modèles peuvent être ajustés et sont dotés de capacités agentiques intégrées, telles que l'appel de fonctions, la navigation sur le Web, l'exécution de code Python et les sorties structurées.
Grâce à la quantification MXFP4 des poids MoE, gpt-oss-120b peut fonctionner sur un seul GPU de 80 Go, tandis que gpt-oss-20b peut fonctionner dans un environnement de 16 Go. Veuillez consulter notre article sur les 10 méthodes pour accéder gratuitement à GPT-OSS 120B.
Qwen3-235B-A22B-Instruct-2507 est le modèle phare sans capacité de réflexion de la famille Qwen3-MoE. Il est conçu pour suivre des instructions avec une grande précision, effectuer des raisonnements logiques rigoureux, comprendre des textes multilingues, traiter des mathématiques, des sciences, du codage, utiliser des outils et accomplir des tâches nécessitant des contextes très longs. Il s'agit d'un modèle linguistique causal mixte d'experts (MoE) comportant un total de 235 milliards de paramètres, dont 22 milliards sont actifs (utilisant 128 experts, dont 8 actifs à la fois). Le modèle comprend 94 couches, inclut un mécanisme GQA avec 64 têtes de requête et 4 têtes clé-valeur, et dispose d'une fenêtre contextuelle native de 262 000 jetons, qui peut être étendue à environ 1,01 million de jetons.
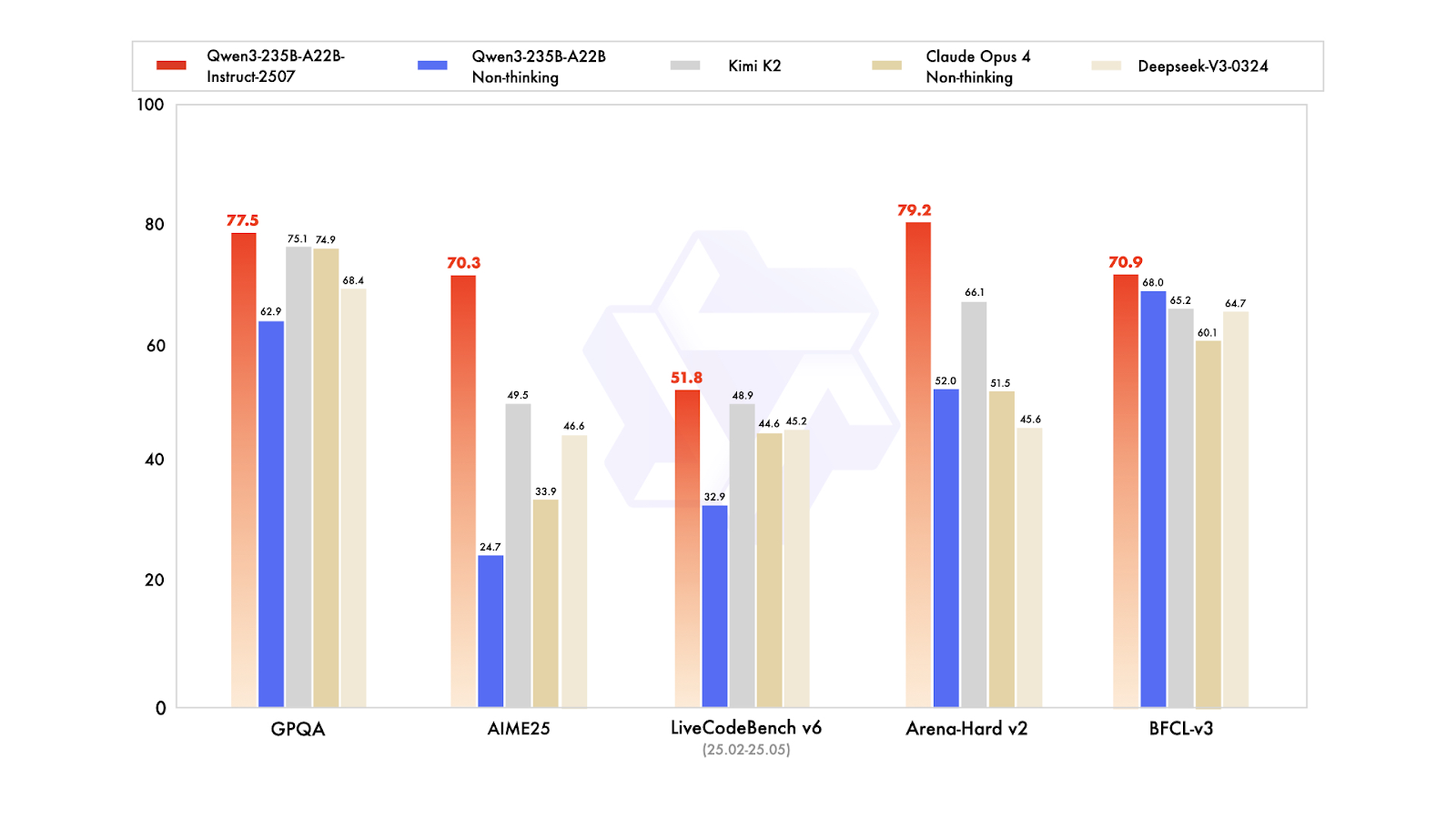
La dernière mise à jour Instruct-2507 apporte des améliorations significatives aux capacités générales et élargit la couverture des connaissances à longue traîne dans plusieurs langues. Il offre également un alignement des préférences nettement amélioré pour les tâches ouvertes et améliore la qualité de l'écriture, en particulier pour la compréhension de contextes longs de plus de 256 000 caractères.
Dans les tests de performance publics, il affiche des résultats remarquables. Dans la pratique, cela positionne Instruct-2507 comme un modèle non pensant de premier plan, surpassant à la fois la variante non pensante précédente Qwen3-235B-A22B et ses principaux concurrents tels que DeepSeek-V3, GPT-4o, Claude Opus 4 (non pensant) et Kimi K2.
Vous pouvez en savoir plus sur Qwen3 dans notre article complet.
DeepSeek-V3.2-Exp est une version intermédiaire expérimentale qui mènera à la prochaine génération de l'architecture DeepSeek. Il s'appuie sur V3.1-Terminus et introduit DeepSeek Sparse Attention afin d'améliorer l'efficacité de la formation et de l'inférence, en particulier dans les scénarios à contexte long. Ce modèle vise à améliorer l'efficacité du transformateur pour des séquences prolongées tout en conservant la qualité de sortie attendue de la gamme Terminus.
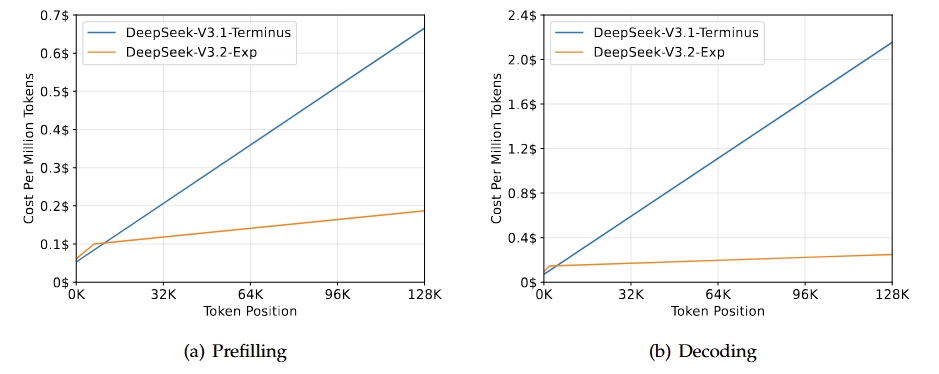
Source : DeepSeek-V3.2-Exp
Le principal résultat de cette version est qu'elle correspond aux capacités globales de la version 3.1-Terminus tout en offrant des améliorations significatives en termes d'efficacité pour les tâches à contexte long. Les évaluations et les analyses réalisées par des tiers indiquent que ses performances sont comparables à celles de Terminus, avec une réduction notable des coûts de calcul. Cela confirme qu'une attention modérée peut améliorer l'efficacité sans compromettre la qualité.
Veuillez consulter notre guide complet sur DeppSeek-V3.2-Exp pour travailler sur un projet de démonstration.
DeepSeek-R1 a bénéficié d'une mise à jour mineure vers la version DeepSeek-R1-0528, qui améliore ses capacités de raisonnement et d'inférence grâce à une puissance de calcul accrue et à des optimisations algorithmiques post-formation. En conséquence, des améliorations significatives ont été observées dans divers domaines, notamment les mathématiques, la programmation et la logique générale. Les performances globales se rapprochent désormais de celles des systèmes leaders tels que O3 et Gemini 2.5 Pro.
Outre les capacités brutes, cette mise à jour met l'accent sur l'utilité pratique grâce à de meilleurs workflows d'appel de fonctions et de codage, reflétant ainsi une volonté de produire des résultats plus fiables et axés sur la productivité.
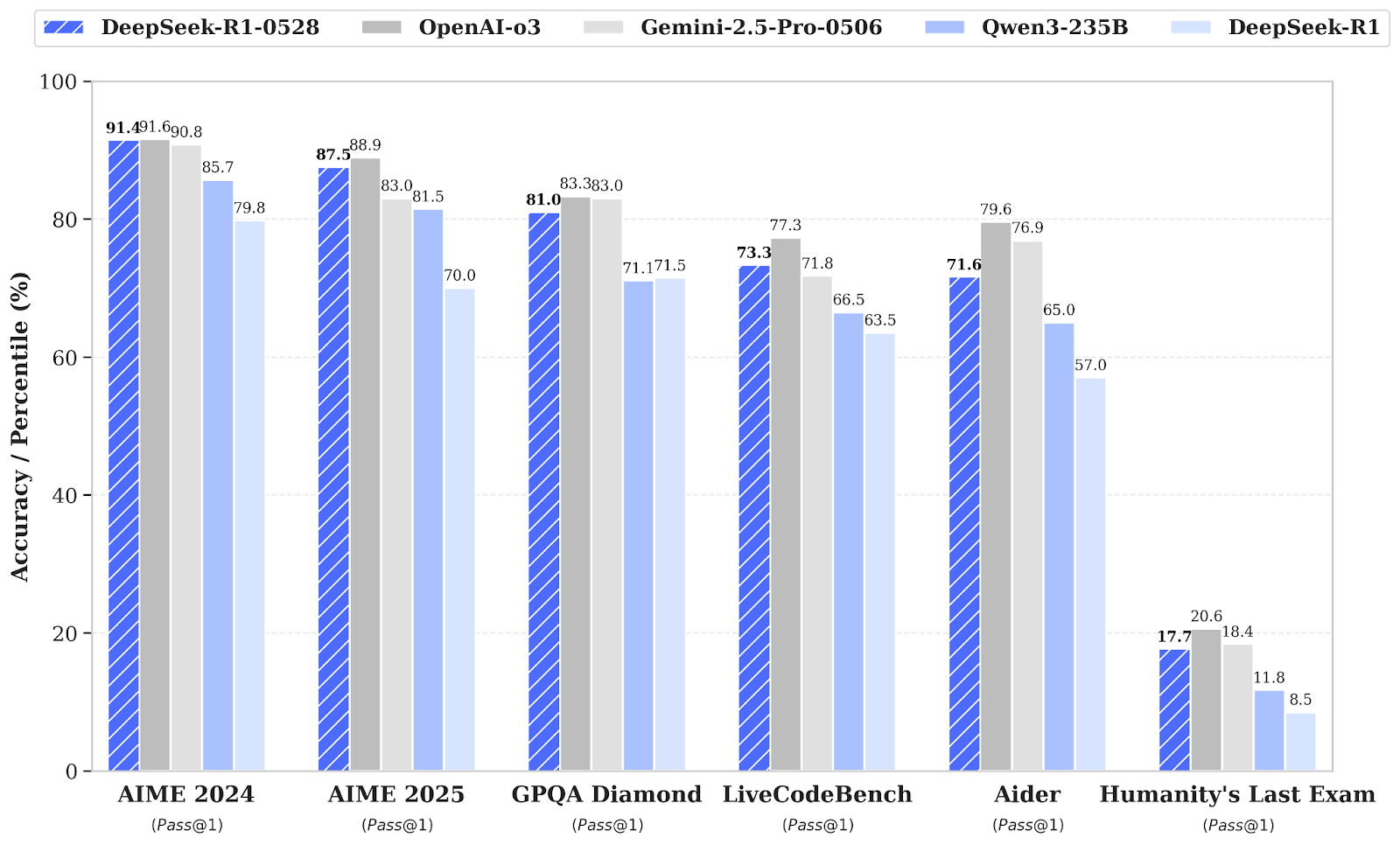
Source : deepseek-ai/DeepSeek-R1-0528
Par rapport à la version précédente DeepSeel R1, le modèle amélioré présente des progrès substantiels en matière de raisonnement complexe. Par exemple, lors de l'examen AIME 2025, la précision est passée de 70 % à 87,5 %, grâce à une réflexion analytique plus approfondie (le nombre moyen de jetons par question étant passé d'environ 12 000 à 23 000).
Des évaluations plus larges montrent également des tendances positives dans des domaines tels que les connaissances, le raisonnement et les performances en codage. Parmi les exemples, citons les améliorations apportées à LiveCodeBench, aux classements Codeforces, à SWE Verified et à Aider-Polyglot, qui témoignent d'une meilleure capacité à résoudre des problèmes et de compétences supérieures en matière de codage dans le monde réel.
Apriel-1.5-15b-Thinker est un modèle de raisonnement multimodal de la série Apriel SLM de ServiceNow. Il offre des performances compétitives avec seulement 15 milliards de paramètres, visant des résultats de pointe dans les limites d'un budget GPU unique. Ce modèle ajoute non seulement des capacités de raisonnement visuel au modèle précédent, qui ne traitait que du texte, mais il renforce également ses capacités de raisonnement textuel.
En tant que deuxième modèle de la série Reasoning, il a fait l'objet d'un pré-entraînement continu et approfondi dans les domaines du texte et de l'image. La phase post-formation comprend un ajustement supervisé (SFT) basé uniquement sur du texte, sans aucun SFT spécifique aux images ni apprentissage par renforcement. Malgré ces contraintes, le modèle vise une qualité de pointe en matière de raisonnement textuel et visuel pour sa taille.
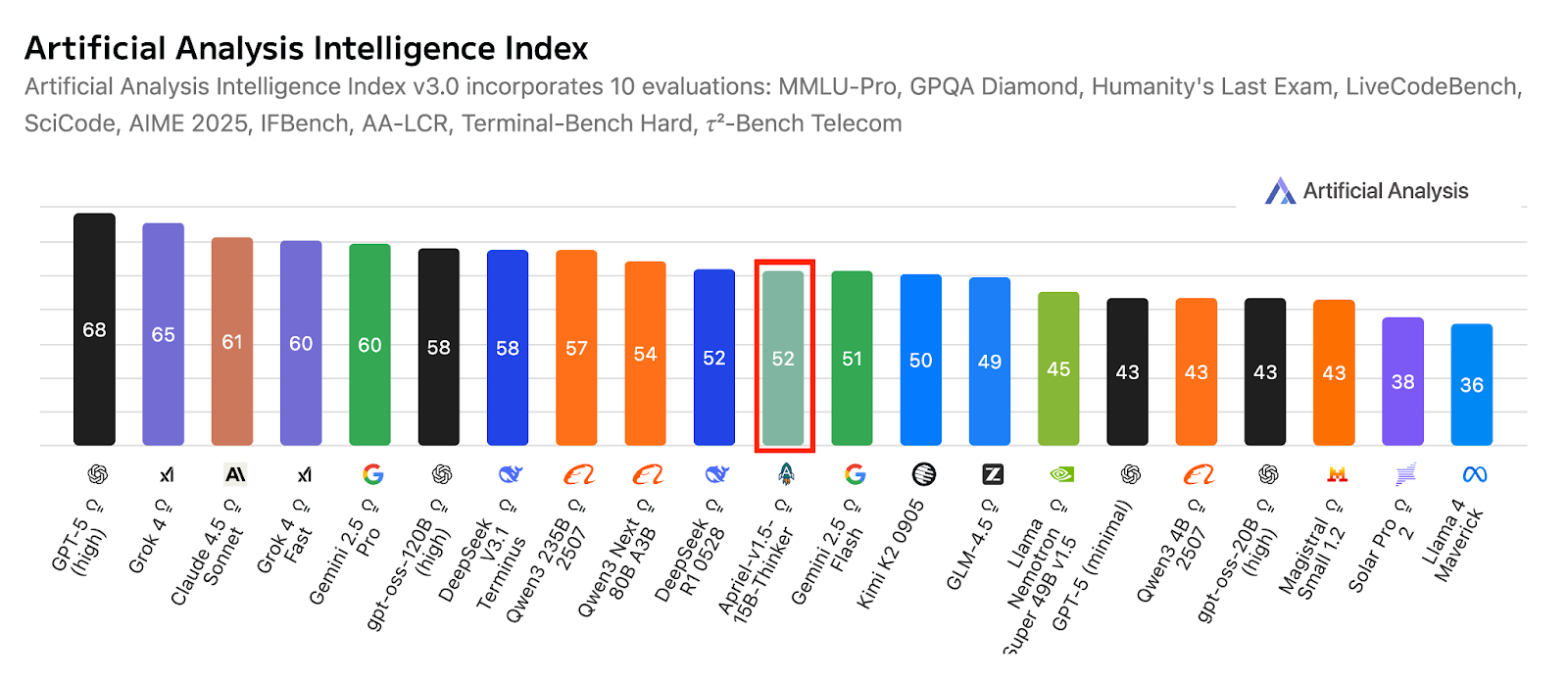
Source : ServiceNow-AI/Apriel-1.5-15b-Thinker
Conçu pour fonctionner sur un seul GPU, il privilégie le déploiement pratique et l'efficacité. Les résultats de l'évaluation indiquent une forte aptitude à être utilisé dans des applications concrètes, avec un score de 52 sur l'indice d'analyse artificielle, ce qui positionne le modèle de manière compétitive par rapport à des systèmes beaucoup plus importants. Ce score reflète également sa couverture par rapport à ses principaux concurrents compacts et pionniers, tout en conservant un format réduit adapté à une utilisation en entreprise.
Kimi-K2-Instruct-0905 est le modèle le plus récent et le plus perfectionné de la gamme Kimi K2. Il s'agit d'un modèle linguistique de pointe de type « Mixture-of-Experts », comprenant un total de 1 billion de paramètres et 32 milliards de paramètres activés. Ce modèle est spécialement conçu pour les processus de raisonnement et de codage haut de gamme.
K2-Instruct-0905 améliore considérablement la capacité de K2 à traiter des tâches à long terme grâce à une fenêtre contextuelle de 256 000 jetons, soit une augmentation par rapport aux 128 000 jetons précédents. Il vise à prendre en charge des cas d'utilisation robustes basés sur des agents, notamment le chat assisté par des outils et l'aide au codage. En tant que produit phare de la série K2 Instruct, il met l'accent sur une ergonomie et une fiabilité optimales pour les développeurs, afin de garantir des applications de qualité professionnelle.
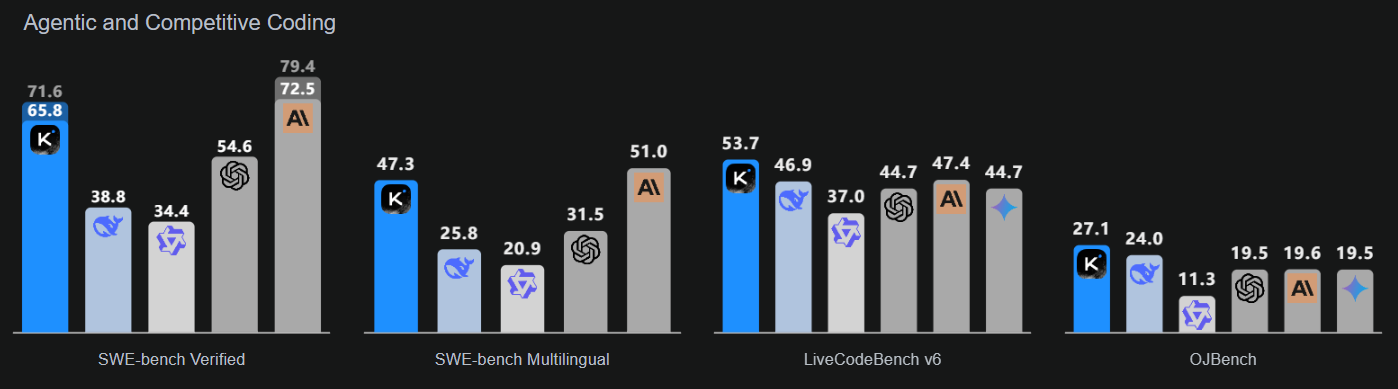
Source : Kimi K2 : Intelligence artificielle ouverte
Ce modèle met l'accent sur trois domaines clés : une intelligence de codage améliorée pour les tâches basées sur des agents, qui montre des améliorations notables dans les benchmarks publics et les applications du monde réel ; une interface utilisateur améliorée qui renforce à la fois l'esthétique et la fonctionnalité ; et une longueur de contexte étendue à 256 000 tokens qui permet des boucles de planification et d'édition plus étendues.
Llama-3_3-Nemotron-Super-49B-v1_5 est un modèle amélioré de 49 milliards de paramètres de la gamme Nemotron de NVIDIA, dérivé du modèle Llama-3.3-70B-Instruct de Meta. Il est spécialement conçu comme modèle de raisonnement pour les tâches de chat et d'agent alignées sur l'humain, telles que la génération augmentée par la récupération (RAG) et l'appel d'outils.
Ce modèle a subi une formation complémentaire afin d'améliorer ses capacités de raisonnement, l'alignement des préférences et l'utilisation des outils. Il prend également en charge les flux de travail à contexte long pouvant atteindre 128 000 jetons, ce qui le rend adapté aux applications complexes en plusieurs étapes.
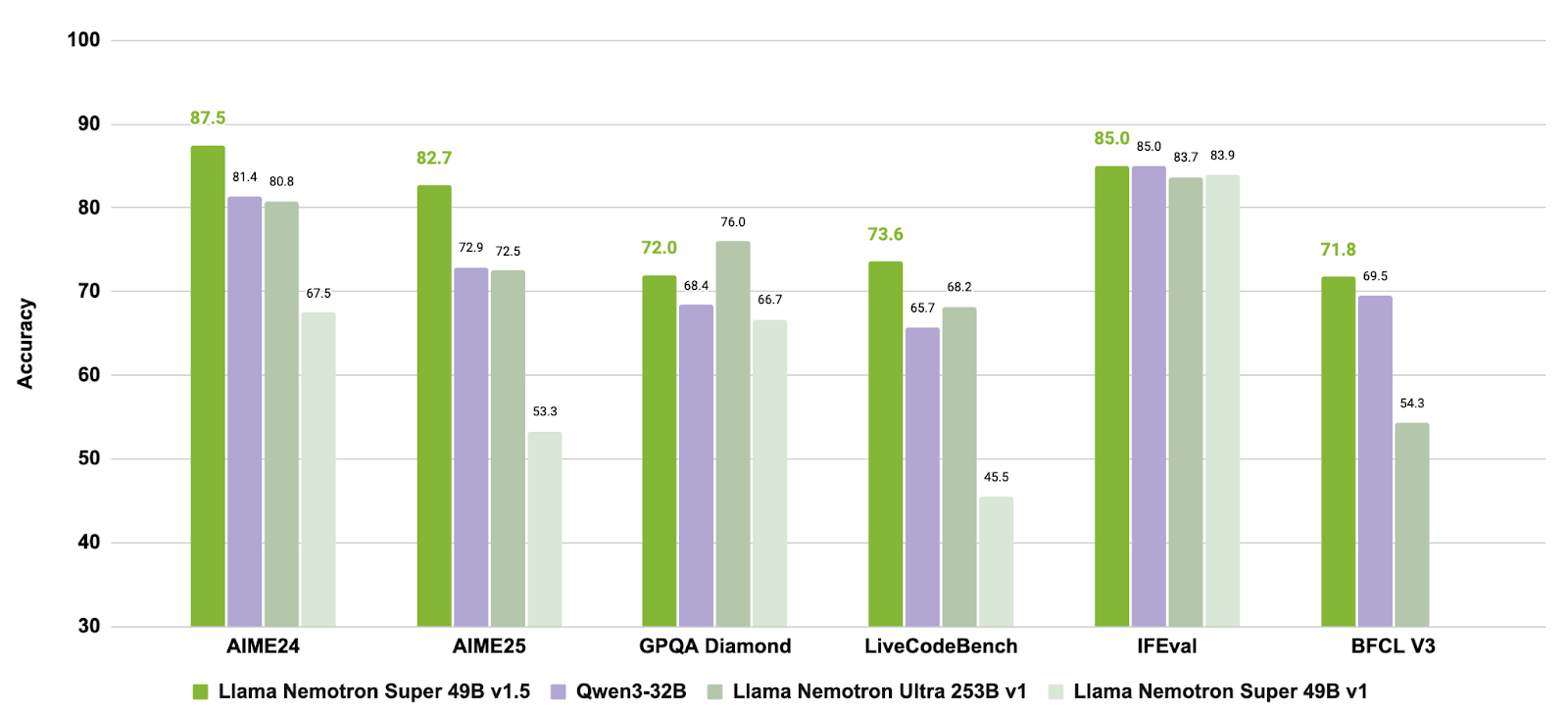
Source : nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
En combinant une formation postérieure ciblée sur le raisonnement et les comportements des agents avec une prise en charge des tâches à contexte long, Llama-3.3-Nemotron-Super-49B-v1.5 offre une solution équilibrée aux développeurs qui ont besoin de capacités de raisonnement avancées et d'outils robustes sans sacrifier l'efficacité d'exécution.
Mistral-Small-3.2-24B-Instruct-2506 représente une mise à niveau significative par rapport à Mistral-Small-3.1-24B-Instruct-2503, améliorant le suivi des instructions, réduisant les erreurs de répétition et fournissant un modèle d'appel de fonction plus robuste, tout en conservant ou en améliorant légèrement les capacités globales. En tant que modèle d'instruction à 24 paramètres B, il est largement accessible sur toutes les plateformes, y compris les marchés AWS, où il est reconnu pour son amélioration de la conformité aux instructions.
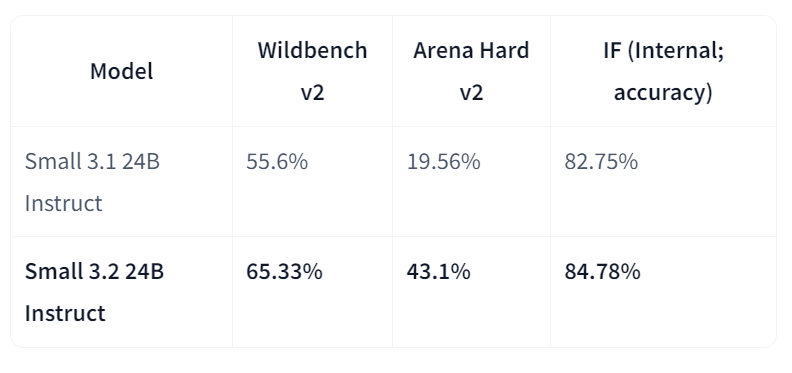
Source : mistralai/Mistral-Small-3.2-24B-Instruct-2506
En comparaison directe avec la version 3.1, Small-3.2 présente des améliorations notables en termes de qualité et de fiabilité de l'assistant. Il améliore les performances de suivi des instructions sur Wildbench v2 (de 55,6 % à 65,33 %) et Arena Hard v2 (de 19,56 % à 43,1 %), tandis que la précision interne du suivi des instructions passe de 82,75 % à 84,78 %. Les échecs de répétition sur les invites difficiles sont réduits de moitié (de 2,11 % à 1,29 %). Par ailleurs, les performances en STEM restent comparables, avec 69,42 % pour MATH et 92,90 % pour HumanEval+ Pass@5.
Dans le tableau ci-dessous, vous trouverez une comparaison des modèles haut de gamme :
| Modèle | Principaux atouts | Améliorations et fonctionnalités notables |
|---|---|---|
| GLM 4.6 | Raisonnement solide, flux de travail proactifs et capacités de codage | Fenêtre de contexte étendue de 128 Ko à 200 Ko ; amélioration des performances de référence par rapport à GLM-4.5 et DeepSeek-V3.1 |
| gpt-oss-120B | Modèle GPT à poids ouvert pour le raisonnement avancé et les tâches d'agent | Profondeur de raisonnement configurable, accès à la chaîne de pensée, appel de fonction et format de réponse harmonieux. |
| Qwen3-235B-Instruct-2507 | Raisonnement multilingue de haute précision et respect des instructions | Contexte de plus d'un million de jetons, rédaction alignée sur les préférences, surpassant GPT-4o et Claude Opus 4 (sans réflexion) |
| DeepSeek-V3.2-Exp | Traitement efficace de contextes longs via l'attention clairsemée | Performances équivalentes à celles de la version V3.1 avec une puissance de calcul réduite ; efficacité du transformateur optimisée. |
| DeepSeek-R1-0528 | Capacités avancées en matière de raisonnement, de mathématiques et de programmation | Amélioration de 17,5 % de l'AIME 2025 ; profondeur analytique et fiabilité du codage renforcées. |
| Avril-1.5-15B-Penseur | Raisonnement multimodal (texte + image) sur un seul GPU | Pré-entraînement continu sur du texte et des images ; raisonnement de pointe pour une taille de modèle compacte |
| Kimi-K2-Instruct-0905 | Raisonnement de pointe et flux de travail de codage basés sur des agents | Contexte de jetons 256K, ergonomie améliorée pour les développeurs et assistance aux tâches améliorée par des outils |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Modèle équilibré de raisonnement et d'utilisation des outils | Optimisé par NVIDIA pour les applications RAG et agentic ; prise en charge de contextes longs jusqu'à 128 000 jetons |
| Mistral-Small-3.2-24B-Instruct-2506 | Suivi des instructions de manière compacte et fiable | Réduction des erreurs de répétition (−50 %) et gains importants sur WildBench v2 et Arena Hard v2 |
L'espace LLM open source connaît une expansion rapide. Aujourd'hui, il existe beaucoup plus de LLM open source que de LLM propriétaires, et l'écart de performances pourrait bientôt être comblé grâce à la collaboration des développeurs du monde entier pour améliorer les LLM actuels et en concevoir de plus optimisés.
Dans ce contexte dynamique et passionnant, il peut être difficile de sélectionner le modèle d'apprentissage automatique open source le mieux adapté à vos besoins. Voici une liste de certains des facteurs à prendre en considération avant de choisir un modèle LLM open source spécifique :
Les modèles linguistiques open source ne sont pas réservés aux projets ou aux intérêts individuels. Alors que la révolution de l'IA générative continue de s'accélérer, les entreprises reconnaissent l'importance cruciale de comprendre et de mettre en œuvre ces outils. Les LLM sont déjà devenus essentiels pour alimenter les applications d'IA avancées, des chatbots aux tâches complexes de traitement des données. Veiller à ce que votre équipe maîtrise les technologies d'IA et de LLM n'est plus seulement un avantage concurrentiel, c'est une nécessité pour assurer la pérennité de votre entreprise.
Si vous êtes chef d'équipe ou chef d'entreprise et que vous souhaitez doter votre équipe de compétences en matière d'IA et de LLM, DataCamp for Business propose des programmes de formation complets qui peuvent aider vos employés à acquérir les compétences nécessaires pour tirer parti de ces outils puissants. Nous proposons :
Investir dans l'amélioration des compétences en matière d'IA et de LLM permet non seulement de renforcer les capacités de votre équipe, mais également de positionner votre entreprise à la pointe de l'innovation, vous permettant ainsi d'exploiter pleinement le potentiel de ces technologies transformatrices. Veuillez contacter notre équipe pour demander une démonstration et commencer dès aujourd'hui à constituer votre main-d'œuvre prête pour l'IA.
Les modèles linguistiques open source connaissent actuellement un essor remarquable. Compte tenu de leur évolution rapide, il semble que le domaine de l'IA générative ne sera pas nécessairement monopolisé par les grands acteurs qui ont les moyens de développer et d'utiliser ces outils puissants.
Nous n'avons observé que huit modèles linguistiques open source, mais leur nombre est en réalité beaucoup plus élevé et augmente rapidement. Chez DataCamp, nous continuerons à fournir des informations sur les dernières actualités dans le domaine des LLM, en proposant des cours, des articles et des tutoriels sur les LLM. Pour l'instant, veuillez consulter notre liste de ressources sélectionnées :
Commencez votre parcours dans l'IA dès aujourd'hui !
Cursus
Cours
Cours
blog
blog
Lynn Heidmann
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel

