
Programa
Fundamentos da IA
10 h
Tem várias vantagens a curto e longo prazo em escolher LLMs de código aberto em vez de LLMs proprietários. Abaixo, você encontra uma lista das razões mais convincentes:
Uma das maiores preocupações com o uso de LLMs proprietários é o risco de vazamento de dados ou acesso não autorizado a dados confidenciais pelo provedor do LLM. Na verdade, já rolou várias polêmicas sobre o suposto uso de dados pessoais e confidenciais para fins de treinamento.
Ao usar LLM de código aberto, as empresas vão ser as únicas responsáveis pela proteção dos dados pessoais, já que vão manter o controle total sobre eles.
A maioria dos LLMs proprietários precisa de uma licença pra poder usar. No longo prazo, isso pode ser uma despesa importante que algumas empresas, especialmente as PMEs, podem não conseguir arcar. Isso não rola com os LLMs de código aberto, já que eles geralmente são de graça.
Mas é importante lembrar que usar LLMs precisa de muitos recursos, mesmo só pra inferência, o que quer dizer que você normalmente vai ter que pagar pra usar serviços em nuvem ou uma infraestrutura potente.
As empresas que escolherem LLMs de código aberto vão poder ver como os LLMs funcionam, incluindo o código-fonte, a arquitetura, os dados de treinamento e o mecanismo de treinamento e inferência. Essa transparência é o primeiro passo para a análise, mas também para a personalização.
Como os LLMs de código aberto estão disponíveis para todo mundo, incluindo o código-fonte, as empresas que os usam podem personalizá-los para seus casos de uso específicos.
O movimento de código aberto promete democratizar o uso e o acesso às tecnologias LLM e IA generativa. Permitir que os desenvolvedores vejam como os LLMs funcionam por dentro é essencial para o futuro dessa tecnologia. Ao diminuir as barreiras de entrada para programadores em todo o mundo, os LLMs de código aberto podem promover a inovação e melhorar os modelos, reduzindo preconceitos e aumentando a precisão e o desempenho geral.
Depois que os LLMs ficaram mais conhecidos, pesquisadores e grupos que cuidam do meio ambiente estão preocupados com a pegada de carbono e o consumo de água que essas tecnologias precisam para funcionar. Os LLMs proprietários raramente divulgam informações sobre os recursos necessários para treinar e operar LLMs, nem sobre o impacto ambiental associado.
Com o LLM de código aberto, os pesquisadores têm mais chances de saber sobre essas informações, o que pode abrir caminho para novas melhorias destinadas a reduzir o impacto ambiental da IA.
GLM-4.6 é um modelo de linguagem de última geração que vem depois do GLM-4.5. Ele foi feito pra melhorar os fluxos de trabalho dos agentes, dar uma força na codificação, facilitar o raciocínio avançado e criar uma linguagem natural de alta qualidade. O modelo é voltado tanto para ambientes de pesquisa quanto de produção, com foco na compreensão de contextos mais longos, inferência aprimorada por ferramentas e redação que se alinha de forma mais natural às preferências do usuário.
Fonte:zai-org/GLM-4.6
Comparado com o GLM-4.5, o GLM-4.6 traz várias melhorias importantes: a janela de contexto foi ampliada de 128K para 200K tokens, permitindo tarefas mais complexas para os agentes. O desempenho da codificação também foi aprimorado, gerando pontuações de benchmark mais altas e resultados mais sólidos em aplicações do mundo real.
O GLM-4.6 mostra ganhos claros em oito benchmarks públicos relacionados a agentes, raciocínio e codificação, superando o GLM-4.5 e mostrando vantagens competitivas em relação a modelos líderes, como DeepSeek-V3.1-Terminus e Claude Sonnet 4.
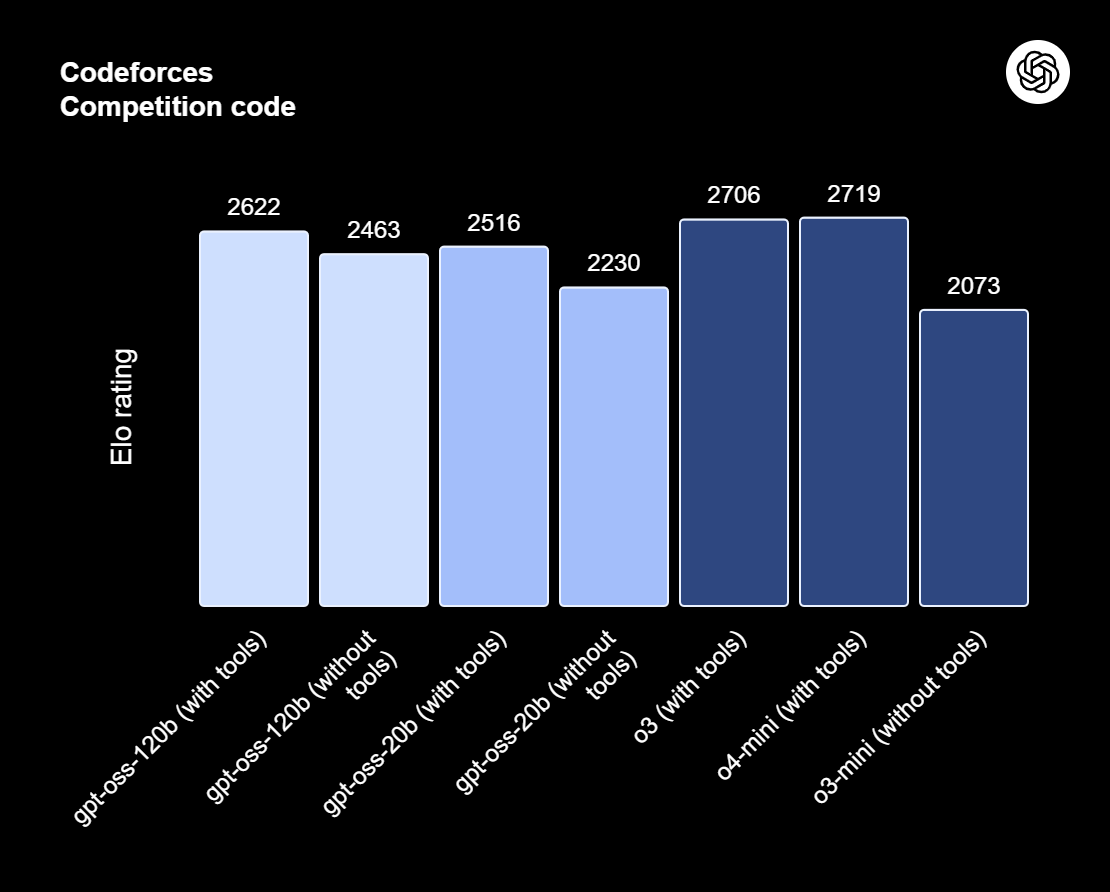
O gpt-oss-120b é o topo da linha da série gpt-oss — os modelos de peso aberto da OpenAI feitos para raciocínio avançado, tarefas de agência e fluxos de trabalho versáteis para desenvolvedores. Essa série tem duas versões: gpt-oss-120b, que é pra casos de uso de nível de produção e uso geral que precisam de raciocínio de alto nível e podem funcionar em uma única GPU de 80 GB (com 117 bilhões de parâmetros, sendo 5,1 bilhões ativos); e gpt-oss-20b, que é otimizada para menor latência e implantações locais ou especializadas (com 21 bilhões de parâmetros e 3,6 bilhões ativos). Os dois modelos são treinados usando o formato de resposta de harmonia e devem ser usados com a estrutura de harmonia para funcionar bem.
Fonte: Apresentando o gpt-oss | OpenAI
O gpt-oss-120b também oferece esforços de raciocínio configuráveis: baixo, médio ou alto, para equilibrar profundidade e latência. Ele dá acesso completo à cadeia de pensamento pra fins de depuração e auditoria. Esses modelos podem ser ajustados e vêm com recursos de agência integrados, como chamada de funções, navegação na web, execução de código Python e saídas estruturadas.
Graças à quantização MXFP4 dos pesos MoE, o gpt-oss-120b pode rodar em uma única GPU de 80 GB, enquanto o gpt-oss-20b pode funcionar em um ambiente de 16 GB. Dá uma olhada no nosso artigo sobre 10 maneiras de acessar o GPT-OSS 120B de graça.
Qwen3-235B-A22B-Instruct-2507 é o modelo principal sem raciocínio da família Qwen3-MoE, feito pra seguir instruções com muita precisão, raciocínio lógico rigoroso, entender textos em várias línguas, matemática, ciências, programação, usar ferramentas e tarefas que precisam de contextos bem longos. É uma mistura de especialistas (MoE) modelo de linguagem causal com um total de 235 bilhões de parâmetros, com 22 bilhões de parâmetros ativos (usando 128 especialistas com 8 ativos ao mesmo tempo). O modelo tem 94 camadas, inclui um mecanismo GQA com 64 cabeçalhos de consulta e 4 cabeçalhos de chave-valor, e tem uma janela de contexto nativa de 262.000 tokens, que pode ser estendida para aproximadamente 1,01 milhão de tokens.
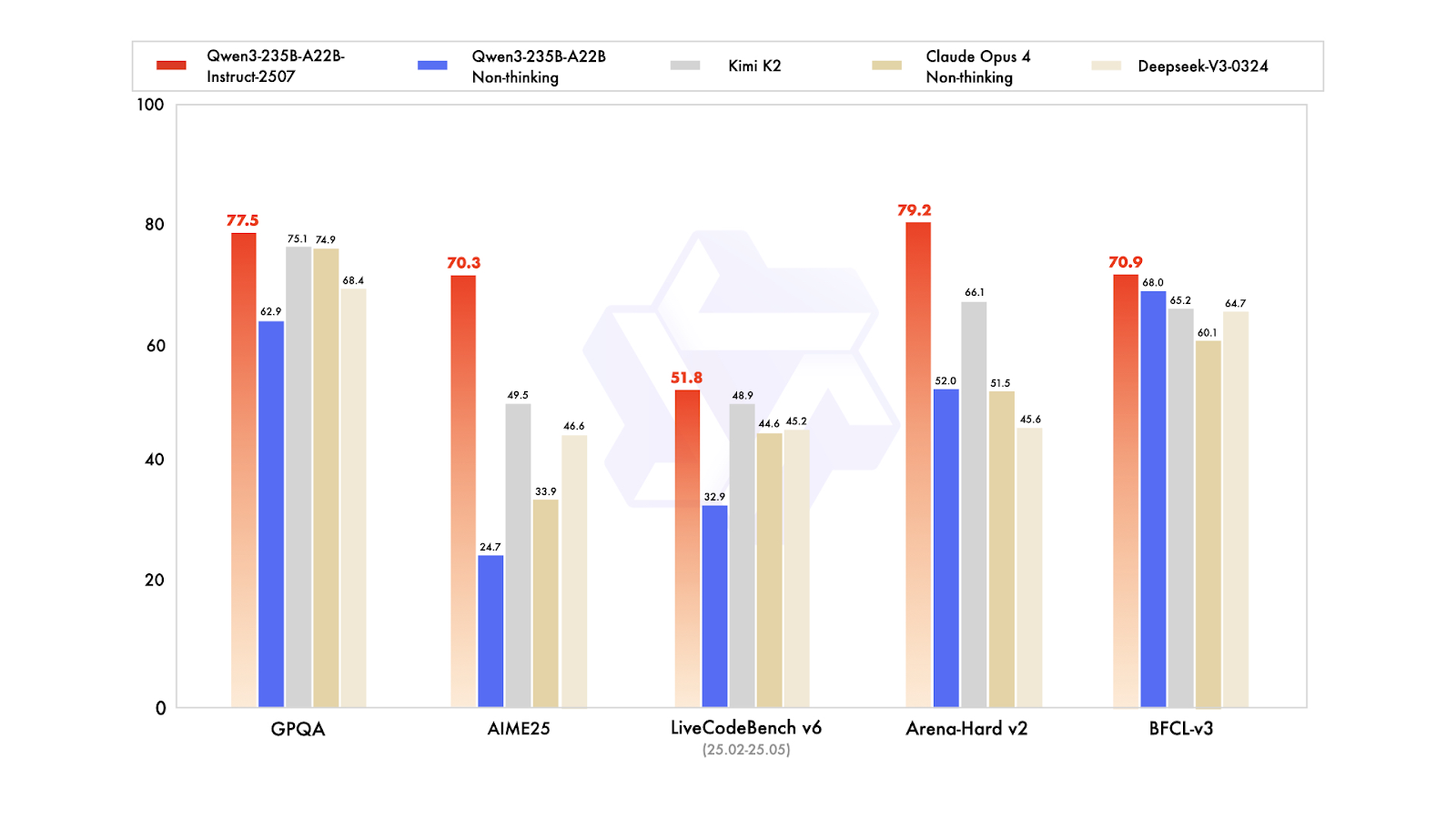
A última atualização do Instruct-2507 traz melhorias significativas nas capacidades gerais e amplia a cobertura de conhecimento de cauda longa em vários idiomas. Ele também oferece um alinhamento de preferências bem melhor para tarefas abertas e melhora a qualidade da escrita, principalmente para compreensão de contextos longos com mais de 256.000 caracteres.
Em benchmarks públicos, ele mostra resultados incríveis. Na prática, isso coloca o Instruct-2507 como um modelo não pensante de primeira linha, superando tanto a variante não pensante anterior Qwen3-235B-A22B quanto os principais concorrentes, como DeepSeek-V3, GPT-4o, Claude Opus 4 (não pensante) e Kimi K2.
Você pode saber mais sobre o Qwen3 no nosso artigo completo.
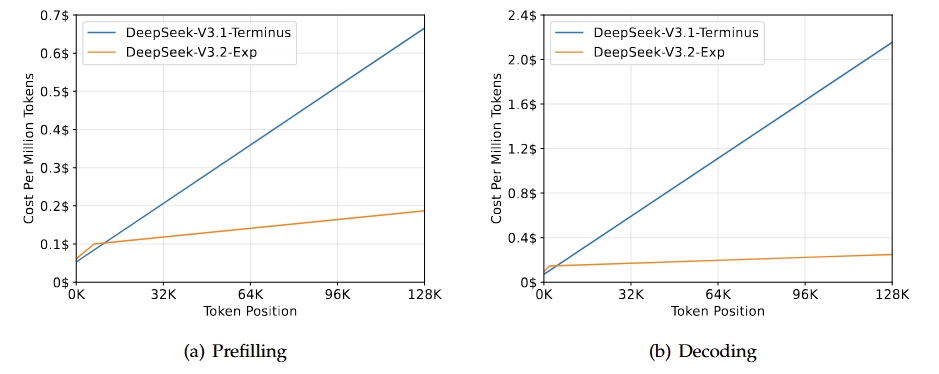
DeepSeek-V3.2-Exp é uma versão experimental intermediária que leva à próxima geração da arquitetura DeepSeek. Ele se baseia no V3.1-Terminus e traz o DeepSeek Sparse Attention para melhorar a eficiência do treinamento e da inferência, principalmente em cenários de contexto longo. Esse modelo quer melhorar a eficiência do transformador para sequências mais longas, mantendo a qualidade de saída esperada da linha Terminus.
Fonte: DeepSeek-V3.2-Exp
O principal resultado dessa versão é que ela tem as mesmas funcionalidades gerais da V3.1-Terminus, mas com melhorias significativas de eficiência para tarefas de contexto longo. Avaliações e análises de terceiros mostram que seu desempenho é comparável ao do Terminus, com uma redução notável nos custos computacionais. Isso mostra que prestar atenção só no que importa pode melhorar a eficiência sem prejudicar a qualidade.
Dá uma olhada no nosso guia completo do DeppSeek-V3.2-Exp pra ver como funciona num projeto de demonstração.
O DeepSeek-R1 recebeu uma pequena atualização de versão para DeepSeek-R1-0528, que melhora suas capacidades de raciocínio e inferência por meio de maior poder computacional e otimizações algorítmicas pós-treinamento. Como resultado, tem melhorias significativas em várias áreas, incluindo matemática, programação e lógica geral. O desempenho geral agora está mais próximo dos sistemas líderes, como O3 e Gemini 2.5 Pro.
Além dos recursos básicos, essa atualização dá uma ênfase na utilidade prática com melhores fluxos de trabalho de chamada de funções e codificação, mostrando um foco em produzir resultados mais confiáveis e voltados para a produtividade.
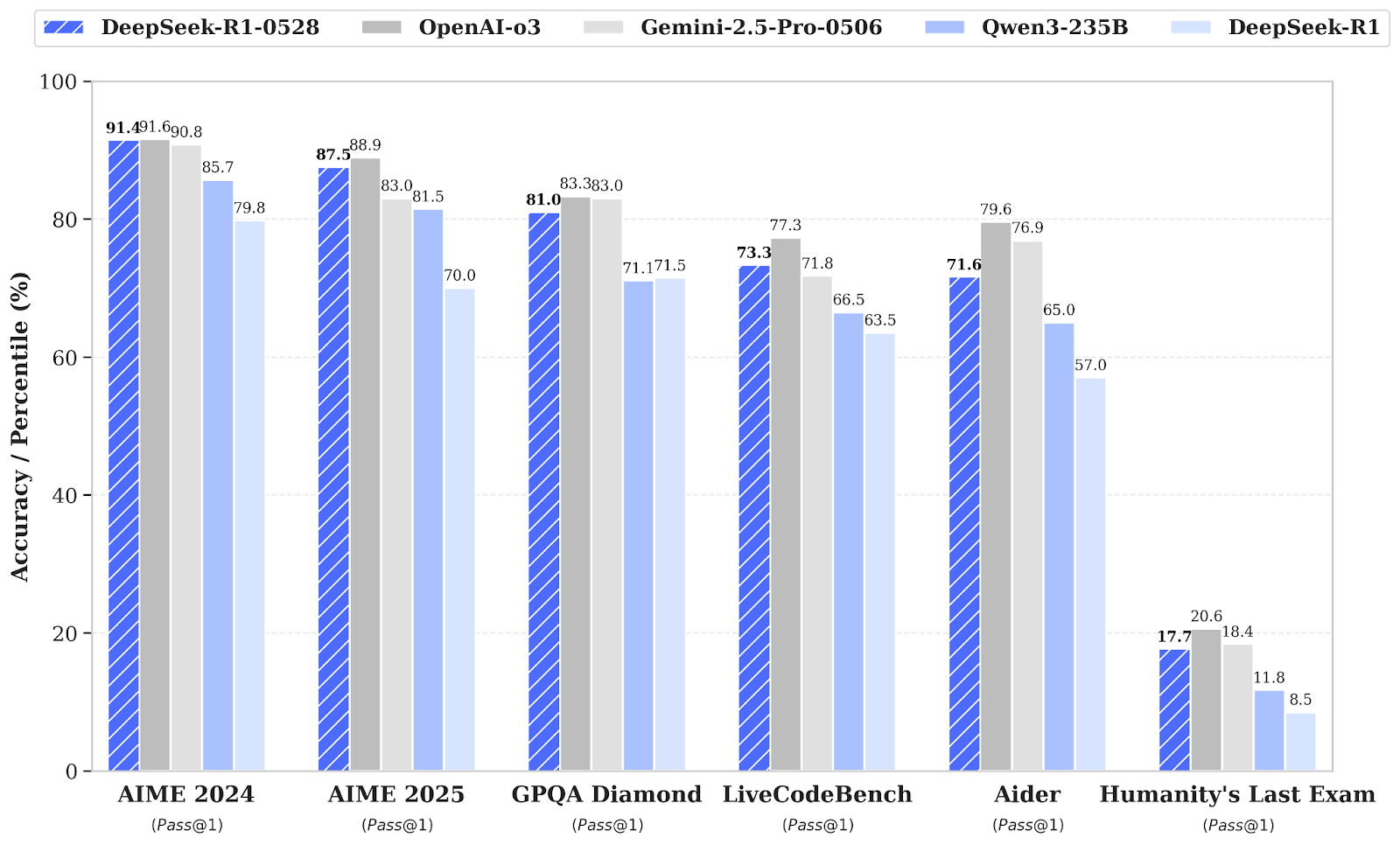
Fonte: deepseek-ai/DeepSeek-R1-0528
Comparado com a versão anterior do DeepSeel R1, o modelo atualizado mostra um progresso bem legal no raciocínio complexo. Por exemplo, no exame AIME 2025, a precisão melhorou de 70% para 87,5%, apoiada por um pensamento analítico mais profundo (com o número médio de tokens por questão aumentando de aproximadamente 12.000 para 23.000).
Avaliações mais amplas também mostram tendências positivas em áreas como conhecimento, raciocínio e desempenho em codificação. Exemplos incluem melhorias no LiveCodeBench, classificações Codeforces, SWE Verified e Aider-Polyglot, mostrando uma maior profundidade na resolução de problemas e habilidades superiores de codificação no mundo real.
Apriel-1.5-15b-Thinker é um modelo de raciocínio multimodal da série Apriel SLM da ServiceNow. Ele oferece desempenho competitivo com apenas 15 bilhões de parâmetros, buscando resultados de ponta dentro das limitações de um orçamento para uma única GPU. Esse modelo não só adiciona recursos de raciocínio por imagem ao modelo anterior, que era só de texto, mas também melhora suas habilidades de raciocínio textual.
Como segundo modelo da série de raciocínio, ele passou por um treinamento prévio intenso e contínuo nos domínios de texto e imagem. O pós-treinamento envolve um ajuste fino supervisionado (SFT) só com texto, sem nenhum SFT específico para imagens ou aprendizado por reforço. Apesar dessas limitações, o modelo visa a qualidade de ponta em raciocínio textual e visual para seu tamanho.
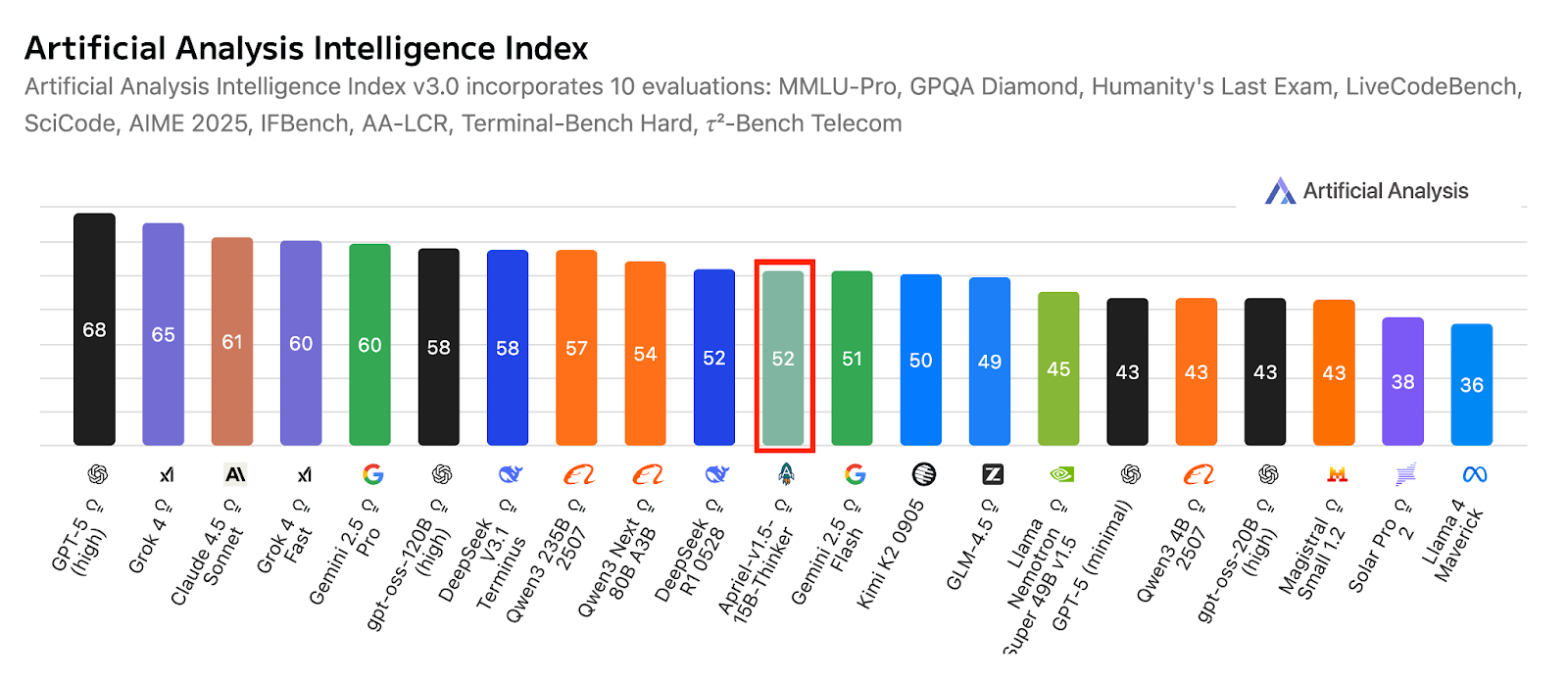
Fonte: ServiceNow-AI/Apriel-1.5-15b-Pensador
Feito pra rodar em uma única GPU, ele prioriza a implementação prática e a eficiência. Os resultados da avaliação mostram que o modelo está bem pronto pra ser usado no mundo real, com uma pontuação de 52 no índice de Análise Artificial, o que o deixa bem competitivo em relação a sistemas muito maiores. Essa pontuação também mostra como ele se sai em comparação com outros compactos e fronteiriços líderes, mantendo um tamanho pequeno que é ideal para uso corporativo.
Kimi-K2-Instruct-0905 é o modelo mais recente e avançado da linha Kimi K2. É um modelo de linguagem Mixture-of-Experts de última geração, com um total de 1 trilhão de parâmetros e 32 bilhões de parâmetros ativados. Esse modelo foi feito especialmente para fluxos de trabalho de raciocínio e codificação de ponta.
O K2-Instruct-0905 melhora bastante a capacidade do K2 de lidar com tarefas de longo prazo com uma janela de contexto de 256.000 tokens, um aumento em relação aos 128.000 tokens anteriores. O objetivo é dar suporte a casos de uso robustos baseados em agentes, que incluem chat aprimorado por ferramentas e assistência de código. Como lançamento principal da série K2 Instruct, ele se concentra em uma forte ergonomia para desenvolvedores e confiabilidade para aplicativos com qualidade de produção.
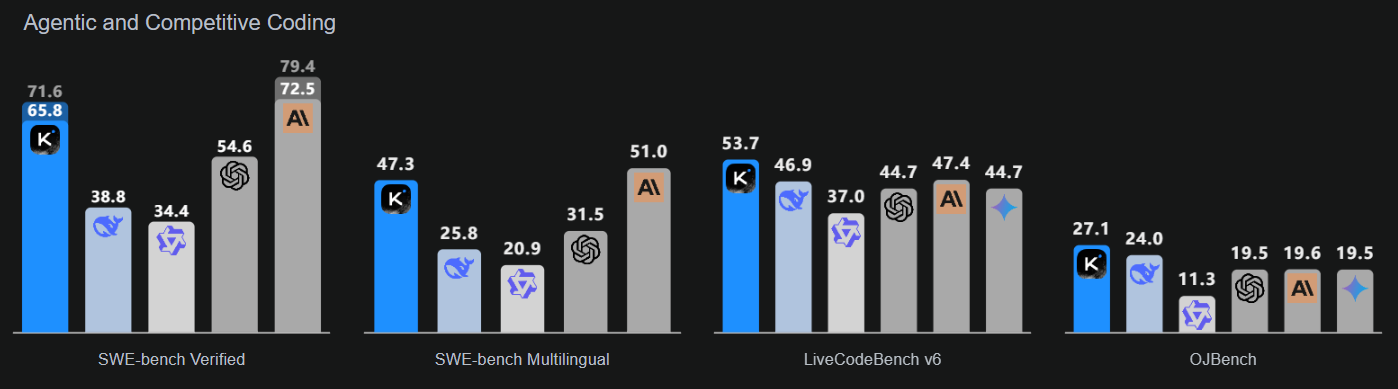
Fonte: Kimi K2: Inteligência Agente Aberta
Esse modelo dá destaque a três áreas principais: inteligência de codificação melhorada para tarefas baseadas em agentes, que mostra melhorias claras em benchmarks públicos e aplicações do mundo real; uma interface de usuário aprimorada que melhora tanto a estética quanto a funcionalidade; e um comprimento de contexto estendido de 256.000 tokens que permite loops de planejamento e edição mais extensos.
Llama-3_3-Nemotron-Super-49B-v1_5 é um modelo atualizado com 49 bilhões de parâmetros da linha Nemotron da NVIDIA, derivado do Llama-3.3-70B-Instruct da Meta. Ele foi feito especialmente como um modelo de raciocínio para bate-papos e tarefas de agentes que se alinham com o ser humano, como geração aumentada por recuperação (RAG) e chamada de ferramentas.
Esse modelo passou por um pós-treinamento para melhorar suas habilidades de raciocínio, alinhamento de preferências e uso de ferramentas. Ele também suporta fluxos de trabalho de contexto longo de até 128.000 tokens, tornando-o adequado para aplicações complexas e com várias etapas.
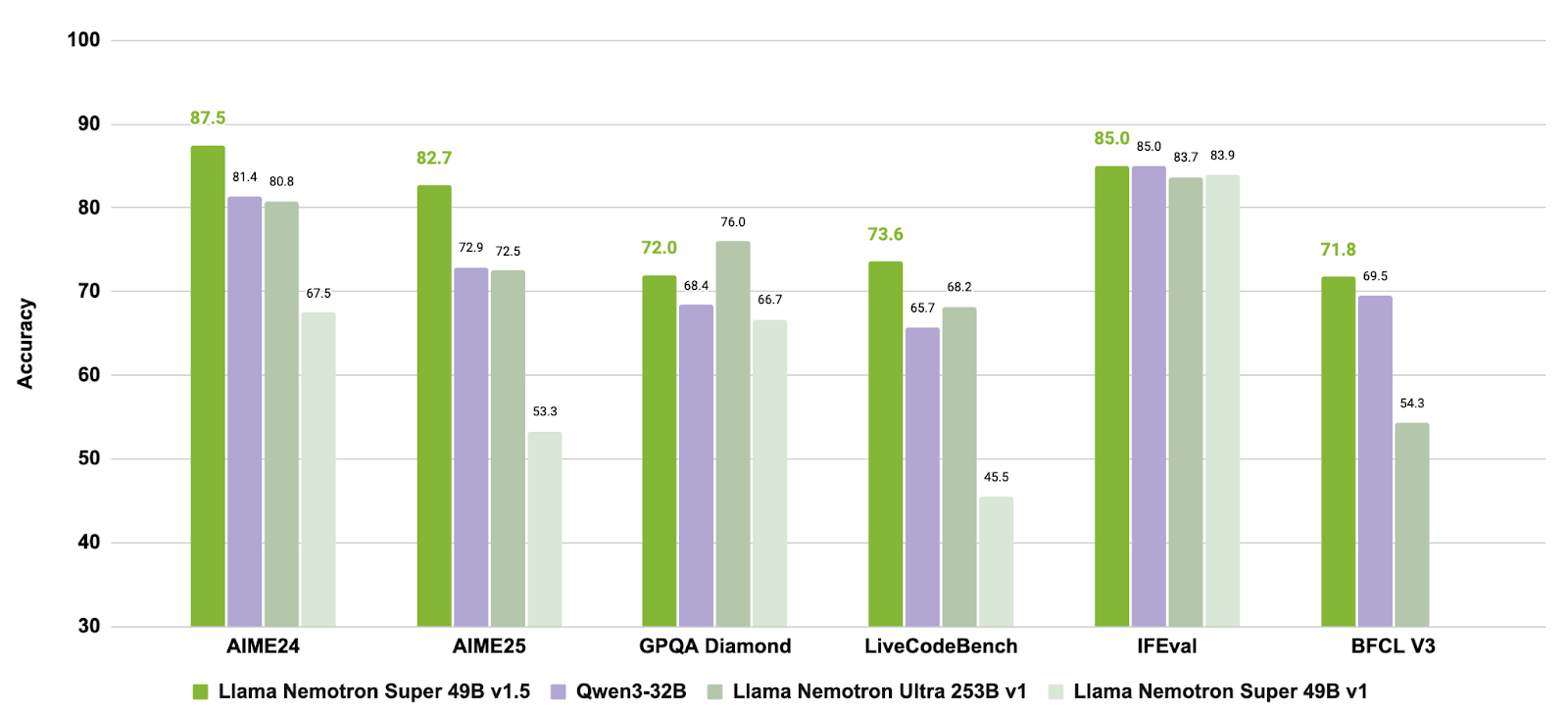
Fonte: nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
Ao juntar um pós-treinamento direcionado para raciocínio e comportamentos de agentes com suporte para tarefas de contexto longo, o Llama-3.3-Nemotron-Super-49B-v1.5 oferece uma solução equilibrada para desenvolvedores que precisam de recursos avançados de raciocínio e uso robusto de ferramentas sem perder a eficiência de tempo de execução.
Mistral-Small-3.2-24B-Instruct-2506 é uma atualização importante em relação ao Mistral-Small-3.1-24B-Instruct-2503, melhorando o seguimento de instruções, reduzindo erros de repetição e oferecendo um modelo de chamada de função mais robusto, tudo isso enquanto mantém ou melhora um pouco as capacidades gerais. Como um modelo de instrução com 24B parâmetros, ele é bem acessível em várias plataformas, incluindo os mercados da AWS, onde é conhecido por melhorar a aderência às instruções.
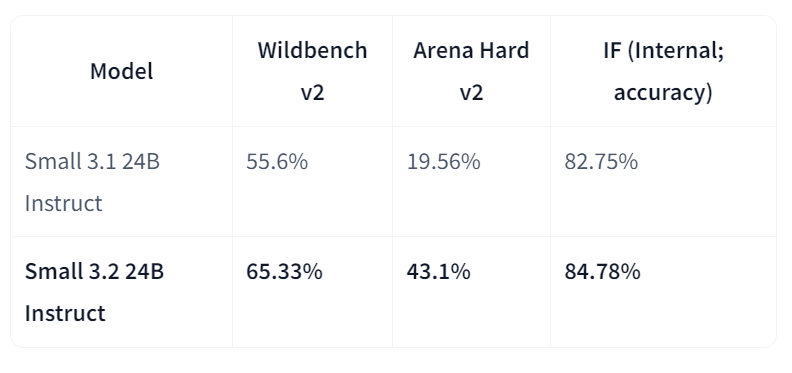
Fonte: mistralai/Mistral-Small-3.2-24B-Instruct-2506
Comparando diretamente com a versão 3.1, a Small-3.2 mostra avanços claros na qualidade e confiabilidade do assistente. Ele melhora o desempenho de seguimento de instruções no Wildbench v2 (de 55,6% para 65,33%) e no Arena Hard v2 (de 19,56% para 43,1%), enquanto a precisão interna de seguimento de instruções sobe de 82,75% para 84,78%. As falhas de repetição em comandos difíceis caíram pela metade (de 2,11% para 1,29%). Enquanto isso, o desempenho em STEM continua parecido, com MATH em 69,42% e HumanEval+ Pass@5 em 92,90%.
Na tabela abaixo, você pode ver uma comparação dos principais modelos:
| Modelo | Principais pontos fortes | Atualizações/recursos importantes |
|---|---|---|
| GLM 4.6 | Raciocínio forte, fluxos de trabalho agenticos e recursos de codificação | Janela de contexto expandida de 128K → 200K; desempenho de benchmark melhorado em relação a GLM-4.5 e DeepSeek-V3.1 |
| gpt-oss-120B | Modelo GPT de peso aberto para raciocínio avançado e tarefas de agência | Profundidade de raciocínio configurável, acesso à cadeia de pensamentos, chamada de funções e formato de resposta harmoniosa |
| Qwen3-235B-Instruct-2507 | Raciocínio multilíngue de alta precisão e seguimento de instruções | Contexto de mais de 1 milhão de tokens, escrita alinhada com as preferências, superando o GPT-4o e o Claude Opus 4 (sem pensamento) |
| DeepSeek-V3.2-Exp | Processamento eficiente de contexto longo por meio de atenção esparsa | Equivalente ao desempenho da versão V3.1 com computação reduzida; eficiência do transformador otimizada |
| DeepSeek-R1-0528 | Raciocínio avançado, matemática e habilidade em programação | Melhoria de 17,5% no AIME 2025; maior profundidade analítica e confiabilidade de codificação |
| Apriel-1.5-15B-Pensador | Raciocínio multimodal (texto + imagem) em uma única GPU | Pré-treinamento contínuo em texto e imagem; raciocínio de ponta para modelos compactos |
| Kimi-K2-Instruct-0905 | Raciocínio sofisticado e fluxos de trabalho de codificação baseados em agentes | Contexto de token de 256K, ergonomia aprimorada para desenvolvedores e suporte a tarefas com ferramentas |
| Llama-3.3-Nemotron-Super-49B-v1.5 | Modelo equilibrado de raciocínio e uso de ferramentas | Otimizado pela NVIDIA para RAG e aplicativos de agência; suporte a contexto longo de até 128 mil tokens |
| Mistral-Small-3.2-24B-Instruct-2506 | Compacto e confiável no seguimento de instruções | Redução dos erros de repetição (−50%) e grandes ganhos no WildBench v2 e no Arena Hard v2 |
O espaço LLM de código aberto está crescendo rapidão. Hoje em dia, tem muito mais LLMs de código aberto do que os proprietários, e a diferença de desempenho pode ser superada em breve, já que desenvolvedores do mundo todo estão colaborando para melhorar os LLMs atuais e criar outros mais otimizados.
Nesse contexto vibrante e empolgante, pode ser difícil escolher o LLM de código aberto certo para seus objetivos. Aqui está uma lista de alguns dos fatores que você deve considerar antes de escolher um LLM de código aberto específico:
Os LLMs de código aberto não são só para projetos ou interesses individuais. À medida que a revolução da IA generativa continua a acelerar, as empresas estão percebendo como é importante entender e implementar essas ferramentas. Os LLMs já são essenciais para alimentar aplicativos avançados de IA, desde chatbots até tarefas complexas de processamento de dados. Garantir que sua equipe seja boa em tecnologias de IA e LLM não é mais só uma vantagem competitiva — é uma necessidade para preparar sua empresa para o futuro.
Se você é um líder de equipe ou empresário que quer capacitar sua equipe com conhecimentos em IA e LLM, o DataCamp for Business oferece programas de treinamento completos que podem ajudar seus funcionários a adquirir as habilidades necessárias para aproveitar essas ferramentas poderosas. Nós oferecemos:
Investir em IA e aprimoramento de habilidades em LLM não só melhora as capacidades da sua equipe, mas também coloca sua empresa na vanguarda da inovação, permitindo que você aproveite todo o potencial dessas tecnologias transformadoras. Fala com a nossa equipe para pedir uma demonstração e começar a montar sua equipe pronta para a IA hoje mesmo.
Os LLMs de código aberto estão em um movimento empolgante. Com a evolução rápida, parece que o espaço da IA generativa não vai ser necessariamente dominado pelas grandes empresas que têm grana pra construir e usar essas ferramentas poderosas.
Só vimos oito LLMs de código aberto, mas o número é bem maior e tá crescendo rápido. A gente da DataCamp vai continuar trazendo as últimas novidades sobre o mundo dos LLMs, com cursos, artigos e tutoriais sobre o assunto. Por enquanto, dá uma olhada na nossa lista de materiais selecionados:
Comece hoje mesmo sua jornada na IA!
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
8 min
blog
Nisha Arya Ahmed
12 min
blog
DataCamp Team
4 min
Tutorial
Josep Ferrer

