
Program
AI İşletme Temelleri
12 sa
Küçük dil modelleri (SLM’ler) kompakt, verimli ve büyük dil modellerinin (LLM’ler) aksine devasa sunuculara ihtiyaç duymaz. Hız ve gerçek zamanlı performans için geliştirilmişlerdir ve akıllı telefonlarımızda, tabletlerimizde veya akıllı saatlerimizde çalışabilirler.
Bu yazıda 2026’nın en iyi 15 SLM’ini inceleyip güçlü ve zayıf yönlerini, ayrıca her modeli benzersiz kılan noktaları ele alacağız.
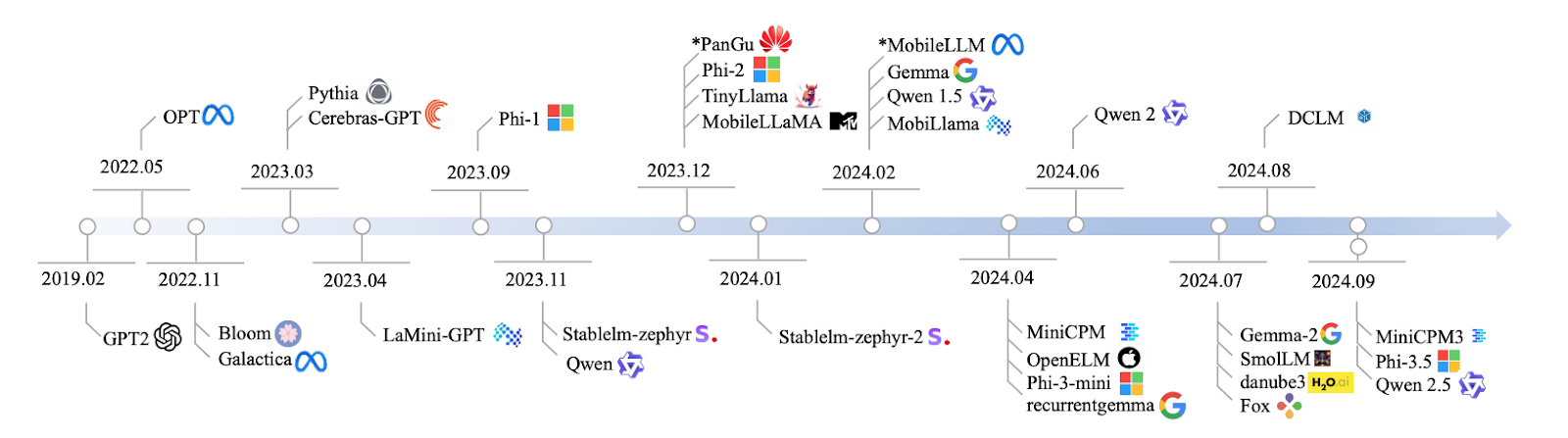
Kaynak: Lu ve diğ., 2024
Doğrudan modellere geçeceğim, ancak küçük dil modellerine dair bir özet ihtiyacınız varsa, burada ayrı bir yazı yazdım: Küçük Dil Modelleri: Örneklerle Rehber.
Qwen2, 0,5 milyardan 7 milyar parametreye kadar uzanan bir model ailesidir. Çok hafif bir modele ihtiyaç duyan uygulamalar için 0.5B sürümü idealdir.
Ancak özetleme veya metin üretimi gibi görevler için daha sağlam bir şeye ihtiyacınız varsa, en yüksek performansı 7B modelinde elde edersiniz. Ölçeklenebilirdir ve özel ihtiyaçlarınıza göre uyarlanabilir.
Qwen2 modelleri karmaşık akıl yürütmede devasa yapay zekâ modellerinin geniş yetenekleriyle eşleşmeyebilir, ancak hız ve verimliliğin en kritik olduğu pek çok pratik kullanımda mükemmeldir. Özellikle hızlı yanıtlar veya sınırlı kaynaklar gerektiren uygulamalar için kullanışlıdır.
12 milyar parametreli Mistral Nemo 12B modeli, dil çevirisi ve gerçek zamanlı diyalog sistemleri gibi karmaşık NLP görevleri için harikadır. Falcon 40B ve Chinchilla 70B gibi modellerle rekabet eder, ancak yine de devasa bir altyapı kurulumuna ihtiyaç duymadan yerelde çalışabilir. Karmaşıklıkla pratikliği dengeleyen modellerden biridir.
Bu kurslarla yapay zekâyı öğrenin!
Program
Program
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
