
Track
AI Business Fundamentals
12 hr
Small language models (SLMs) are compact, efficient, and don’t need massive servers—unlike their large language models (LLMs) counterparts. They’re built for speed and real-time performance and can run on our smartphones, tablets, or smartwatches.
In this article, we’ll examine the top 15 SLMs of 2026 and explore their strengths, weaknesses, and what makes each model unique.
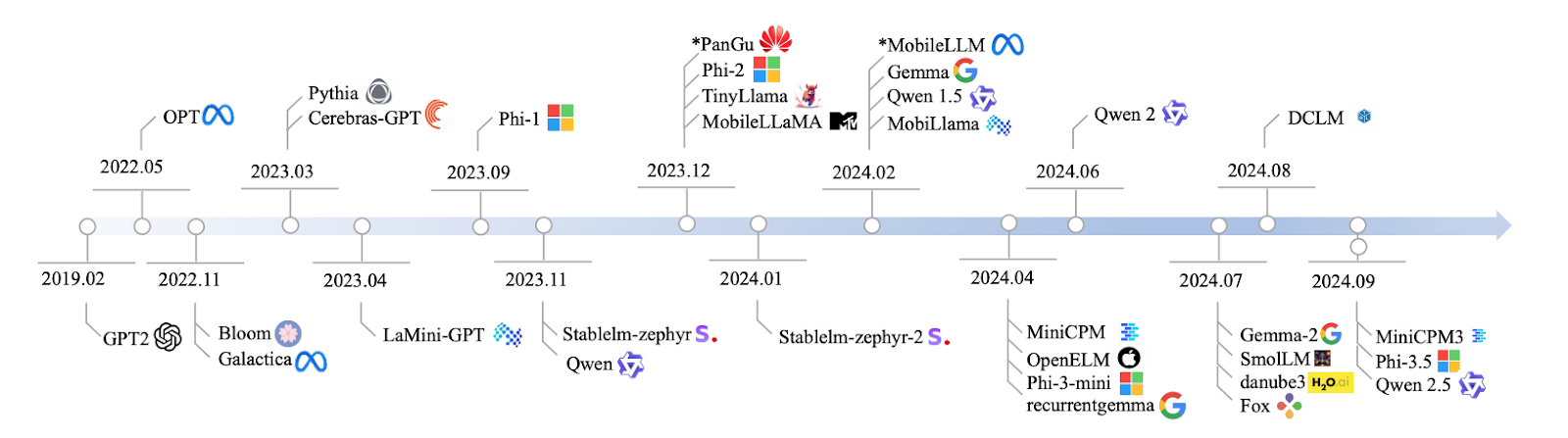
Source: Lu et al., 2024
I’ll jump straight to discussing the models, but if you need a primer on small language models, I wrote a separate article here: Small Language Models: A Guide With Examples.
Qwen2 it’s a family of models, with sizes that go from 0.5 billion to 7 billion parameters. If you’re working on an app that needs a super lightweight model, the 0.5B version is perfect.
However, if you need something more robust for tasks like summarization or text generation, the 7B model is where you’ll get the most performance. It’s scalable and can be tailored to your specific needs.
Qwen2 models may not match the broad abilities of huge AI models in complex thinking, but they're great for many practical uses where speed and efficiency matter most. They're particularly useful for apps requiring quick responses or limited resources.
With 12 billion parameters, Mistral Nemo 12B model is great for complex NLP tasks like language translation and real-time dialogue systems. It competes with models like Falcon 40B and Chinchilla 70B, but it can still run locally without a massive infrastructure setup. It’s one of those models that balances complexity with practicality.
Learn AI with these courses!
Track
Track
Course
blog
Abid Ali Awan
7 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Alex Olteanu
8 min
blog
Tim Lu
15 min
blog
Richie Cotton
8 min
blog
Richie Cotton
5 min


