
Tracks
Cơ bản về Kinh doanh Trí tuệ Nhân tạo
12 giờ
Small language models (SLMs) là các mô hình gọn nhẹ, hiệu quả và không cần máy chủ khổng lồ—khác với các mô hình ngôn ngữ lớn (LLMs). Chúng được xây dựng cho tốc độ và hiệu năng thời gian thực, có thể chạy trên điện thoại thông minh, máy tính bảng hoặc đồng hồ thông minh của chúng ta.
Trong bài viết này, chúng ta sẽ xem xét 15 SLM hàng đầu của năm 2026 và khám phá điểm mạnh, điểm yếu cũng như điều làm nên sự khác biệt của từng mô hình.
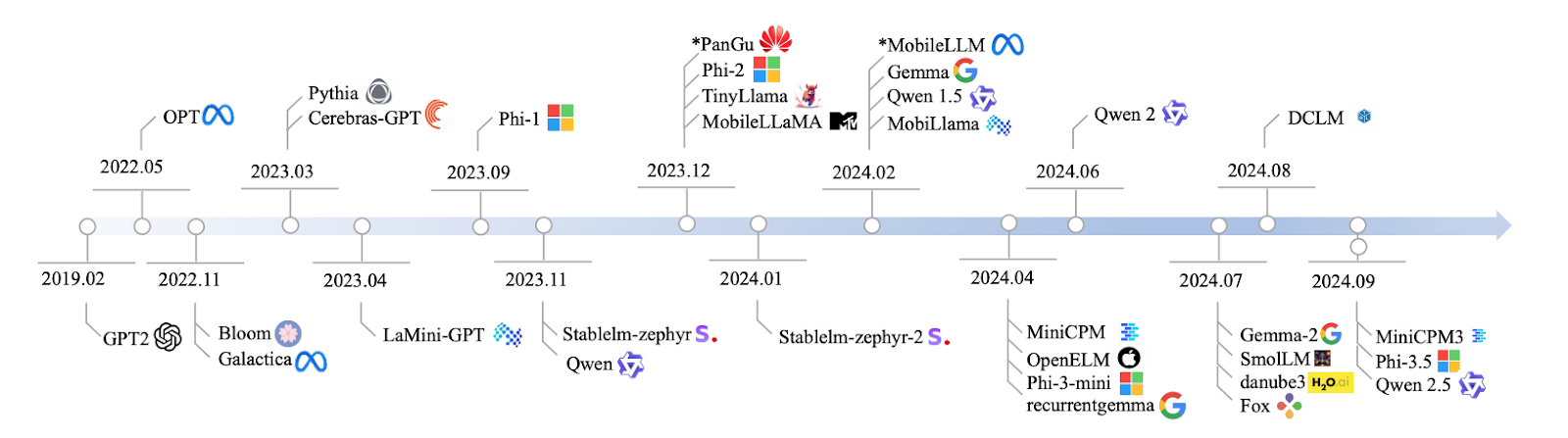
Nguồn: Lu et al., 2024
Tôi sẽ đi thẳng vào phần mô hình, nhưng nếu bạn cần phần nhập môn về các mô hình ngôn ngữ nhỏ, tôi đã viết một bài riêng tại đây: Small Language Models: A Guide With Examples.
Qwen2 là một họ mô hình, với kích thước từ 0,5 tỷ đến 7 tỷ tham số. Nếu bạn đang phát triển ứng dụng cần mô hình siêu gọn nhẹ, phiên bản 0.5B là hoàn hảo.
Tuy nhiên, nếu bạn cần thứ gì đó mạnh mẽ hơn cho các tác vụ như tóm tắt hoặc tạo văn bản, mô hình 7B sẽ cho hiệu năng tốt nhất. Nó có khả năng mở rộng và có thể điều chỉnh theo nhu cầu cụ thể của bạn.
Các mô hình Qwen2 có thể không sánh bằng các mô hình AI khổng lồ về tư duy phức tạp, nhưng chúng rất phù hợp cho nhiều tình huống thực tế nơi tốc độ và hiệu quả là ưu tiên hàng đầu. Chúng đặc biệt hữu ích cho các ứng dụng cần phản hồi nhanh hoặc tài nguyên hạn chế.
Với 12 tỷ tham số, Mistral Nemo 12B rất phù hợp cho các tác vụ NLP phức tạp như dịch ngôn ngữ và hệ thống hội thoại thời gian thực. Nó cạnh tranh với các mô hình như Falcon 40B và Chinchilla 70B, nhưng vẫn có thể chạy cục bộ mà không cần hạ tầng đồ sộ. Đây là một trong những mô hình cân bằng giữa độ phức tạp và tính thực tiễn.
Học AI với những khóa học này!
Tracks
Tracks
Courses
blogs
Matt Crabtree
10 phút