
Leerpad
Basisprincipes van AI-business
12 Hr
Small language models (SLM’s) zijn compact, efficiënt en hebben geen enorme servers nodig—anders dan hun tegenhangers, de large language models (LLM’s). Ze zijn gebouwd voor snelheid en real-time prestaties en kunnen draaien op smartphones, tablets of smartwatches.
In dit artikel bekijken we de top 15 SLM’s van 2026 en onderzoeken we hun sterke en zwakke punten en wat elk model uniek maakt.
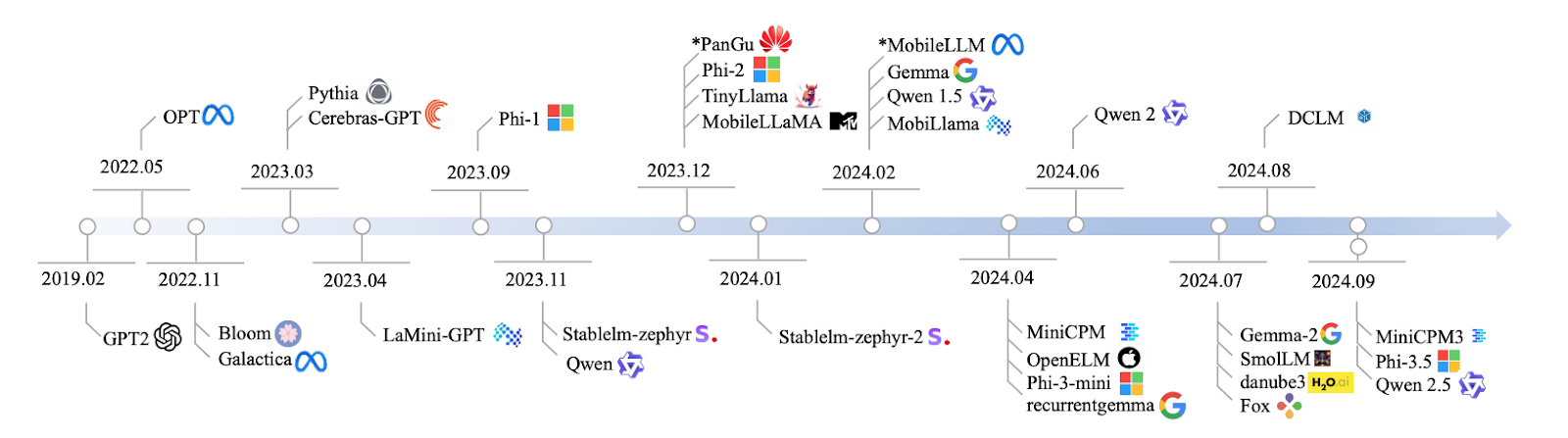
Bron: Lu et al., 2024
Ik ga meteen in op de modellen, maar als je een introductie in small language models nodig hebt, lees dan dit aparte artikel: Small Language Models: A Guide With Examples.
Qwen2 is een modellenfamilie met groottes van 0,5 miljard tot 7 miljard parameters. Werk je aan een app die een superlicht model nodig heeft, dan is de 0,5B-versie perfect.
Heb je echter iets robuusters nodig voor taken als samenvatten of tekstgeneratie, dan biedt het 7B-model de meeste performance. Het is schaalbaar en af te stemmen op jouw specifieke behoeften.
Qwen2-modellen halen misschien niet de brede capaciteiten van enorme AI-modellen bij complexe redenering, maar ze zijn uitstekend voor veel praktische toepassingen waar snelheid en efficiëntie het belangrijkst zijn. Ze zijn vooral handig voor apps die snelle reacties of beperkte resources vereisen.
Met 12 miljard parameters is Mistral Nemo 12B uitstekend voor complexe NLP-taken zoals vertalen en real-time dialoogsysteemen. Het concurreert met modellen als Falcon 40B en Chinchilla 70B, maar kan lokaal draaien zonder enorme infrastructuur. Het is een model dat complexiteit en praktische inzet mooi in balans houdt.
Leer AI met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
