
Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
Les modèles linguistiques de petite taille (SLM) sont compacts, efficaces et ne nécessitent pas de serveurs massifs, contrairement à leurs homologues, les grands modèles linguistiques (LLM). Ils sont conçus pour offrir vitesse et performances en temps réel et peuvent fonctionner sur nos smartphones, tablettes ou montres connectées.
Dans cet article, nous examinerons les 15 meilleurs SLM de 2026 et explorerons leurs forces, leurs faiblesses et ce qui rend chaque modèle unique.
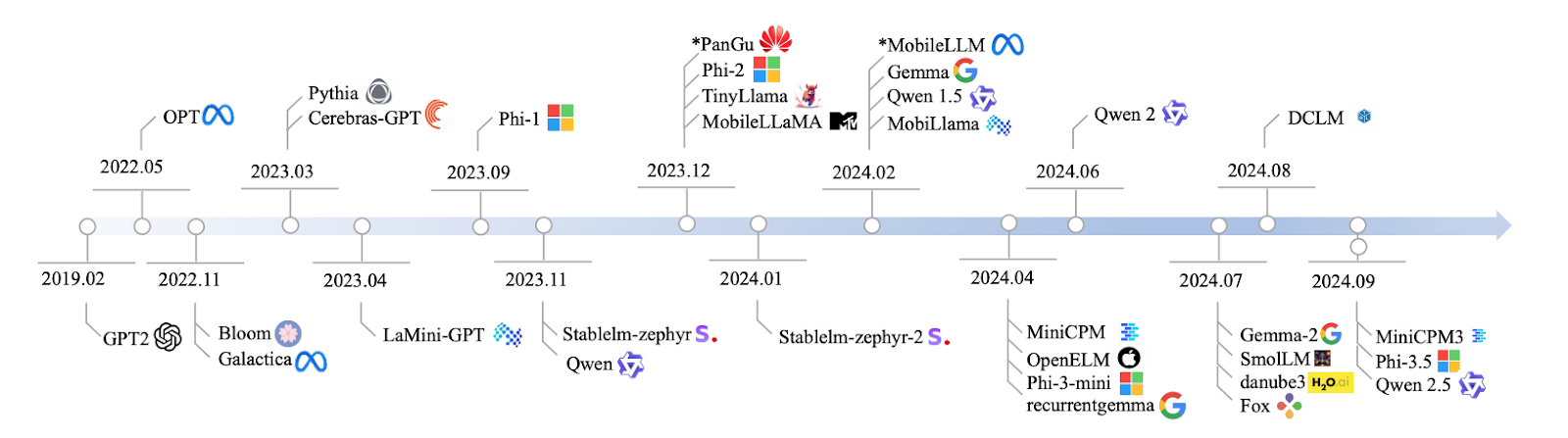
Source : Lu et al., 2024
Je vais passer directement à la discussion des modèles, mais si vous avez besoin d'une introduction aux petits modèles linguistiques, j'ai rédigé un article séparé à ce sujet ici : Modèles linguistiques de petite taille : Un guide illustré d'exemples.
Qwen2 est une famille de modèles dont la taille varie de 0,5 milliard à 7 milliards de paramètres. Si vous travaillez sur une application qui nécessite un modèle extrêmement léger, la version 0.5B est idéale.
Toutefois, si vous avez besoin d'un modèle plus robuste pour des tâches telles que la synthèse ou la génération de texte, le modèle 7B est celui qui vous offrira les meilleures performances. Il est évolutif et peut être adapté à vos besoins spécifiques.
Les modèles Qwen2 ne peuvent pas rivaliser avec les capacités étendues des modèles d'IA de grande envergure en matière de réflexion complexe, mais ils sont excellents pour de nombreuses utilisations pratiques où la rapidité et l'efficacité sont primordiales. Ils sont particulièrement utiles pour les applications nécessitant des réponses rapides ou des ressources limitées.
Avec 12 milliards de paramètres, le modèle Mistral Nemo 12B est idéal pour les tâches complexes de traitement du langage naturel, telles que la traduction linguistique et les systèmes de dialogue en temps réel. Il est en concurrence avec des modèles tels que Falcon 40B et Chinchilla 70B, mais il peut néanmoins fonctionner localement sans nécessiter une infrastructure importante. C'est l'un de ces modèles qui allient complexité et fonctionnalité.
Apprenez l'IA grâce à ces cours.
Cursus
Cursus
Cours
blog
blog
Kurtis Pykes
9 min
blog
Nisha Arya Ahmed
15 min
blog
Lynn Heidmann
Tutoriel

