
Programa
Fundamentos do Negócio de IA
12 h
Os modelos de linguagem pequenos (SLMs) são compactos, eficientes e não precisam de servidores enormes — ao contrário dos seus equivalentes, os grandes modelos de linguagem (LLMs). Elas são feitas pra serem rápidas e funcionarem em tempo real, e podem rodar nos nossos smartphones, tablets ou smartwatches.
Neste artigo, vamos dar uma olhada os 15 principais SLMs de 2026 e vamos ver seus pontos fortes, pontos fracos e o que torna cada modelo único.
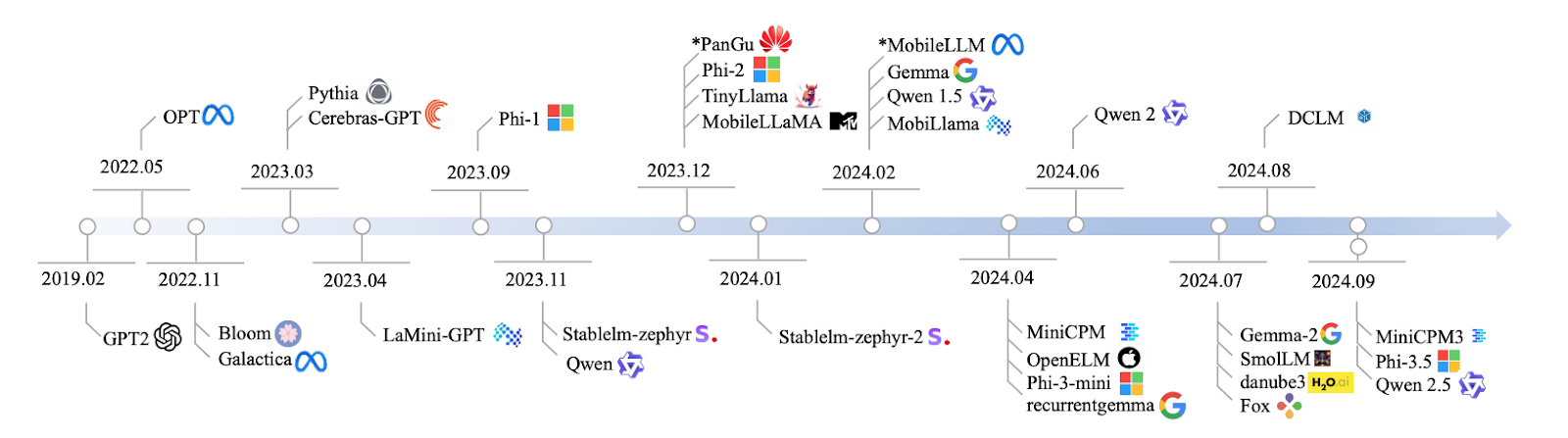
Fonte: Lu et al., 2024
Vou direto ao ponto e falar sobre os modelos, mas se você precisar de uma introdução sobre modelos de linguagem pequenos, escrevi um artigo separado aqui: Modelos de linguagem pequenos: Um guia com exemplos.
Qwen2 é uma família de modelos, com tamanhos que vão de 0,5 bilhão a 7 bilhões de parâmetros. Se você está trabalhando em um aplicativo que precisa de um modelo super leve, a versão 0.5B é perfeita.
Mas, se você precisar de algo mais robusto para tarefas como resumo ou geração de texto, o modelo 7B é onde você vai conseguir o melhor desempenho. É escalável e pode ser adaptado às suas necessidades específicas.
Os modelos Qwen2 podem não ter as mesmas capacidades gerais dos grandes modelos de IA em termos de raciocínio complexo, mas são ótimos para muitas aplicações práticas em que a velocidade e a eficiência são mais importantes. São especialmente úteis para aplicativos que precisam de respostas rápidas ou têm recursos limitados.
Com 12 bilhões de parâmetros, o modelo Mistral Nemo 12B é ótimo para tarefas complexas de PLN, como tradução de idiomas e sistemas de diálogo em tempo real. Ele compete com modelos como Falcon 40B e Chinchilla 70B, mas ainda pode funcionar localmente sem precisar de uma infraestrutura enorme. É um daqueles modelos que equilibra complexidade com praticidade.
Aprenda IA com esses cursos!
Programa
Programa
Curso
blog
Ryan Ong
8 min
blog
Abid Ali Awan
13 min
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
9 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer


