
Programma
Nozioni di base sull'intelligenza artificiale nel mondo degli affari
12 h
I small language models (SLM) sono compatti, efficienti e non richiedono server mastodontici, a differenza dei loro omologhi LLM. Sono pensati per la velocità e le prestazioni in tempo reale e possono girare su smartphone, tablet o smartwatch.
In questo articolo esamineremo i 15 migliori SLM del 2026 e ne esploreremo punti di forza, limiti e ciò che rende unico ciascun modello.
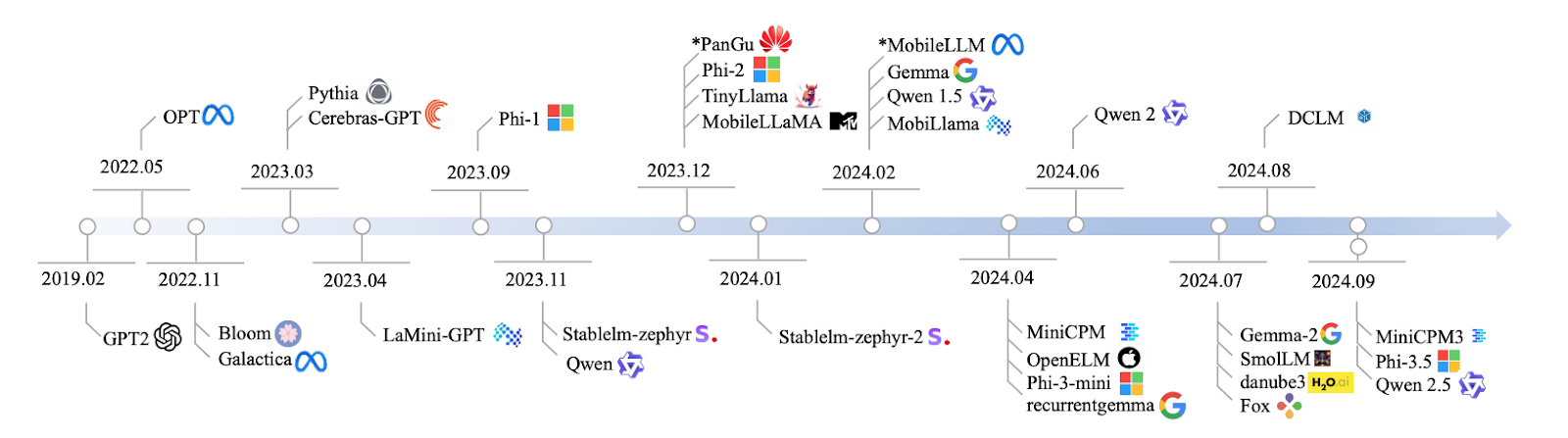
Fonte: Lu et al., 2024
Passo subito ai modelli; se però ti serve un’introduzione agli small language models, ho scritto un articolo a parte qui: Small Language Models: guida con esempi.
Qwen2 è una famiglia di modelli, con dimensioni che vanno da 0,5 a 7 miliardi di parametri. Se stai lavorando a un’app che richiede un modello super leggero, la versione 0.5B è perfetta.
Se invece ti serve qualcosa di più robusto per attività come riassunti o generazione di testo, il 7B è quello da cui otterrai il meglio. È scalabile e si può adattare alle tue esigenze specifiche.
I modelli Qwen2 forse non eguagliano le capacità generali dei grandi modelli nell’elaborazione complessa, ma sono ottimi per molti casi d’uso pratici in cui contano soprattutto velocità ed efficienza. Sono particolarmente utili per app che richiedono risposte rapide o hanno risorse limitate.
Con 12 miliardi di parametri, Mistral Nemo 12B è ottimo per attività NLP complesse come la traduzione e i sistemi di dialogo in tempo reale. Compete con modelli come Falcon 40B e Chinchilla 70B, ma può comunque girare in locale senza un’infrastruttura mastodontica. È uno di quei modelli che bilanciano complessità e praticità.
Impara l'AI con questi corsi!
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

