
programa
Fundamentos del negocio de la IA
12 h
Los modelos de lenguaje pequeños (SLM) son compactos, eficientes y no necesitan servidores masivos, a diferencia de sus homólogos, los modelos de lenguaje grandes (LLM). Están diseñadas para ofrecer velocidad y rendimiento en tiempo real, y pueden ejecutarse en nuestros teléfonos inteligentes, tabletas o relojes inteligentes.
En este artículo, examinaremos los 15 mejores SLM de 2026 y exploraremos sus puntos fuertes, sus puntos débiles y lo que hace que cada modelo sea único.
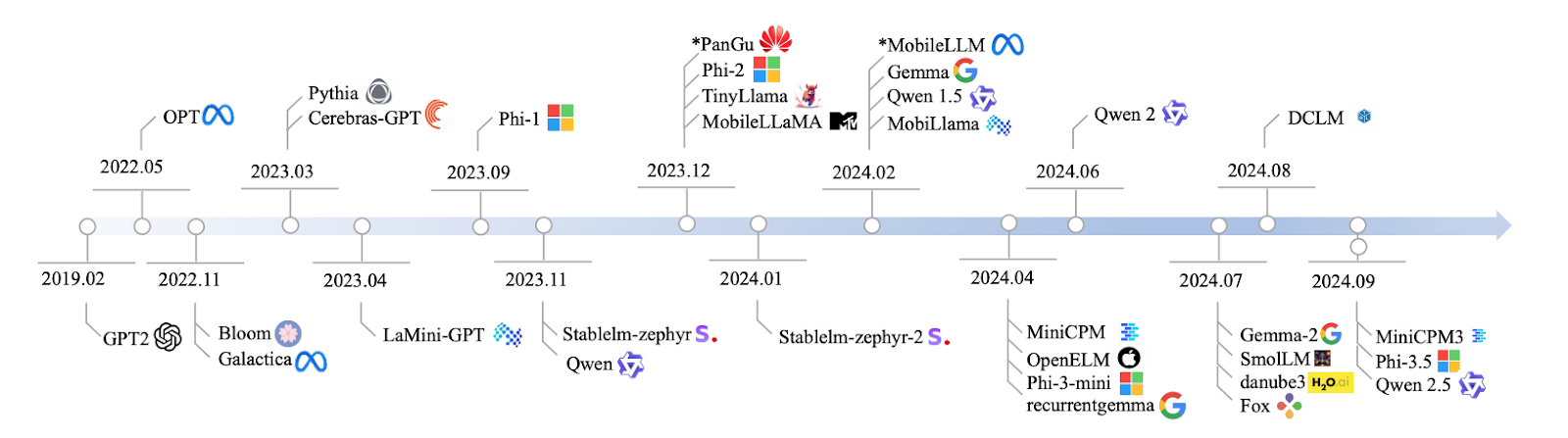
Fuente: Lu et al., 2024
Pasaré directamente a hablar de los modelos, pero si necesitas una introducción a los modelos de lenguaje pequeños, he escrito un artículo aparte aquí: Modelos lingüísticos pequeños: Guía con ejemplos.
Qwen2 es una familia de modelos, con tamaños que van desde los 500 millones hasta los 7000 millones de parámetros. Si estás trabajando en una aplicación que necesita un modelo superligero, la versión 0.5B es perfecta.
Sin embargo, si necesitas algo más robusto para tareas como la síntesis o la generación de texto, el modelo 7B es el que te ofrecerá un mayor rendimiento. Es escalable y se puede adaptar a tus necesidades específicas.
Es posible que los modelos Qwen2 no igualen las amplias capacidades de los enormes modelos de IA en cuanto a pensamiento complejo, pero son excelentes para muchos usos prácticos en los que la velocidad y la eficiencia son lo más importante. Son especialmente útiles para aplicaciones que requieren respuestas rápidas o recursos limitados.
Con 12 000 millones de parámetros, el modelo Mistral Nemo 12B es ideal para tareas complejas de PLN, como la traducción de idiomas y los sistemas de diálogo en tiempo real. Compite con modelos como Falcon 40B y Chinchilla 70B, pero puede funcionar a nivel local sin necesidad de una gran infraestructura. Es uno de esos modelos que equilibra la complejidad con la practicidad.
¡Aprende IA con estos cursos!
programa
programa
Curso
blog
Ryan Ong
8 min
blog
Abid Ali Awan
10 min
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Dimitri Didmanidze

