
Program
Dasar-Dasar Bisnis Kecerdasan Buatan
12 Hr
Small language models (SLMs) bersifat ringkas, efisien, dan tidak memerlukan server besar—berbeda dengan rekan besarnya, large language models (LLMs). Model ini dibuat untuk kecepatan dan kinerja real-time serta dapat dijalankan di ponsel pintar, tablet, atau jam tangan pintar Anda.
Dalam artikel ini, kita akan membahas 15 SLM teratas tahun 2026 dan menelusuri kelebihan, kekurangan, serta apa yang membuat tiap model unik.
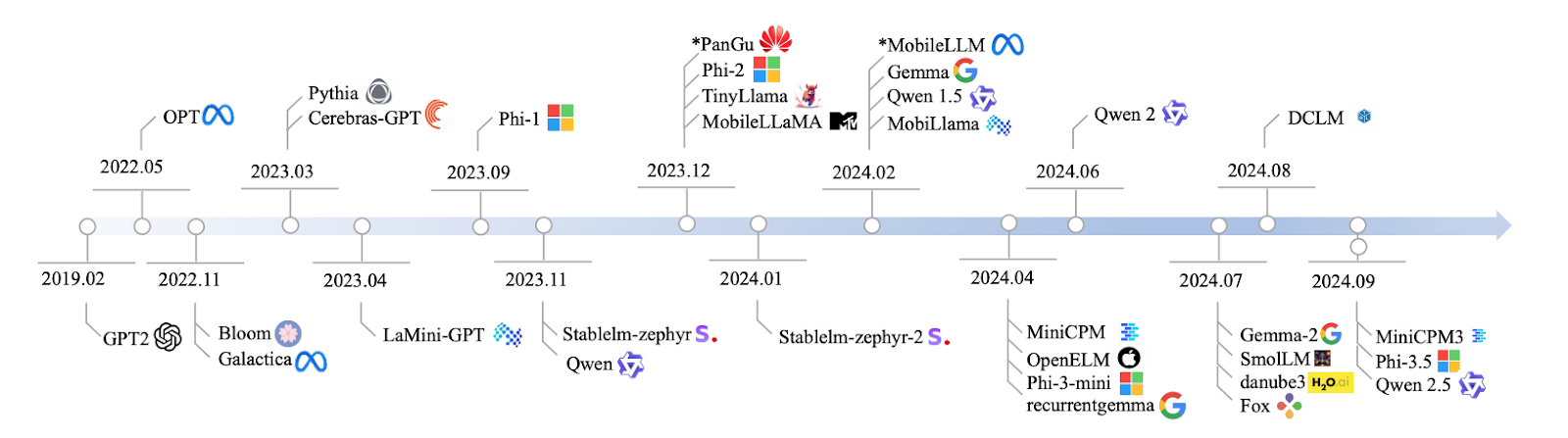
Sumber: Lu et al., 2024
Saya akan langsung membahas modelnya, namun jika Anda memerlukan pengantar tentang small language models, saya menulis artikel terpisah di sini: Small Language Models: A Guide With Examples.
Qwen2 adalah keluarga model, dengan ukuran dari 0,5 miliar hingga 7 miliar parameter. Jika Anda mengerjakan aplikasi yang membutuhkan model sangat ringan, versi 0.5B sangat tepat.
Namun, jika Anda memerlukan sesuatu yang lebih tangguh untuk tugas seperti peringkasan atau pembuatan teks, model 7B akan memberi performa terbaik. Model ini dapat diskalakan dan disesuaikan dengan kebutuhan spesifik Anda.
Model Qwen2 mungkin tidak menyamai kemampuan luas model AI raksasa dalam penalaran kompleks, tetapi sangat andal untuk banyak kegunaan praktis ketika kecepatan dan efisiensi paling utama. Model ini sangat berguna untuk aplikasi yang membutuhkan respons cepat atau sumber daya terbatas.
Dengan 12 miliar parameter, Mistral Nemo 12B sangat cocok untuk tugas NLP kompleks seperti penerjemahan bahasa dan sistem dialog real-time. Model ini bersaing dengan model seperti Falcon 40B dan Chinchilla 70B, namun tetap dapat dijalankan secara lokal tanpa infrastruktur besar. Ini salah satu model yang menyeimbangkan kompleksitas dan kepraktisan.
Pelajari AI dengan kursus-kursus ini!
Program
Program
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
