
Kurs
Large Language Models (LLMs) Kavramları
2 sa
104K
RAG’in ne olduğunu ve nasıl çalıştığını daha iyi göstermek için, günümüzde birçok işletmenin karşılaştığı bir senaryoyu ele alalım.
Akıllı telefon ve dizüstü bilgisayar gibi cihazlar satan bir elektronik şirketinde yönetici olduğunuzu düşünün. Ürün özellikleri, sorun giderme, garanti bilgileri ve daha fazlasıyla ilgili kullanıcı sorularını yanıtlayacak bir müşteri destek sohbet botu oluşturmak istiyorsunuz.
Sohbet botunuzu çalıştırmak için GPT-3 veya GPT-4 gibi LLM’lerin yeteneklerinden yararlanmak istiyorsunuz.
Ancak büyük dil modellerinin aşağıdaki sınırlamaları vardır ve bu da verimsiz bir müşteri deneyimine yol açar:
Dil modelleri, eğitim verilerine dayalı olarak genel yanıtlar vermekle sınırlıdır. Kullanıcılar sattığınız yazılıma özgü sorular sorarsa veya derinlemesine sorun giderme hakkında bilgi isterse, geleneksel bir LLM doğru yanıtlar veremeyebilir.
Bunun nedeni, bu modellerin sizin kurumunuza özgü verilerle eğitilmemiş olmasıdır. Ayrıca bu modellerin eğitim verilerinin bir kesme tarihi vardır; bu da güncel yanıt verme yeteneklerini sınırlar.
LLM’ler “halüsinasyon” görebilir; yani uydurma olgulara dayanarak kendinden emin bir şekilde yanlış yanıtlar üretme eğilimindedir. Doğru cevabı olmadığında konuyla alakasız yanıtlar da verebilirler; bu da kötü bir müşteri deneyimine neden olur.
Dil modelleri sıklıkla belirli bağlamlara uyarlanmamış genel yanıtlar verir. Bu, müşteri desteği senaryosunda önemli bir dezavantaj olabilir; çünkü kişiselleştirilmiş bir deneyim için genellikle bireysel kullanıcı tercihlerini dikkate almak gerekir.
RAG, LLM’lerin genel bilgi tabanını, ürün veritabanınız ve kullanıcı kılavuzlarınızda yer alan veriler gibi spesifik bilgilere erişim ile entegre etmenin bir yolunu sunarak bu boşlukları etkili şekilde kapatır. Bu yöntem, kurumunuzun ihtiyaçlarına göre uyarlanmış, son derece doğru ve güvenilir yanıtlar sağlar.
Artık RAG’in ne olduğunu anladığınıza göre, bu yapının kurulmasında yer alan adımlara bakalım:
Öncelikle uygulamanız için gerekli tüm verileri toplamalısınız. Bir elektronik şirketi için müşteri destek sohbet botu özelinde, buna kullanıcı kılavuzları, bir ürün veritabanı ve SSS listesi dahil olabilir.
Veri parçalama, verilerinizi daha küçük ve yönetilebilir parçalara bölme işlemidir. Örneğin, uzun bir 100 sayfalık kullanıcı kılavuzunuz varsa, bunu farklı müşteri sorularını yanıtlayabilecek bölümlere ayırabilirsiniz.
Böylece her veri parçası belirli bir konuya odaklanır. Kaynak veri setinden bilgi getirildiğinde, tüm belgenin ilgisiz kısımlarını dahil etmekten kaçındığımız için elde edilen bilginin kullanıcının sorusuna doğrudan uygulanabilir olma olasılığı artar.
Bu aynı zamanda verimliliği artırır; sistem tüm belgeleri işlemek yerine en ilgili bilgi parçalarını hızla elde edebilir.
Kaynak veriler daha küçük parçalara ayrıldıktan sonra, bir vektör gösterimine dönüştürülmesi gerekir. Bu, metin verilerinin, metnin ardındaki anlamsal içeriği yakalayan sayısal temsiller olan gömlemelere dönüştürülmesini içerir.
Basitçe söylemek gerekirse, belge gömlemeleri sistemin kullanıcı sorularını anlamasını ve metnin anlamına dayalı olarak, basit kelime kelime karşılaştırma yerine, kaynak veri setindeki ilgili bilgilerle eşleştirmesini sağlar. Bu yöntem, yanıtların ilgili ve kullanıcının sorusuyla uyumlu olmasını güvence altına alır.
Metin verilerinin vektör temsillerine nasıl dönüştürüldüğü hakkında daha fazla bilgi edinmek isterseniz, OpenAI API ile metin gömlemeleri hakkındaki eğitimimize göz atmanızı öneririz.
Bir kullanıcı sorgusu sisteme girdiğinde, bunun da bir gömme ya da vektör temsiline dönüştürülmesi gerekir. Tutarlılık için hem belge hem de sorgu gömlemesi için aynı model kullanılmalıdır.
Sorgu bir gömmeye dönüştürüldükten sonra, sistem sorgu gömmesini belge gömlemeleriyle karşılaştırır. Kosinüs benzerliği ve Öklid uzaklığı gibi ölçümler kullanarak, gömmeleri sorgu gömmesine en çok benzeyen parçaları belirleyip getirir.
Bu parçalar, kullanıcının sorusuyla en ilgili içerik olarak kabul edilir.
Getirilen metin parçaları, ilk kullanıcı sorgusuyla birlikte bir dil modeline beslenir. Algoritma bu bilgiyi kullanarak sohbet arayüzü üzerinden kullanıcının sorularına tutarlı bir yanıt üretir.
İşte RAG’in nasıl çalıştığını özetleyen basitleştirilmiş bir akış şeması:
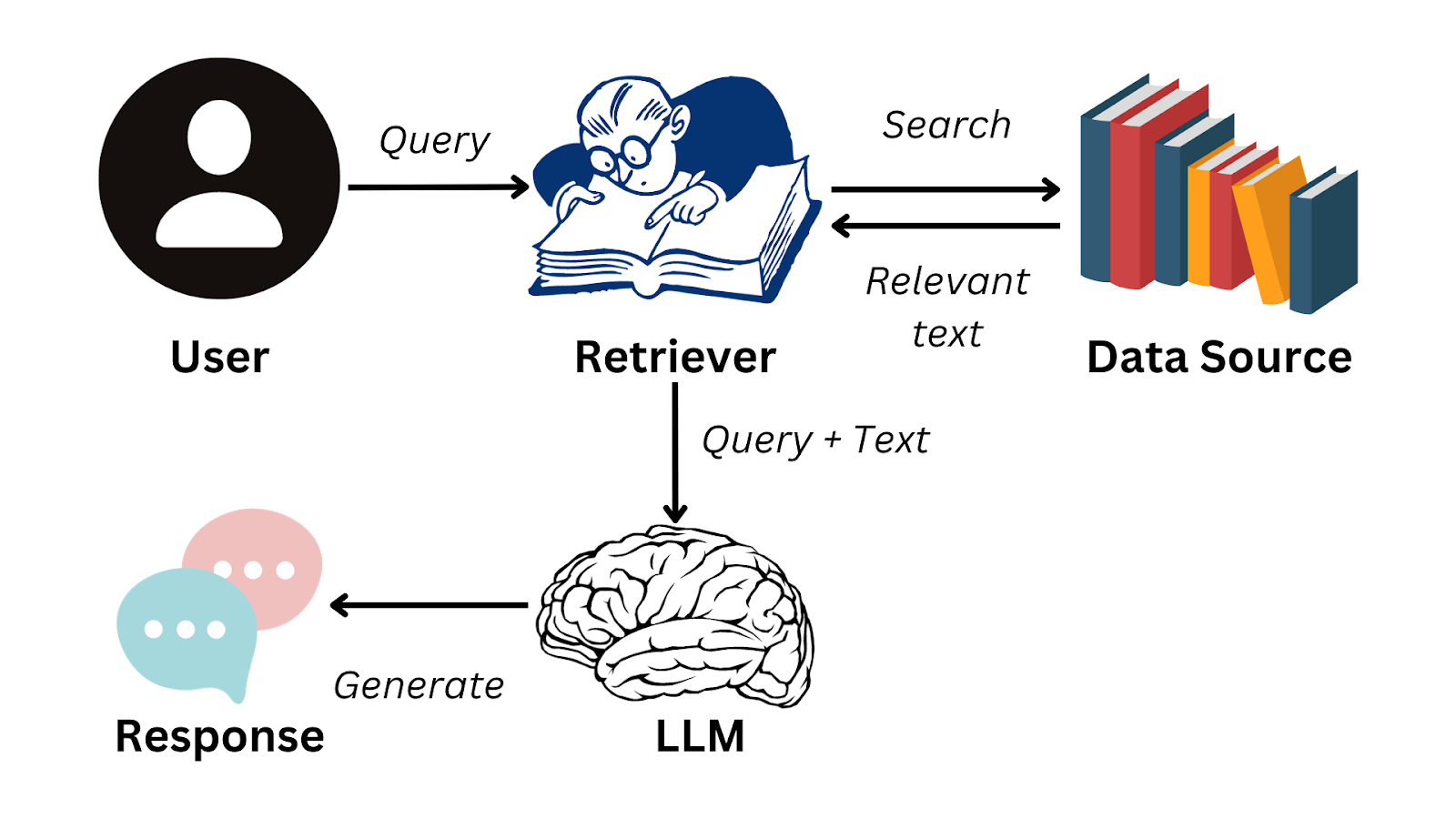
Yazarın görseli
LLM’lerle yanıt üretmek için gereken adımları sorunsuzca gerçekleştirmek üzere LlamaIndex gibi bir veri çerçevesi kullanabilirsiniz.
Bu çözüm, harici veri kaynaklarından GPT-3 gibi dil modellerine bilgi akışını verimli biçimde yöneterek kendi LLM uygulamalarınızı geliştirmenize olanak tanır. Bu çerçeve hakkında daha fazla bilgi edinmek ve LLM tabanlı uygulamalar oluşturmak için nasıl kullanabileceğinizi öğrenmek üzere LlamaIndex hakkındaki eğitimimizi okuyun.
Artık RAG’in LLM’lerin eğitim verileri dışındaki bilgilere dayanarak tutarlı yanıtlar vermesini sağladığını biliyoruz. Bu tür bir sistemin, kurumsal verimliliği ve kullanıcı deneyimini iyileştiren çeşitli iş kullanım alanları vardır. Yazının başlarında ele aldığımız müşteri sohbet botu örneğinin yanı sıra, RAG’in bazı pratik uygulamaları şunlardır:
RAG, harici kaynaklardaki içeriği kullanarak doğru özetler üretebilir ve ciddi zaman tasarrufu sağlar. Örneğin, yöneticiler ve üst düzey yöneticiler, kapsamlı raporları satır satır incelemeye vakit bulamayabilir.
RAG destekli bir uygulama ile metin verilerinden en kritik bulgulara hızla erişebilir, uzun belgeleri okumak yerine daha verimli şekilde karar alabilirler.
RAG sistemleri, geçmiş satın alımlar ve yorumlar gibi müşteri verilerini analiz ederek ürün önerileri üretebilir. Bu, kullanıcının genel deneyimini artırır ve nihayetinde kuruma daha fazla gelir sağlar.
Örneğin, RAG uygulamaları, kullanıcının izleme geçmişi ve puanlarına göre yayın platformlarında daha iyi film önerileri sunmak için kullanılabilir. E-ticaret platformlarındaki yazılı değerlendirmeleri analiz etmek için de kullanılabilirler.
LLM’ler metin verilerinin ardındaki anlamı kavrama konusunda başarılı olduğundan, RAG sistemleri, geleneksel bir öneri sistemine kıyasla daha incelikli kişiselleştirilmiş öneriler sunabilir.
Kurumlar genellikle rakip davranışlarını izleyip pazar eğilimlerini analiz ederek iş kararları alır. Bu, iş raporlarında, finansal tablolarda ve pazar araştırması belgelerinde yer alan verilerin titizlikle analiz edilmesiyle yapılır.
Bir RAG uygulamasıyla kurumlar bu belgelerdeki eğilimleri elle analiz edip belirlemek zorunda kalmaz. Bunun yerine, anlamlı içgörüleri verimli şekilde çıkarmak ve pazar araştırması sürecini iyileştirmek için bir LLM’den yararlanılabilir.
RAG uygulamaları bilgi getirme ile doğal dil işlemi arasındaki boşluğu kapatmamıza olanak tanırken, uygulamaları bazı özgün zorluklar barındırır. Bu bölümde, RAG uygulamaları geliştirirken karşılaşılan karmaşıklıkları inceleyecek ve bunların nasıl hafifletilebileceğini tartışacağız.
Bir getirme sistemini bir LLM ile entegre etmek zor olabilir. Farklı formatlarda birden fazla harici veri kaynağı olduğunda bu karmaşıklık artar. RAG sistemine beslenen verilerin tutarlı olması, üretilen gömlemelerin de tüm veri kaynakları arasında yeknesak olması gerekir.
Bu zorluğun üstesinden gelmek için, farklı veri kaynaklarını bağımsız olarak ele alan ayrı modüller tasarlanabilir. Her modüldeki veriler daha sonra tutarlılık için ön işleme tabi tutulabilir ve gömlemelerin tutarlı bir biçime sahip olmasını sağlamak üzere standartlaştırılmış bir model kullanılabilir.
Veri miktarı arttıkça, RAG sisteminin verimliliğini korumak daha zorlu hale gelir. Gömleme üretme, farklı metin parçaları arasındaki anlamı karşılaştırma ve veriyi gerçek zamanlı getirme gibi birçok karmaşık işlem gerçekleştirilmelidir.
Bu görevler hesaplama açısından yoğundur ve kaynak veri boyutu arttıkça sistemi yavaşlatabilir.
Bu sorunu ele almak için, hesaplama yükünü farklı sunucular arasında dağıtabilir ve sağlam bir donanım altyapısına yatırım yapabilirsiniz. Yanıt süresini iyileştirmek için, sıkça sorulan sorguları önbelleğe almak da faydalı olabilir.
Vektör veritabanlarının uygulanması, RAG sistemlerindeki ölçeklenebilirlik sorununu da hafifletebilir. Bu veritabanları, gömlemelerle kolayca çalışmanıza ve her sorguyla en yakından ilişkili vektörleri hızla getirmenize olanak tanır.
Bir RAG uygulamasında vektör veritabanlarının nasıl uygulandığı hakkında daha fazla bilgi edinmek isterseniz, GPT ve Milvus ile Retrieval Augmented Generation başlıklı canlı kodlama oturumumuzu izleyebilirsiniz. Bu eğitim, açık kaynaklı bir vektör veritabanı olan Milvus’u GPT modelleriyle birleştirmeye yönelik adım adım bir rehber sunar.
Bir RAG sisteminin etkinliği, büyük ölçüde sisteme beslenen verinin kalitesine bağlıdır. Uygulamanın eriştiği kaynak içerik zayıfsa, üretilen yanıtlar da hatalı olacaktır.
Kurumların titiz bir içerik kürasyonu ve ince ayar sürecine yatırım yapması gerekir. Veri kaynaklarının kalitesini artırmak için rafine edilmesi şarttır. Ticari uygulamalarda, veri setini bir RAG sisteminde kullanmadan önce, içerikteki boşlukları gözden geçirmek ve doldurmak üzere konu uzmanlarını sürece dahil etmek faydalı olabilir.
RAG, LLM’lerin dil yeteneklerinden, uzmanlaşmış bir veritabanıyla birlikte yararlanmak için bugün bilinen en iyi tekniktir. Bu sistemler, dil modelleriyle çalışırken karşılaşılan en kritik zorlukların bazılarını ele alır ve doğal dil işleme alanında yenilikçi bir çözüm sunar.
Ancak, diğer tüm teknolojiler gibi RAG uygulamalarının da sınırlamaları vardır—özellikle de girdi verisinin kalitesine bağımlılıkları. RAG sistemlerinden en iyi şekilde yararlanmak için sürece insan denetimini dahil etmek kritik önemdedir.
Veri kaynaklarının titizlikle küratörlüğü ve uzman bilgisi, bu çözümlerin güvenilirliğini sağlamak için zorunludur.
RAG dünyasını daha derinlemesine keşfetmek ve etkili yapay zeka uygulamaları geliştirmek için nasıl kullanılabileceğini anlamak isterseniz, LangChain ile yapay zeka uygulamaları geliştirme konulu canlı eğitimimizi izleyebilirsiniz. Bu eğitim, gerçek dünya senaryolarında RAG sistemlerinin uygulanmasını sağlayan bir kütüphane olan LangChain ile uygulamalı deneyim sunar.
LLM’lerle Bugün Başlayın!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
