
Corso
Concetti sui Large Language Models (LLM)
2 h
104.1K
Per capire meglio cos’è RAG e come funziona la tecnica, consideriamo uno scenario comune a molte aziende.
Immagina di essere un dirigente di un’azienda di elettronica che vende dispositivi come smartphone e laptop. Vuoi creare un chatbot di assistenza clienti per rispondere alle domande degli utenti su specifiche dei prodotti, risoluzione dei problemi, informazioni sulla garanzia e altro.
Vorresti usare le capacità degli LLM come GPT-3 o GPT-4 per alimentare il tuo chatbot.
Tuttavia, i large language model hanno i seguenti limiti, che portano a un'esperienza cliente inefficiente:
I modelli linguistici si limitano a fornire risposte generiche basate sui loro dati di addestramento. Se gli utenti pongono domande specifiche sul software che vendi o hanno richieste su come eseguire una diagnosi approfondita, un LLM tradizionale potrebbe non essere in grado di fornire risposte accurate.
Questo perché non sono stati addestrati su dati specifici della tua organizzazione. Inoltre, i dati di addestramento di questi modelli hanno una data di cutoff, il che limita la loro capacità di fornire risposte aggiornate.
Gli LLM possono “allucinare”, ovvero tendono a generare con sicurezza risposte false basate su fatti inventati. Questi algoritmi possono anche fornire risposte fuori tema se non hanno una risposta accurata alla domanda dell’utente, con conseguente cattiva esperienza cliente.
I modelli linguistici spesso forniscono risposte generiche non calibrate su contesti specifici. Questo può essere un grosso limite in un contesto di assistenza clienti, dove le preferenze individuali dell’utente sono di solito necessarie per offrire un'esperienza personalizzata.
RAG colma efficacemente queste lacune offrendo un modo per integrare la base di conoscenza generale degli LLM con l’accesso a informazioni specifiche, come i dati presenti nel tuo database prodotti e nei manuali utente. Questa metodologia consente risposte altamente accurate e affidabili, calibrate sulle esigenze della tua organizzazione.
Ora che hai capito cos’è RAG, vediamo i passaggi per configurare questo framework:
Per prima cosa devi raccogliere tutti i dati necessari alla tua applicazione. Nel caso di un chatbot di assistenza clienti per un’azienda di elettronica, questo può includere manuali utente, un database prodotti e un elenco di FAQ.
La suddivisione in chunk è il processo di frammentazione dei dati in parti più piccole e gestibili. Ad esempio, se hai un manuale utente lungo 100 pagine, potresti dividerlo in sezioni diverse, ciascuna potenzialmente in grado di rispondere a differenti domande dei clienti.
In questo modo, ogni chunk di dati è focalizzato su un argomento specifico. Quando si recupera un’informazione dal dataset di origine, è più probabile che sia direttamente applicabile alla domanda dell’utente, evitando di includere informazioni irrilevanti da interi documenti.
Questo migliora anche l’efficienza, perché il sistema può ottenere rapidamente i pezzi di informazione più rilevanti invece di elaborare documenti interi.
Ora che i dati di origine sono stati suddivisi in parti più piccole, vanno convertiti in una rappresentazione vettoriale. Ciò implica trasformare i testi in embedding, rappresentazioni numeriche che catturano il significato semantico del testo.
In parole semplici, gli embedding dei documenti consentono al sistema di comprendere le domande degli utenti e di associarle a informazioni pertinenti nel dataset di origine in base al significato del testo, invece che a un semplice confronto parola per parola. Questo metodo garantisce che le risposte siano pertinenti e allineate alla richiesta dell’utente.
Se vuoi saperne di più su come i testi vengono convertiti in rappresentazioni vettoriali, ti consigliamo di esplorare il nostro tutorial sugli embedding testuali con le API di OpenAI.
Quando una richiesta utente entra nel sistema, deve essere anch’essa convertita in un embedding o rappresentazione vettoriale. Bisogna usare lo stesso modello sia per l’embedding dei documenti sia per quello della query, per garantire uniformità tra i due.
Una volta convertita la query in embedding, il sistema la confronta con gli embedding dei documenti. Identifica e recupera i chunk i cui embedding sono più simili a quello della query, usando misure come similarità del coseno e distanza euclidea.
Questi chunk sono considerati i più rilevanti per la richiesta dell’utente.
I chunk di testo recuperati, insieme alla domanda iniziale dell’utente, vengono forniti a un modello linguistico. L’algoritmo utilizzerà queste informazioni per generare una risposta coerente alle domande dell’utente tramite un’interfaccia chat.
Ecco un diagramma di flusso semplificato che riassume come funziona RAG:
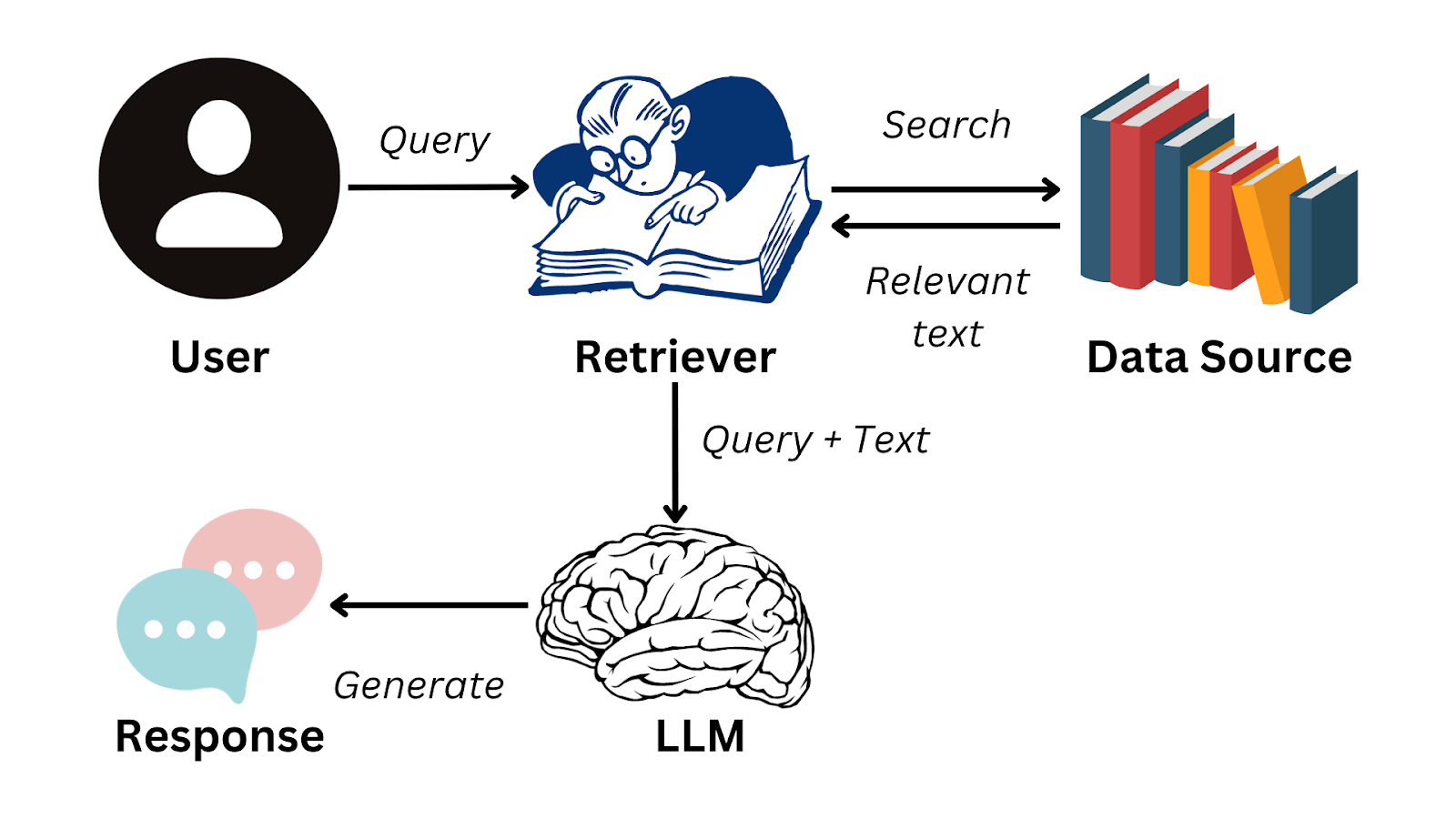
Immagine dell’autore
Per realizzare in modo fluido i passaggi necessari a generare risposte con gli LLM, puoi usare un framework dati come LlamaIndex.
Questa soluzione ti permette di sviluppare applicazioni LLM gestendo in modo efficiente il flusso di informazioni dalle fonti di dati esterne a modelli linguistici come GPT-3. Per saperne di più su questo framework e su come usarlo per costruire applicazioni basate su LLM, leggi il nostro tutorial su LlamaIndex.
Ora sappiamo che RAG consente agli LLM di formulare risposte coerenti basate su informazioni al di fuori dei loro dati di addestramento. Un sistema del genere ha varie applicazioni di business che migliorano l’efficienza organizzativa e l’esperienza utente. Oltre all’esempio del chatbot per i clienti visto in precedenza, ecco alcune applicazioni pratiche di RAG:
RAG può usare contenuti da fonti esterne per produrre riassunti accurati, con notevoli risparmi di tempo. Ad esempio, manager e dirigenti sono persone impegnate che non hanno tempo per spulciare report estesi.
Con un’applicazione basata su RAG, possono attingere rapidamente ai risultati più critici dai testi e prendere decisioni in modo più efficiente, invece di dover leggere documenti lunghi.
I sistemi RAG possono essere utilizzati per analizzare dati dei clienti, come acquisti passati e recensioni, per generare raccomandazioni di prodotto. Questo migliora l’esperienza complessiva dell’utente e, in ultima analisi, genera più ricavi per l’organizzazione.
Ad esempio, le applicazioni RAG possono essere utilizzate per consigliare film migliori sulle piattaforme di streaming in base alla cronologia di visione e alle valutazioni dell’utente. Possono anche analizzare recensioni scritte sulle piattaforme di e-commerce.
Poiché gli LLM eccellono nella comprensione della semantica dei testi, i sistemi RAG possono fornire suggerimenti personalizzati più sfumati rispetto a un sistema di raccomandazione tradizionale.
Le organizzazioni in genere prendono decisioni di business monitorando il comportamento dei competitor e analizzando le tendenze di mercato. Questo avviene analizzando meticolosamente i dati presenti in report aziendali, bilanci e documenti di ricerche di mercato.
Con un’applicazione RAG, le organizzazioni non devono più analizzare manualmente e identificare le tendenze in questi documenti. Invece, si può impiegare un LLM per ricavare in modo efficiente insight significativi e migliorare il processo di ricerca di mercato.
Sebbene le applicazioni RAG consentano di colmare il divario tra recupero delle informazioni ed elaborazione del linguaggio naturale, la loro implementazione presenta alcune sfide specifiche. In questa sezione esamineremo le complessità affrontate nella costruzione di applicazioni RAG e vedremo come mitigarle.
Integrare un sistema di retrieval con un LLM può essere difficile. Questa complessità aumenta quando ci sono più fonti di dati esterne in formati diversi. I dati immessi in un sistema RAG devono essere coerenti e gli embedding generati devono essere uniformi su tutte le fonti.
Per superare questa sfida, si possono progettare moduli separati per gestire indipendentemente le diverse fonti di dati. I dati all’interno di ciascun modulo possono poi essere pre-processati per garantire uniformità e si può usare un modello standardizzato per assicurare che gli embedding abbiano un formato coerente.
Con l’aumentare della quantità di dati, diventa più difficile mantenere l’efficienza del sistema RAG. Occorre svolgere molte operazioni complesse, come generare embedding, confrontare il significato tra diversi testi e recuperare dati in tempo reale.
Questi compiti sono intensivi dal punto di vista computazionale e possono rallentare il sistema man mano che cresce la dimensione dei dati di origine.
Per affrontare questa sfida, puoi distribuire il carico computazionale su diversi server e investire in un’infrastruttura hardware robusta. Per migliorare i tempi di risposta, può essere utile anche memorizzare in cache le query poste più frequentemente.
L’implementazione di database vettoriali può inoltre mitigare la sfida della scalabilità nei sistemi RAG. Questi database consentono di gestire facilmente gli embedding e di recuperare rapidamente i vettori più allineati a ciascuna query.
Se vuoi saperne di più sull’implementazione di database vettoriali in un’applicazione RAG, puoi guardare la nostra sessione di live code-along intitolata Retrieval Augmented Generation with GPT and Milvus. Questo tutorial offre una guida passo passo per combinare Milvus, un database vettoriale open-source, con i modelli GPT.
L’efficacia di un sistema RAG dipende fortemente dalla qualità dei dati in ingresso. Se i contenuti di origine a cui accede l’applicazione sono scadenti, le risposte generate saranno inaccurate.
Le organizzazioni devono investire in un processo diligente di curatela dei contenuti e di fine-tuning. È necessario perfezionare le fonti dati per migliorarne la qualità. Per applicazioni commerciali, può essere utile coinvolgere un esperto del dominio per revisionare e colmare eventuali lacune informative prima di usare il dataset in un sistema RAG.
RAG è attualmente la tecnica migliore per sfruttare le capacità linguistiche degli LLM insieme a un database specializzato. Questi sistemi affrontano alcune delle sfide più pressanti nel lavoro con i modelli linguistici e rappresentano una soluzione innovativa nel campo dell’elaborazione del linguaggio naturale.
Tuttavia, come ogni altra tecnologia, anche le applicazioni RAG hanno dei limiti, in particolare la dipendenza dalla qualità dei dati in input. Per ottenere il massimo dai sistemi RAG, è fondamentale includere la supervisione umana nel processo.
La curatela meticolosa delle fonti dati, insieme all’expertise degli specialisti, è imprescindibile per garantire l’affidabilità di queste soluzioni.
Se vuoi approfondire il mondo di RAG e capire come può essere usata per costruire applicazioni di IA efficaci, puoi guardare il nostro live training su come creare applicazioni di IA con LangChain. Questo tutorial ti offrirà un’esperienza pratica con LangChain, una libreria pensata per abilitare l’implementazione di sistemi RAG in scenari reali.
Inizia a usare gli LLM oggi!
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

