
Kursus
Konsep Large Language Models (LLM)
2 Hr
104.1K
Untuk menunjukkan apa itu RAG dan bagaimana teknik ini bekerja, mari pertimbangkan skenario yang banyak dihadapi bisnis saat ini.
Bayangkan Anda adalah eksekutif di perusahaan elektronik yang menjual perangkat seperti ponsel pintar dan laptop. Anda ingin membuat chatbot dukungan pelanggan untuk menjawab pertanyaan pengguna terkait spesifikasi produk, pemecahan masalah, informasi garansi, dan lainnya.
Anda ingin memanfaatkan kapabilitas LLM seperti GPT-3 atau GPT-4 untuk menggerakkan chatbot Anda.
Namun, model bahasa besar memiliki keterbatasan berikut yang berdampak pada pengalaman pelanggan yang kurang efisien:
Model bahasa terbatas pada jawaban generik berdasarkan data pelatihannya. Jika pengguna menanyakan hal-hal spesifik tentang perangkat lunak yang Anda jual, atau memiliki pertanyaan terkait cara melakukan pemecahan masalah secara mendalam, LLM tradisional mungkin tidak mampu memberikan jawaban yang akurat.
Ini karena model tersebut tidak dilatih pada data spesifik organisasi Anda. Selain itu, data pelatihan model memiliki tanggal batas, sehingga membatasi kemampuannya untuk memberikan jawaban yang mutakhir.
LLM dapat “berhalusinasi,” artinya mereka cenderung dengan yakin menghasilkan jawaban yang salah berdasarkan fakta yang dibayangkan. Algoritme ini juga dapat memberikan respons yang tidak relevan jika tidak memiliki jawaban yang akurat atas pertanyaan pengguna, sehingga menurunkan pengalaman pelanggan.
Model bahasa sering memberikan respons generik yang tidak disesuaikan dengan konteks tertentu. Ini bisa menjadi kelemahan besar dalam skenario dukungan pelanggan karena preferensi individu biasanya diperlukan untuk menghadirkan pengalaman yang dipersonalisasi.
RAG secara efektif menjembatani kesenjangan ini dengan memberi Anda cara untuk menghubungkan basis pengetahuan umum LLM dengan kemampuan mengakses informasi spesifik, seperti data di basis data produk dan buku petunjuk pengguna Anda. Metodologi ini memungkinkan respons yang sangat akurat dan andal, disesuaikan dengan kebutuhan organisasi Anda.
Sekarang Anda memahami apa itu RAG, mari lihat langkah-langkah yang terlibat dalam menyiapkan kerangka kerja ini:
Pertama, Anda harus mengumpulkan semua data yang diperlukan untuk aplikasi Anda. Dalam kasus chatbot dukungan pelanggan untuk perusahaan elektronik, ini bisa mencakup buku petunjuk pengguna, basis data produk, dan daftar FAQ.
Data chunking adalah proses memecah data menjadi bagian-bagian yang lebih kecil dan lebih mudah dikelola. Misalnya, jika Anda memiliki buku petunjuk pengguna setebal 100 halaman, Anda dapat memecahnya menjadi beberapa bagian, yang masing-masing berpotensi menjawab pertanyaan pelanggan yang berbeda.
Dengan cara ini, setiap potongan data berfokus pada topik tertentu. Saat informasi diambil dari dataset sumber, kemungkinannya lebih besar untuk langsung relevan dengan pertanyaan pengguna karena kita menghindari memasukkan informasi tidak relevan dari seluruh dokumen.
Ini juga meningkatkan efisiensi, karena sistem dapat dengan cepat mendapatkan potongan informasi paling relevan alih-alih memproses seluruh dokumen.
Setelah data sumber dipecah menjadi bagian yang lebih kecil, data tersebut perlu dikonversi ke dalam representasi vektor. Ini melibatkan transformasi data teks menjadi embedding, yaitu representasi numerik yang menangkap makna semantik di balik teks.
Secara sederhana, embedding dokumen memungkinkan sistem memahami pertanyaan pengguna dan mencocokkannya dengan informasi relevan dalam dataset sumber berdasarkan makna teks, bukan sekadar perbandingan kata demi kata. Metode ini memastikan respons yang relevan dan selaras dengan pertanyaan pengguna.
Jika Anda ingin mempelajari lebih lanjut cara data teks diubah menjadi representasi vektor, kami sarankan menjelajahi tutorial kami tentang embedding teks dengan OpenAI API.
Saat kueri pengguna masuk ke sistem, kueri tersebut juga harus dikonversi menjadi embedding atau representasi vektor. Model yang sama harus digunakan untuk embedding dokumen dan embedding kueri untuk memastikan keseragaman.
Setelah kueri dikonversi menjadi embedding, sistem membandingkan embedding kueri dengan embedding dokumen. Sistem mengidentifikasi dan mengambil potongan yang embedding-nya paling mirip dengan embedding kueri, menggunakan ukuran seperti cosine similarity dan Euclidean distance.
Potongan-potongan ini dianggap paling relevan dengan pertanyaan pengguna.
Potongan teks yang diambil, bersama dengan pertanyaan awal pengguna, dimasukkan ke model bahasa. Algoritme akan menggunakan informasi ini untuk menghasilkan jawaban yang koheren atas pertanyaan pengguna melalui antarmuka chat.
Berikut bagan alir sederhana yang merangkum cara kerja RAG:
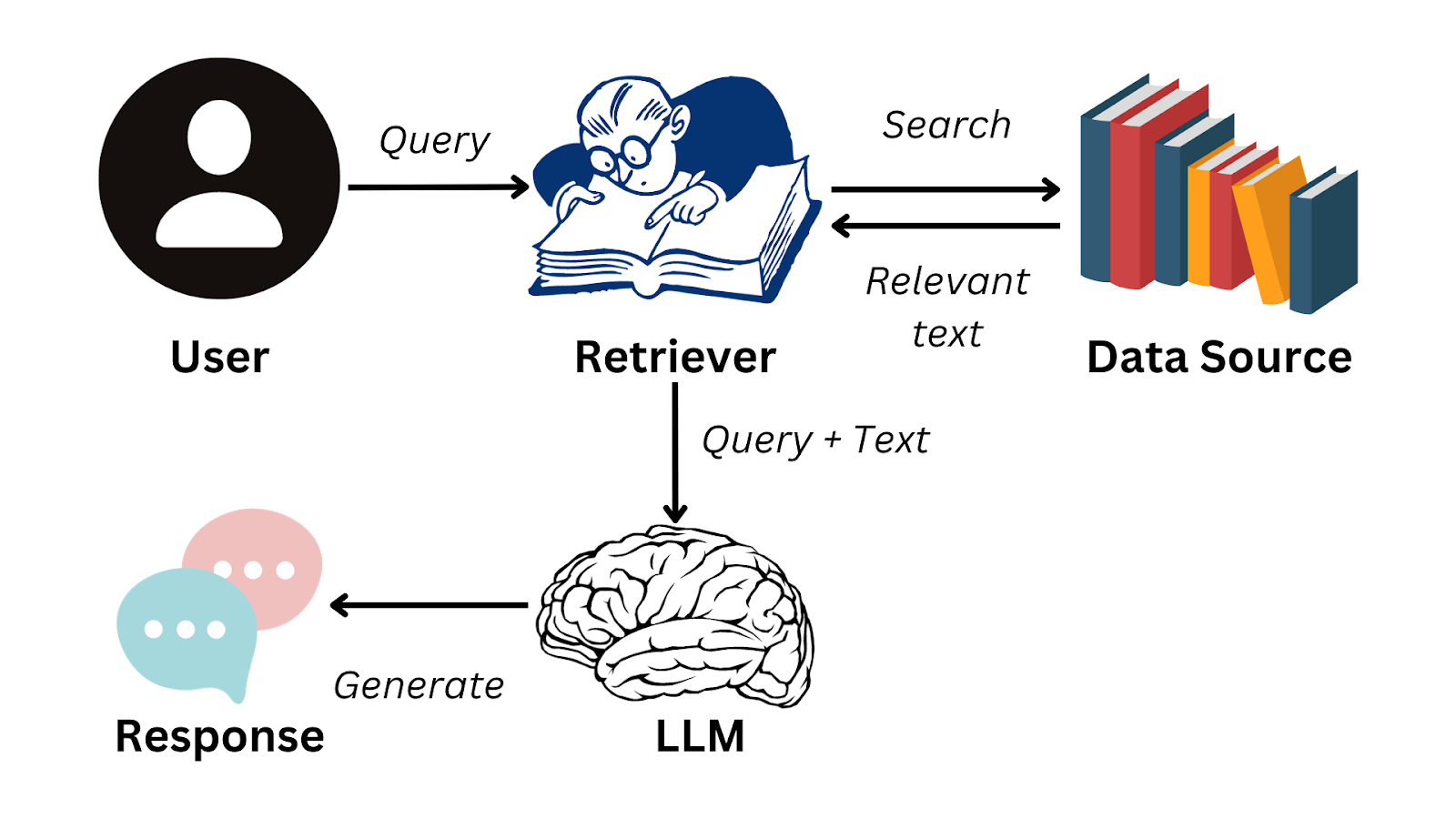
Gambar oleh penulis
Untuk menyelesaikan langkah-langkah menghasilkan respons dengan LLM secara mulus, Anda dapat menggunakan kerangka data seperti LlamaIndex.
Solusi ini memungkinkan Anda mengembangkan aplikasi LLM sendiri dengan mengelola aliran informasi secara efisien dari sumber data eksternal ke model bahasa seperti GPT-3. Untuk mempelajari lebih lanjut tentang kerangka ini dan cara menggunakannya membangun aplikasi berbasis LLM, baca tutorial kami tentang LlamaIndex.
Kini kita tahu bahwa RAG memungkinkan LLM membentuk respons yang koheren berdasarkan informasi di luar data pelatihannya. Sistem seperti ini memiliki beragam use case bisnis yang akan meningkatkan efisiensi organisasi dan pengalaman pengguna. Selain contoh chatbot pelanggan yang kita lihat sebelumnya, berikut beberapa aplikasi praktis RAG:
RAG dapat menggunakan konten dari sumber eksternal untuk menghasilkan ringkasan yang akurat, sehingga menghemat banyak waktu. Misalnya, manajer dan eksekutif tingkat tinggi adalah orang-orang sibuk yang tidak punya waktu untuk menelusuri laporan panjang.
Dengan aplikasi bertenaga RAG, mereka dapat dengan cepat menggali temuan paling kritis dari data teks dan mengambil keputusan lebih efisien tanpa harus membaca dokumen yang panjang.
Sistem RAG dapat digunakan untuk menganalisis data pelanggan, seperti riwayat pembelian dan ulasan, untuk menghasilkan rekomendasi produk. Ini akan meningkatkan pengalaman pengguna secara keseluruhan dan pada akhirnya menghasilkan lebih banyak pendapatan bagi organisasi.
Contohnya, aplikasi RAG dapat digunakan untuk merekomendasikan film yang lebih sesuai di platform streaming berdasarkan riwayat tontonan dan penilaian pengguna. Aplikasi ini juga dapat digunakan untuk menganalisis ulasan tertulis di platform e-niaga.
Karena LLM unggul dalam memahami semantik di balik data teks, sistem RAG dapat memberikan saran personal yang lebih bernuansa dibandingkan sistem rekomendasi tradisional.
Organisasi biasanya membuat keputusan bisnis dengan memantau perilaku pesaing dan menganalisis tren pasar. Ini dilakukan dengan menganalisis secara cermat data dalam laporan bisnis, laporan keuangan, dan dokumen riset pasar.
Dengan aplikasi RAG, organisasi tidak lagi harus menganalisis dan mengidentifikasi tren dalam dokumen-dokumen ini secara manual. Sebagai gantinya, LLM dapat digunakan untuk secara efisien memperoleh wawasan bermakna dan meningkatkan proses riset pasar.
Meskipun aplikasi RAG memungkinkan kita menjembatani kesenjangan antara pencarian informasi dan pemrosesan bahasa alami, implementasinya menghadirkan beberapa tantangan unik. Pada bagian ini, kita akan membahas kompleksitas yang dihadapi saat membangun aplikasi RAG dan bagaimana cara menguranginya.
Mengintegrasikan sistem retrieval dengan LLM bisa sulit. Kompleksitas ini meningkat ketika terdapat banyak sumber data eksternal dengan format yang bervariasi. Data yang dimasukkan ke dalam sistem RAG harus konsisten, dan embedding yang dihasilkan perlu seragam di semua sumber data.
Untuk mengatasi tantangan ini, modul terpisah dapat dirancang untuk menangani berbagai sumber data secara independen. Data dalam setiap modul kemudian dapat dipraproses agar seragam, dan model standar dapat digunakan untuk memastikan embedding memiliki format yang konsisten.
Seiring bertambahnya jumlah data, semakin menantang untuk mempertahankan efisiensi sistem RAG. Banyak operasi kompleks harus dilakukan—seperti menghasilkan embedding, membandingkan makna antar potongan teks, dan mengambil data secara real-time.
Tugas-tugas ini intensif komputasi dan dapat memperlambat sistem seiring ukuran data sumber bertambah.
Untuk mengatasinya, Anda dapat mendistribusikan beban komputasi ke berbagai server dan berinvestasi pada infrastruktur perangkat keras yang tangguh. Untuk meningkatkan waktu respons, akan bermanfaat juga melakukan cache terhadap pertanyaan yang sering diajukan.
Penerapan basis data vektor juga dapat mengurangi tantangan skalabilitas pada sistem RAG. Basis data ini memudahkan Anda menangani embedding, dan dapat dengan cepat mengambil vektor yang paling selaras dengan setiap kueri.
Jika Anda ingin mempelajari lebih lanjut tentang penerapan basis data vektor dalam aplikasi RAG, Anda dapat menonton sesi live code-along kami berjudul Retrieval Augmented Generation with GPT and Milvus. Tutorial ini menawarkan panduan langkah demi langkah untuk menggabungkan Milvus, basis data vektor open-source, dengan model GPT.
Efektivitas sistem RAG sangat bergantung pada kualitas data yang dimasukkan. Jika konten sumber yang diakses aplikasi buruk, respons yang dihasilkan akan tidak akurat.
Organisasi harus berinvestasi dalam kurasi konten yang saksama dan proses fine-tuning. Diperlukan penyempurnaan sumber data untuk meningkatkan kualitasnya. Untuk aplikasi komersial, akan bermanfaat melibatkan pakar materi untuk meninjau dan mengisi kesenjangan informasi sebelum menggunakan dataset dalam sistem RAG.
Saat ini, RAG adalah teknik terbaik yang dikenal untuk memanfaatkan kapabilitas bahasa LLM bersama basis data khusus. Sistem ini mengatasi beberapa tantangan paling mendesak saat bekerja dengan model bahasa, dan menghadirkan solusi inovatif di bidang pemrosesan bahasa alami.
Namun, seperti teknologi lainnya, aplikasi RAG memiliki keterbatasan—terutama ketergantungan pada kualitas data masukan. Untuk memaksimalkan sistem RAG, keterlibatan pengawasan manusia sangat penting.
Kurasi sumber data yang teliti, beserta keahlian pakar, mutlak diperlukan untuk memastikan keandalan solusi ini.
Jika Anda ingin menyelami lebih jauh dunia RAG dan memahami bagaimana teknologi ini dapat digunakan untuk membangun aplikasi AI yang efektif, Anda dapat menonton pelatihan langsung kami tentang membangun aplikasi AI dengan LangChain. Tutorial ini akan memberi Anda pengalaman langsung dengan LangChain, sebuah pustaka yang dirancang untuk memungkinkan implementasi sistem RAG dalam skenario dunia nyata.
Mulai Gunakan LLM Hari Ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
