
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Pour mieux comprendre ce qu'est le RAG et comment la technique fonctionne, examinons un scénario auquel de nombreuses entreprises sont confrontées aujourd'hui.
Imaginez que vous êtes cadre dans une entreprise d'électronique qui vend des appareils tels que des smartphones et des ordinateurs portables. Vous souhaitez créer un chatbot d'assistance à la clientèle pour votre entreprise afin de répondre aux questions des utilisateurs concernant les spécifications des produits, le dépannage, les informations sur la garantie, etc.
Vous souhaitez utiliser les capacités de LLM comme GPT-3 ou GPT-4 pour alimenter votre chatbot.
Cependant, les grands modèles linguistiques présentent les limites suivantes, qui conduisent à une expérience client inefficace :
Les modèles linguistiques se limitent à fournir des réponses génériques sur la base de leurs données d'apprentissage. Si les utilisateurs posent des questions spécifiques au logiciel que vous vendez, ou s'ils veulent savoir comment effectuer un dépannage approfondi, un LLM traditionnel peut ne pas être en mesure de fournir des réponses précises.
Cela est dû au fait qu'ils n'ont pas été formés aux données spécifiques à votre organisation. En outre, les données d'apprentissage de ces modèles ont une date limite, ce qui limite leur capacité à fournir des réponses actualisées.
Les LLM peuvent "halluciner", ce qui signifie qu'ils ont tendance à générer en toute confiance de fausses réponses basées sur des faits imaginaires. Ces algorithmes peuvent également fournir des réponses hors sujet s'ils n'ont pas de réponse précise à la requête de l'utilisateur, ce qui peut entraîner une mauvaise expérience pour le client.
Les modèles linguistiques fournissent souvent des réponses génériques qui ne sont pas adaptées à des contextes spécifiques. Cela peut constituer un inconvénient majeur dans un scénario d'assistance à la clientèle, étant donné que les préférences individuelles des utilisateurs sont généralement nécessaires pour faciliter une expérience personnalisée.
RAG comble efficacement ces lacunes en vous fournissant un moyen d'intégrer la base de connaissances générales des LLM avec la capacité d'accéder à des informations spécifiques, telles que les données présentes dans votre base de données de produits et vos manuels d'utilisation. Cette méthodologie permet d'obtenir des réponses très précises et fiables, adaptées aux besoins de votre organisation.
Maintenant que vous savez ce qu'est un RAG, examinons les étapes de la mise en place de ce cadre :
Vous devez d'abord rassembler toutes les données nécessaires à votre application. Dans le cas d'un chatbot d'assistance à la clientèle pour une entreprise d'électronique, il peut s'agir de manuels d'utilisation, d'une base de données de produits et d'une liste de FAQ.
Le découpage des données consiste à diviser vos données en éléments plus petits et plus faciles à gérer. Par exemple, si vous avez un long manuel d'utilisation de 100 pages, vous pouvez le diviser en plusieurs sections, chacune pouvant répondre à différentes questions des clients.
De cette manière, chaque élément de données se concentre sur un sujet spécifique. Lorsqu'une information est extraite de l'ensemble de données source, il est plus probable qu'elle soit directement applicable à la requête de l'utilisateur, puisque nous évitons d'inclure des informations non pertinentes provenant de documents entiers.
L'efficacité s'en trouve également améliorée, puisque le système peut obtenir rapidement les éléments d'information les plus pertinents au lieu de traiter des documents entiers.
Maintenant que les données sources ont été divisées en plusieurs parties, elles doivent être converties en une représentation vectorielle. Il s'agit de transformer des données textuelles en encastrements, c'est-à-dire en représentations numériques qui capturent le sens sémantique du texte.
En d'autres termes, l'intégration de documents permet au système de comprendre les requêtes des utilisateurs et de les faire correspondre aux informations pertinentes de l'ensemble de données source en se basant sur le sens du texte, au lieu de procéder à une simple comparaison mot à mot. Cette méthode garantit que les réponses sont pertinentes et correspondent à la requête de l'utilisateur.
Si vous souhaitez en savoir plus sur la manière dont les données textuelles sont converties en représentations vectorielles, nous vous recommandons d'explorer notre tutoriel sur les text embeddings avec l'API OpenAI.
Lorsqu'une requête d'utilisateur entre dans le système, elle doit également être convertie en une représentation vectorielle. Le même modèle doit être utilisé pour l'intégration du document et de la requête afin de garantir l'uniformité entre les deux.
Une fois que la requête a été convertie en une représentation, le système compare la représentation de la requête avec les représentations du document. Il identifie et récupère les morceaux dont l'intégration est la plus similaire à l'intégration de la requête, en utilisant des mesures telles que la similarité cosinusoïdale et la distance euclidienne.
Ces morceaux sont considérés comme les plus pertinents par rapport à la requête de l'utilisateur.
Les morceaux de texte récupérés, ainsi que la requête initiale de l'utilisateur, sont introduits dans un modèle linguistique. L'algorithme utilisera ces informations pour générer une réponse cohérente aux questions de l'utilisateur par le biais d'une interface de discussion.
Voici un organigramme simplifié qui résume le fonctionnement du GCR :
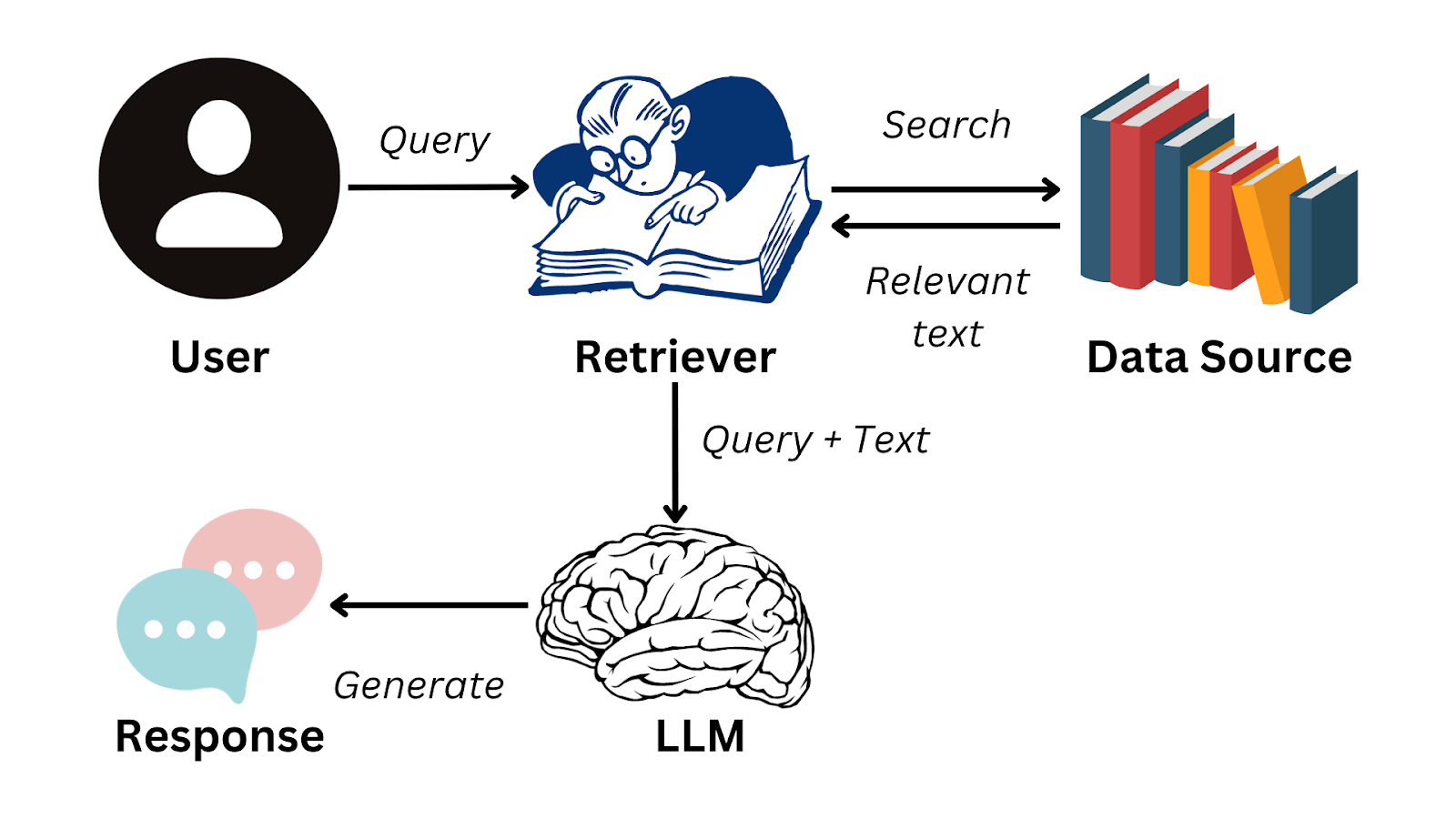
Image de l'auteur
Pour accomplir de manière transparente les étapes requises pour générer des réponses avec des MLD, vous pouvez utiliser un cadre de données tel que LlamaIndex.
Cette solution vous permet de développer vos propres applications LLM en gérant efficacement le flux d'informations entre les sources de données externes et les modèles linguistiques tels que GPT-3. Pour en savoir plus sur ce cadre et sur la façon dont vous pouvez l'utiliser pour créer des applications basées sur LLM, lisez notre tutoriel sur LlamaIndex.
Nous savons maintenant que le RAG permet aux LLM de former des réponses cohérentes basées sur des informations en dehors de leurs données de formation. Un tel système peut être utilisé de diverses manières par les entreprises afin d'améliorer l'efficacité de l'organisation et l'expérience des utilisateurs. Outre l'exemple du chatbot client que nous avons vu plus haut dans l'article, voici quelques applications pratiques de RAG :
RAG peut utiliser le contenu de sources externes pour produire des résumés précis, ce qui permet un gain de temps considérable. Par exemple, les managers et les cadres de haut niveau sont des personnes très occupées qui n'ont pas le temps d'examiner des rapports détaillés.
Avec une application alimentée par RAG, ils peuvent rapidement accéder aux conclusions les plus importantes des données textuelles et prendre des décisions plus efficacement au lieu d'avoir à lire de longs documents.
Les systèmes RAG peuvent être utilisés pour analyser les données des clients, telles que les achats antérieurs et les commentaires, afin de générer des recommandations de produits. Cela améliorera l'expérience globale de l'utilisateur et, en fin de compte, générera plus de revenus pour l'organisation.
Par exemple, les applications RAG peuvent être utilisées pour recommander de meilleurs films sur les plateformes de streaming en fonction de l'historique de visionnage et des évaluations de l'utilisateur. Ils peuvent également être utilisés pour analyser les commentaires écrits sur les plateformes de commerce électronique.
Comme les LLM excellent dans la compréhension de la sémantique des données textuelles, les systèmes RAG peuvent fournir aux utilisateurs des suggestions personnalisées plus nuancées que celles d'un système de recommandation traditionnel.
Les entreprises prennent généralement leurs décisions en surveillant le comportement de leurs concurrents et en analysant les tendances du marché. Pour ce faire, il faut analyser méticuleusement les données contenues dans les rapports d'activité, les états financiers et les documents d'étude de marché.
Avec une application RAG, les organisations n'ont plus besoin d'analyser manuellement et d'identifier les tendances dans ces documents. Au contraire, un LLM peut être utilisé pour obtenir des informations significatives et améliorer le processus d'étude de marché.
Si les applications RAG nous permettent de combler le fossé entre la recherche d'informations et le traitement du langage naturel, leur mise en œuvre pose quelques problèmes particuliers. Dans cette section, nous examinerons les difficultés rencontrées lors de la création d'applications RAG et nous verrons comment elles peuvent être atténuées.
Il peut être difficile d'intégrer un système de recherche à un LLM. Cette complexité s'accroît lorsqu'il existe de multiples sources de données externes dans des formats différents. Les données introduites dans un système RAG doivent être cohérentes et les embeddings générés doivent être uniformes pour toutes les sources de données.
Pour surmonter cette difficulté, des modules distincts peuvent être conçus pour traiter indépendamment les différentes sources de données. Les données de chaque module peuvent alors être prétraitées pour assurer leur uniformité, et un modèle normalisé peut être utilisé pour garantir que les encastrements ont un format cohérent.
Au fur et à mesure que la quantité de données augmente, il devient de plus en plus difficile de maintenir l'efficacité du système RAG. De nombreuses opérations complexes doivent être effectuées, telles que la génération d'enchâssements, la comparaison de la signification de différents morceaux de texte et l'extraction de données en temps réel.
Ces tâches sont intensives en termes de calcul et peuvent ralentir le système à mesure que la taille des données sources augmente.
Pour relever ce défi, vous pouvez répartir la charge de calcul sur différents serveurs et investir dans une infrastructure matérielle robuste. Pour améliorer le temps de réponse, il peut également être utile de mettre en cache les requêtes les plus fréquentes.
La mise en œuvre de bases de données vectorielles peut également atténuer le problème d'extensibilité des systèmes RAG. Ces bases de données vous permettent de manipuler facilement les embeddings et de retrouver rapidement les vecteurs les plus étroitement alignés avec chaque requête.
Si vous souhaitez en savoir plus sur la mise en œuvre des bases de données vectorielles dans une application RAG, vous pouvez regarder notre session de code-along en direct, intitulée Retrieval Augmented Generation with GPT and Milvus (Génération augmentée de récupération avec GPT et Milvus). Ce tutoriel propose un guide étape par étape pour combiner Milvus, une base de données vectorielle open-source, avec les modèles GPT.
L'efficacité d'un système RAG dépend fortement de la qualité des données qui l'alimentent. Si le contenu source auquel l'application accède est de mauvaise qualité, les réponses générées seront inexactes.
Les organisations doivent investir dans un processus diligent de curation et de mise au point du contenu. Il est nécessaire d'affiner les sources de données pour en améliorer la qualité. Pour les applications commerciales, il peut être utile de faire appel à un expert en la matière pour examiner et combler les lacunes en matière d'information avant d'utiliser l'ensemble de données dans un système RAG.
RAG est actuellement la technique la plus connue pour exploiter les capacités linguistiques des LLM avec une base de données spécialisée. Ces systèmes répondent à certains des défis les plus urgents rencontrés lors de l'utilisation de modèles de langage et constituent une solution innovante dans le domaine du traitement du langage naturel.
Cependant, comme toute autre technologie, les applications RAG ont leurs limites - en particulier leur dépendance à l'égard de la qualité des données d'entrée. Pour tirer le meilleur parti des systèmes RAG, il est essentiel d'inclure un contrôle humain dans le processus.
La conservation méticuleuse des sources de données, ainsi que les connaissances des experts, sont impératives pour garantir la fiabilité de ces solutions.
Si vous souhaitez plonger plus profondément dans le monde de RAG et comprendre comment il peut être utilisé pour créer des applications d'IA efficaces, vous pouvez regarder notre formation en direct sur la création d'applications d'IA avec LangChain. Ce tutoriel vous permettra d'acquérir une expérience pratique avec LangChain, une bibliothèque conçue pour permettre la mise en œuvre de systèmes RAG dans des scénarios réels.
Commencez dès aujourd'hui avec les LLM !
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
blog
Kurtis Pykes
15 min
blog
Zoumana Keita
15 min
Tutoriel

