
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
Um besser zu verdeutlichen, was RAG ist und wie die Technik funktioniert, lass uns ein Szenario betrachten, mit dem viele Unternehmen heute konfrontiert sind.
Stell dir vor, du bist eine Führungskraft in einem Elektronikunternehmen, das Geräte wie Smartphones und Laptops verkauft. Du möchtest einen Chatbot für den Kundensupport deines Unternehmens erstellen, um Nutzeranfragen zu Produktspezifikationen, Fehlerbehebung, Garantieinformationen und mehr zu beantworten.
Du möchtest die Fähigkeiten von LLMs wie GPT-3 oder GPT-4 nutzen, um deinen Chatbot zu betreiben.
Große Sprachmodelle haben jedoch die folgenden Einschränkungen, die zu einem ineffizienten Kundenerlebnis führen:
Sprachmodelle sind darauf beschränkt, generische Antworten auf der Grundlage ihrer Trainingsdaten zu geben. Wenn Nutzer/innen spezielle Fragen zu der Software stellen, die du verkaufst, oder wenn sie Fragen zur Fehlerbehebung haben, kann ein herkömmlicher LLM möglicherweise keine genauen Antworten geben.
Das liegt daran, dass sie nicht für die spezifischen Daten deines Unternehmens geschult wurden. Außerdem haben die Trainingsdaten dieser Modelle einen Stichtag, was ihre Fähigkeit einschränkt, aktuelle Antworten zu geben.
LLMs können "halluzinieren", das heißt, sie neigen dazu, selbstbewusst falsche Antworten zu geben, die auf eingebildeten Fakten basieren. Diese Algorithmen können auch Antworten geben, die nicht zum Thema passen, wenn sie keine genaue Antwort auf die Anfrage des Nutzers haben, was zu einem schlechten Kundenerlebnis führt.
Sprachmodelle liefern oft generische Antworten, die nicht auf bestimmte Kontexte zugeschnitten sind. Dies kann in einem Kundensupport-Szenario ein großer Nachteil sein, da individuelle Nutzerpräferenzen in der Regel erforderlich sind, um ein personalisiertes Kundenerlebnis zu ermöglichen.
RAG überbrückt diese Lücken effektiv, indem es dir eine Möglichkeit bietet, die allgemeine Wissensbasis der LLMs mit der Möglichkeit zu verbinden, auf spezifische Informationen zuzugreifen, wie z.B. die Daten in deiner Produktdatenbank und den Benutzerhandbüchern. Diese Methodik ermöglicht sehr genaue und zuverlässige Antworten, die auf die Bedürfnisse deines Unternehmens zugeschnitten sind.
Jetzt, wo du weißt, was RAG ist, schauen wir uns die Schritte an, die nötig sind, um diesen Rahmen einzurichten:
Du musst zunächst alle Daten sammeln, die du für deine Bewerbung brauchst. Im Falle eines Chatbots für den Kundensupport eines Elektronikunternehmens kann dies Benutzerhandbücher, eine Produktdatenbank und eine Liste von FAQs umfassen.
Beim Data Chunking werden deine Daten in kleinere, besser handhabbare Teile zerlegt. Wenn du zum Beispiel ein umfangreiches 100-seitiges Benutzerhandbuch hast, könntest du es in verschiedene Abschnitte unterteilen, die jeweils unterschiedliche Kundenfragen beantworten.
Auf diese Weise konzentriert sich jedes Datenpaket auf ein bestimmtes Thema. Wenn eine Information aus dem Quelldatensatz abgerufen wird, ist es wahrscheinlicher, dass sie direkt auf die Anfrage des Nutzers anwendbar ist, da wir vermeiden, irrelevante Informationen aus ganzen Dokumenten einzubeziehen.
Dies verbessert auch die Effizienz, da das System schnell die wichtigsten Informationen abrufen kann, anstatt ganze Dokumente zu verarbeiten.
Nachdem die Quelldaten nun in kleinere Teile zerlegt wurden, müssen sie in eine Vektordarstellung umgewandelt werden. Dabei werden Textdaten in Einbettungen umgewandelt, d.h. in numerische Darstellungen, die die semantische Bedeutung des Textes erfassen.
Mit einfachen Worten: Die Dokumenteneinbettung ermöglicht es dem System, Benutzeranfragen zu verstehen und sie mit relevanten Informationen im Quelldatensatz abzugleichen, und zwar auf der Grundlage der Bedeutung des Textes und nicht durch einen einfachen Wort-zu-Wort-Vergleich. Diese Methode stellt sicher, dass die Antworten relevant und auf die Anfrage des Nutzers abgestimmt sind.
Wenn du mehr darüber erfahren möchtest, wie Textdaten in Vektordarstellungen umgewandelt werden, empfehlen wir dir unser Tutorial über Texteinbettungen mit der OpenAI API.
Wenn eine Benutzeranfrage in das System eingeht, muss sie auch in eine Einbettung oder Vektordarstellung umgewandelt werden. Sowohl für die Einbettung der Dokumente als auch für die Einbettung der Abfragen muss das gleiche Modell verwendet werden, um die Einheitlichkeit zwischen beiden zu gewährleisten.
Sobald die Abfrage in eine Einbettung umgewandelt ist, vergleicht das System die Abfrageeinbettung mit den Dokumenteneinbettungen. Sie identifiziert und findet die Chunks, deren Einbettungen der Abfrage am ähnlichsten sind, indem sie Maße wie die Kosinusähnlichkeit und die euklidische Distanz verwendet.
Diese Chunks werden als die relevantesten für die Anfrage des Nutzers angesehen.
Die abgerufenen Textabschnitte werden zusammen mit der ursprünglichen Benutzeranfrage in ein Sprachmodell eingegeben. Der Algorithmus nutzt diese Informationen, um über ein Chat-Interface eine schlüssige Antwort auf die Fragen des Nutzers zu geben.
Hier ist ein vereinfachtes Flussdiagramm, das zusammenfasst, wie die RAG funktioniert:
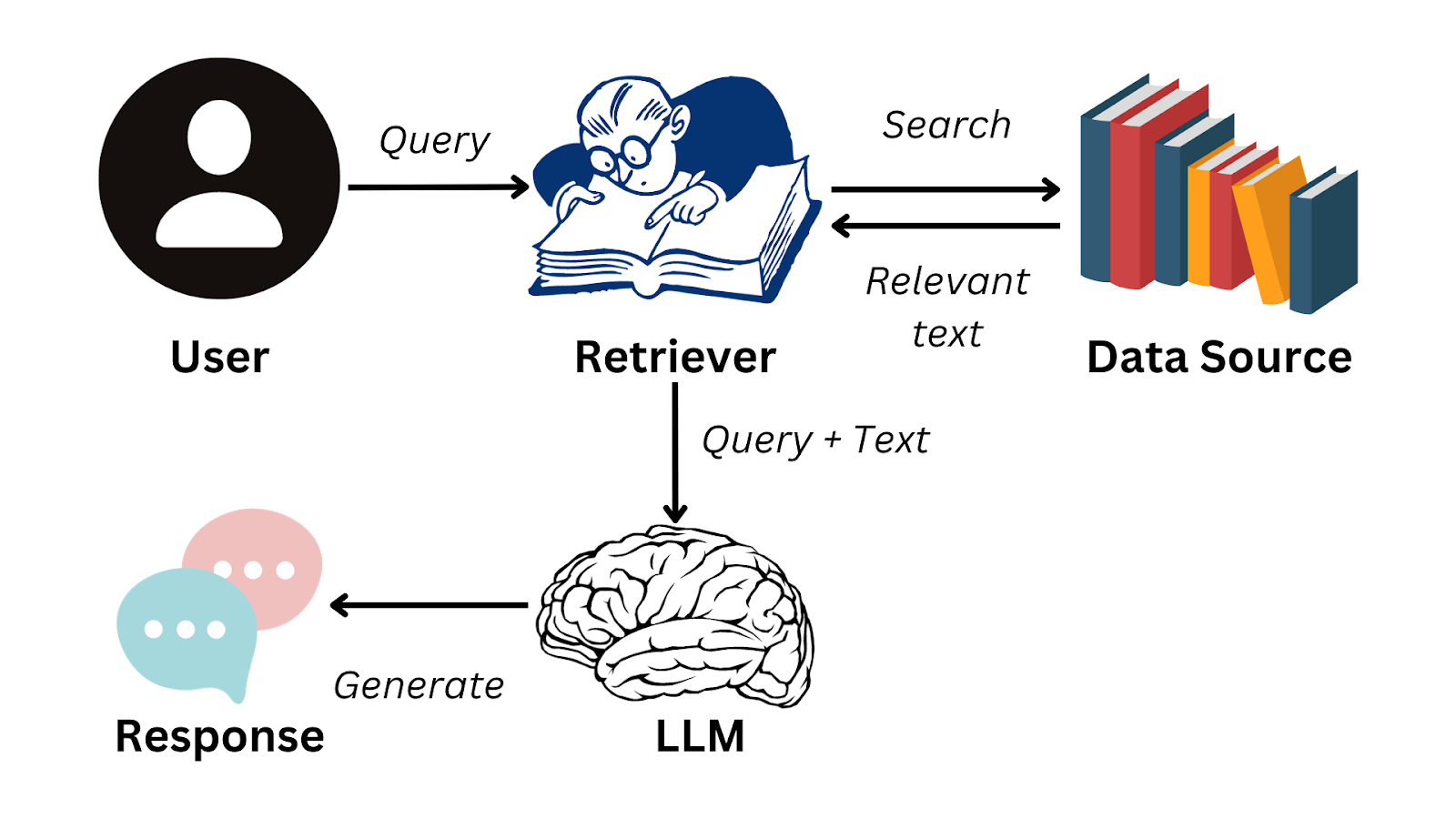
Bild vom Autor
Um die Schritte, die zur Erstellung von Antworten mit LLMs erforderlich sind, nahtlos durchzuführen, kannst du ein Daten-Framework wie LlamaIndex verwenden.
Diese Lösung ermöglicht es dir, deine eigenen LLM-Anwendungen zu entwickeln, indem du den Informationsfluss von externen Datenquellen zu Sprachmodellen wie GPT-3 effizient verwaltest. Wenn du mehr über dieses Framework erfahren möchtest und wie du damit LLM-basierte Anwendungen erstellen kannst, lies unser Tutorial zu LlamaIndex.
Wir wissen jetzt, dass RAG es LLMs ermöglicht, kohärente Antworten auf der Grundlage von Informationen außerhalb ihrer Trainingsdaten zu bilden. Ein solches System hat eine Vielzahl von Anwendungsfällen, die die organisatorische Effizienz und das Nutzererlebnis verbessern. Abgesehen von dem Kunden-Chatbot-Beispiel, das wir weiter oben im Artikel gesehen haben, gibt es hier einige praktische Anwendungen von RAG:
RAG kann Inhalte aus externen Quellen nutzen, um genaue Zusammenfassungen zu erstellen, was zu einer erheblichen Zeitersparnis führt. Zum Beispiel sind Manager und Führungskräfte vielbeschäftigte Menschen, die keine Zeit haben, umfangreiche Berichte zu lesen.
Mit einer RAG-gestützten Anwendung können sie schnell auf die wichtigsten Erkenntnisse aus Textdaten zugreifen und Entscheidungen effizienter treffen, anstatt lange Dokumente lesen zu müssen.
Mit RAG-Systemen können Kundendaten wie frühere Einkäufe und Bewertungen analysiert werden, um Produktempfehlungen zu erstellen. Das steigert das Gesamterlebnis der Nutzerinnen und Nutzer und generiert letztendlich mehr Umsatz für das Unternehmen.
RAG-Anwendungen können zum Beispiel genutzt werden, um bessere Filme auf Streaming-Plattformen zu empfehlen, die auf der Sehgeschichte und den Bewertungen des Nutzers/der Nutzerin basieren. Sie können auch verwendet werden, um schriftliche Bewertungen auf E-Commerce-Plattformen zu analysieren.
Da LLMs die Semantik von Textdaten besonders gut verstehen, können RAG-Systeme den Nutzern personalisierte Vorschläge machen, die differenzierter sind als die eines herkömmlichen Empfehlungssystems.
Unternehmen treffen ihre Geschäftsentscheidungen in der Regel, indem sie das Verhalten ihrer Konkurrenten im Auge behalten und Markttrends analysieren. Dies geschieht durch die sorgfältige Analyse von Daten, die in Geschäftsberichten, Jahresabschlüssen und Marktforschungsunterlagen enthalten sind.
Mit einer RAG-Anwendung müssen Unternehmen diese Dokumente nicht mehr manuell analysieren und Trends in ihnen erkennen. Stattdessen kann ein LLM eingesetzt werden, um effizient aussagekräftige Erkenntnisse zu gewinnen und den Marktforschungsprozess zu verbessern.
RAG-Anwendungen ermöglichen es uns zwar, die Lücke zwischen Information Retrieval und natürlicher Sprachverarbeitung zu schließen, ihre Umsetzung stellt uns jedoch vor einige besondere Herausforderungen. In diesem Abschnitt befassen wir uns mit den Schwierigkeiten, die bei der Erstellung von RAG-Anwendungen auftreten, und erörtern, wie sie entschärft werden können.
Es kann schwierig sein, ein Retrievalsystem in ein LLM zu integrieren. Diese Komplexität nimmt zu, wenn es mehrere Quellen für externe Daten in unterschiedlichen Formaten gibt. Daten, die in ein RAG-System eingespeist werden, müssen konsistent sein, und die erzeugten Einbettungen müssen über alle Datenquellen hinweg einheitlich sein.
Um diese Herausforderung zu meistern, können separate Module entwickelt werden, die verschiedene Datenquellen unabhängig voneinander verarbeiten. Die Daten in den einzelnen Modulen können dann vorverarbeitet werden, damit sie einheitlich sind, und es kann ein standardisiertes Modell verwendet werden, um sicherzustellen, dass die Einbettungen ein einheitliches Format haben.
Je größer die Datenmenge wird, desto schwieriger wird es, die Effizienz des RAG-Systems aufrechtzuerhalten. Es müssen viele komplexe Operationen durchgeführt werden, wie z. B. das Erzeugen von Einbettungen, das Vergleichen der Bedeutung verschiedener Textstücke und das Abrufen von Daten in Echtzeit.
Diese Aufgaben sind rechenintensiv und können das System mit zunehmender Größe der Quelldaten verlangsamen.
Um dieser Herausforderung zu begegnen, kannst du die Rechenlast auf verschiedene Server verteilen und in eine robuste Hardware-Infrastruktur investieren. Um die Antwortzeit zu verbessern, kann es auch von Vorteil sein, häufig gestellte Anfragen zu cachen.
Die Implementierung von Vektordatenbanken kann auch das Problem der Skalierbarkeit in RAG-Systemen entschärfen. Mit diesen Datenbanken kannst du einfach mit Einbettungen umgehen und schnell die Vektoren finden, die am besten mit der jeweiligen Abfrage übereinstimmen.
Wenn du mehr über die Implementierung von Vektordatenbanken in einer RAG-Anwendung erfahren möchtest, kannst du dir unsere Live-Sitzung mit dem Titel Retrieval Augmented Generation with GPT and Milvus ansehen. Dieses Tutorial bietet eine Schritt-für-Schritt-Anleitung zur Kombination von Milvus, einer Open-Source-Vektordatenbank, mit GPT-Modellen.
Die Wirksamkeit eines RAG-Systems hängt stark von der Qualität der Daten ab, die in das System eingespeist werden. Wenn der Quellinhalt, auf den die Anwendung zugreift, schlecht ist, werden die Antworten ungenau sein.
Unternehmen müssen in einen sorgfältigen Prozess der Inhaltskuratierung und Feinabstimmung investieren. Es ist notwendig, die Datenquellen zu verfeinern, um ihre Qualität zu verbessern. Bei kommerziellen Anwendungen kann es von Vorteil sein, einen Fachexperten hinzuzuziehen, der den Datensatz vor der Verwendung in einem RAG-System überprüft und eventuelle Informationslücken füllt.
RAG ist derzeit die bekannteste Technik, um die Sprachfähigkeiten von LLMs zusammen mit einer spezialisierten Datenbank zu nutzen. Diese Systeme befassen sich mit einigen der dringendsten Herausforderungen bei der Arbeit mit Sprachmodellen und stellen eine innovative Lösung im Bereich der Verarbeitung natürlicher Sprache dar.
Doch wie jede andere Technologie haben auch RAG-Anwendungen ihre Grenzen - vor allem, weil sie von der Qualität der Eingabedaten abhängen. Um das Beste aus den RAG-Systemen herauszuholen, ist es wichtig, die menschliche Aufsicht in den Prozess einzubeziehen.
Um die Zuverlässigkeit dieser Lösungen zu gewährleisten, ist eine sorgfältige Aufbereitung der Datenquellen zusammen mit Expertenwissen unerlässlich.
Wenn du tiefer in die Welt von RAG eintauchen und verstehen möchtest, wie du damit effektive KI-Anwendungen erstellen kannst, kannst du dir unser Live-Training zum Erstellen von KI-Anwendungen mit LangChain ansehen. In diesem Tutorium lernst du LangChain kennen, eine Bibliothek, die die Implementierung von RAG-Systemen in realen Szenarien ermöglicht.
Beginne noch heute mit LLMs!
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Zoumana Keita
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Matt Crabtree
14 Min.
