
Cursus
Concepten van Large Language Models (LLMs)
2 Hr
104.1K
Om beter te laten zien wat RAG is en hoe de techniek werkt, bekijken we een scenario waar veel bedrijven vandaag de dag mee te maken hebben.
Stel, je bent leidinggevende bij een elektronicabedrijf dat apparaten verkoopt zoals smartphones en laptops. Je wilt een klantenservice-chatbot bouwen die vragen van gebruikers beantwoordt over productspecificaties, probleemoplossing, garantie-informatie en meer.
Je wilt graag de mogelijkheden van LLM’s zoals GPT-3 of GPT-4 gebruiken om je chatbot aan te sturen.
Grote taalmodellen hebben echter de volgende beperkingen, wat leidt tot een inefficiënte klantervaring:
Taalmodellen zijn beperkt tot generieke antwoorden op basis van hun trainingsdata. Als gebruikers vragen stellen die specifiek zijn voor de software die je verkoopt, of als ze diepgaande troubleshooting willen doen, kan een traditioneel LLM mogelijk geen nauwkeurige antwoorden geven.
Dat komt doordat ze niet zijn getraind op data die specifiek is voor jouw organisatie. Bovendien hebben de trainingsdata van deze modellen een afkapdatum, waardoor hun vermogen om actuele antwoorden te geven beperkt is.
LLM’s kunnen “hallucineren”: ze genereren dan met grote stelligheid onjuiste antwoorden op basis van verzonnen feiten. Als ze geen goed antwoord hebben op de vraag van de gebruiker, kunnen ze ook off-topic reageren, wat tot een slechte klantervaring leidt.
Taalmodellen geven vaak generieke antwoorden die niet zijn toegesneden op specifieke contexten. Dit is een groot nadeel in een klantenservicesituatie, omdat individuele voorkeuren van gebruikers meestal nodig zijn voor een persoonlijke ervaring.
RAG overbrugt deze kloof effectief door je een manier te bieden om de algemene kennis van LLM’s te combineren met toegang tot specifieke informatie, zoals de data in je productdatabase en handleidingen. Deze aanpak zorgt voor zeer nauwkeurige en betrouwbare antwoorden die aansluiten op de behoeften van jouw organisatie.
Nu je weet wat RAG is, kijken we naar de stappen die komen kijken bij het opzetten van dit framework:
Verzamel eerst alle data die je applicatie nodig heeft. Voor een klantenservice-chatbot van een elektronicabedrijf kan dit handleidingen, een productdatabase en een lijst met veelgestelde vragen omvatten.
Data chunking is het opsplitsen van je data in kleinere, beter hanteerbare stukken. Als je bijvoorbeeld een lange handleiding van 100 pagina’s hebt, kun je die opdelen in secties die elk mogelijk antwoord geven op verschillende klantvragen.
Zo focust elke chunk op een specifiek onderwerp. Wanneer informatie uit de brondataset wordt opgehaald, is de kans groter dat die direct toepasbaar is op de vraag van de gebruiker, omdat we irrelevante informatie uit volledige documenten vermijden.
Dit verbetert ook de efficiëntie, omdat het systeem snel de meest relevante stukjes informatie kan ophalen in plaats van hele documenten te verwerken.
Nu de brondata is opgesplitst, moet die worden omgezet naar een vectorrepresentatie. Dit houdt in dat tekst wordt getransformeerd naar embeddings: numerieke representaties die de semantische betekenis van tekst vastleggen.
Eenvoudig gezegd stellen document-embeddings het systeem in staat om gebruikersvragen te begrijpen en te koppelen aan relevante informatie in de brondataset op basis van betekenis, in plaats van een simpele woord-voor-woordvergelijking. Zo blijven de antwoorden relevant en in lijn met de vraag van de gebruiker.
Wil je meer leren over hoe tekst wordt omgezet in vectorrepresentaties? Bekijk dan onze tutorial over text embeddings met de OpenAI API.
Wanneer een gebruikersvraag het systeem binnenkomt, moet die ook worden omgezet in een embedding of vectorrepresentatie. Gebruik voor zowel document- als query-embedding hetzelfde model om uniformiteit te waarborgen.
Zodra de vraag is omgezet in een embedding, vergelijkt het systeem de query-embedding met de document-embeddings. Het identificeert en haalt chunks op waarvan de embeddings het meest lijken op de query-embedding, met maten zoals cosinus-similariteit en Euclidische afstand.
Deze chunks worden beschouwd als het meest relevant voor de vraag van de gebruiker.
De opgehaalde tekstchunks worden, samen met de oorspronkelijke gebruikersvraag, ingevoerd in een taalmodel. Het algoritme gebruikt deze informatie om via een chatinterface een samenhangend antwoord op de vraag te genereren.
Hier is een vereenvoudigd stroomdiagram dat samenvat hoe RAG werkt:
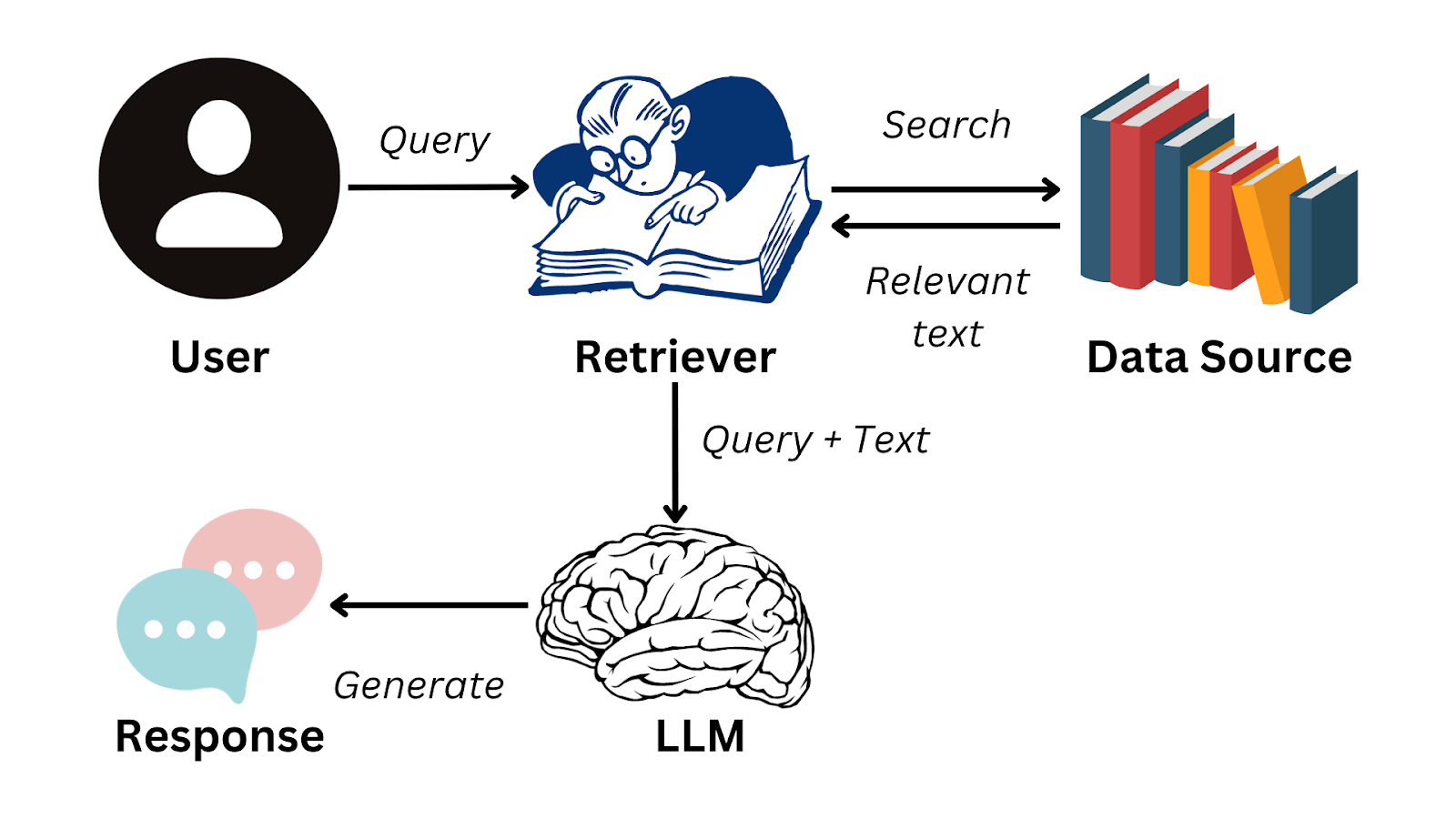
Afbeelding door de auteur
Om de stappen voor het genereren van antwoorden met LLM’s naadloos uit te voeren, kun je een dataframework zoals LlamaIndex gebruiken.
Met deze oplossing kun je eigen LLM-toepassingen ontwikkelen door de informatiestroom van externe databronnen naar taalmodellen zoals GPT-3 efficiënt te beheren. Wil je meer weten over dit framework en hoe je het kunt gebruiken om LLM-gebaseerde applicaties te bouwen? Lees dan onze tutorial over LlamaIndex.
We weten nu dat RAG LLM’s in staat stelt om samenhangende antwoorden te vormen op basis van informatie buiten hun trainingsdata. Zo’n systeem kent allerlei zakelijke use-cases die de efficiëntie en gebruikerservaring verbeteren. Naast het voorbeeld van de klantenservice-chatbot eerder in dit artikel, zijn dit enkele praktische toepassingen van RAG:
RAG kan content uit externe bronnen gebruiken om accurate samenvattingen te maken, wat veel tijd kan besparen. Managers en executives hebben bijvoorbeeld vaak geen tijd om uitgebreide rapporten door te pluizen.
Met een RAG-gestuurde applicatie kunnen ze snel de belangrijkste bevindingen uit tekstdata halen en efficiënter beslissingen nemen, zonder lange documenten te hoeven lezen.
RAG-systemen kunnen klantdata analyseren, zoals eerdere aankopen en reviews, om productaanbevelingen te genereren. Dit verbetert de algehele gebruikerservaring en kan uiteindelijk meer omzet opleveren.
Zo kunnen RAG-applicaties betere films aanbevelen op streamingplatforms op basis van kijkgeschiedenis en beoordelingen. Ze kunnen ook geschreven reviews op e-commerceplatforms analyseren.
Omdat LLM’s uitblinken in het begrijpen van de semantiek van tekstdata, kunnen RAG-systemen gebruikers persoonlijkere en genuanceerdere suggesties geven dan traditionele aanbevelingssystemen.
Organisaties nemen zakelijke beslissingen door concurrentgedrag te volgen en markttrends te analyseren. Dit gebeurt door data in bedrijfsrapporten, financiële overzichten en marktonderzoeken nauwgezet te bestuderen.
Met een RAG-applicatie hoeven organisaties trends in deze documenten niet langer handmatig te analyseren en te identificeren. In plaats daarvan kan een LLM worden ingezet om efficiënt betekenisvolle inzichten te halen en het marktonderzoeksproces te verbeteren.
Hoewel RAG-applicaties de kloof tussen informatieophaling en natuurlijke taalverwerking dichten, brengt de implementatie enkele unieke uitdagingen met zich mee. In dit deel bekijken we de complexiteiten bij het bouwen van RAG-toepassingen en hoe je die kunt mitigeren.
Het kan lastig zijn om een retrieval-systeem te integreren met een LLM. Deze complexiteit neemt toe wanneer er meerdere externe databronnen in uiteenlopende formaten zijn. Data die in een RAG-systeem wordt gevoerd, moet consistent zijn en de gegenereerde embeddings moeten uniform zijn over alle bronnen.
Om dit te ondervangen kun je aparte modules ontwerpen die verschillende databronnen onafhankelijk verwerken. De data binnen elke module kan vervolgens worden voorbewerkt voor uniformiteit, en een gestandaardiseerd model kan zorgen dat de embeddings een consistent formaat hebben.
Naarmate de hoeveelheid data toeneemt, wordt het lastiger om de efficiëntie van het RAG-systeem te behouden. Er moeten veel complexe operaties worden uitgevoerd—zoals embeddings genereren, betekenis tussen verschillende tekstfragmenten vergelijken en data realtime ophalen.
Deze taken zijn rekenintensief en kunnen het systeem vertragen naarmate de brondataset groeit.
Om dit aan te pakken kun je de rekenlast verdelen over verschillende servers en investeren in robuuste hardware-infrastructuur. Om de responstijd te verbeteren, kan het ook nuttig zijn om veelgestelde queries te cachen.
De inzet van vector-databases kan de schaalbaarheidsuitdaging in RAG-systemen eveneens verkleinen. Deze databases maken het eenvoudig om met embeddings te werken en kunnen snel de vectoren ophalen die het best aansluiten op elke query.
Wil je meer leren over de implementatie van vector-databases in een RAG-applicatie? Bekijk dan onze live code-along-sessie: Retrieval Augmented Generation with GPT and Milvus. Deze tutorial biedt een stapsgewijze gids voor het combineren van Milvus, een open-source vector-database, met GPT-modellen.
De effectiviteit van een RAG-systeem hangt sterk af van de kwaliteit van de aangeleverde data. Als de broncontent die de applicatie raadpleegt zwak is, zullen de gegenereerde antwoorden onnauwkeurig zijn.
Organisaties moeten investeren in zorgvuldige contentcuratie en fine-tuning. Het is noodzakelijk om databronnen te verfijnen om de kwaliteit te verhogen. Voor commerciële toepassingen kan het nuttig zijn om een inhoudsexpert te betrekken om eventuele kennishiaten te beoordelen en aan te vullen voordat de dataset in een RAG-systeem wordt gebruikt.
RAG is momenteel de bekendste techniek om de taalmogelijkheden van LLM’s te benutten in combinatie met een gespecialiseerde database. Deze systemen pakken enkele van de meest prangende uitdagingen aan bij het werken met taalmodellen en bieden een innovatieve oplossing binnen natural language processing.
Maar zoals elke technologie hebben RAG-applicaties hun beperkingen—met name de afhankelijkheid van de kwaliteit van de inputdata. Om het maximale uit RAG-systemen te halen, is menselijke toetsing cruciaal.
Zorgvuldige curatie van databronnen, aangevuld met expertise, is essentieel om de betrouwbaarheid van deze oplossingen te borgen.
Wil je dieper duiken in de wereld van RAG en begrijpen hoe je het kunt gebruiken om effectieve AI-toepassingen te bouwen? Bekijk dan onze live training over het bouwen van AI-applicaties met LangChain. Deze tutorial laat je hands-on kennismaken met LangChain, een bibliotheek die is ontworpen om de implementatie van RAG-systemen in praktijksituaties mogelijk te maken.
Ga vandaag nog aan de slag met LLM’s!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
