Courses
R 数据科学的线性代数
4小时
21.1K
有些函数过于复杂,难以直接处理——于是数学家想出了用多项式来“仿真”它们的方法。
这就是麦克劳林级数背后的基本思想。它把一个函数表示为多项式项的无限和,每一项都由该函数在零点处的导数构成。这样得到的表达式即便在原函数过于复杂时也便于计算。
您可以将麦克劳林级数看作泰勒级数的一个特例——只是把中心取在零点。这个限制让推导更简单、应用更容易。
本文将介绍麦克劳林级数的公式,带您走一遍最常见的展开,并说明如何理解与应用它们。
麦克劳林级数将一个函数表示为由其在零点处导数组成的项的无限和。
每一项都是一个多项式——即某个x的幂乘以一个导数值的系数。把足够多的这些项相加,您就得到一个在零点附近与原函数表现相同的多项式。
用多项式去逼近复杂函数,是麦克劳林级数的核心思想。多项式易于计算、求导和积分,而大多数其他函数并非如此。
泰勒级数将函数近似为以任意点a为中心的无限多项式。您选定这个点,在其附近构建级数,从而得到一个在该点附近表现良好的多项式。
麦克劳林级数就是把a = 0的泰勒级数。仅此而已。
以零为中心会简化数学推导,因为多项式项不再带有(x - a)的位移,而变成了单纯的x的幂。因此,在微积分、物理和机器学习中常见的标准函数,通常都有简洁且众所周知的麦克劳林展开。

泰勒级数与麦克劳林级数对比
小结:当您需要在某个非零的特定点附近近似函数时,用泰勒级数;当以零点为出发点(这在实践中很常见)时,用麦克劳林级数。
麦克劳林级数公式把任意函数f(x)表示为一个无限和:
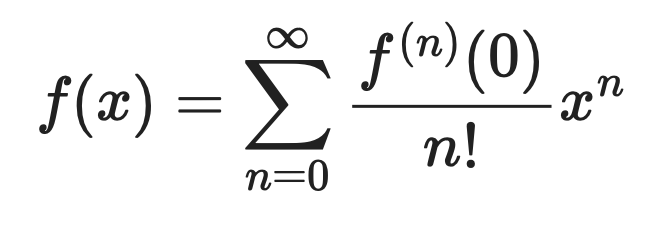
麦克劳林级数公式
展开后如下:
麦克劳林级数公式(展开)
每一项包含三部分:
f⁽ⁿ⁾(0) —— f的第n阶导数在零点处的取值,体现了函数在该点的局部行为
n! —— n的阶乘,用于缩放各项,使得当n增大时级数仍保持良好性质
xⁿ —— x的第n次幂,决定了每一项离零点“影响”多远
首项f(0)把多项式的常数项设为函数在零点的值。之后的每一项都在做校正——调整斜率、曲率等——直到多项式与原函数足够接近。
一句话:项越多,近似越好。
构建麦克劳林级数基本上就是重复做一件事:在零点求导数,然后把结果堆叠成多项式。
步骤如下:
x = 0代入f(x),得到第一项——确定多项式起始值的常数项f'(x)、f''(x)、f'''(x)等,并在每一步都取零点的值。每个值都揭示了函数的某种性质——斜率、曲率以及曲率变化的速度x幂最后把所有项相加:
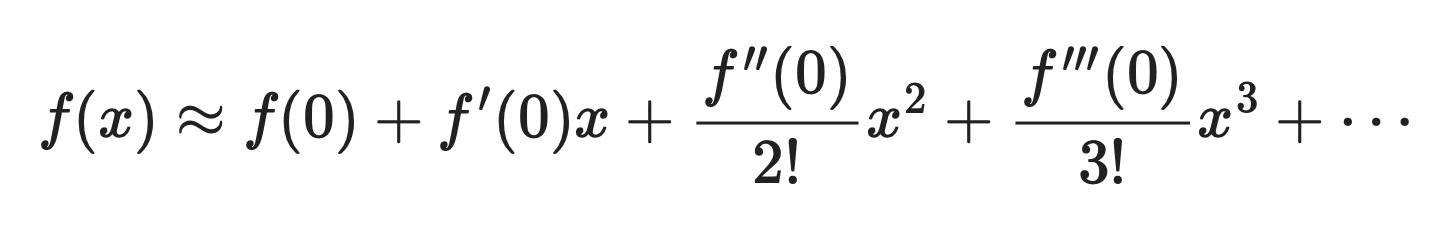
麦克劳林级数如何起作用
每一项都会改进近似。第一项匹配函数值;第二项匹配斜率;第三项匹配曲率;以此类推。
当近似已满足您的精度需求时就可以停止——或者继续下去以获得更高精度。
有些函数出现频率极高,值得记住它们的麦克劳林展开。下面四个是您最常会见到的。
指数函数是最简单的情形——eˣ的各阶导数仍是eˣ,因此在零点处各阶导数都等于 1。
ex 展开
系数就是1/n!。该级数对所有x都收敛,因此在实践中极为有用。
正弦函数的展开只包含x的奇次幂,并且符号正负交替。
sin(x) 展开
sin(x)在零点的偶阶导数都为零,因此这些项会消失。剩下的是奇次幂、阶乘分母、交替符号。与eˣ一样,该级数对所有x都收敛。
余弦的展开则与正弦“镜像”——只出现x的偶次幂,符号同样正负交替。
cos(x) 展开
这也合理,因为cos(x)是sin(x)的导数,逐项对sin(x)的展开求导即可得到本级数。奇次幂项消失的原因与正弦中偶次幂项消失相同——零点处的导数把它们“抹掉”了。它对所有x都收敛。
这四者中模式最简单:每个系数都是 1,没有阶乘,也没有交替符号。
1/(1-x) 展开
这是一个几何级数,所以模式看起来很整齐。但与上面三个函数不同,该级数只在|x| < 1时收敛。如果把x取在这个范围之外,各项不会趋近于零,反而会发散。
最后,给视觉型学习者一张图,比较上述四个级数在取多项时的表现:
常见的麦克劳林级数
麦克劳林级数在实际应用中很少需要所有无限项。通常取部分和——前若干项——作为近似即可。
包含的项越多,部分和对原函数的跟踪就越贴近。只取两项,只能在零点附近粗略拟合;再多加几项,近似可延伸到更远处。每一项都在纠正先前项未能捕捉的部分。
以sin(x)为例。完整级数为:
sin(x) 近似公式
让我们用部分和来近似sin(0.3),看看各自与精确值的差异:
1 项:0.3 —— 误差约 0.0045
2 项:0.3 - (0.3³/6) = 0.2955 —— 误差约 0.0000196
3 项:再加(0.3⁵/120) = 0.29552 —— 误差约 0.0000000239
三项即可达到小数点后六位的精度,基本足够。多数情况下无需再往后加。
用 Python 表达同样的思路:
import numpy as np
from math import factorial
def maclaurin_sin(x, n_terms):
return sum(((-1)**n * x**(2*n+1)) / factorial(2*n+1) for n in range(n_terms))
vec_sin = np.vectorize(maclaurin_sin)
x_val = 0.3
print(f"Approximating sin({x_val}):")
print(f" Exact value : {np.sin(x_val):.10f}")
for n in [1, 2, 3, 4]:
approx = maclaurin_sin(x_val, n)
error = abs(np.sin(x_val) - approx)
print(f" {n} term(s) : {approx:.10f} | error: {error:.2e}"运行后会在x = 0.3处打印各个部分和及其误差:

用 Python 近似 sin(x) 的麦克劳林示例
您也可以通过可视化来查看:
sin(x) 麦克劳林近似的图示
您可以直观看到每个近似与sin(x)函数的贴合程度。
麦克劳林级数并不总对所有x都有效。对某些函数,级数只在零点附近的特定范围内收敛到正确值;在该范围之外,部分和会发散。
这个范围称为收敛半径。它告诉您从零点出发,级数在多远的范围内仍然可靠。
不同函数的行为不同:
eˣ、sin(x)、cos(x) —— 对所有x都收敛。代入任意数,级数都能给出正确结果
1/(1-x) —— 仅在|x| < 1时收敛。在x = 1处函数本身发散,级数在该点附近也会失去收敛性
可以把收敛半径想象成以零点为中心的“信任圆”。只有在圆内,级数才是有效近似。
您不总是需要去计算收敛半径。对于标准函数,它是已知量。但当处理不太熟悉的函数时,在依赖麦克劳林近似之前检查收敛性是个好习惯。
麦克劳林级数在数学、物理和机器学习的实际计算工作中随处可见。
计算机无法对大多数函数做符号计算,它们计算的是多项式。当库去计算sin(x)或eˣ时,往往采用的是多项式近似——由该函数的麦克劳林或泰勒展开而来。级数提供了硬件可以快速、稳定(不会陷入无限循环)计算的形式。
当精确解过于复杂时,物理学中常用麦克劳林级数。最常见的例子是小角近似:当θ很小时,sin(θ) ≈ θ。这正是sin(x)麦克劳林级数的第一项。它能简化单摆方程、光学计算和波动模型——把非线性问题转化为可解的线性问题。
在机器学习中,泰勒与麦克劳林展开支撑着您日常接触的许多数学。梯度下降使用损失函数的一阶近似来确定前进方向;牛顿法等二阶方法利用曲率项。当研究者分析模型损失面的局部行为时,往往是在某点附近用泰勒展开来思考。
在理论分析中,sigmoid和tanh等激活函数也常用麦克劳林级数来近似。把它们展开成多项式,便于讨论梯度与饱和行为。
麦克劳林级数只做一件事:把函数在零点附近用多项式来近似。这个看似简单的想法影响深远。
无论是数值计算、物理还是机器学习,套路都是一样的:面对复杂函数,用足够接近的多项式替代,然后去解决真正的问题。梯度下降、小角近似以及各类内置库函数背后的数学,都可追溯到这个核心思想。
eˣ、sin(x)、cos(x)与1/(1-x)的展开值得牢记。它们出现得足够频繁,能一眼认出会真正节省时间,尤其当您在阅读论文时。
与 DataCamp 一起学习
Courses
Courses
Courses