
In diesem Beitrag werden wir verschiedene Arten von generativen Modellen kennenlernen, mit denen wir interessante Projekte erstellen können. Außerdem werden wir lernen, wie wir ChatGPT nutzen können, um ein durchgängiges Data Science-Projekt zu erstellen.
Fünf generative KI-Projekte verbessern dein Portfolio im Bereich maschinelles Lernen und Data Science und machen dich zu einem attraktiven Kandidaten für die Bewerbung. Sie werden dir auch helfen, die neuesten Tools wie Stable Diffusion Inpainting, Segment Anything, Stanford Alpaca, LoRA, LangChain, OpenAI API und Whisper zu verstehen.
Mehr über die GPT-Reihe, einschließlich GPT-1, GPT-2, GPT-3 und GPT-4, erfährst du in dem Artikel "Was ist GPT-4 und warum ist es wichtig?
1. StableSAM: Stabile Diffusion Inpainting mit Segment Anything
In diesem Projekt verwendest du Meta's segment-anything, Hugging Face diffusers und Gradio, um eine App zu erstellen, die den Hintergrund, das Gesicht, die Kleidung oder alles, was du auswählst, verändern kann. Er braucht nur das Bild, den ausgewählten Bereich und die Eingabeaufforderung.
Stabile Diffusion Inpainting Pipeline erstellen
Wir werden eine Stable Diffusion Inpainting Pipeline mit Diffusor und Modellgewichten erstellen, die auf stabilityai/stable-diffusion-2-inpainting - Hugging Face verfügbar sind. Danach fügen wir sie zur GPU-Beschleunigung zu "cuda" hinzu.
Definieren der Bildmaske und der Inpainting-Funktion
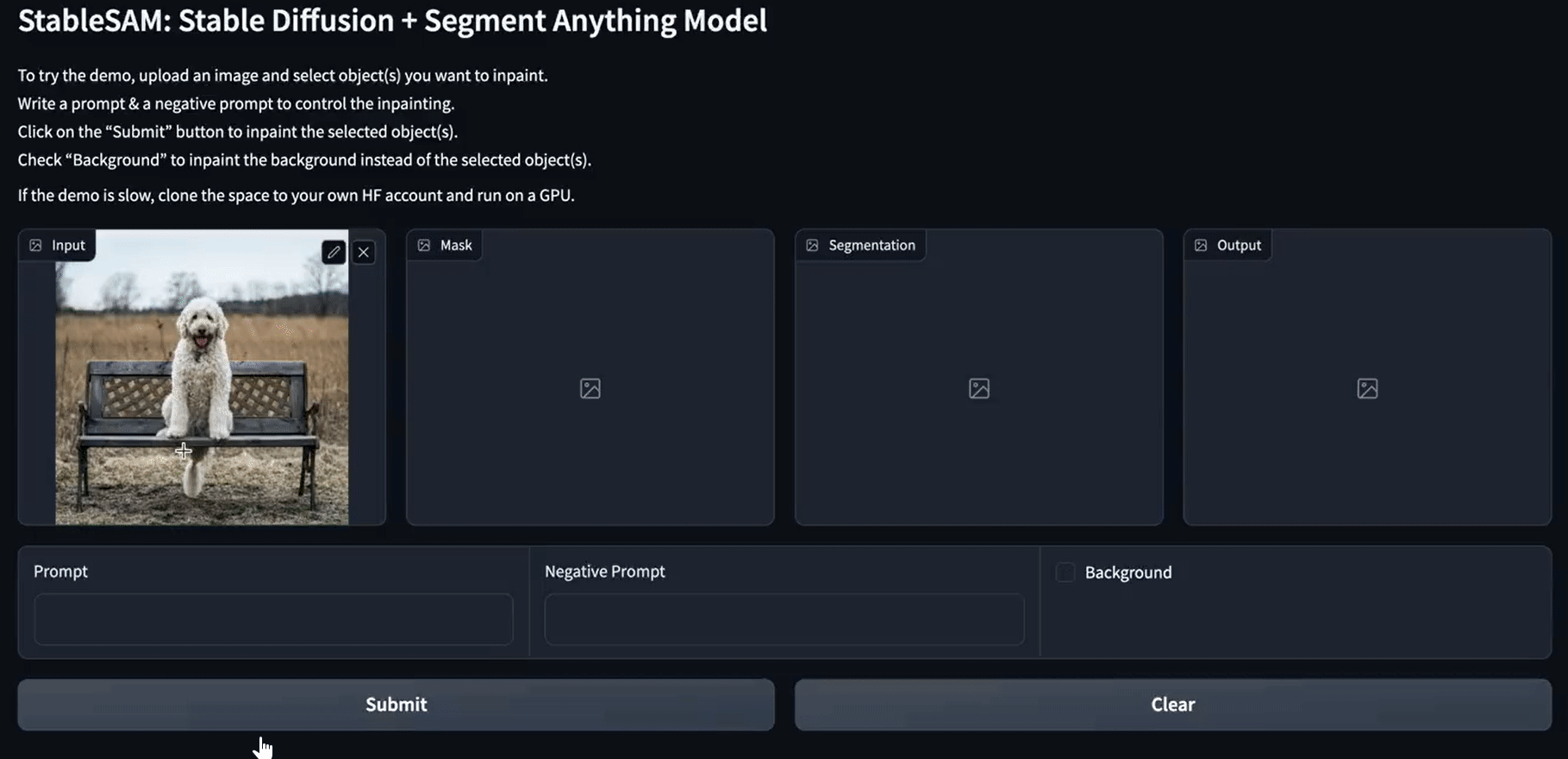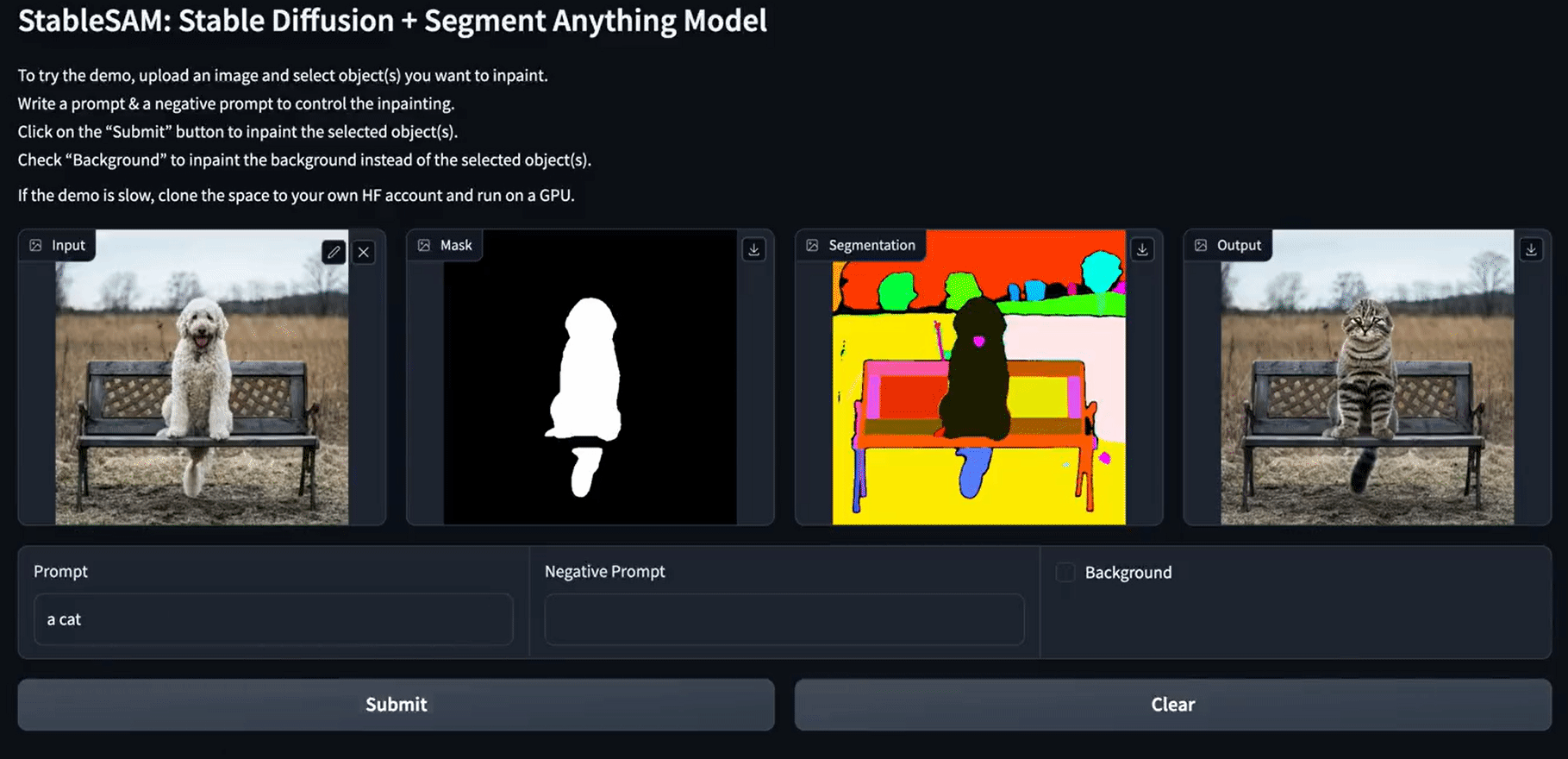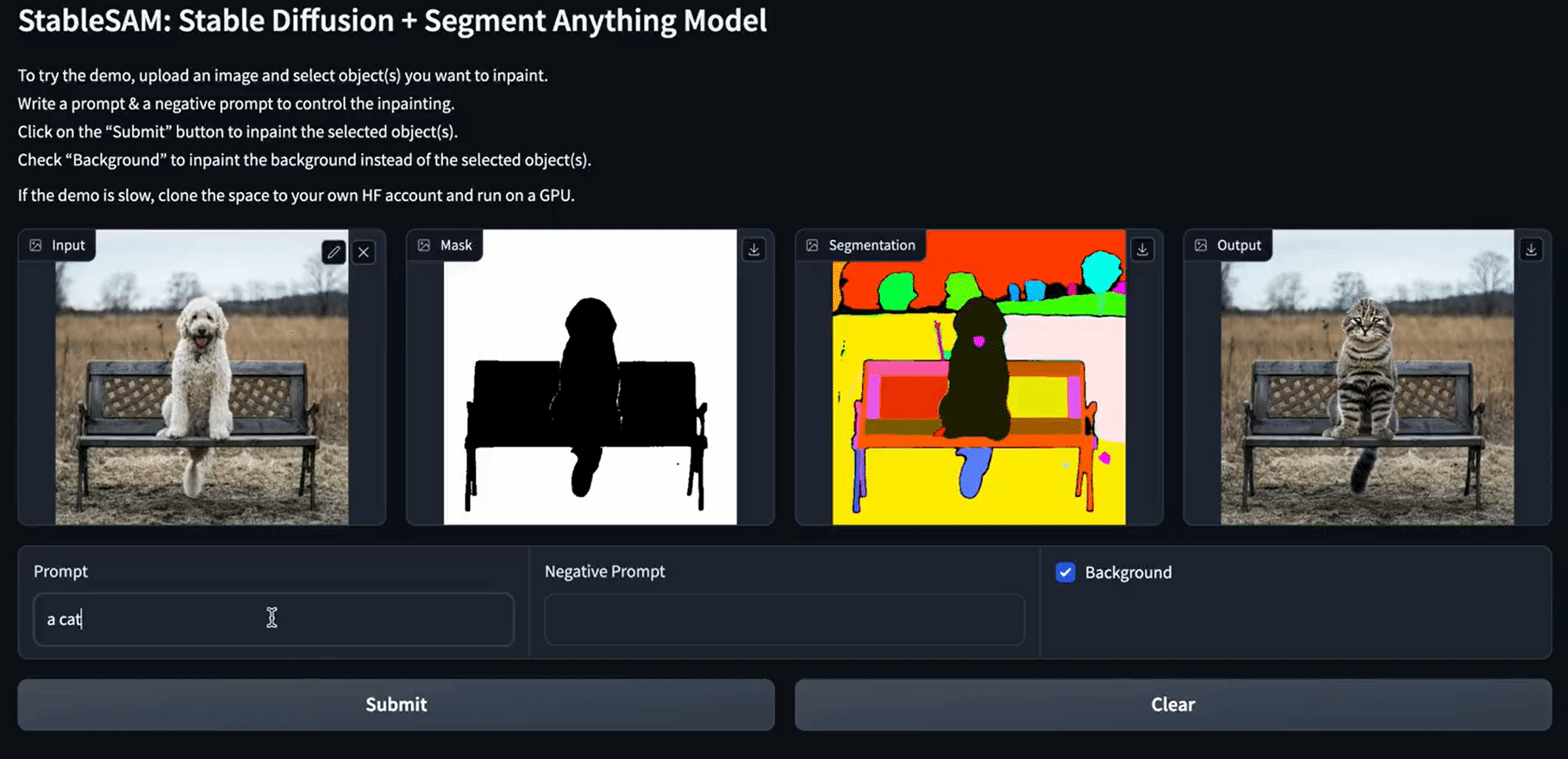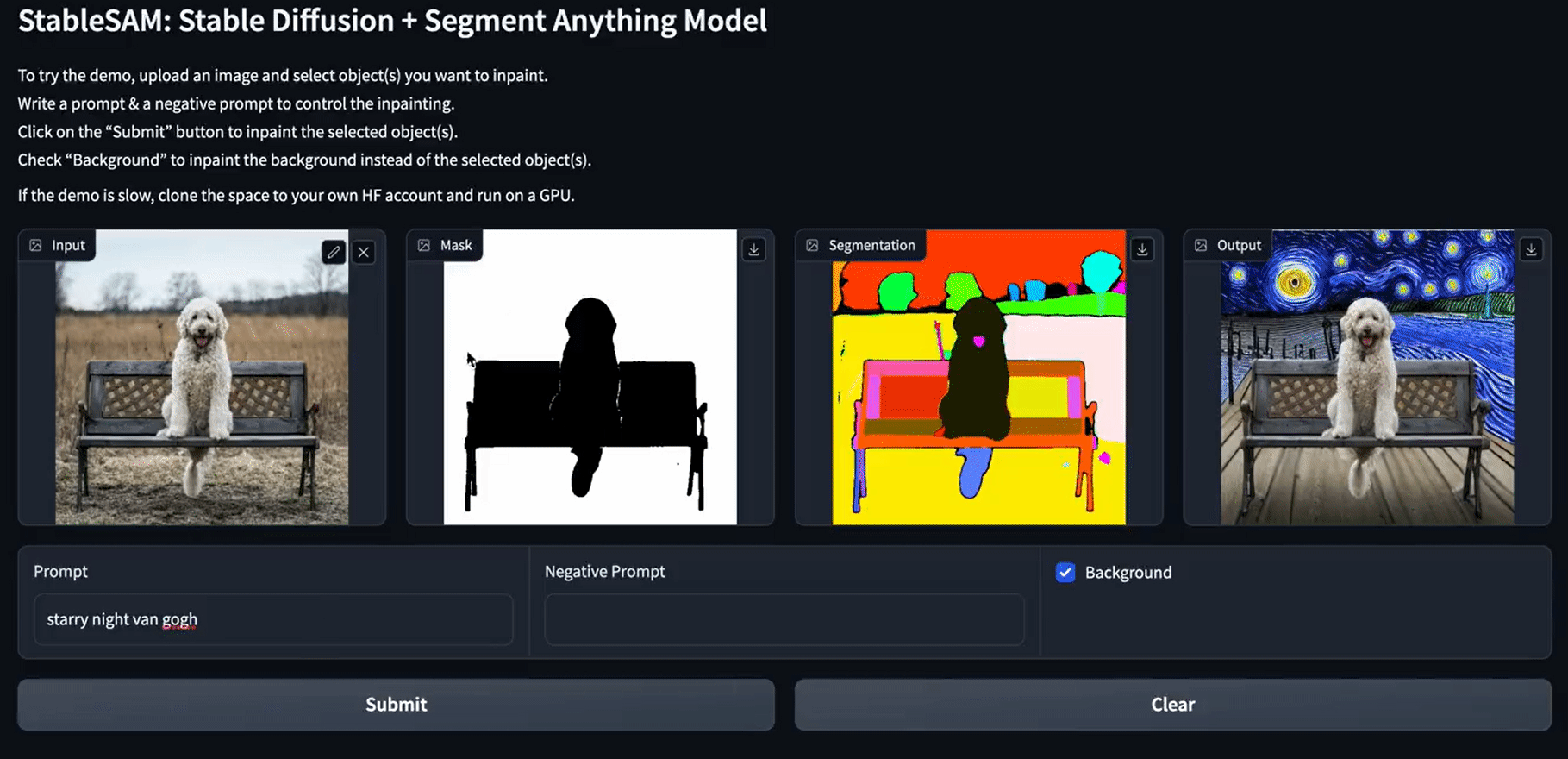
Die Bildmaskenfunktion wird mit SAM Predictor erstellt. Sie nimmt ein Bild, einen ausgewählten Bildausschnitt und den booleschen Wert is_backgroud, um ein maskiertes Bild und eine Segmentierung zu erstellen.
Danach verwendet die Inpainting-Funktion die Stable Diffusion Inpainting Pipeline, um ausgewählte Teile der Bilder zu verändern. Die Pipelines benötigen ein Eingangsbild, ein maskiertes Bild, ein segmentiertes Bild, einen Prompt-Text und einen negativen Prompt-Text.
Gradio UI erstellen
Du wirst eine Reihe erstellen und drei Bildblöcke hinzufügen. Für ein minimal rentables Produkt musst du eine weitere Zeile mit einem Submit-Button hinzufügen. Danach musst du das Objekt "Eingabebild" ändern, um Pixel auszuwählen, eine Maske und eine Segmentierung zu erstellen und dem Submit-Button eine Aktion hinzuzufügen, um die Inpainting-Funktion auszuführen.
Gradio ist recht einfach zu erlernen. Du kannst alles erfahren, wenn du die Gradio Docs liest.
Verbesserte Version von StableSAM
Die verbesserte Version von StableSAM ist bei hugging face erhältlich. Sie enthält eine angepasste Inpainting-Pipeline, die ControlNet nutzt. Es verwendet Runway ML Stable Diffusion Inpainting anstelle von Stability AI.
Wie du siehst, sieht die endgültige Version der App sauber aus, mit einem Segmentierungsblock, einer sauberen Schaltfläche, einer Hintergrundoption und einer negativen Eingabeaufforderung.
Ressourcen:
- Umarmendes Gesicht Demo: StableSAM
- Youtube Tutorial: Stabiles Diffusions-Inpainting mit Segment Anything Model (SAM)
2. Alpaca-LoRA: ChatGPT-ähnlich mit minimalen Ressourcen aufbauen
Alpaca-LoRA bietet alle notwendigen Komponenten, damit du deinen eigenen ChatGPT-ähnlichen Chatbot mit einer einzigen GPU erstellen kannst.
In diesem Abschnitt befassen wir uns mit der anfänglichen Einrichtung, dem Training, dem Inferenzskript und dem nativen Client, der die Inferenz auf der CPU ausführt.
Lokale Einrichtung
- Klon-Repository: tloen/alpaca-lora
- Abhängigkeiten installieren mit
pip install -r requirements.txt - Wenn bitsandbytes nicht funktioniert, installiere es aus der Quelle.
Ausbildung
In diesem Teil sehen wir uns das Skript zur Feinabstimmung an, das du mit dem bereinigten Stanford Alpaca-Modell auf dem LLaMA-Modell ausführen kannst.
Du kannst im Repository nachschauen, um die Hyperparameter für eine bessere Leistung zu optimieren.
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca'Inferenz
Das Inferenzskript liest das LLaMA-Grundmodell aus Hugging Face und lädt die LoRA-Gewichte, um eine Gradio-Schnittstelle auszuführen.
python generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
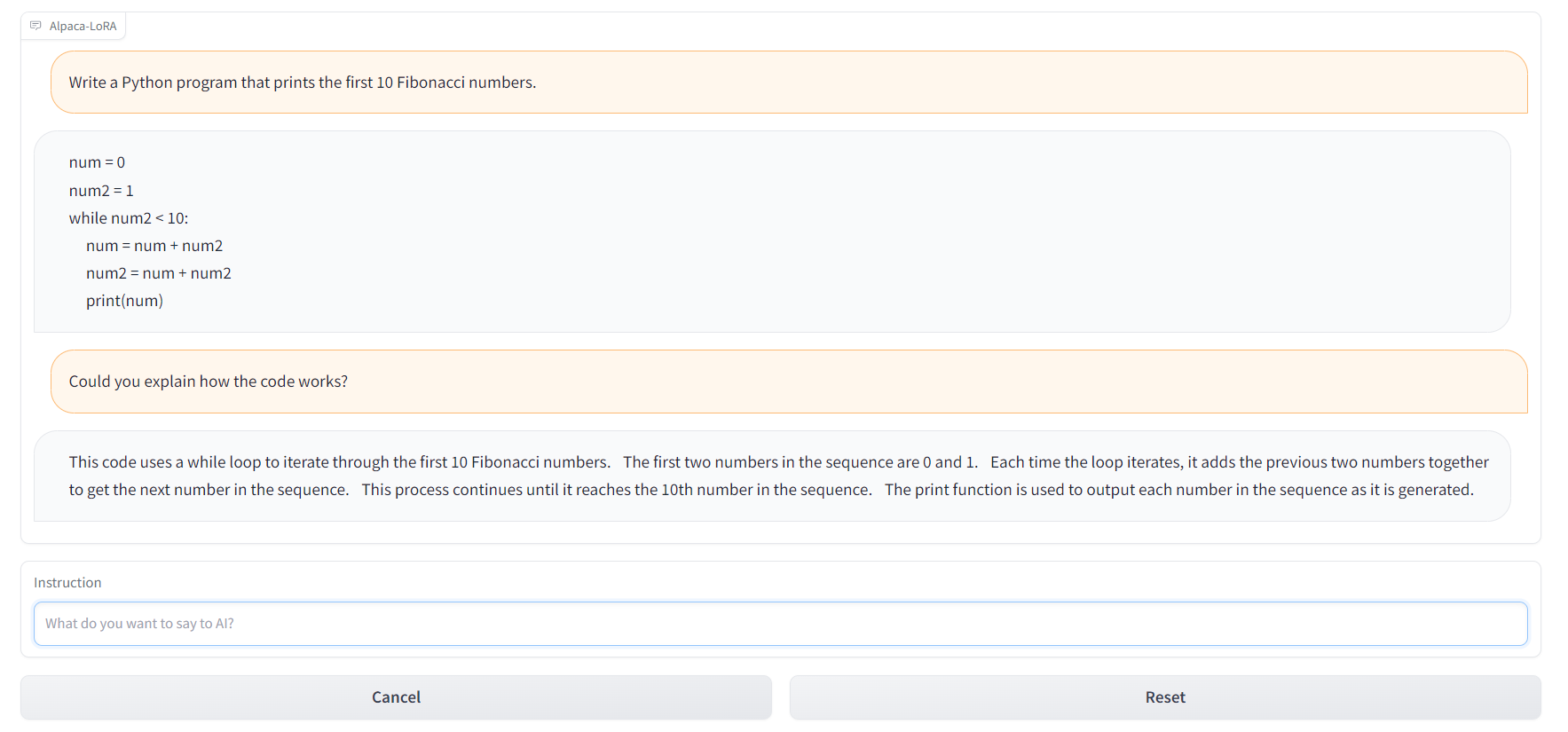
--lora_weights 'tloen/alpaca-lora-7b'Du kannst auch die Datei alpaca.cpp verwenden, um die alpaca-Modelle auf dem Raspberry Pi 4 mit CPU oder 4 GB RAM laufen zu lassen. Außerdem kannst du den Alpaca-LoRA-Serve verwenden, um eine ChatGPT-ähnliche Schnittstelle zu erstellen, wie unten gezeigt.
Ressourcen:
- GitHub: tloen/alpaca-lora
- Modellkarte: tloen/alpaca-lora-7b
- Umarmendes Gesicht Demo: Alpaca-LoRA-Serve
- ChatGPT-ähnliche Schnittstelle: Alpaca-LoRA-Serve
- Alpaca Dataset: AlpacaDataCleaned
3. Automatisierte PDF-Interaktion mit LangChain und ChatGPT
Erstelle deinen eigenen ChatPDF-Klon mit dem PDF-Lader von LangChain, OpenAI Embeddings und GPT-3.5. Du erstellst einen Chatbot, der mit deinem Buch, deinen rechtlichen Unterlagen und anderen wichtigen PDF-Dokumenten kommunizieren kann.
Laden des Dokuments
Wir werden den LangChain Document Loader verwenden, um PDFs zu laden und den Inhalt zu lesen.
from langchain.document_loaders import PyPDFLoader
pdf_path = "./paper.pdf"
loader = PyPDFLoader(pdf_path)
pages = loader.load_and_split()
print(pages[0].page_content)Erstellen von Einbettungen und Vektorisierung
Wir werden die Einbettungen mit OpenAIEmbeddings Klasse aus der LangChain API. Danach übergibst du diese Einbettungen an die Chroma Klasse, um eine Vektordatenbank für das PDF-Dokument zu erstellen.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(pages, embedding=embeddings, persist_directory=".")
vectordb.persist()Abfrage der PDF-Datei
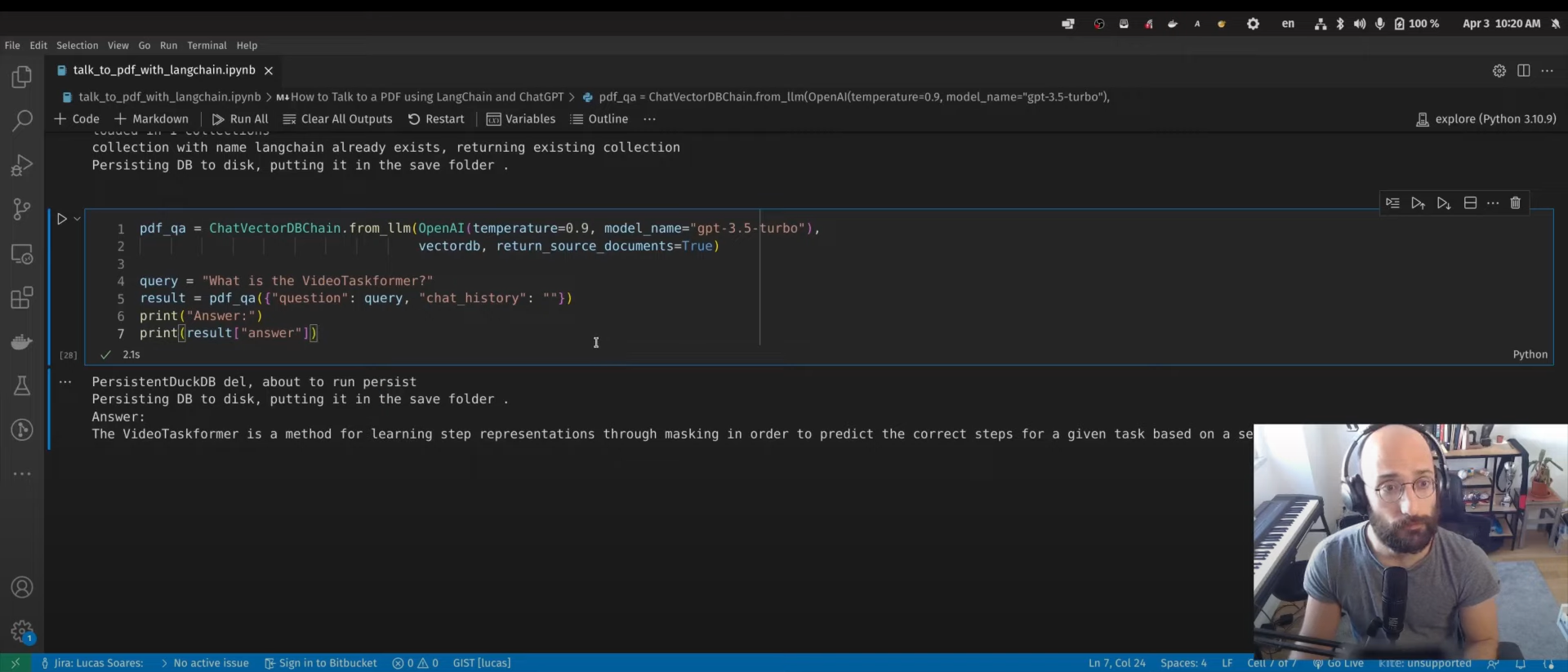
Wir verwenden die ChatVectorDBChain Klasse, um mit ChatGPT zu interagieren, indem wir eine generierte Vektordatenbank verwenden.
from langchain.chains import ChatVectorDBChain
from langchain.llms import OpenAI
pdf_qa = ChatVectorDBChain.from_llm(
OpenAI(temperature=0.9, model_name="gpt-3.5-turbo"),
vectordb,
return_source_documents=True,
)
query = "What is the VideoTaskformer?"
result = pdf_qa({"question": query, "chat_history": ""})
print("Answer:")
print(result["answer"])Der nächste Schritt wird in dem Video-Tutorial nicht erwähnt. Du kannst das Gradio-Framework nutzen, um eine Web-App zu erstellen und sie mit deinen Kollegen und Freunden zu teilen.
Ressourcen:
- Youtube Tutorial: Wie man mit LangChain und ChatGPT mit einer PDF-Datei spricht
- Blog mit Code Source: Automatisierte PDF-Interaktion mit LangChain und ChatGPT
- Sieh dir das auch an: Sprich mit deinem CSV & Excel mit LangChain
4. Bing-GPT Sprachassistent
Baue deinen eigenen KI-gesteuerten persönlichen Assistenten, genau wie J.A.R.V.I.S. Dafür brauchst du die OpenAI API, die Text-to-Speech-Bibliothek, die Spracherkennungsbibliothek und die generative KI.
Nachdem du die erforderlichen Bibliotheken geladen hast, musst du den OpenAI API-Schlüssel angeben:
openai.api_key = "[paste your OpenAI API key here]"Weckwort
Erstelle eine Weckwortfunktion, um die KI zu aktivieren. In diesem Fall verwendet der Entwickler "'bing" oder "gpt".
Sprachsynthese
Die Sprachsynthesefunktion bietet Text-zu-Sprache-Inferenz. Du kannst auf Polly (Text-to-Speech) von boto3 zugreifen und den Ton mit pydub abspielen.
Transkription mit Whisper
Die Spracherkennung wird von openai/whisper übernommen. Du musst nur die API herausfinden, um sie zu deiner Anwendung hinzuzufügen.
ChatBot mit EdgeGPT
Am Ende wirst du acheong08/EdgeGPT und die OpenAI API verwenden, um einen Chatbot zu erstellen. Wenn der Nutzer das Signalwort "bing" benutzt, wird das EdgeGPT-Modell verwendet, ansonsten das ChatGPT-Modell.
Wenn du nach einer viel einfacheren Implementierung des Sprachassistenten suchst, schau dir OpenAI Whisper, ChatGPT, TTS und Gradio Web UI an.
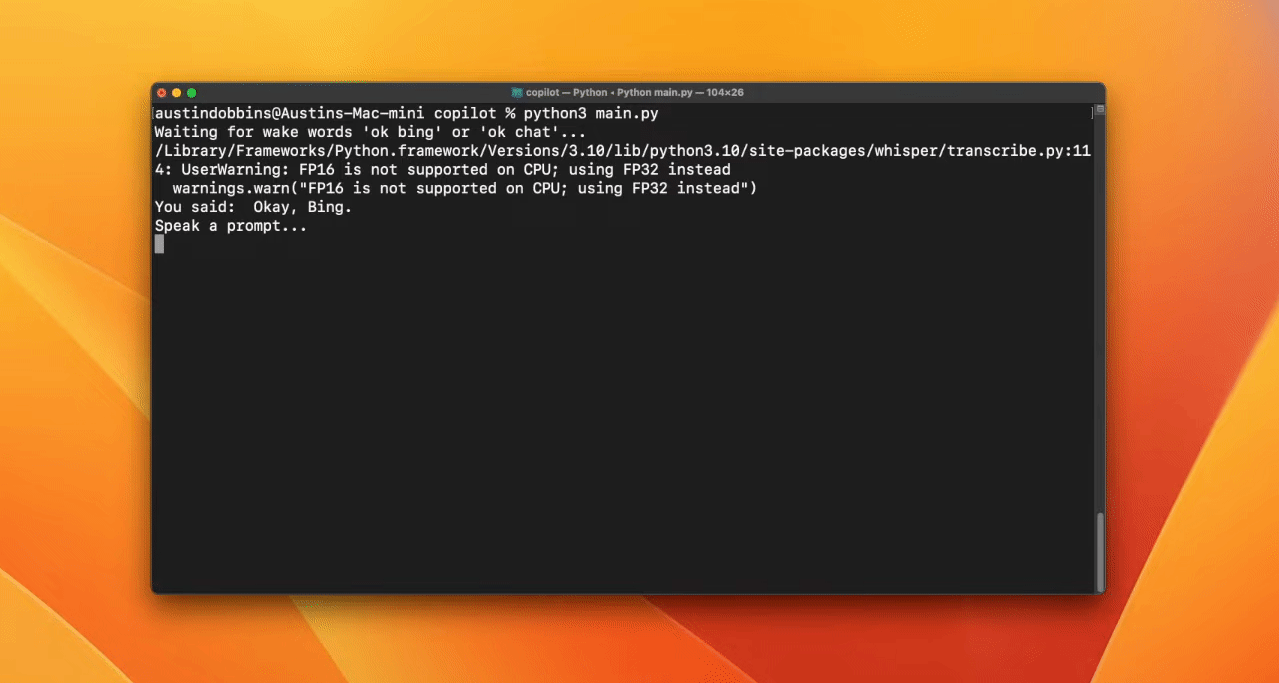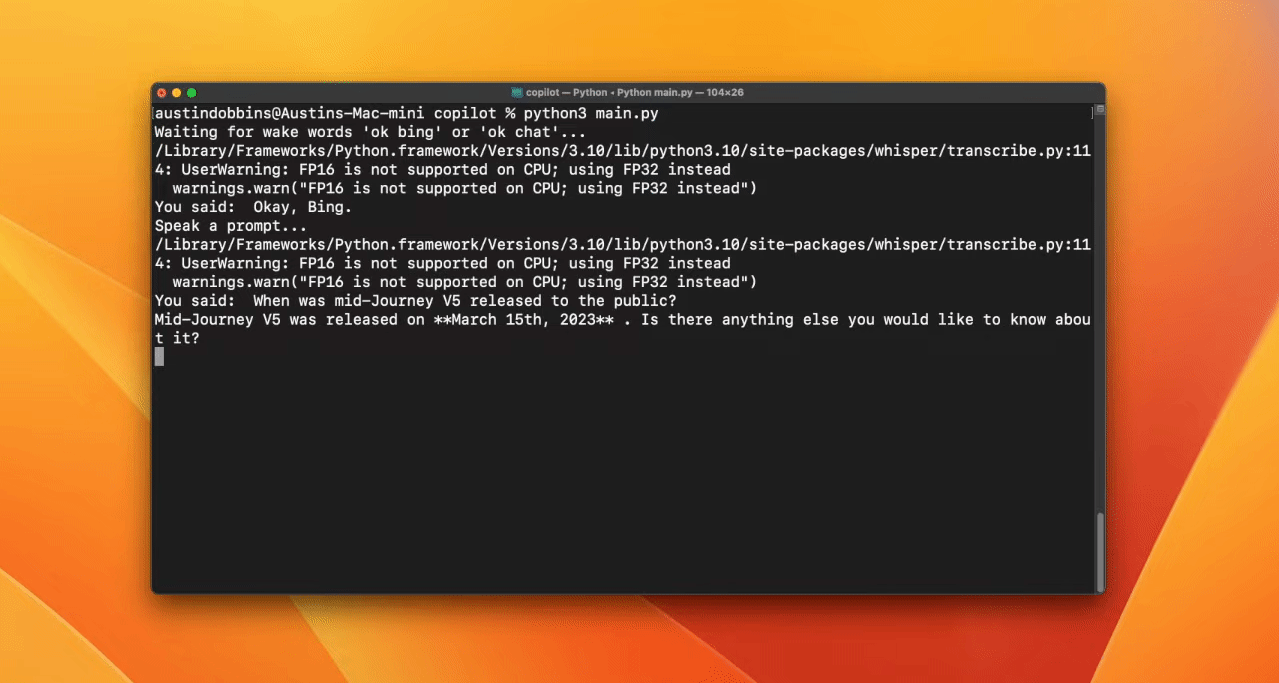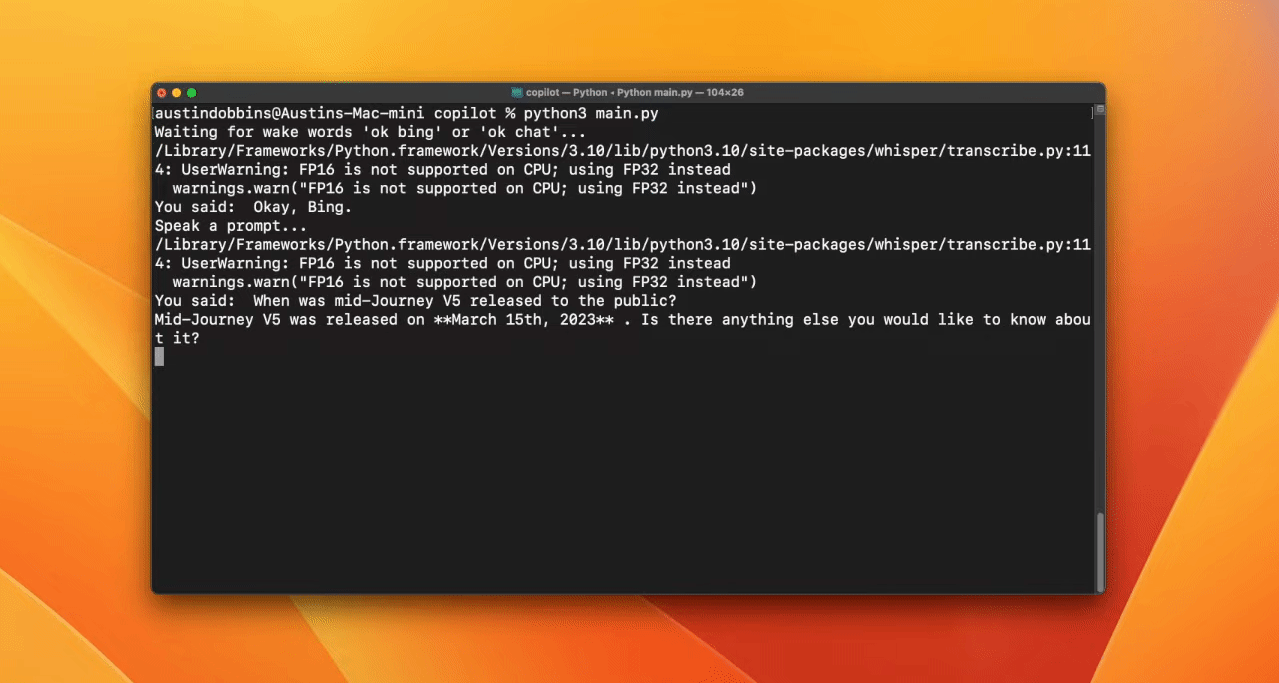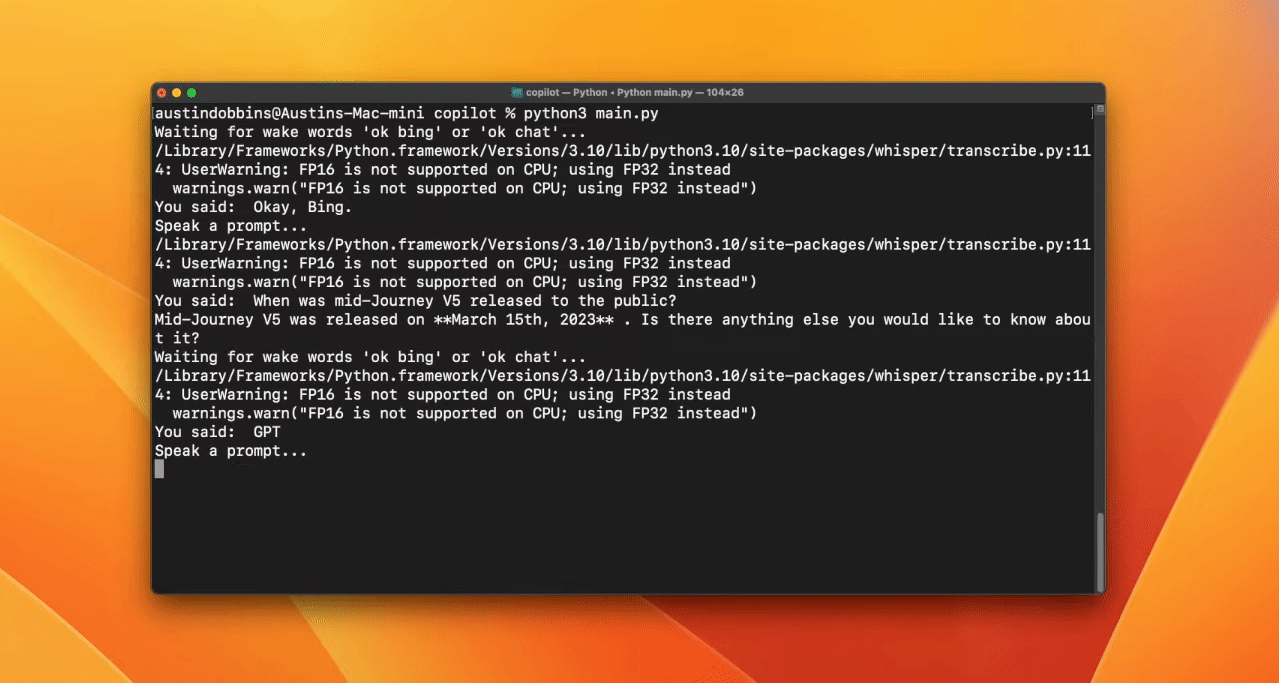
Ressourcen:
- Youtube Tutorial: Erstelle einen ChatGPT & Bing Sprachassistenten in 7 Minuten
- GitHub: Ai-Austin/Bing-GPT-Voice-Assistant
- Alternative Lösung: youtube-stuffs/voiceGPT.ipynb
5. Ein durchgängiges Data Science Projekt
In diesem Projekt werden wir ChatGPT verwenden, um an End-to-End-Klassifizierungsanwendungen für die Kreditvergabe zu arbeiten. Alles, was wir brauchen, ist Zugang zur ChatGPT-Schnittstelle und einen eigenen Rechner, auf dem wir den Code ausführen können.
Projektplanung
In der Planungsphase beschreiben wir den Datensatz und was wir von ihm wollen. Manchmal sind die Antworten nicht perfekt, aber du kannst die Antwort verbessern, indem du nachfragst.
Danach fangen wir an, den kurzen Plan zu befolgen.
Explorative Datenanalyse (EDA)
Wir werden ChatGPT bitten, Python-Code zu erzeugen, der den Datensatz lädt und eine explorative Datenanalyse mit verschiedenen Visualisierungstechniken durchführt. Du kannst ihn sogar bitten, die Ergebnisse zu interpretieren.
Feature Engineering
Wir haben ChatGPT gebeten, einen Feature-Engineering-Code zu schreiben, und erstaunlicherweise hat es zwei Features aus bestehenden Features erstellt. Das bedeutet, dass die KI den Datensatz jetzt vollständig versteht.
Vorverarbeitung und Abgleich der Daten
Wir haben einen unausgewogenen Datensatz, und in diesem Teil werden wir ChatGPT verwenden, um den Code für die Vorverarbeitung und das Klassengleichgewicht zu erstellen.
Modellauswahl
Wir haben ChatGPT gerade gebeten, den Code für die Modellauswahl zu schreiben, indem wir die Machine-Learning-Modelle angeben. Nachdem wir den Code ausgeführt haben, wählen wir das Modell aus, das am besten abschneidet.
Abstimmung der Hyperparameter und Modellbewertung
Um die Leistung zu verbessern, werden wir ChatGPT bitten, Python-Code für die Abstimmung der Hyperparameter und die Modellbewertung zu schreiben und das beste Modell zu speichern.
Erstellen einer Web-App mit Gradio
Wir werden ChatGPT bitten, mit dem gespeicherten Modell und dem Preprocessing Gradio-App-Code zu schreiben. Die KI verstand die eingegebenen Merkmale und die ausgegebenen Ergebnisse. Als Ergebnis haben wir eine voll funktionsfähige Web-App.
Bereitstellen der Web-App auf Spaces
Im letzten Schritt haben wir ChatGPT gebeten, eine Web-App auf dem Speicherplatz bereitzustellen. Es gibt ein paar Schritte, die wir befolgen und in wenigen Minuten umsetzen können.
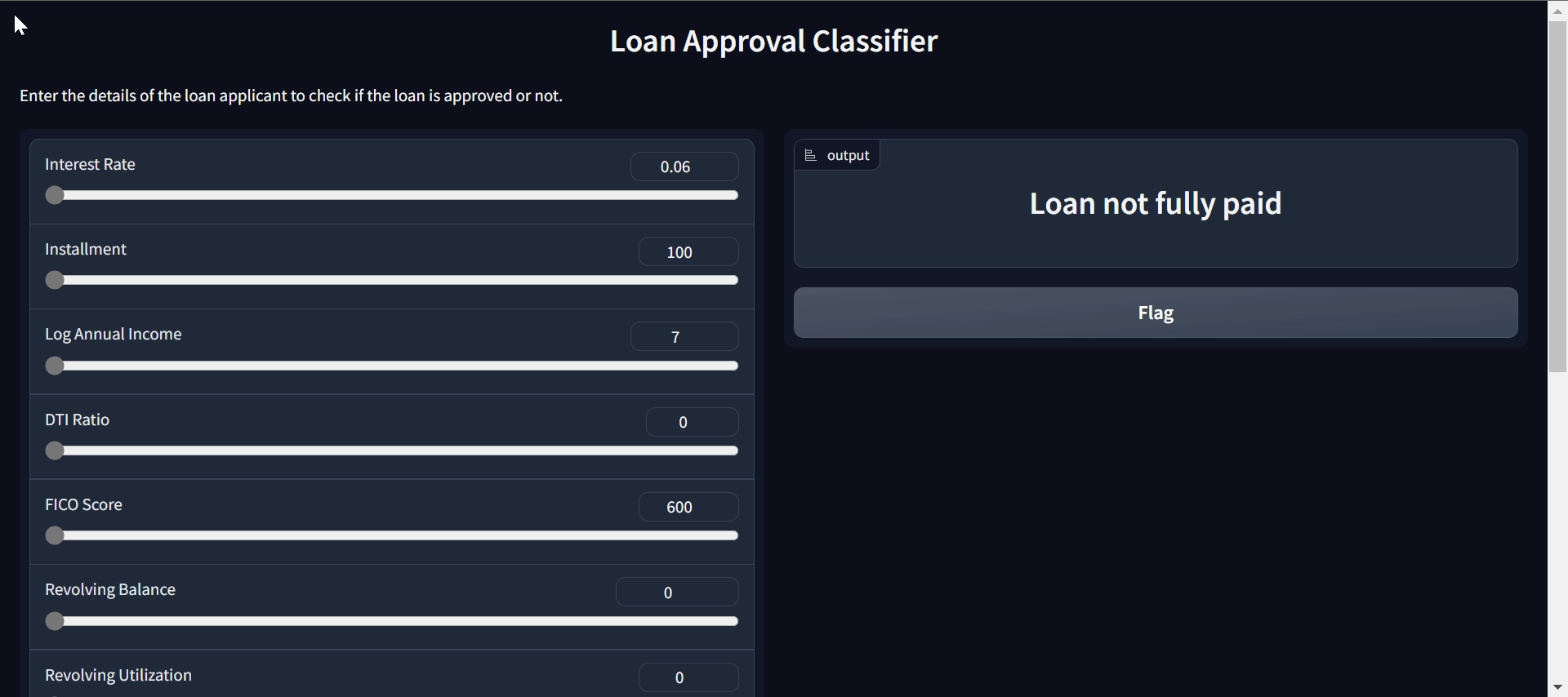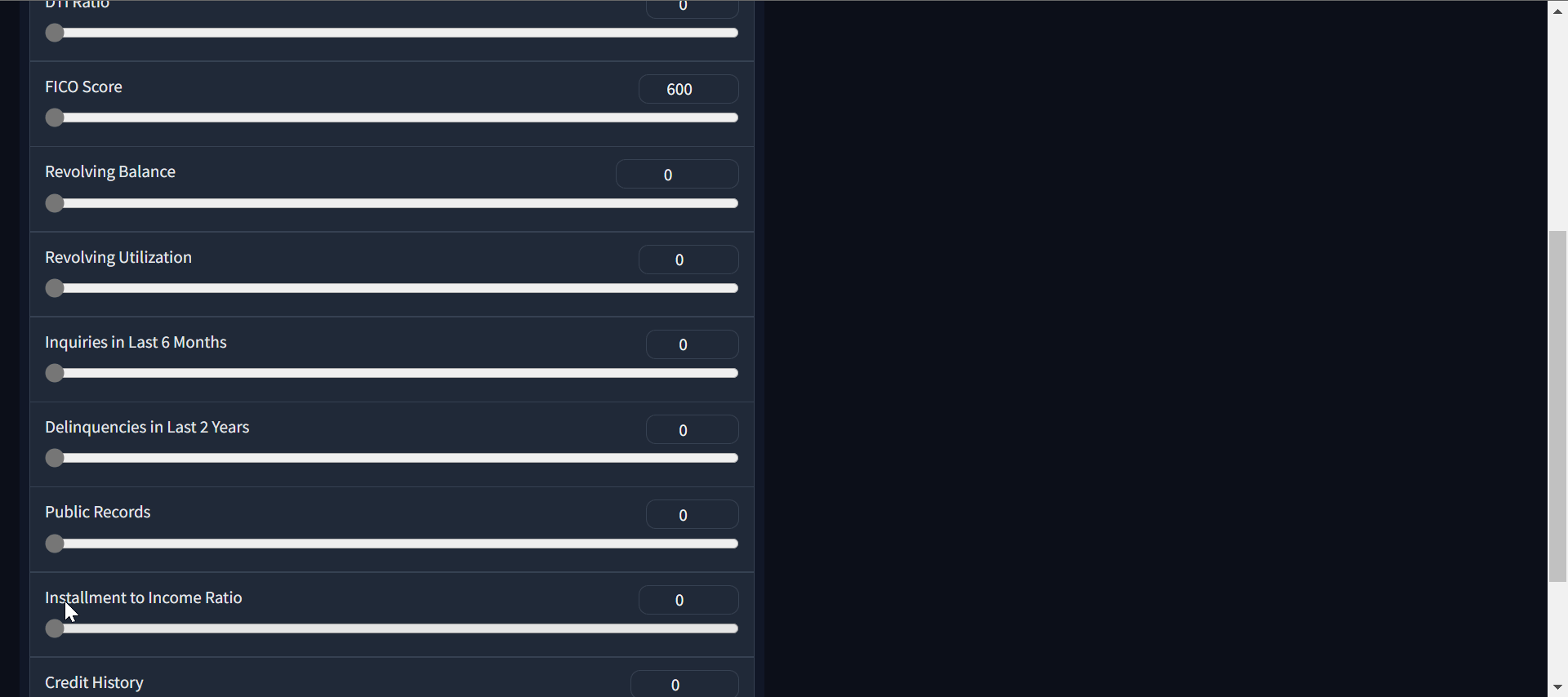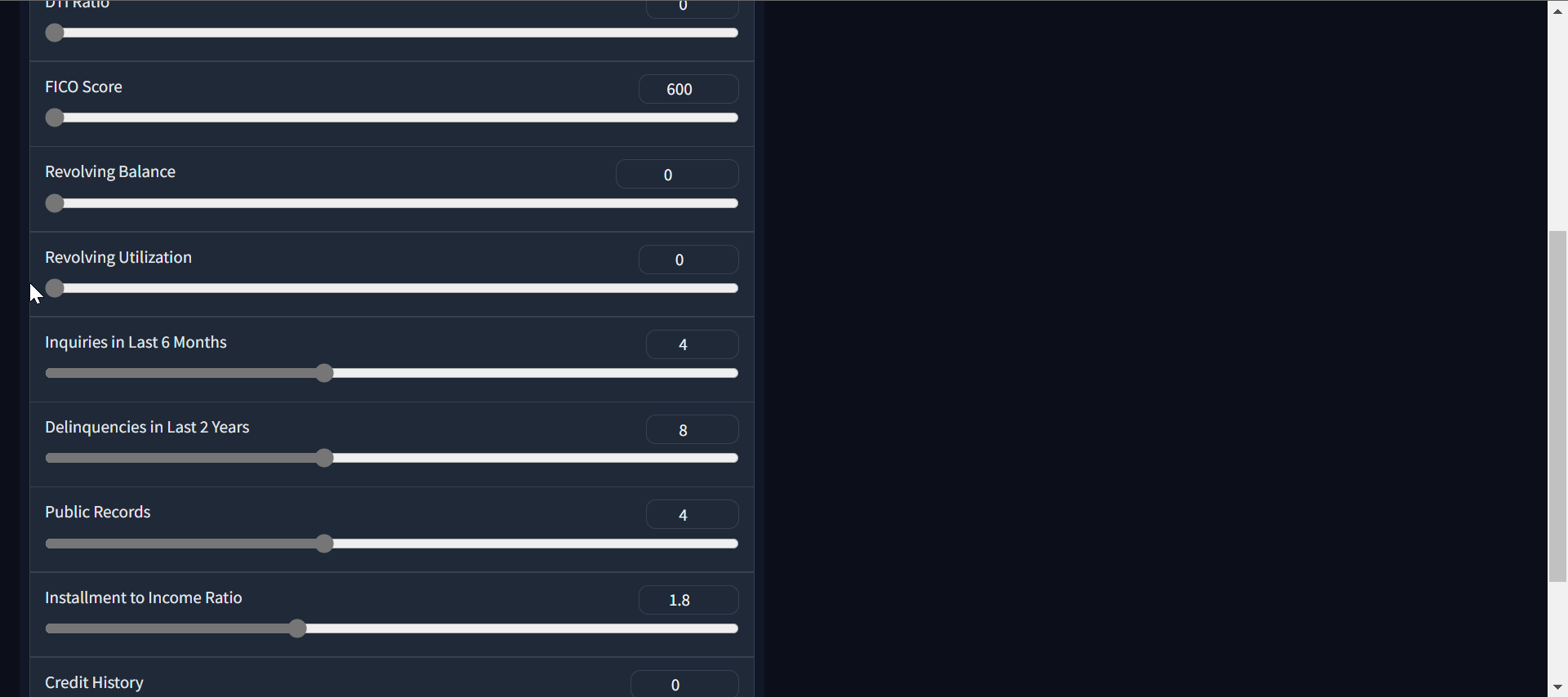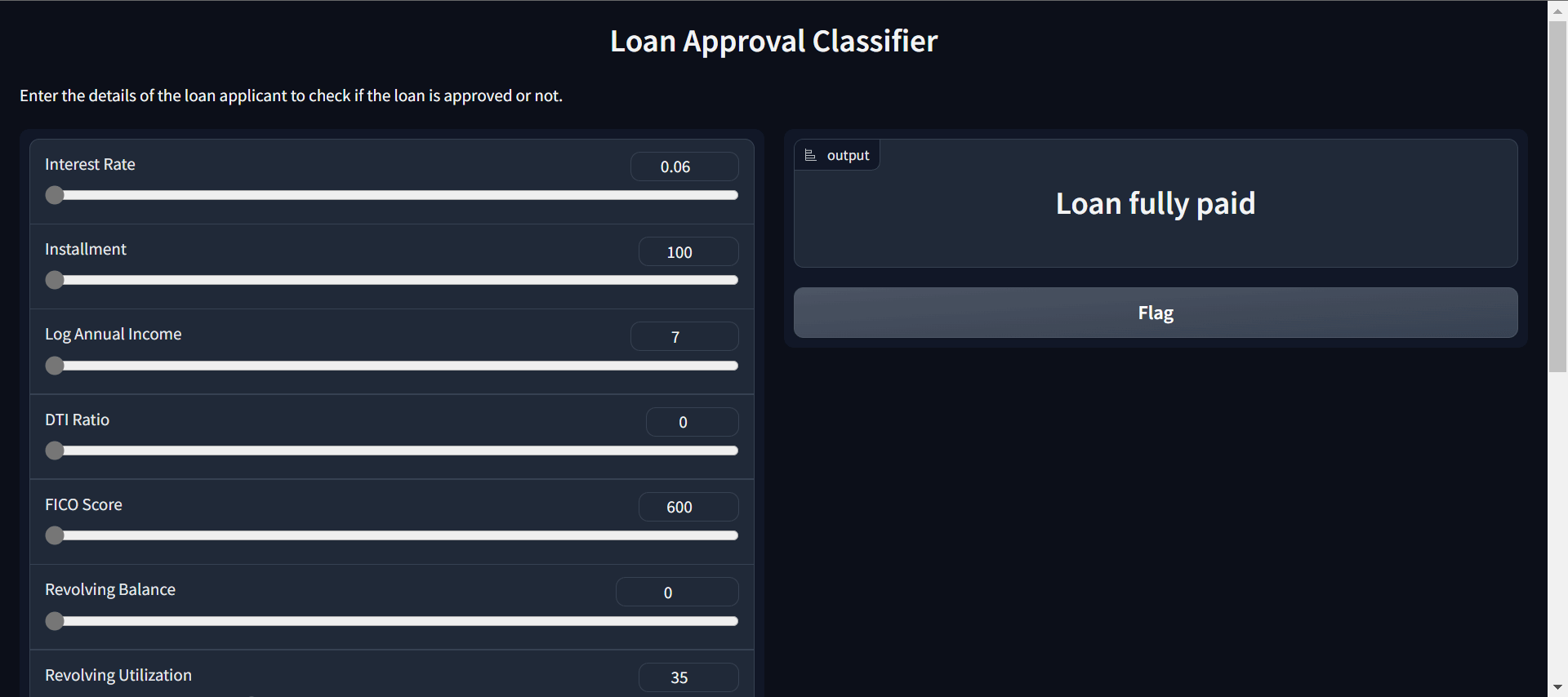
In diesem Projekt werden auch Tipps zum Schreiben von effektiven Prompts vermittelt, die für jeden Bereich wichtig sind.
Ressourcen:
- DataCamp Tutorial: Ein Leitfaden zur Verwendung von ChatGPT für Data Science-Projekte
- Umarmendes Gesicht Demo: Darlehensklassifikator
Fazit
Das ist nur ein Anfang von dem, was mit generativen KI-Modellen noch kommen wird. Die Open-Source-Community arbeitet hart an der Entwicklung von Tools, die dir helfen, jede Art von KI zu entwickeln. Mit diesen Tools kannst du sogar AGI (Artificial general AI) erstellen; sieh dir Auto-GPT (experimentelle Open-Source-Software zur Erstellung von völlig autonomen GPT-4) und babyagi (AI-powered task management system) an.
In diesem Beitrag haben wir uns mit den Projekten beschäftigt, die von allen Ebenen verstanden werden können und weniger Ressourcen benötigen, um loszulegen. Sie alle nutzen Open-Source-Tools, Modelle, Datensätze und Pakete, die für jeden zugänglich sind.
Wenn du neu bei ChatGPT bist, solltest du den Kurs "Einführung in ChatGPT " besuchen. Wenn du bereits mit generativer KI vertraut bist, kannst du deine Prompting-Fähigkeiten verbessern, indem du dir das umfassende ChatGPT Cheat Sheet for Data Science oder die folgenden Ressourcen ansiehst:
- In unserem Kurs "Einführung in ChatGPT" kannst du mit ChatGPT loslegen.
- Lade diesen praktischen Spickzettel mit ChatGPT-Aufforderungen für die Datenwissenschaft herunter.
- Hör dir diese Podcast-Episode zum Thema " Wie ChatGPT und GPT-3 die Arbeitsabläufe verbessern " an, um zu verstehen, wie ChatGPT deinem Unternehmen nutzen kann.
- Tutorial über die Whisper API
- Beginne KI zu lernen