
Kurs
Cloud Computing verstehen
2 Std.
234.6K
Bevor wir uns die Interviewfragen und -antworten anschauen, solltest du wissen, warum die AWS Cloud die wichtigste Plattform ist – das könnte auch eine Frage im Interview sein.
Schauen wir uns erstmal die folgende Grafik an:
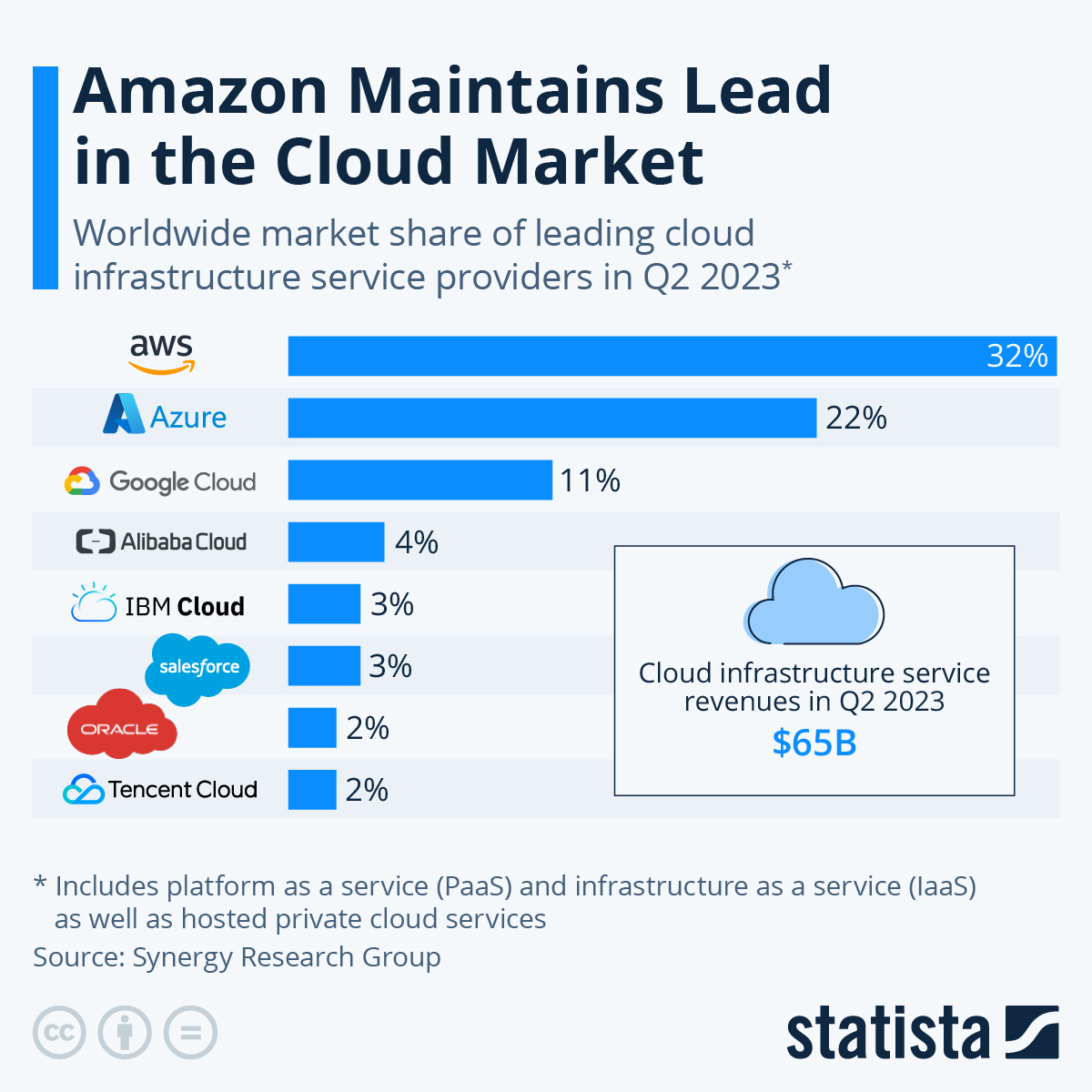
Quelle (Statista)
Die Grafik zeigt, wie stark AWS im zweiten Quartal 2023 auf dem globalen Markt für Cloud-Infrastrukturdienste ist. Mit einem Marktanteil von 32 % ist AWS klarer Marktführer und liegt weit vor seinem nächsten Konkurrenten, Microsoft Azure, der 22 % des Marktes hält. Auch andere große Anbieter wie Google Cloud (11 %) und Alibaba Cloud (4 %) sind auf dem Markt, aber ihre Marktanteile sind im Vergleich zu AWS und Azure eher gering.
Der Gesamtumsatz von Cloud-Infrastrukturdiensten im zweiten Quartal 2023, der sich auf 65 Milliarden US-Dollar belief, zeigt mal wieder, wie wichtig und finanziell bedeutend dieser Markt geworden ist. Die führende Position von AWS in diesem boomenden Bereich macht, wie wichtig es für Unternehmen ist, die nach zuverlässigen und skalierbaren Cloud-Lösungen suchen.
Wenn du mehr darüber erfahren möchtest, wie verschiedene Cloud-Anbieter im Vergleich abschneiden, schau dir diesen Spickzettel zum Vergleich der Dienste von AWS, Azure und GCP an.
Finanzielle Aspekte sind zwar wichtig, aber AWS ist nicht nur wegen seiner Marktanteile so attraktiv. Es bietet auch eine riesige Auswahl an Services, Zuverlässigkeit, Skalierbarkeit, globale Reichweite, robuste Sicherheit, ständige Innovation und eine hilfsbereite Community. Diese Faktoren zusammen machen AWS-Kenntnisse zu einer super gefragten Fähigkeit in der Tech-Branche und bieten viele Karrieremöglichkeiten für Leute, die sich mit dieser führenden Cloud-Plattform auskennen.
Schauen wir uns mal ein paar Interviewfragen an!
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Lerne mit diesen Kursen mehr über AWS!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Tutorial
Mark Pedigo
Tutorial
Javier Canales Luna
