
Cours
Comprendre le cloud
2 h
234.6K
Avant d'examiner les questions et réponses de l'entretien, il est important de comprendre pourquoi le cloud AWS est la principale plateforme de référence. Cela pourrait constituer une question à part entière lors de l'entretien.
Commençons par examiner le graphique suivant :
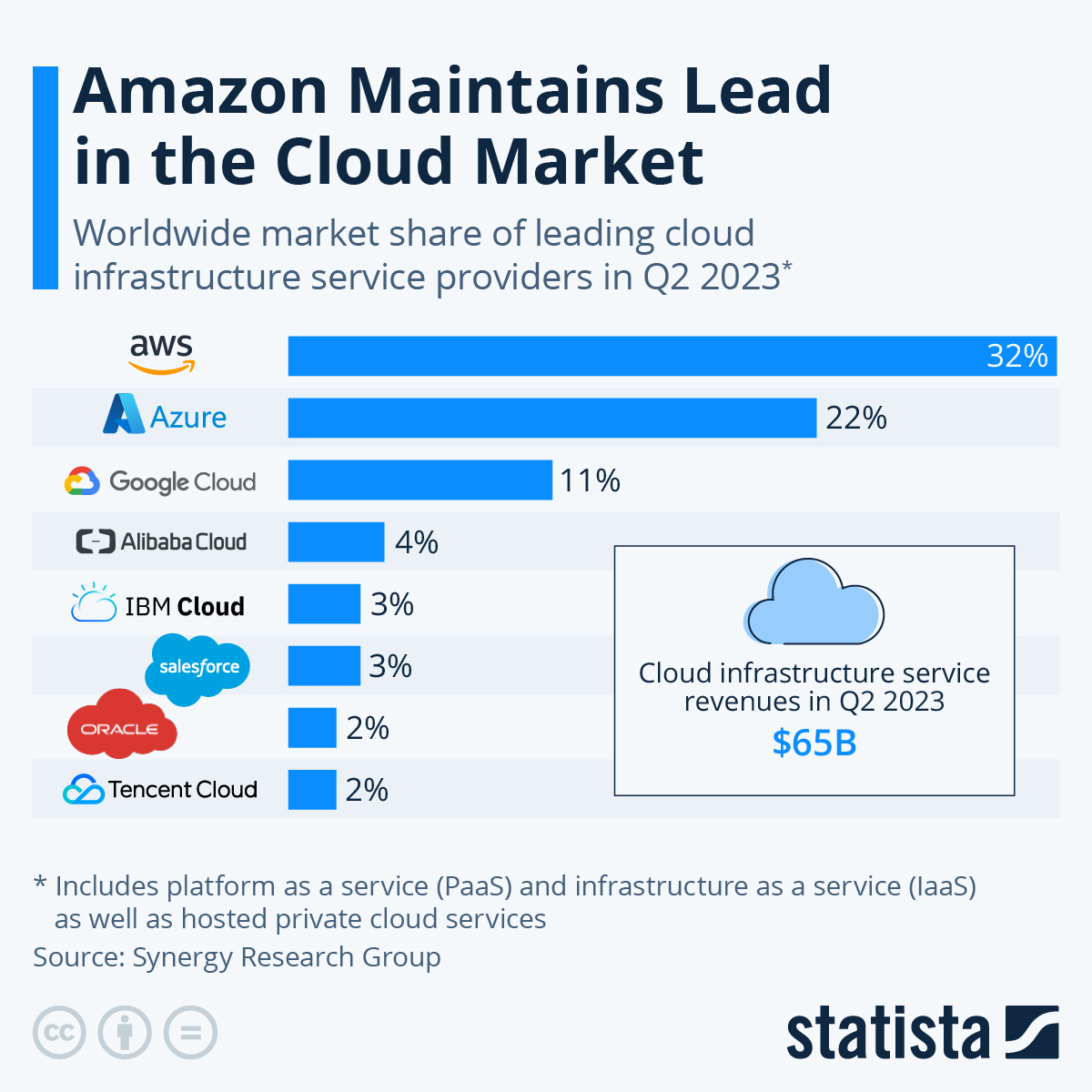
Source (Statista)
Le graphique illustre la position dominante d'AWS sur le marché mondial des services d'infrastructure cloud au deuxième trimestre 2023. Avec une part de marché de 32 %, AWS est clairement en tête, loin devant son concurrent le plus proche, Microsoft Azure, qui détient 22 % du marché. Bien que d'autres acteurs majeurs tels que Google Cloud (11 %) et Alibaba Cloud (4 %) contribuent au marché, leurs parts sont insignifiantes par rapport à celles d'AWS et d'Azure.
Le chiffre d'affaires total généré par les services d'infrastructure cloud au deuxième trimestre 2023, qui s'élève à 65 milliards de dollars, souligne encore davantage l'importance croissante et la signification financière de ce marché. La position dominante d'AWS dans ce secteur en pleine expansion renforce son importance stratégique pour les entreprises à la recherche de solutions cloud fiables et évolutives.
Si vous souhaitez en savoir plus sur les différences entre les différents fournisseurs de services cloud, veuillez consulter cette fiche comparative des services AWS, Azure et GCP.
Bien que les aspects financiers soient importants, l'attrait d'AWS va au-delà de sa part de marché et englobe une vaste sélection de services, la fiabilité, l'évolutivité, la portée mondiale, une sécurité robuste, l'innovation continue et une communauté solidaire. Ces facteurs combinés font de l'expertise AWS une compétence très recherchée dans le secteur technologique, offrant de nombreuses opportunités de carrière à ceux qui maîtrisent cette plateforme cloud de premier plan.
Examinons quelques questions d'entretien.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Veuillez approfondir vos connaissances sur AWS grâce à ces cours.
Cours
Cours
Cours