Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
Die Auswahl der Datenbank ist bei der Entwicklung von Data Science und Anwendungen von entscheidender Bedeutung, da sie sich direkt auf die Leistung, Skalierbarkeit und die Fähigkeit auswirkt, die Daten zu verarbeiten, die für die Anwendung verwendet werden. Die Wahl zwischen NoSQL und SQL-Datenbanken wirken sich auf die Effizienz der Datenabfrage, -speicherung und -verarbeitung aus, was für den Erfolg und die Reaktionsfähigkeit datengesteuerter Anwendungen bei der Erfüllung bestimmter Anforderungen entscheidend ist.
SQL und NoSQL sind zwei unterschiedliche Datenbanktechnologien, wobei SQL-Datenbanken den Schwerpunkt auf strukturierte, relationale Modelle legen und NoSQL-Datenbanken einen flexiblen, schemalosen Ansatz für den Umgang mit vielfältigen und dynamischen Daten verfolgen, bei dem Skalierbarkeit und Geschwindigkeit im Vordergrund stehen.
In diesem Artikel werden die Unterschiede zwischen den beiden Datenbanksystemen erläutert. Wir werden jedoch nicht auf die Grundlagen von beiden eingehen. In unserem Lernpfad zu den SQL-Grundlagen erfährst du, wie du auf Daten aus SQL-Datenbanken zugreifen kannst.
1970 wurde das relationale Modell für Datenbanken, ein Modell zur effektiven Organisation und Speicherung von Daten in Tabellen mit einer Spalten- und Zeilenstruktur, von Dr. Edgar Codd in seinem bahnbrechenden Werk "A Relational Model of Data for Large Shared Data Banks". 1974 entwickelte IBM das System R, das erste Projekt zur Umsetzung des relationalen Modells für die Datenspeicherung, und sie entwickelten SQL als Sprache für die Interaktion mit diesen relationalen Datenbanken.
Im Laufe der Jahre wurden neue Standards für SQL entwickelt, und Oracle, IBM und Microsoft haben jeweils relationale Datenbankmanagementsysteme (RDBMS) für die effiziente, sichere und bequeme Nutzung von SQL zur Interaktion mit SQL-Datenbanken entwickelt.
Dann begannen Open-Source-Sprachen wie MySQL, SQL und relationale Datenbanken für die breite Bevölkerung zugänglicher zu machen. SQL ist jetzt sowohl auf physischen als auch auf Cloud-Systemen wie AWS, Azure und Google Cloud weithin zugänglich.
In SQL-Datenbanken dient das relationale Modell als konzeptionelle Grundlage, um Daten in strukturierten und miteinander verbundenen Tabellen zu organisieren. SQL-Datenbanken setzen sich aus Schemata und Tabellen zusammen:
Das relationale Modell erzwingt die Konsistenz durch zwei Arten von Schlüsseln: (1) Primärschlüssel, die jeden Datensatz eindeutig identifizieren, und (2) Fremdschlüssel, die Beziehungen zwischen Tabellen herstellen. Mehr über relationale Datenbanken erfährst du in unserem Kurs Einführung in SQL.
SQL (Structured Query Language) dient als Schnittstelle für die Verwaltung dieser Datenbanken und ermöglicht das Erstellen, Abrufen, Aktualisieren und Löschen von Daten durch standardisierte Befehle. Eine Liste dieser Befehle und der Möglichkeiten von SQL findest du in unserem Spickzettel zu den SQL-Grundlagen. Dieses Modell und seine Komponenten bieten einen leistungsstarken und flexiblen Rahmen für die Organisation und Abfrage von Daten in einer Weise, die die Integrität und Kohärenz der gesamten Datenbank gewährleistet.

Ein Blick auf unseren SQL-Grundlagen-Spickzettel
SQL bietet einen Standardbefehlssatz zum Definieren, Abfragen, Aktualisieren und Verwalten von Daten in einem relationalen Datenbankmanagementsystem (RDBMS). Zu den wichtigsten SQL-Operationen gehören SELECT (Abfrage von Daten), INSERT (Hinzufügen neuer Datensätze), UPDATE (Ändern bestehender Datensätze) und DELETE (Löschen von Datensätzen).
Wenn du diese Befehle verwendest, stellt SQL sicher, dass die ACID-Eigenschaften (Atomicity, Consistency, Isolation, and Durability) erhalten bleiben. Dies gewährleistet die Zuverlässigkeit und Konsistenz von Datenbankänderungen.
Diese grundlegenden Eigenschaften von SQL-Datenbanken sorgen dafür, dass Datenbanksysteme auch bei unerwarteten Ereignissen oder Systemausfällen zuverlässig und konsistent sind.
Es gibt drei gebräuchliche RDBMS:
In unserem Tutorial zu MySQL in Python erfährst du mehr über die ersten Schritte mit diesem RDBMS, ebenso wie in unserem Einsteigerhandbuch zu PostgreSQL.
In unserem Leitfaden " Was ist NoSQL?" erfährst du alles über Not Only SQL-Datenbanken. Im Folgenden haben wir unsere Ergebnisse zusammengefasst.
NoSQL-Datenbanken(Not Only SQL) wurden als Antwort auf die Herausforderungen durch die Zunahme von Big Data und den steigenden Bedarf an Skalierbarkeit in Datenbanksystemen entwickelt. Herkömmliche relationale Datenbanken haben Schwierigkeiten, die riesigen Mengen an unstrukturierten und halbstrukturierten Daten, wie sie in modernen Big Data vorkommen, effizient zu verwalten. NoSQL-Datenbanken sind eine flexiblere und skalierbarere Alternative zu relationalen Datenbanken.
Sie können verschiedene Datentypen effektiv verarbeiten, ein schnelles Datenwachstum bewältigen und Daten effizient auf mehrere Server verteilen.
NoSQL-Lösungen wie MongoDB, Cassandra und Couchbase verwenden nicht die gleichen starren Strukturen, die das relationale Modell unterstützt. Diese Systeme begünstigen die Schema-Flexibilität und die horizontale Skalierung, so dass sich Unternehmen an die Dynamik von Big Data anpassen können und gleichzeitig die Leistung und Zuverlässigkeit erhalten bleibt. Der Zusammenhang zwischen NoSQL, Big Data und Skalierbarkeit unterstreicht eine entscheidende Entwicklung im Datenbankmanagement, die es Unternehmen ermöglicht, die Herausforderungen des exponentiellen Datenwachstums zu bewältigen.
Im Gegensatz zu SQL-Datenbanken verwenden NoSQL-Datenbanken dynamische Schemata und unterstützen verschiedene Datenmodelle, um unterschiedliche Anwendungsanforderungen zu erfüllen.
Ein charakteristisches Merkmal von nicht-relationalen Datenbanken ist die Verwendung dynamischer Schemata. Im Gegensatz zu den vordefinierten, festen Schemata von relationalen Datenbanken bieten nicht-relationale Datenbanken Flexibilität. Verschiedene Datensätze in derselben Datenbank können unterschiedliche Felder haben. In einer Kundendatenbank kann ein Kunde zum Beispiel ein Feld für Name und Alter haben, während der andere ein Feld für Name und E-Mail hat.
Es gibt verschiedene Arten von NoSQL-Datenbanken:
Mehr über MongoDB erfährst du in unserem Kurs Einführung in MongoDB in Python.
Die Entscheidung für eine der beiden Varianten hängt von der Anwendung ab, für die du eine NoSQL-Datenbank verwenden möchtest.
NoSQL-Datenbanken bieten eine Reihe von Vorteilen, vor allem in Bezug auf Skalierbarkeit, Flexibilität und Leistung beim Umgang mit unstrukturierten Daten.
NoSQL-Datenbanken bieten Skalierbarkeit in Form von horizontaler Skalierbarkeit und Elastizität. Sie sind so konzipiert, dass sie horizontal skaliert werden können. So können Unternehmen wachsende Datenmengen verarbeiten, indem sie weitere Server zu einem verteilten System hinzufügen. Dadurch eignen sie sich gut für Anwendungen mit wachsenden oder unvorhersehbaren Arbeitslasten.
Viele NoSQL-Datenbanken bieten auch automatisches Sharding und Load Balancing, d.h. die Verteilung der Daten auf mehrere Knotenpunkte, um eine effiziente Ressourcennutzung und eine bessere Leistung zu gewährleisten. Diese Fähigkeit ermöglicht es den Systemen, sich je nach Bedarf dynamisch zu vergrößern oder zu verkleinern und wird als Elastizität bezeichnet.
Außerdem bieten sie Schema-Flexibilität. NoSQL-Datenbanken verwenden dynamische Schemata, die eine flexible Datendarstellung ermöglichen. Das bedeutet, dass die Felder in einem Datensatz in verschiedenen Dokumenten variieren können, um die vielfältigen und sich entwickelnden Datenstrukturen, die in modernen Anwendungen üblich sind, zu berücksichtigen.
Sie sind auch für unstrukturierte und halbstrukturierte Datentypen wie JSON und XML gut geeignet. Heutzutage sind Daten oft unvorhersehbar, vor allem wenn sie von Nutzern erzeugt werden, und NoSQL kann diese Daten gut speichern.
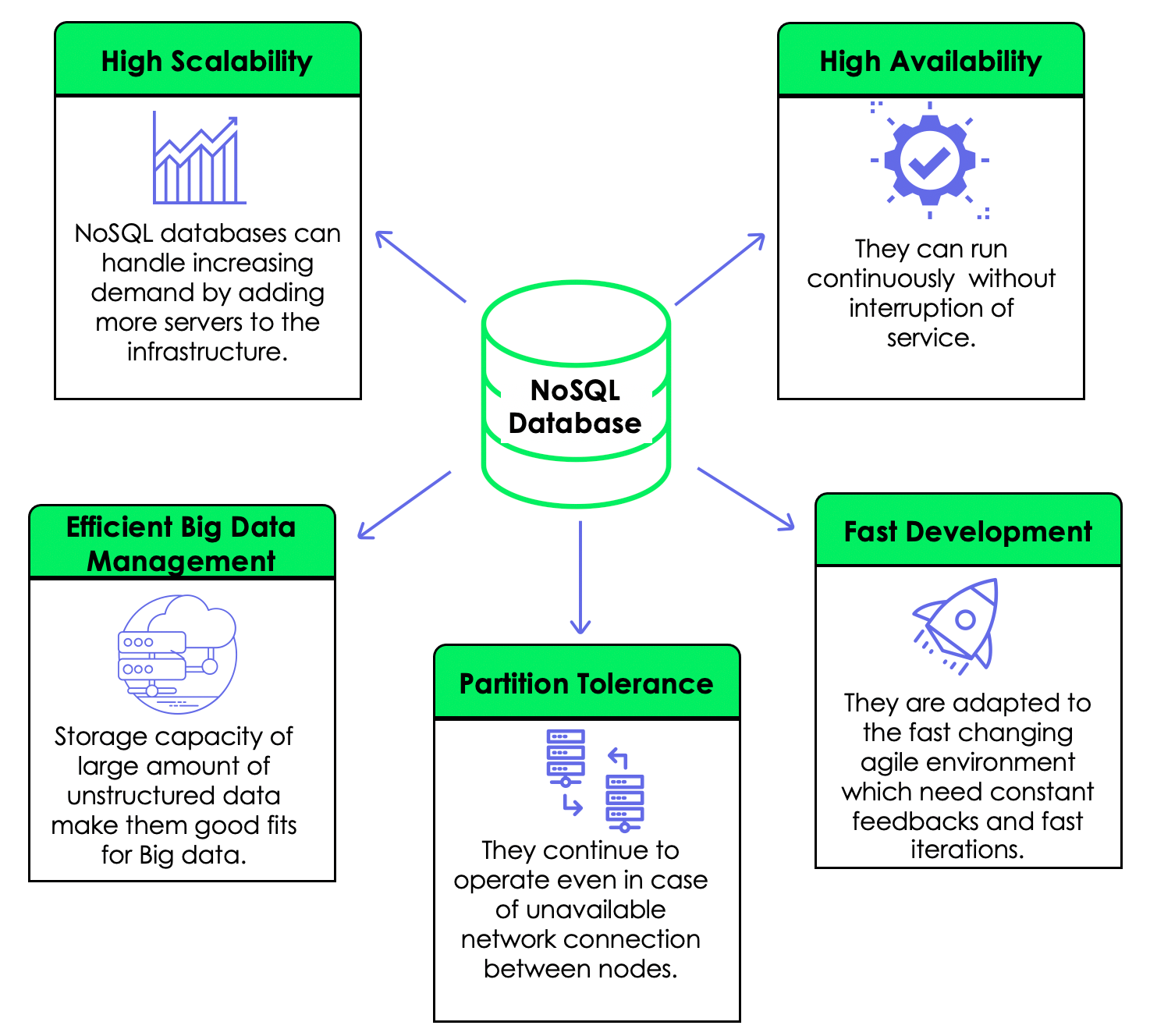
Die Vorteile von NoSQL aus unserem Artikel
Einige der am häufigsten verwendeten NoSQL-Datenbanksysteme sind:
Vergleichen wir SQL und NoSQL, um ein besseres Verständnis dafür zu bekommen, wo sich die beiden überschneiden und wo sie sich unterscheiden:
SQL-Datenbanken, die sich durch strukturierte Datenmodelle auszeichnen, erzwingen ein vordefiniertes Schema, in dem Daten in Tabellen mit bestimmten Spalten und Datentypen passen müssen. Diese starre Struktur sorgt für Konsistenz und eignet sich gut für Anwendungen mit stabilen und vorhersehbaren Datenanforderungen.
Im Gegensatz dazu verwenden NoSQL-Datenbanken flexible Datenmodelle, die eine dynamische und schemalose Datenspeicherung ermöglichen. Diese Flexibilität ermöglicht es Entwicklern, Daten ohne ein vordefiniertes Schema einzufügen. NoSQL-Datenbanken sind vor allem in Szenarien nützlich, in denen die Datenstrukturen undefiniert sind oder sich häufig ändern.
SQL- und NoSQL-Server sind aufgrund ihrer Bauweise unterschiedlich stark skalierbar. SQL-Systeme basieren in der Regel auf einer vertikalen Skalierung, bei der derselbe Server verbessert und mit zusätzlichen Ressourcen ausgestattet wird, um eine höhere Last zu bewältigen. Die horizontale Skalierung, die typischerweise in NoSQL-Systemen zu finden ist, wird durch das Hinzufügen weiterer Server oder Knoten zu einem verteilten System erreicht, wodurch die Kapazität erhöht wird.
In NoSQL-Systemen kommunizieren die Knoten miteinander und verteilen die Last, sodass das Hinzufügen weiterer Knoten die Gesamtkapazität des Systems erhöht. Dies ist eine skalierbare und kosteneffiziente Lösung für die Verwaltung einer wachsenden Datenbank und eines erhöhten Datenbankverkehrs.
SQL-Datenbanken verwenden vordefinierte Schemata, die eine starre Struktur für die Datenorganisation erzwingen und von den Tabellen verlangen, dass sie sich an eine vordefinierte Struktur von Zeilen und Spalten halten. Im Gegensatz dazu bieten NoSQL-Datenbanken dynamische Schemata und damit Flexibilität bei der Datendarstellung. Diese Datenbanken ermöglichen das Einfügen von Daten ohne vordefinierte Struktur, so dass die Entwickler die Schemata im Handumdrehen anpassen können.
Diese Flexibilität ist besonders vorteilhaft für den Umgang mit verschiedenen, sich entwickelnden und unvorhersehbaren Datentypen. NoSQL-Datenbanken eignen sich daher gut für Szenarien, in denen die Datenstrukturen im Voraus nicht vollständig bekannt sind oder sich häufig ändern, während SQL-Datenbanken gut funktionieren, wenn die Daten gut strukturiert und vorhersehbar sind.
SQL- und NoSQL-Datenbankmanagementsysteme verfolgen unterschiedliche Ansätze zur Gewährleistung der Zuverlässigkeit. SQL basiert auf den ACID-Eigenschaften (Atomicity, Consistency, Isolation, Durability), die, wie bereits erwähnt, die sofortige und strikte Konsistenz in der Datenbank sicherstellen. SQL-Abfragen garantieren, dass entweder alle oder keine der Änderungen, die während einer Transaktion vorgenommen werden, in die Datenbank übertragen werden und haben Regeln für den Umgang mit gleichzeitigen Transaktionen und unerwarteten Ereignissen.
NoSQL-Datenbanken hingegen, bei denen Skalierbarkeit und verteilte Architekturen im Vordergrund stehen, verwenden das Konzept der eventuellen Konsistenz. Eventuelle Konsistenz erkennt an, dass es in einem verteilten System einige Zeit dauern kann, bis alle Knoten nach einer Aktualisierung zu einem konsistenten Zustand konvergieren. NoSQL-Datenbanken opfern zwar die unmittelbare Konsistenz zugunsten von Skalierbarkeit und Fehlertoleranz, aber sie stellen sicher, dass alle Replikate der Daten mit der Zeit denselben Zustand erreichen werden.
Dieser Kompromiss ermöglicht es NoSQL-Systemen, mit großen, verteilten Umgebungen umzugehen, in denen die Konsistenz in Echtzeit nur schwer zu erreichen ist.
Wenn du dir unsicher bist, welche Datenbank du verwenden sollst, haben wir dir einige Möglichkeiten aufgezeigt, wie du zwischen NoSQL und SQL wählen kannst:
SQL-Datenbanken eignen sich am besten für Szenarien, in denen Daten strukturiert und vorhersehbar sind, komplexe Beziehungen genau erfasst werden müssen und sofortige Datenintegrität wichtig ist.
Die starren Strukturen und ACID-Eigenschaften von SQL eignen sich gut für diese Art von Anwendungen.
Einige häufige Anwendungsfälle, in denen SQL-Datenbanken gut funktionieren, sind:
NoSQL-Datenbanken eignen sich am besten, wenn es sinnvoll ist, flexible Datenstrukturen zu haben, die sich dynamisch an neue Informationen und Schemata anpassen können, wenn Skalierbarkeit und Leistung wichtig sind, und für unstrukturierte Daten. Die dynamischen Schemata und die horizontale Skalierung von NoSQL eignen sich hervorragend für diese Art von Anwendungsfällen, die in Szenarien wie diesen auftreten:
Ein paar Beispiele für Branchen, die auf SQL-Datenbanken angewiesen sind, sind:
Ein paar Beispiele für Branchen, die auf NoSQL-Datenbanken setzen, sind:
Die Wahl zwischen SQL- und NoSQL-Datenbanken spielt eine entscheidende Rolle für die Effektivität und den Erfolg von Data Science und Anwendungsentwicklung. Die Auswirkungen auf die Leistung, Skalierbarkeit und Anpassungsfähigkeit an Datentypen haben einen direkten Einfluss auf die Reaktionsfähigkeit von datengesteuerten Anwendungen.
SQL mit seinem strukturierten, relationalen Modell eignet sich besonders gut für Szenarien, in denen die Daten klar definiert sind und Beziehungen entscheidend sind, die durch ACID-Eigenschaften sofortige Konsistenz gewährleisten.
NoSQL-Datenbanken hingegen bieten Flexibilität und Skalierbarkeit und eignen sich für dynamische, unstrukturierte Datentypen, die in modernen Anwendungen häufig vorkommen.
Da sich die Industrien weiterentwickeln, wird das Verständnis der Nuancen zwischen diesen grundlegenden Datenbanktechnologien für Architekten und Entwickler, die sich in der vielfältigen Landschaft des Datenmanagements bewegen, immer wichtiger.
Wenn du mehr über die zugrundeliegende Sprache für den Zugriff auf Daten in relationalen Datenbanken erfahren möchtest, dann schau dir unseren SQL-Kurs für Fortgeschrittene an.
Beginne deine SQL-Reise noch heute!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
