Lernpfad
Associate Data Engineer in SQL
30 Std.
Vor ein paar Jahren, in meiner ersten Woche in einer neuen Funktion als Softwareentwickler, wurde ich gebeten, mich mit Zeitreihen-Datenbanken (TSDBs) um unsere Postgres-Lösung zu ersetzen.
Ich wusste absolut nichts über das Thema und hatte so viele Fragen. Was ist überhaupt eine Zeitreihen-Datenbank? Wie funktioniert das? Wie unterscheidet sie sich von einer herkömmlichen Datenbank? Warum sollten wir einen benutzen? Brauche ich dafür besondere Fähigkeiten?
Seitdem habe ich eine Menge über TSDBs gelernt und dieses Wissen in verschiedenen Unternehmen angewandt, um eine Vielzahl von Problemen zu lösen.
In diesem Artikel fasse ich zusammen, was ich in den letzten Jahren gelernt habe, um dir eine gute Vorstellung davon zu geben, was TSDBs sind, wie sie funktionieren und für welche Anwendungsfälle sie am besten geeignet sind. Außerdem stelle ich dir einige der TSDBs vor, die derzeit auf dem Markt sind, und gebe dir Tipps, damit du diejenige auswählen kannst, die deinen Bedürfnissen am besten entspricht.
Stell dir ein intelligentes Thermostat vor, das von Unternehmen X verkauft wird und alle 30 Sekunden die Temperaturwerte aufzeichnet. An einem einzigen Tag generiert dieses eine Gerät Tausende von Datenpunkten. Multipliziere das mit Hunderten oder Tausenden von Geräten in einer Stadt, und die Menge der von Unternehmen X gesammelten Zeitstempel-Daten wird atemberaubend.
Um diese Daten effizient zu speichern und Trends zu analysieren (z. B. Temperaturveränderungen im Laufe der Zeit oder plötzliche Spitzen), benötigt Unternehmen X eine Datenbank, die massive Schreibgeschwindigkeiten bewältigen und zeitbasierte Abfragen effizient durchführen kann.
Herkömmliche Datenbanken haben mit dieser Art von Arbeitsbelastung zu kämpfen, weil sie nicht dafür ausgelegt sind, hochfrequente Schreibvorgänge zu verarbeiten oder Daten effizient über bestimmte Zeiträume abzufragen. Hier kommen die Zeitreihen-Datenbanken ins Spiel.
Zeitreihendatenbanken sind spezialisierte Datenbanken zur Verwaltung von Daten, die nach Zeit organisiert und indiziert sind. Im Gegensatz zu herkömmlichen Datenbanken, die für die Speicherung von Allzweckdaten optimiert sind, konzentrieren sich TSDBs auf die effiziente Speicherung, Abfrage und Analyse von Sequenzen von Datenpunkten mit Zeitstempeln.
TSDBs eignen sich besonders für Anwendungen, die mit kontinuierlichen Datenströmen arbeiten, wie z.B. IoT, DevOps Monitoring und Finanzanalysen.
Es gibt ein paar Dinge, die TSDBs anders machen als traditionelle Datenbanken.
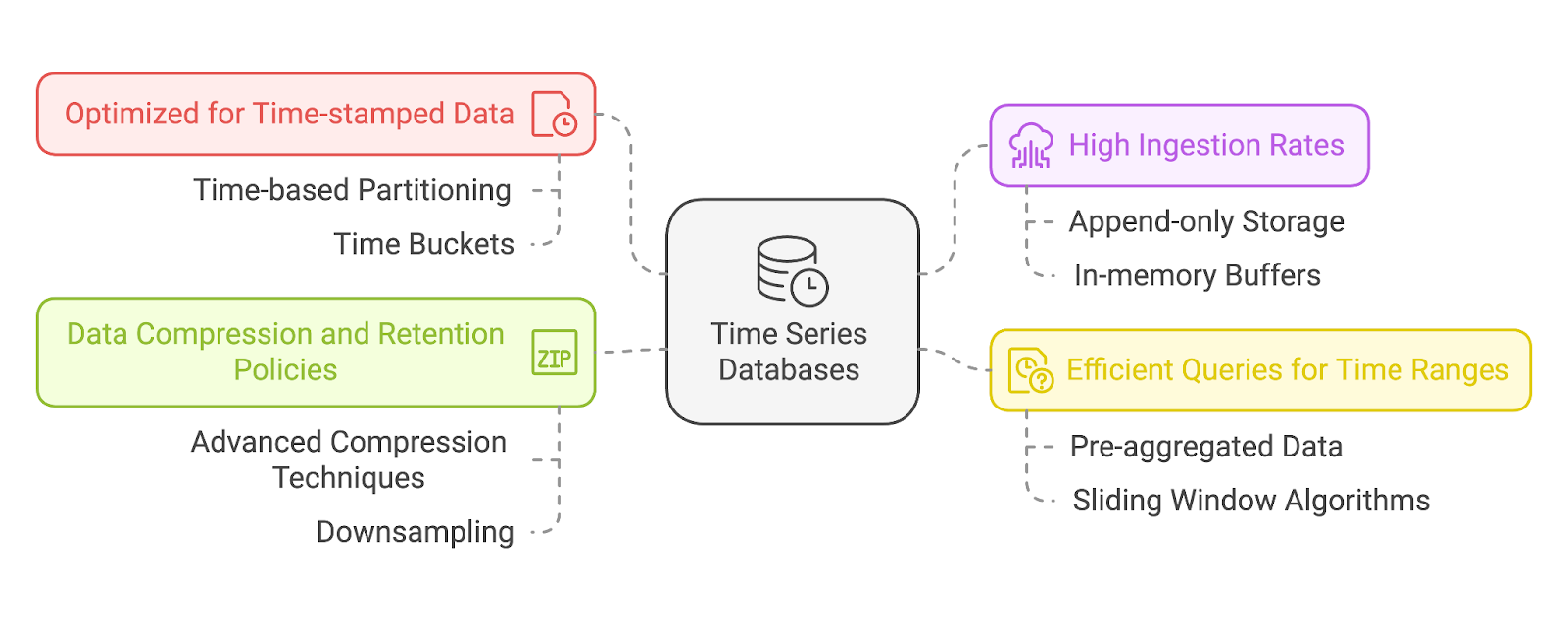
Im Kern sind TSDBs für die Verarbeitung von Daten mit Zeitstempeln als grundlegendem Attribut konzipiert. Jeder Datenpunkt in einer TSDB enthält einen Zeitstempel, der als Primärindex dient. So können diese Datenbanken zeitlich geordnete Sequenzen effizient speichern und abrufen und einen schnellen Zugriff auf historische Trends oder aktuelle Ereignisse ermöglichen.
Die meisten TSDBs verwenden eine zeitbasierte Partitionierung, d.h. die Daten werden in Partitionen gespeichert, die auf Zeitintervallen basieren (z.B. stündlich, täglich). Dies ermöglicht ein effizientes Pruning, bei dem die Abfragen irrelevante Partitionen komplett ignorieren.
Sie können auch implementieren Zeitabschnitteimplementieren, die Daten in vordefinierten Zeitfenstern (z. B. 1 Minute, 1 Stunde) gruppieren, um sie schneller zu aggregieren.
Zeitreihendaten werden oft in rasantem Tempo generiert - man denke nur an IoT-Geräte, die Tausende von Datenpunkten pro Sekunde senden, oder an ein Server-Überwachungstool, das Systemmetriken in Echtzeit erfasst. TSDBs sind für diese hohen Schreibraten optimiert und können große Datenmengen aufnehmen, ohne langsamer zu werden oder Informationen zu verlieren.
Dies wird in der Regel durch Append-Only-Datenspeichermodelle und In-Memory-Puffer erreicht, um Sperren oder transaktionale Engpässe zu vermeiden.
Bei der Analyse von Zeitreihendaten werden oft bestimmte Zeitintervalle oder Zeitfenster abgefragt, z. B. "letzte 24 Stunden" oder "dieses Jahr im Vergleich zum letzten Jahr". TSDBs werden mit diesem Ziel entwickelt und bieten spezielle Abfragefunktionen, mit denen die Nutzer schnell Daten über bestimmte Zeiträume abrufen können. Sie unterstützen auch Aggregationen wie Durchschnittswerte, Summen oder Trends und bieten so wertvolle Analysen ohne komplexe Abfragelogik.
Zu den Techniken zur Abfrageoptimierung gehören:
Um die riesigen Mengen an Zeitreihendaten zu verwalten, die im Laufe der Zeit entstehen, verwenden TSDBs fortschrittliche Datenkomprimierungstechniken. Diese Methoden reduzieren den Speicherbedarf bei gleichbleibender Abfrageleistung.
TSDBs enthalten in der Regel Aufbewahrungsrichtlinien, damit die Benutzer festlegen können, wie lange die Daten aufbewahrt werden sollen. So kann ein System zum Beispiel detaillierte Daten für den letzten Monat aufbewahren, während für ältere Datenein Downsampling durchführt. Downsampling ist der Prozess, bei dem die Granularität der Daten im Laufe der Zeit reduziert wird. Zum Beispiel:
Beispiele für fortschrittliche Komprimierungstechniken sind:
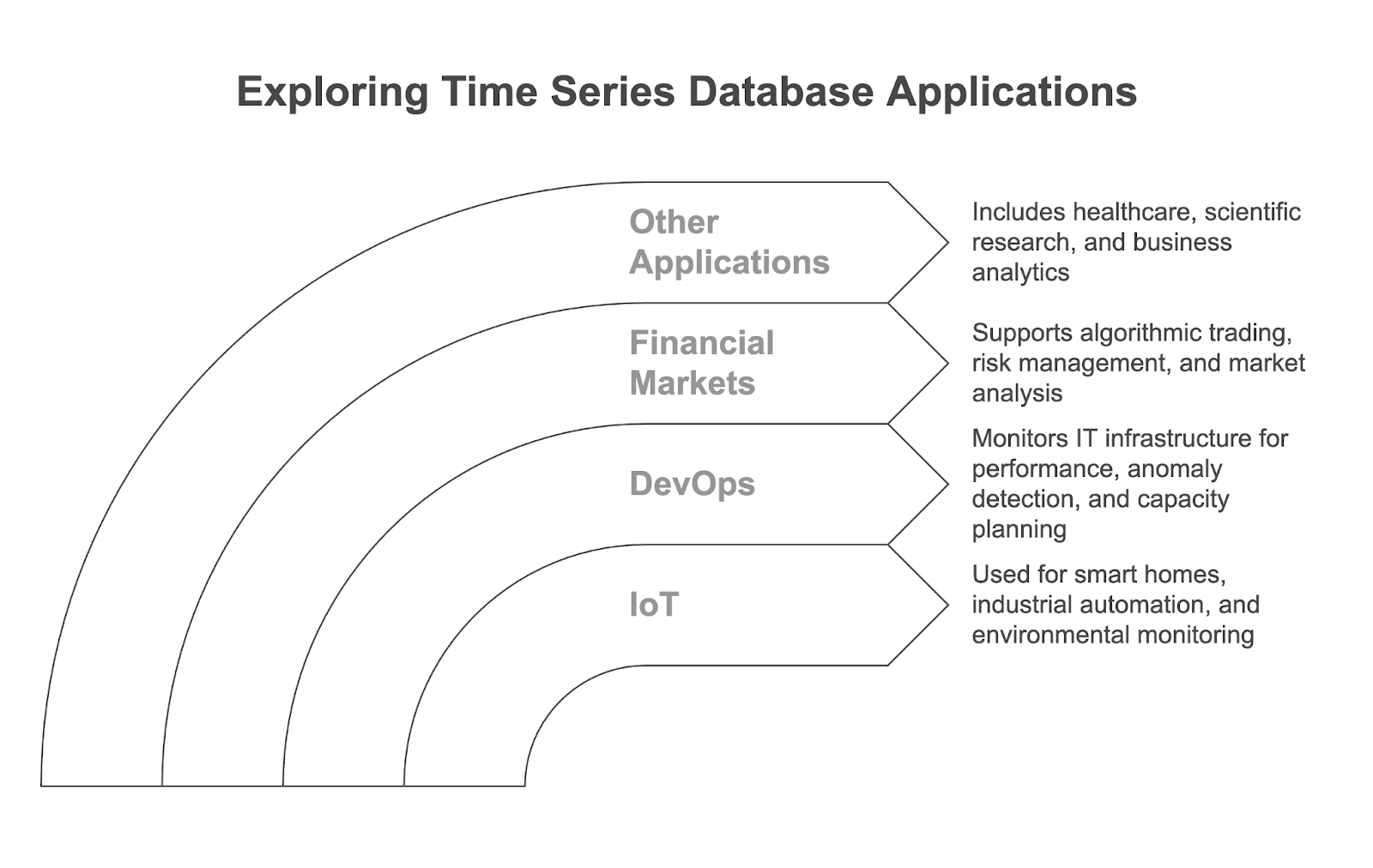
Zeitreihen-Datenbanken werden in vielen modernen datengesteuerten Anwendungen und in verschiedenen Branchen eingesetzt. Sehen wir uns die wichtigsten Anwendungsfälle an.
IoT-Geräte wie intelligente Thermostate, Industriesensoren und Umweltmonitore erzeugen kontinuierliche Datenströme mit Zeitstempeln. TSDBs werden verwendet, um diese Daten zu speichern und zu analysieren und ermöglichen Anwendungen wie:
In DevOps werden TSDBs häufig zur Überwachung der IT-Infrastruktur und der Anwendungen eingesetzt, indem sie Metriken wie CPU-Auslastung, Speicherverbrauch und Netzwerkdurchsatz erfassen. Sie ermöglichen:
Tools wie Prometheus und Grafana lassen sich oft in TSDBs integrieren, um Visualisierungs- und Alarmierungsfunktionen für DevOps-Teams bereitzustellen.
TSDBs sind entscheidend für die Verarbeitung und Analyse der riesigen Mengen an Hochfrequenzdaten, die auf den Finanzmärkten anfallen. Sie werden verwendet für:
Während die drei oben genannten Anwendungsfälle sehr häufig sind, können Zeitreihendatenbanken auch in einer Vielzahl anderer Bereiche eingesetzt werden:
Zeitreihen-Datenbanken gibt es in verschiedenen Formen, die jeweils auf bestimmte Anwendungsfälle zugeschnitten sind.
InfluxDB ist eine beliebte Open-Source-Zeitreihendatenbank, die von InfluxData entwickelt wurde. Sie wurde speziell für hohe Ingestion-Raten und effiziente Abfragen von Zeitstempeldaten entwickelt, was sie zu einer gängigen Lösung für IoT-Monitoring, DevOps-Metriken und Echtzeitanalysen macht.
|
Pros |
Nachteile |
|
Hohe Ingestionsraten für große Datenmengen. |
Erfordert eine manuelle Verwaltung der Aufbewahrungsrichtlinien für eine optimale Speicherung. |
|
Das SQL-ähnliche InfluxQL vereinfacht die Abfrage für Analysten, die mit relationalen Datenbanken vertraut sind. |
Skalierbarkeitsprobleme bei sehr großen Datensätzen ohne Unternehmensfunktionen. |
|
Lässt sich leicht mit Tools wie Grafana zur Visualisierung integrieren. |
Begrenzte erweiterte Abfragemöglichkeiten im Vergleich zu SQL-basierten Datenbanken. |
TimescaleDB ist eine Open-Source-Erweiterung für PostgreSQLdie entwickelt wurde, um die Leistungsfähigkeit von relationalen Datenbanken mit der Funktionalität von Zeitreihen zu kombinieren. Sie ermöglicht es dir, SQL zu nutzen und dabei effizient mit Zeitstempeldaten umzugehen. Dadurch eignet sie sich besonders gut für Anwendungsfälle, die die Integration von Zeitreihendaten mit relationalen Daten erfordern, wie z. B. Business Analytics oder IoT-Telemetrie.
|
Pros |
Nachteile |
|
Die vollständige SQL-Unterstützung ermöglicht eine einfache Integration mit bestehenden PostgreSQL-Tools und -Workflows. |
Erfordert PostgreSQL-Kenntnisse für die Einrichtung und Wartung. |
|
Hypertabellen: Partitioniere Zeitreihendaten automatisch für eine effiziente Speicherung und Abfrage. |
Die Ingestion-Geschwindigkeit von dedizierten TSDBs wie InfluxDB kann noch nicht erreicht werden. |
|
Kombiniert relationale und Zeitreihendaten in einer einzigen Datenbank. |
Prometheus ist ein Überwachungs- und Warnsystem mit einer eingebauten TSDB, das in DevOps für Echtzeit-Systemmetriken, Leistungsverfolgung und Warnmanagement weit verbreitet ist.
|
Pros |
Nachteile |
|
Leichtgewichtig und einfach zu implementieren, besonders mit Kubernetes. |
Begrenzte Langzeitlagerung ohne externe Lösungen. |
|
Das Pull-basierte Metrik-Scraping stellt sicher, dass nur relevante Daten gesammelt werden. |
Die Skalierbarkeit hängt von zusätzlichen Tools wie Thanos oder Cortex ab. |
|
PromQL bietet leistungsstarke Abfragemöglichkeiten. |
Konzentriert sich auf Metriken und ist möglicherweise nicht für alle allgemeinen TSDB-Anforderungen geeignet. |
ClickHouse ist eine Open-Source-Spalten-Datenbank, die für leistungsstarke analytische Abfragen entwickelt wurde. Obwohl es sich nicht um eine traditionelle TSDB handelt, eignet sie sich aufgrund ihrer Architektur hervorragend für Zeitreihendaten, insbesondere wenn eine schnelle Abfrageleistung entscheidend ist.
|
Pros |
Nachteile |
|
Hohe Abfrageleistung für analytische Workloads. |
Für Anfänger ist die Einrichtung und Wartung kompliziert. |
|
Spaltenbasierte Speicherung reduziert die Abfragelatenz. |
Nicht speziell als TSDB konzipiert (kann Workarounds erfordern). |
Apache Cassandra ist eine verteilte NoSQL-Datenbank, die für horizontale Skalierbarkeit und hohe Verfügbarkeit entwickelt wurde. Obwohl es sich nicht ausschließlich um eine TSDB handelt, kann sie effektiv für Zeitreihen-Workloads eingesetzt werden, insbesondere wenn Haltbarkeit und Fehlertoleranz entscheidend sind.
|
Pros |
Nachteile |
|
Ausgezeichnete horizontale Skalierbarkeit. |
Die Abfrage von Zeitreihendaten kann ohne zusätzliche Optimierungen mühsam sein, da die Datenbank nicht über native Zeitreihenabfrage- und Aggregationsfunktionen verfügt. |
|
Fehlertolerant und hochverfügbar. |
Amazon Timestream ist ein vollständig verwalteter Zeitreihen-Datenbankdienst, der von AWS angeboten wird. Sie wurde für Skalierbarkeit und Einfachheit entwickelt und ist ideal für Unternehmen, die bereits die AWS-Infrastruktur für IoT und Anwendungsüberwachung nutzen.
|
Pros |
Nachteile |
|
Die serverlose Architektur vereinfacht die Verwaltung. |
Begrenzte Funktionalität außerhalb des AWS-Ökosystems. |
|
Skaliert automatisch, um große Datenmengen zu verarbeiten. |
Die Kosten können bei hohen Datenerfassungsraten eskalieren. |
Lerne Data Engineering mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
