
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Also, lass uns loslegen und Amazon Polly einrichten! Dieser Abschnitt gibt dir einen Überblick darüber, wie du das machen kannst.
Um Amazon Polly zu nutzen, brauchst du zunächst ein AWS-Konto. Wenn du noch keinehast, gehe auf die AWS-Anmeldeseiteund folge den Schritten, um sie zu erstellen. Vergewissere dich, dass du gültige Rechnungsdaten angibst, denn AWS-Dienste, einschließlich Polly, werden nach Verbrauch abgerechnet.
IAM-Einrichtung für Berechtigungen
Ich empfehle,einen IAM-Benutzer (Identity and Access Management) einzurichten, derüber die notwendigen Berechtigungen verfügt, um Amazon Polly-Ressourcen zu verwalten. Weise die Richtlinie AmazonPollyFullAccess zu, um sicherzustellen, dass der Benutzer auf alle Polly-Funktionen zugreifen kann.
Nachdem du dich in der AWS Management Console angemeldet hast, suche in der Suchleiste oben nach Polly.
Die Suchmenü in der AWS-Konsole.
Klicke auf den Amazon Polly-Service, um die Polly-Oberfläche zu öffnen.
Normalerweise verwenden Entwickler die Amazon Polly API, um Text-to-Speech-Funktionen direkt in ihre Anwendungen zu integrieren. Du kannst aber auch die AWS Polly-Schnittstelle nutzen, um schnell verschiedene Stimmen und Einstellungen auszuprobieren, ohne Code zu schreiben. Dazu klickst du auf die Schaltfläche Try Polly in der Polly-Oberfläche. Mit dieser Schaltfläche kannst du von der AWS-Konsole aus mit verschiedenen Texteingaben, Sprachtypen und Ausgabeformaten experimentieren und so die Möglichkeiten von Polly erkunden, bevor du sie programmatisch umsetzt.
Um eine einfache Text-zu-Sprache-Umwandlung durchzuführen, gib einen Satz wie "Hallo, willkommen bei Amazon Polly!" in das Eingabefeld ein. Du kannst auch die Art der Engine (z.B. Generativ, Langform, Neural oder Standard), die Sprache und die Stimme auswählen. Klicke auf Listen, um die Ausgabe sofort anzuhören oder klicke auf Download, um sie als .mp3 Datei herunterzuladen.
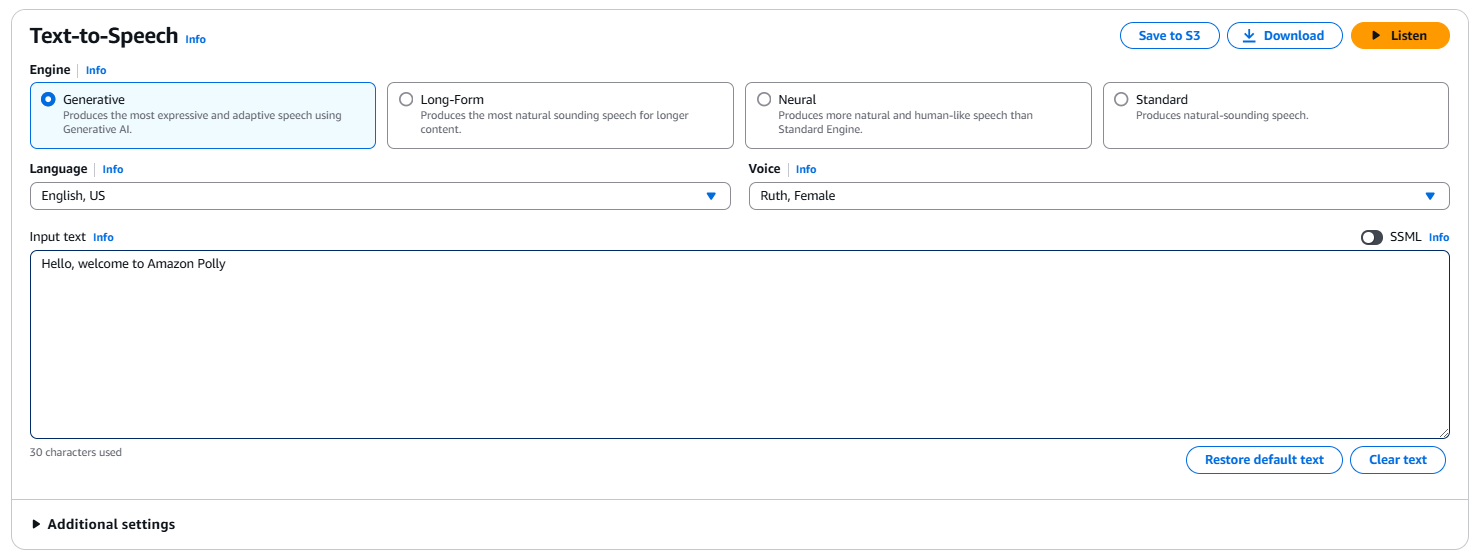
Die Amazon Polly-Schnittstelle in der AWS-Konsole.
Du musst das AWS SDK einrichten, um Amazon Polly programmatisch in deine Anwendungen zu integrieren. So kannst du direkt von deinem Code aus mit Amazon Polly interagieren und dynamischere und anpassbare Text-to-Speech-Funktionen ermöglichen.
In diesem Lernprogramm verwenden wirdas Python SDK (boto3). Installiere boto3 über pip:
pip install boto3Konfigurieren Sie dann Ihre AWS-Anmeldedaten mit der AWS CLI:
aws configure
Der aws configure Befehl auf der CLI.
Hier ist ein einfaches Python-Skript, das Text mit Amazon Polly in Sprache umwandelt:
import boto3
polly = boto3.client('polly')
response = polly.synthesize_speech(
Text='Hello, this is a test of Amazon Polly.',
OutputFormat='mp3',
VoiceId='Joanna'
)
with open('speech.mp3', 'wb') as file:
file.write(response['AudioStream'].read())Dieses Skript erzeugt Sprache aus Text und speichert sie als mp3-Datei.
Amazon Polly ist zwar für seine grundlegende Text-to-Speech-Funktionalität bekannt, bietet aber auch eine Reihe fortschrittlicher Funktionen, mit denen Entwickler anspruchsvollere und interaktive Spracherlebnisse schaffen können.
SSML (Speech Synthesis Markup Language) ermöglicht es Entwicklern, verschiedene Sprachaspekte wie Tonhöhe, Geschwindigkeit, Lautstärke und Betonung zu steuern, um die Audioausgabe ausdrucksstärker und natürlicher zu gestalten.
Mit SSML-Tags kannst du Pausen einfügen, den Sprechstil anpassen und sogar Akronyme Buchstabe für Buchstabe buchstabieren. Diese Flexibilität ist besonders nützlich für Szenarien wie Storytelling, E-Learning-Plattformen und Kundendienstanwendungen, bei denen der Ton und der Vortragsstil einen großen Einfluss auf das Engagement der Nutzer haben.
Du kannst zum Beispiel bestimmte Wörter betonen, um die Wichtigkeit zu vermitteln, oder die Sprechgeschwindigkeit für Unterrichtsinhalte ändern, um die Verständlichkeit zu gewährleisten.
Hier erfährst du, wie du SSML mit dem Polly SDK verwenden kannst:
response = polly.synthesize_speech(
Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>",
TextType='ssml',
OutputFormat='mp3',
VoiceId='Matthew'
)
# Save the audio file
with open('speech_ssml.mp3', 'wb') as file:
file.write(response['AudioStream'].read())In diesem Beispiel wird das Wort "wichtig" hervorgehoben, um es in der gesprochenen Nachricht hervorzuheben und die emotionale Wirkung auf den Zuhörer zu verstärken. SSML unterstützt auch fortgeschrittene Funktionen wie die Aussprache von Phonemen, Flüstern und das Hinzufügen von Soundeffekten und gibt Entwicklern die volle Kontrolle über das Spracherlebnis.
Sprachmarkierungen liefern zeitlich abgestimmte Metadaten, die es Entwicklern ermöglichen, Sprache mit Animationen, Texthervorhebungen oder Lippenbewegungen von Figuren zu synchronisieren.
Diese Funktion ist besonders wertvoll für interaktive Anwendungen wie virtuelle Figuren, Lernspiele oder Karaoke-ähnliche Texthervorhebungen.
Wenn du neben der Sprachsynthese auch Sprachmarkierungen anforderst, erhältst du detaillierte Zeitangaben für jedes Wort oder jeden Satz und kannst so dynamische, synchronisierte Multimedia-Erlebnisse schaffen.
Du kannst zum Beispiel die Mundbewegungen eines Charakters synchron zu den gesprochenen Worten animieren oder Text in Echtzeit markieren, während er erzählt wird. Hier erfährst du, wie du Sprachmarken beantragen kannst:
response = polly.synthesize_speech(
Text='Hello, world!',
OutputFormat='json',
VoiceId='Emma',
SpeechMarkTypes=['word']
)
# Save the speech marks to a JSON file
with open('speech_marks.json', 'wb') as file:
file.write(response['AudioStream'].read())JSON ausgeben:
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"}
{"time":714,"type":"word","start":7,"end":12,"value":"world"}Das obige Beispiel fragt für jedes Wort Sprachmarken ab und gibt ein JSON-Objekt mit Zeitstempeln und Textdaten zurück. Die Entwickler können diese Informationen nutzen, um die Animationen Frame für Frame zu synchronisieren und so das audiovisuelle Erlebnis noch fesselnder und realistischer zu gestalten.
Für Echtzeitanwendungen wie Sprachassistenten, Live-Kommentare oder interaktive Chatbots unterstützt Amazon Polly das Streaming über das WebSocket-Protokoll oder Media Player, die HLS (HTTP Live Streaming) unterstützen.
Dadurch können Anwendungen bereits während der Synthese mit der Audiowiedergabe beginnen, was die Latenzzeit verkürzt und ein schnelleres Nutzererlebnis ermöglicht. Echtzeit-Streaming ist ideal für Szenarien, in denen es auf Unmittelbarkeit ankommt, wie z.B. beim Live-Kundensupport oder bei der KI-Konversation.
Entwickler können diese Funktion nutzen, um sprachgesteuerte Geräte, Newsreader oder interaktive Storytelling-Anwendungen zu entwickeln, die auf Benutzereingaben reagieren.
Eine effektive Verwaltung der Amazon Polly-Ressourcen ist entscheidend für die Optimierung von Leistung, Kosten und Skalierbarkeit. Indem du Sprachdateien strategisch speicherst und die Nutzung überwachst, kannst du eine effiziente Ressourcennutzung sicherstellen und gleichzeitig ein hochwertiges Nutzererlebnis gewährleisten.
Amazon Polly lässt sich nahtlos in andere AWS-Dienste wie Amazon S3 für die Speicherung und das AWS Billing Dashboard für die Kostenüberwachungintegrieren und erleichtert so die Ressourcenverwaltung.
Mit Amazon Polly kannst du synthetisierte Sprache in Amazon S3 speichern, um sie skalierbar zu halten und einfach abzurufen. Dieser Ansatz ist besonders nützlich für Anwendungen mit wiederkehrenden Audioanforderungen, wie z. B. E-Learning-Plattformen, Hörbücher oder Kundensupport-Bots, bei denen du Audiodateien wiederverwenden kannst, anstatt jedes Mal Sprache zu synthetisieren.
Indem du häufig verwendete Sprachausgaben in S3 speicherst, kannst du Kosten senken und die Leistung verbessern, indem du Audiodateien direkt aus der Cloud bereitstellst.
s3 = boto3.client('s3')
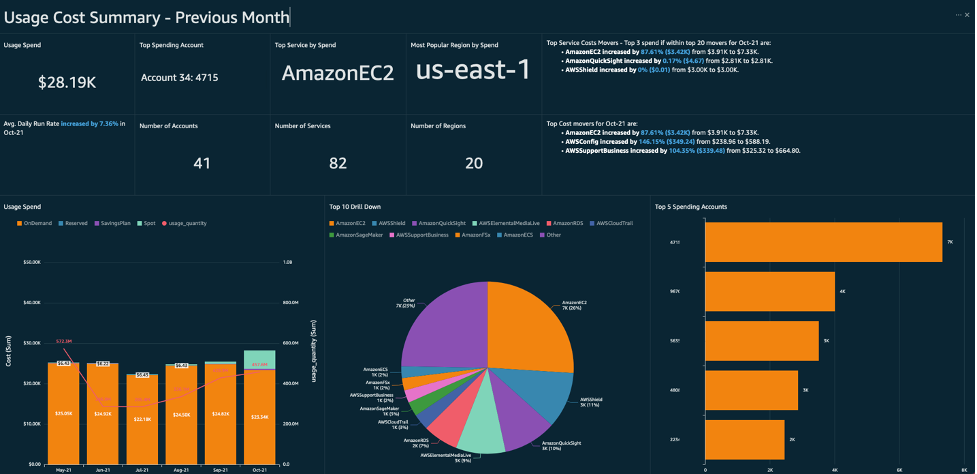
s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')Nutze das AWS Billing and Cost Management Dashboard, um Nutzung und Kosten effizient zu überwachen. Dieses Dashboard bietet detaillierte Kostenaufstellungen, Nutzungsberichte und die Möglichkeit, Budgets und Warnmeldungen einzurichten, um unerwartete Kosten zu vermeiden.
Die Überwachung der Kosten ist besonders wichtig, wenn neuronale Stimmen verwendet werden, die teurer sind als Standardstimmen. Du kannst auch Nutzungskennzahlen wie die Anzahl der synthetisierten Zeichen und die Häufigkeit der API-Aufrufe nachverfolgen, was dir helfen kann, die Ressourcennutzung zu optimieren.
Beispiel für ein AWS-Kosten-Dashboard.
Bei der Verwendung von Amazon Polly sorgt die Anwendung von Best Practices für optimale Leistung, Kosteneffizienz und Benutzerfreundlichkeit. Hier sind einige wichtige Richtlinien:
Die Wahl der richtigen Stimme hängt vom Zweck der Anwendung und der Zielgruppe ab. Amazon Polly bietet eine Vielzahl von Stimmen, darunter Standard- und neuronale Stimmen, jede mit einzigartigen Tönen und Eigenschaften.
Nutze SSML (Speech Synthesis Markup Language), um die Sprachqualität zu verbessern, indem du die Parameter Tonhöhe, Geschwindigkeit und Lautstärke anpasst. Du kannst ein dynamischeres und fesselnderes Klangerlebnis schaffen, indem du diese Einstellungen fein abstimmst.
Wenn du zum Beispiel das Sprechtempo verlangsamst, werden Unterrichtsinhalte klarer, während die Betonung von Schlüsselsätzen das Erzählen von Geschichten verbessert. Das Experimentieren mit verschiedenen SSML-Tags hilft dir, die am natürlichsten klingende Sprache zu erreichen.
Strategien wie die Steuerung der Häufigkeit der Spracherzeugung und die Speicherung häufig verwendeter Audiodateien in S3 zur Wiederverwendung sollten in Betracht gezogen werden, um die Kosten beim Einsatz von Amazon Polly zu optimieren. Dieser Ansatz minimiert sich wiederholende API-Aufrufe und reduziert die Synthesekosten.
Außerdem kann der strategische Einsatz einer Mischung aus Standard- und neuronalen Stimmen ein Gleichgewicht zwischen Kosten und Qualität herstellen.
Verwende zum Beispiel neuronale Stimmen nur für kritische Touchpoints wie Willkommensnachrichten, während Standardstimmen für informativen Inhalt verwendet werden. Die Einrichtung von Nutzungsgrenzen und Kostenwarnungen im AWS Billing Dashboard hilft dabei, das Budget zu kontrollieren und unerwartete Ausgaben zu vermeiden.
Amazon Polly ist ein leistungsstarker Text-to-Speech-Service, der fortschrittliche Deep-Learning-Technologien nutzt, um Text in lebensechte Sprache umzuwandeln und so das Nutzererlebnis und die Barrierefreiheit zu verbessern.
In diesem Lernprogramm haben wir die grundlegenden Funktionen von Amazon Polly kennengelernt, von der Einrichtung des AWS SDK bis zur programmgesteuerten Spracherzeugung. Wir haben auch fortgeschrittene Funktionen behandelt, wie die Verwendung von SSML für individuelle Sprachausgabe, die Nutzung von Speech Marks für Lippensynchronisation und Animationen und die Implementierung von Echtzeit-Streaming für dynamische Sprachanwendungen.
Die Integration von Amazon Polly in deine Anwendungen ermöglicht es dir, hochgradig interaktive und personalisierte Spracherlebnisse zu schaffen, die ein globales Publikum ansprechen. Egal, ob du virtuelle Assistenten, Hörbücher, Bildungsplattformen oder Tools für Barrierefreiheit entwickelst, Amazon Polly bietet die Flexibilität, Skalierbarkeit und fortschrittlichen Funktionen, die du brauchst, um deine Ideen zum Leben zu erwecken.
Wenn du neu bei AWS bist und deine Cloud-Kenntnisse vertiefen möchtest, solltest du diese Kurse in Betracht ziehen:
Lerne mehr über AWS mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
