Du arbeitest mit künstlicher Intelligenz (KI) oder maschinellem Lernen (ML) und brauchst eine Text-to-Speech-Engine? In diesem Fall brauchst du eine Open-Source-Lösung. Wir wollen herausfinden, wie Text-to-Speech-Engines (TTS) funktionieren und einige der besten Open-Source-Optionen kennenlernen.
In diesem einfachen Leitfaden erzähle ich mehr über TTS-Engines und liste einige der besten verfügbaren Optionen auf.
Was ist eine Text-to-Speech (TTS) Engine?
Bevor wir mit der Liste beginnen, lass uns kurz definieren, was eine Text-to-Speech-Engine eigentlich ist.
Eine Text-to-Speech-Engine ist eine Software, die geschriebenen Text in gesprochene Wörter umwandelt. Es nutzt die Verarbeitung natürlicher Sprache (NLP), um geschriebenen Text zu analysieren und zu interpretieren, und verwendet dann einen Sprachsynthesizer, um menschenähnliche Sprache zu erzeugen.
TTS-Engines werden häufig in Anwendungen wie virtuellen Assistenten, Navigationssystemen und Barrierefreiheitstools eingesetzt.
Bist du daran interessiert, mit NLP zu arbeiten? Der DataCamp Skill Track Natural Language Processing in Python hilft dir, dein technisches Know-how auf Vordermann zu bringen.
Was sind Open-Source Text-to-Speech (TTS)-Engines?
Open-Source-Text-to-Speech-Engines (TTS) sind wertvolle Werkzeuge, um geschriebenen Text in gesprochene Worte umzuwandeln und ermöglichen so u.a. Anwendungen in den Bereichen Barrierefreiheit, automatische Sprachsteuerung und virtuelle Assistenten.
Sie werden normalerweise von einer Gemeinschaft von Entwicklern entwickelt und unter einer Open-Source-Lizenz veröffentlicht, die es jedem erlaubt, die Software frei zu nutzen, zu verändern und zu verbreiten.
Die 7 besten Open Source Text-to-Speech (TTS) Engines
Hier sind einige bekannte Open-Source-TTS-Engines:
1. MaryTTS (Multimodale Interaktionsarchitektur)
Eine flexible, modulare Architektur für den Aufbau von TTS-Systemen, einschließlich eines Werkzeugs zur Erzeugung neuer Stimmen aus aufgezeichneten Audiodaten.
Hier ist ein Übersichtsdiagramm der Architektur hinter dieser Maschine:
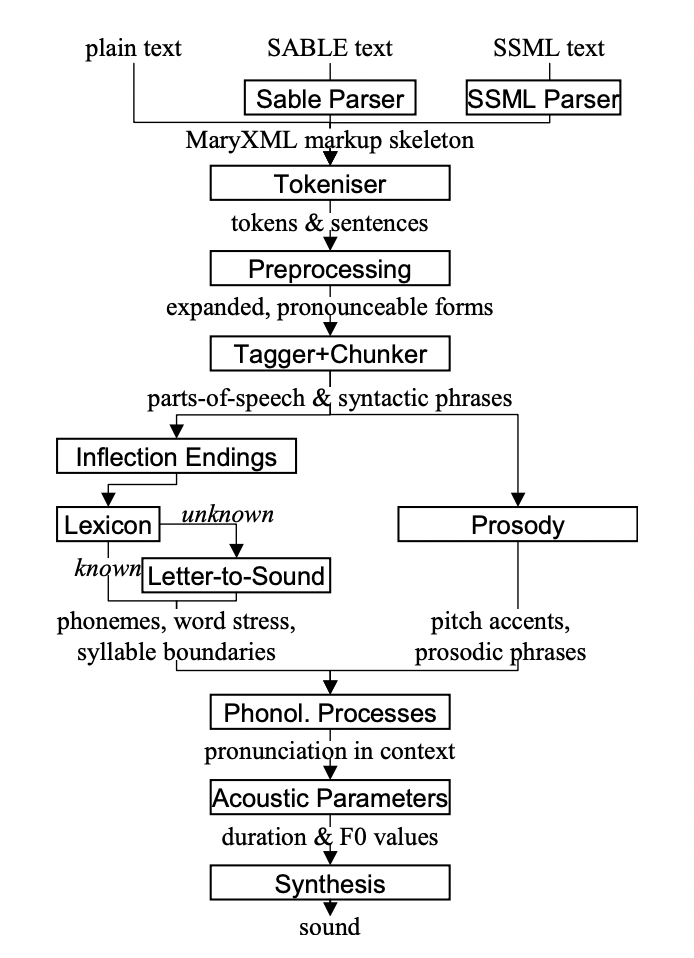
Quelle: MaryTTS GitHub
Diese Architektur umfasst einige grundlegende Komponenten wie:
- Ein Parser für Auszeichnungssprachen: Eine Komponente, die die im Textfeld verwendete Auszeichnungssprache liest und interpretiert.
- Ein Prozessor: Eine Komponente, die den geparsten Text aufnimmt und alle notwendigen Aktionen durchführt, wie z. B. die Umwandlung in Sprache oder die Erzeugung einer visuellen Ausgabe.
- Ein Synthesizer: Eine Komponente, die für die Produktion der endgültigen Ausgabe verantwortlich ist, egal ob es sich um Audio- oder Bildmaterial handelt. Sie hilft dabei, Sprachmerkmale wie Intonation und Tonfall hinzuzufügen, damit die Ausgabe natürlicher klingt.
Vorteile: Die MaryTTS-Architektur ist in hohem Maße anpassbar und ermöglicht es Entwicklern, ihre eigenen Parser, Prozessoren und Synthesizer zu erstellen, die ihren spezifischen Bedürfnissen entsprechen. Das ermöglicht auch eine flexible Integration der Software in verschiedene Plattformen und Anwendungen.
Nachteile: Da das Programm sehr anpassungsfähig ist, kann es für Entwickler, die mit der Auszeichnungssprache und der Text-to-Speech-Technologie nicht vertraut sind, eine Lernkurve geben.
2. eSpeak
 kompakter Open-Source-Software-Sprachsynthesizer für Englisch und andere Sprachen, eSpeak produziert klare und verständliche Sprache in einer Vielzahl von Sprachen. Sie ist bekannt für ihre Einfachheit und ihren geringen Platzbedarf.
kompakter Open-Source-Software-Sprachsynthesizer für Englisch und andere Sprachen, eSpeak produziert klare und verständliche Sprache in einer Vielzahl von Sprachen. Sie ist bekannt für ihre Einfachheit und ihren geringen Platzbedarf.
eSpeak kann auf verschiedenen Plattformen ausgeführt werden, darunter Windows, Linux, macOS und Android.
Vorteile: Einfach zu bedienen, unterstützt viele Sprachen und Stimmen.
Nachteile: Begrenzte Funktionen und Anpassungsmöglichkeiten und in C geschrieben.
Link: GitHub
3. Festival-Sprachsynthese-System
Festival wurde von der University of Edinburgh entwickelt und bietet einen allgemeinen Rahmen für die Entwicklung von Sprachsynthesesystemen sowie Beispiele für verschiedene Module. Es wird häufig für Forschungs- und Bildungszwecke verwendet.
Die folgende Abbildung zeigt die allgemeine Äußerungsstruktur von Festival. Es handelt sich um eine Baumform mit Verbindungen zwischen den Knoten, die eine Beziehung darstellen.
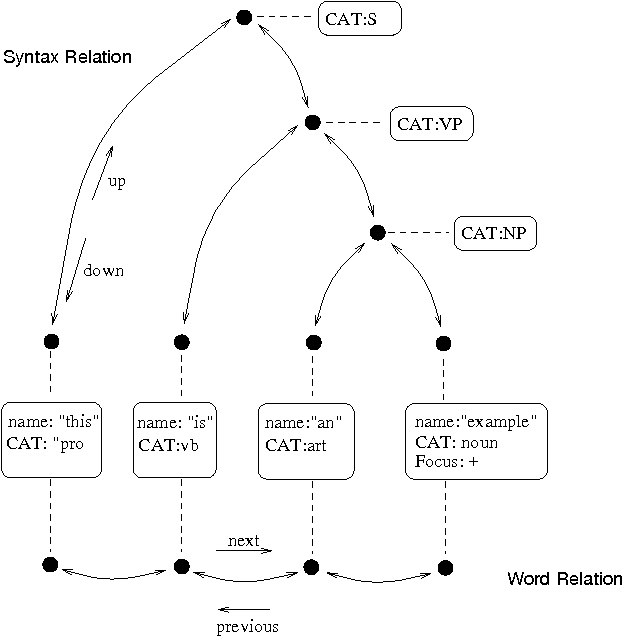
Vorteile: Hochgradig anpassbar, geeignet für Forschungszwecke.
Nachteile: Schwierig zu bedienen für Anfänger, erfordert einige Programmierkenntnisse.
Link: GitHub
4. Mimik
Quelle: Mimic
Mimic wurde von Mycroft AI entwickelt und ist in der Lage, sehr natürlich klingende Sprache zu produzieren. Es umfasst Mimic 1, das auf dem Festival Speech Synthesis System basiert, und Mimic 2, das tiefe neuronale Netze für die Sprachsynthese verwendet.
Vorteile: Bietet sowohl traditionelle als auch moderne Sprachsynthesemethoden und unterstützt mehrere Sprachen.
Nachteile: Begrenzte Dokumentation.
Link: GitHub
5. Mozilla TTS
Eine auf Deep Learning basierende TTS-Engine, die darauf abzielt, eine natürlichere und menschenähnliche Sprachsynthese zu schaffen. Es nutzt moderne neuronale Netzwerkarchitekturen, insbesondere Sequenz-zu-Sequenz-Modelle.
Vorteile: Verwendet fortschrittliche Technologie für eine natürlichere Sprache und ist kostenlos zu verwenden.
Nachteile: Eingeschränkte Sprachunterstützung.
Link: GitHub
6. Tacotron 2 (by NVIDIA)
Obwohl es sich bei Tacotron 2 nicht um eine Engine im eigentlichen Sinne handelt, ist es eine neuronale Netzwerkmodellarchitektur zur Erzeugung natürlicher Sprache. Es gibt Open-Source-Implementierungen von Tacotron 2 und es hat viele Entwicklungen in der Sprachsynthesetechnologie inspiriert.
Dieses System ermöglicht es den Nutzern, Sprache anhand von Rohtranskripten ohne zusätzliche Prosodie-Informationen zu synthetisieren.
Vorteile: Entwickelt von NVIDIA, gut geeignet als neuronales Netzwerkmodell.
Nachteile: Für die Umsetzung sind einige technische Kenntnisse erforderlich.
Obwohl diese Engine technisch recht schwierig zu beherrschen ist, kannst du dich mit verwandten neuronalen Netzwerkmodellen über Online-Ressourcen vertraut machen. Ein solcher Ort wäre zum Beispiel unser Leitfaden für neuronale Netze oder unser Tutorial über neuronale Netze.
Link: GitHub
7. ESPnet-TTS
Diese TTS-Engine ist Teil des ESPnet-Projekts und wurde für eine durchgängige Sprachverarbeitung entwickelt, die sowohl Spracherkennung als auch Sprachsynthese umfasst. Sie nutzt moderne Deep-Learning-Techniken, um Sprache zu erzeugen.
Vorteile: Modern und flexibel, unterstützt mehrere Sprachen.
Nachteile: Für die Umsetzung sind einige technische Kenntnisse erforderlich.
Link: GitHub
Open-Source TTS-Engines im Vergleich
|
TTS-System |
Architektur/Technologie |
Profis |
Nachteile |
Anwendungsfälle |
|
MaryTTS |
Modulare Architektur mit anpassbaren Komponenten |
Hochgradig anpassbare, flexible Integration |
Lernkurve für Entwickler |
Ideal für Entwickler und Forscher, die maßgeschneiderte TTS-Anwendungen erstellen, vor allem in Projekten, die auf Bildung und Barrierefreiheit ausgerichtet sind. |
|
eSpeak |
Kompakter Open-Source-Software-Synthesizer |
Einfach, unterstützt viele Sprachen |
Begrenzte Funktionen und Anpassungen, geschrieben in C |
Geeignet für Anwendungen, die eine breite Sprachunterstützung und minimale Systemressourcen erfordern, wie z. B. eingebettete Systeme oder Hilfstechnologien. |
|
Festival-Sprachsynthese-System |
Allgemeiner Rahmen mit Beispielen für Module |
Hochgradig anpassbar, geeignet für die Forschung |
Schwierig für Anfänger, erfordert Programmierkenntnisse |
Am besten geeignet für akademische Forschungs- und Entwicklungsprojekte, bei denen ein hoher Bedarf an Anpassungen und Versuchsaufbauten besteht. |
|
Mimik |
Traditionelle und neuronale Netzwerk-basierte Sprachsynthese |
Natürlich klingende Sprache, unterstützt mehrere Sprachen |
Begrenzte Dokumentation |
Gut geeignet für Projekte, die eine hochwertige Sprachsynthese erfordern, wie virtuelle Assistenten oder Multimedia-Anwendungen. |
|
Mozilla TTS |
Deep Learning-basierte Sequenz-zu-Sequenz-Modelle |
Fortschrittliche Technologie für natürlichere Sprache, kostenlos zu nutzen |
Eingeschränkte Sprachunterstützung |
Ideal für Open-Source-Projekte und Entwickler, die modernste Deep-Learning-Techniken für natürlich klingende TTS nutzen möchten. |
|
Tacotron 2 (NVIDIA) |
Neuronales Netzwerkmodell für natürliche Spracherzeugung |
Gut als Modell für ein neuronales Netz |
Erforderliche technische Kenntnisse |
Perfekt für die Forschung und Entwicklung im Bereich der Sprachsynthese mit neuronalen Netzwerken, die eine Grundlage für innovative TTS-Anwendungen bietet. |
|
ESPnet-TTS |
End-to-End-Sprachverarbeitung mit Deep-Learning |
Modern und flexibel, unterstützt mehrere Sprachen |
Erforderliche technische Kenntnisse |
Richtet sich an Entwickler und Forscher, die an fortgeschrittenen Sprachsynthese- und -erkennungsprojekten arbeiten, insbesondere an solchen, die eine mehrsprachige Unterstützung erfordern. |
Anwendungen von TTS-Engines
Hier sind einige Möglichkeiten, wie die oben genannten TTS-Engines eingesetzt werden können:
1. Virtuelle Assistenten
Durch den Einsatz von Text-to-Speech-Engines wie den oben genannten können virtuelle Assistenten erstellt werden. Diese virtuellen Assistenten können mit Sprachassistenten wie Siri und Alexa vergleichbar sein.

Einige von ihnen können sogar als Zugänglichkeitshilfe für Menschen mit Sehbehinderungen eingesetzt werden, so dass sie geschriebenen Text hören können, anstatt ihn zu lesen.
2. Automatische Sprachantworten mit KI-Stimme
TTS-Engines werden auch in automatischen Antwortsystemen wie Telefon- oder Chatbot-Assistenten eingesetzt. Diese Maschinen können Antworten auf bestimmte Aufforderungen und Interaktionen vorlesen und bieten so eine menschenähnliche Erfahrung für die Nutzer.
3. Video/Bild Voiceover
Die Text-to-Speech-Technologie kann auch Voiceover für Videos oder Bilder erzeugen, was dynamischere und ansprechendere Inhalte ermöglicht.
Die eSpeak-Engine kann zum Beispiel dazu verwendet werden, Videos in verschiedenen Sprachen zu vertonen, um sie für ein größeres Publikum zugänglicher und attraktiver zu machen.
Dies ist besonders nützlich für Anwendungen im Marketing, E-Learning und in der Unterhaltungsbranche.
Herausforderungen bei der Verwendung von Open-Source-TTS-Engines
Die Verwendung einer Open-Source-Option kann kostengünstig sein und bietet mehr Flexibilität bei der Anpassung. Allerdings gibt es einige Herausforderungen, die mit der Nutzung dieser Motoren einhergehen:
1. Eingeschränkte Sprachunterstützung
Viele Open-Source-TTS-Engines haben im Vergleich zu kommerziellen Lösungen eine begrenzte Sprachunterstützung.
Diese Einschränkung kann ein Hindernis für Nutzer sein, die TTS in weniger verbreiteten Sprachen benötigen.
2. Anpassung und Implementierung
Die meisten Open-Source-TTS-Engines erfordern einige Programmierkenntnisse, um sie anzupassen und zu implementieren. Das macht es für normale Geschäftsakteure schwierig, sie ohne technische Unterstützung zu nutzen.
Das kann für Einzelpersonen oder Organisationen ohne technisches Fachwissen eine Herausforderung sein.
3. Kostenüberlegungen
Open-Source-Engines können zwar kostenlos genutzt werden, erfordern aber möglicherweise zusätzliche Ressourcen und Zeit für die Anpassung und Implementierung.
Außerdem muss ein Ingenieur oder Analytiker mit dem entsprechenden Know-how über TTS-Engines eingestellt oder geschult werden.
Deshalb können in manchen Fällen kommerzielle Lösungen auf lange Sicht kostengünstiger sein.
4. Unterstützung und Dokumentation
Da Open-Source-Projekte nur über begrenzte Ressourcen verfügen und von der Gemeinschaft getragen werden, stehen nicht immer umfangreiche Unterstützung und Dokumentation zur Verfügung.
Quelle: ESPnet Dokumentation
Das kann es für die Nutzer/innen schwierig machen, Probleme zu beheben oder zu lernen, wie man die Engine effektiv nutzt.
Da diese Engines jedoch immer beliebter werden und immer mehr Entwickler dazu beitragen, könnte diese Herausforderung mit der Zeit kleiner werden.
5. Sicherheit und Leistung
Da Open-Source-Engines von einer Gemeinschaft entwickelt und gewartet werden, kann es Bedenken hinsichtlich Sicherheit und Leistung geben.
Diese Risiken können jedoch durch eine ordnungsgemäße Überprüfung und Überwachung des Codes und der Updates der Engine gemildert werden.
Darüber hinaus kann die Wahl zuverlässiger und seriöser Open-Source-Projekte dazu beitragen, diese Bedenken zu zerstreuen.
Die Auswahl der besten Engine für die TTS-Integration
Wir wollen nun besprechen, wie du die richtige Engine für dein Text-to-Speech-Modell auswählst.
Hier sind einige Faktoren, die du berücksichtigen solltest:
1. Zweck und Anwendungsfall
Beginne damit, deinen speziellen Anwendungsfall und den Zweck des Einsatzes von TTS zu ermitteln. Mach dir klar, welche Funktionen und Anpassungsmöglichkeiten für dein Projekt notwendig sind, und wähle dann eine entsprechende Engine aus.
2. Sprachliche Unterstützung
Wenn du Unterstützung für eine bestimmte Sprache oder mehrere Sprachen benötigst, solltest du eine Engine wählen, die diese Möglichkeiten bietet.

In diesem Fall könnte die eSpeak-Engine die bessere Option für dich sein.
3. Kosten und Budget
Berücksichtige dein Budget und deine Ressourcen, bevor du einen Motor auswählst. Open-Source-Optionen können zwar auf lange Sicht kostengünstig sein, erfordern aber möglicherweise zusätzliche Ressourcen für die Anpassung und Implementierung.
4. Technisches Fachwissen
Beurteile die Fähigkeiten deines Teams oder von dir selbst bei der Arbeit mit TTS-Engines. Wenn du kein technisches Fachwissen hast, solltest du dich für eine kommerzielle Lösung entscheiden, die benutzerfreundliche Schnittstellen und Unterstützung bietet.
5. Leistung und Qualität
Achte darauf, dass die von dir gewählte Engine eine hochwertige, natürlich klingende Sprachausgabe liefert. Vielleicht möchtest du auch verschiedene Motoren testen, um herauszufinden, welcher am besten zu deinem gewünschten Leistungsniveau passt.
Schlussgedanken
Die Text-to-Speech-Technologie hat einen langen Weg zurückgelegt, um eine natürlichere und menschenähnliche Sprachausgabe zu ermöglichen. Dank zahlreicher Open-Source-Optionen ist es jetzt einfacher und kostengünstiger, TTS in verschiedene Anwendungen zu integrieren.
Allerdings musst du auch mit einigen Einschränkungen und Herausforderungen rechnen, die mit der Verwendung von Open-Source-Engines einhergehen, bevor du eine Entscheidung triffst. Ich hoffe, dieser Leitfaden hat dir ein besseres Verständnis für TTS-Engines vermittelt und dir bei der Auswahl der besten Engine für deine Bedürfnisse geholfen.
Suchst du nach Möglichkeiten, diesen Prozess rückgängig zu machen? Schau dir unseren Kurs Spoken Language Processing in Python an.