
Track
AWS Cloud Practitioner (CLF-C02)
10 hr
Now, let’s get hands-on and set up Amazon Polly! This section provides an overview of how to do that.
To use Amazon Polly, you first need an AWS account. If you don't already have one, go to the AWS sign-up page and follow the steps to create it. Ensure you provide valid billing information, as AWS services, including Polly, are billed based on usage.
IAM setup for permissions
I recommend setting up an IAM (Identity and Access Management) user with the necessary permissions to manage Amazon Polly resources. Assign the AmazonPollyFullAccess policy to ensure the user can access all Polly features.
After logging into the AWS Management Console, search for Polly in the search bar towards the top.
The search menu in the AWS console.
Click on Amazon Polly service to get into the Polly interface.
Normally, developers use the Amazon Polly API to integrate text-to-speech functionality directly into their applications. However, you can also use the AWS Polly interface to quickly try out different voices and settings without writing code. To do that, click on the Try Polly button in the Polly interface. This button lets you experiment with various text inputs, voice types, and output formats from the AWS Console, making it easy to explore Polly’s capabilities before implementing them programmatically.
To perform a basic text-to-speech conversion, enter a sentence like "Hello, welcome to Amazon Polly!" in the input box. You can also choose the engine type (e.g., Generative, long-form, neural, or standard), language, and voice. Click on Listen to immediately listen to the output or click Download to download it as a .mp3 file.
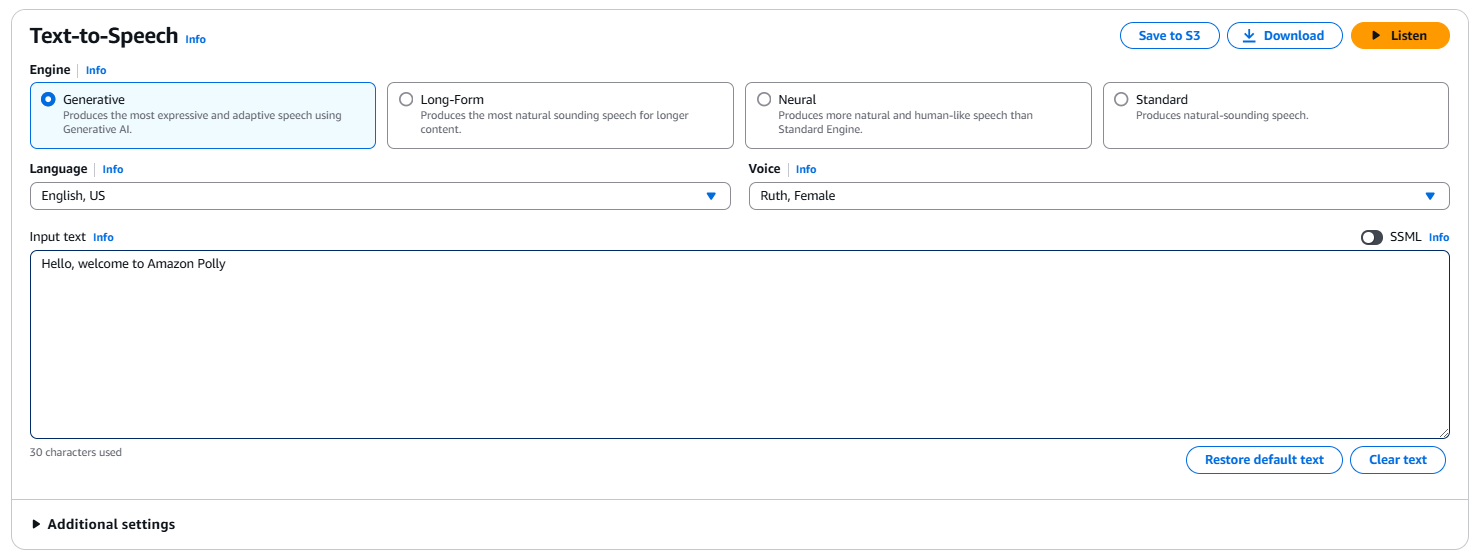
The Amazon Polly interface in the AWS console.
You need to set up the AWS SDK to integrate Amazon Polly into your applications programmatically. This lets you interact with Amazon Polly directly from your code, enabling more dynamic and customizable text-to-speech functionalities.
In this tutorial, we'll use the Python SDK (boto3). Install boto3 via pip:
pip install boto3Then, configure your AWS credentials using the AWS CLI:
aws configure
The aws configure command on the CLI.
Here's a simple Python script to convert text to speech using Amazon Polly:
import boto3
polly = boto3.client('polly')
response = polly.synthesize_speech(
Text='Hello, this is a test of Amazon Polly.',
OutputFormat='mp3',
VoiceId='Joanna'
)
with open('speech.mp3', 'wb') as file:
file.write(response['AudioStream'].read())This script generates speech from text and saves it as an mp3 file.
While Amazon Polly is widely known for its basic text-to-speech functionality, it also offers a range of advanced features that allow developers to create more sophisticated and interactive voice experiences.
SSML (Speech Synthesis Markup Language) allows developers to control various speech aspects, such as pitch, rate, volume, and emphasis, making the audio output more expressive and natural.
Using SSML tags, you can add pauses, adjust speaking styles, and even spell out acronyms letter by letter. This flexibility is particularly useful for scenarios like storytelling, e-learning platforms, and customer service applications, where the tone and delivery style significantly impact user engagement.
For example, you can emphasize certain words to convey importance or alter the speaking rate for instructional content to ensure clarity.
Here’s how to use SSML with the Polly SDK:
response = polly.synthesize_speech(
Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>",
TextType='ssml',
OutputFormat='mp3',
VoiceId='Matthew'
)
# Save the audio file
with open('speech_ssml.mp3', 'wb') as file:
file.write(response['AudioStream'].read())This example emphasizes the word "Important" to make it stand out in the spoken message, enhancing the emotional impact on the listener. SSML also supports advanced features like phoneme pronunciation, whispering, and adding sound effects, giving developers full control over the voice experience.
Speech marks provide time-aligned metadata, enabling developers to synchronize speech with animations, text highlighting, or character lip movements.
This feature is especially valuable for interactive applications such as virtual characters, educational games, or karaoke-style text highlighting.
By requesting speech marks alongside speech synthesis, you get detailed timing information for each word or sentence, allowing you to create dynamic, synchronized multimedia experiences.
For example, you can animate a character’s mouth movements in sync with the spoken words or highlight text in real time as it is narrated. Here’s how to request speech marks:
response = polly.synthesize_speech(
Text='Hello, world!',
OutputFormat='json',
VoiceId='Emma',
SpeechMarkTypes=['word']
)
# Save the speech marks to a JSON file
with open('speech_marks.json', 'wb') as file:
file.write(response['AudioStream'].read())Output JSON:
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"}
{"time":714,"type":"word","start":7,"end":12,"value":"world"}The above example requests speech marks for each word, returning a JSON object with timestamps and text data. Developers can then use this information to synchronize animations frame-by-frame, making the audio-visual experience more engaging and realistic.
For real-time applications like voice assistants, live commentary, or interactive chatbots, Amazon Polly supports streaming using the WebSocket protocol or media players that support HLS (HTTP Live Streaming).
This allows applications to start playing audio as it is being synthesized, reducing latency and creating a more responsive user experience. Real-time streaming is ideal for scenarios where immediacy is critical, such as live customer support or conversational AI.
Developers can leverage this feature to build voice-activated devices, newsreaders, or interactive storytelling applications that respond to user input on the fly.
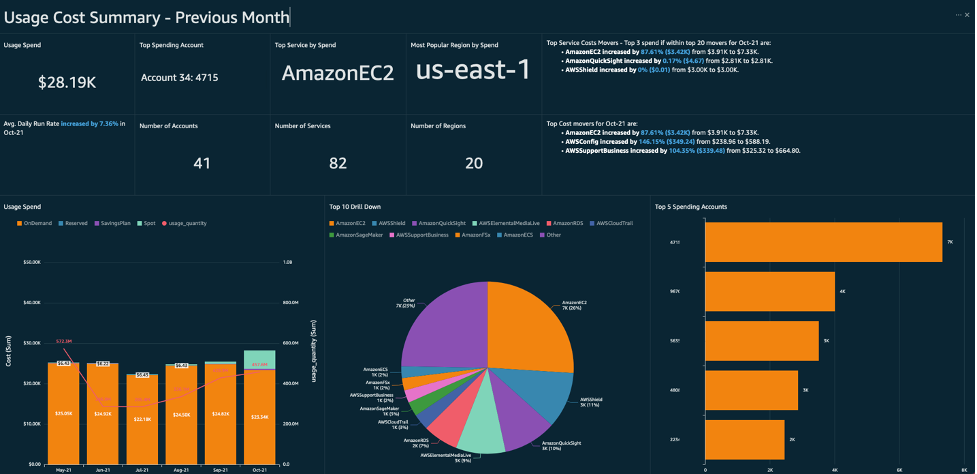
Effective management of Amazon Polly resources is crucial for optimizing performance, cost, and scalability. By strategically storing speech files and monitoring usage, you can ensure efficient resource utilization while maintaining a high-quality user experience.
Amazon Polly integrates seamlessly with other AWS services, such as Amazon S3 for storage and the AWS Billing Dashboard for cost monitoring, making resource management easier.
Amazon Polly allows you to store synthesized speech in Amazon S3 for scalable storage and easy retrieval. This approach is especially useful for applications with recurring audio requirements, such as e-learning platforms, audiobooks, or customer support bots, where you can reuse audio files instead of synthesizing speech each time.
By storing frequently used speech outputs in S3, you can reduce costs and improve performance by serving cached audio files directly from the cloud.
s3 = boto3.client('s3')
s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')Leverage the AWS Billing and Cost Management Dashboard to efficiently monitor usage and costs. This dashboard provides detailed cost breakdowns, usage reports, and the ability to set up budgets and alerts to avoid unexpected charges.
Monitoring costs is particularly important when using neural voices, which are more expensive than standard voices. You can also track usage metrics like the number of characters synthesized and the frequency of API calls, which can help you optimize resource utilization.
Example of an AWS costs dashboard.
When using Amazon Polly, adopting best practices ensures optimal performance, cost-efficiency, and user experience. Here are some key guidelines:
Choosing the right voice depends on the application’s purpose and target audience. Amazon Polly offers a variety of voices, including standard and neural voices, each with unique tones and characteristics.
Leverage SSML (Speech Synthesis Markup Language) to enhance speech quality by adjusting pitch, rate, and volume parameters. You can create a more dynamic and engaging audio experience by fine-tuning these settings.
For instance, slowing down the speaking rate improves clarity for instructional content while emphasizing key phrases enhances storytelling. Experimenting with different SSML tags helps you achieve the most natural-sounding speech.
Strategies such as managing the frequency of speech generation and storing frequently used audio files in S3 for reuse should be considered to optimize costs when using Amazon Polly. This approach minimizes repetitive API calls and reduces synthesis costs.
Additionally, strategically using a mix of standard and neural voices can balance cost and quality.
For example, use neural voices only for critical touchpoints like welcome messages, while standard voices handle informational content. Setting up usage limits and cost alerts in the AWS Billing Dashboard helps maintain budget control and avoid unexpected expenses.
Amazon Polly is a powerful text-to-speech service that leverages advanced deep learning technologies to convert text into lifelike speech, enhancing user experiences and accessibility.
Throughout this tutorial, we explored the fundamental features of Amazon Polly, from setting up the AWS SDK to generating speech programmatically. We also covered advanced capabilities, such as using SSML for customized speech output, leveraging Speech Marks for lip-syncing and animations, and implementing real-time streaming for dynamic voice applications.
Integrating Amazon Polly into your applications allows you to create highly interactive and personalized voice experiences that cater to a global audience. Whether you're building virtual assistants, audiobooks, educational platforms, or accessibility tools, Amazon Polly provides the flexibility, scalability, and advanced features needed to bring your ideas to life.
If you're new to AWS and want to strengthen your cloud skills, consider exploring these related courses:
Learn more about AWS with these courses!
Track
Course
Course
blog
Thalia Barrera
15 min
Tutorial
Kurtis Pykes
Tutorial
Arun Nanda
Tutorial
Zoumana Keita
Tutorial
Rahul Sharma
Tutorial
Kenny Ang
