
Kurs
Konzeptuelle Grundlagen von AWS
2 Std.
47.2K
Die Verwaltung der Cloud-Infrastruktur mit rohen JSON- oder YAML-Vorlagen kann mühsam und fehleranfällig sein. Das AWS Cloud Development Kit (CDK) ändert das, indem es dir ermöglicht, Cloud-Ressourcen mit modernen Programmiersprachen wie Python, TypeScript, Java und C# zu definieren.
Mit CDK wird die Infrastruktur zu wiederverwendbarem, testbarem und versionskontrolliertem Code. Sie ermöglicht es dir, auch bei der Bereitstellung komplexer Cloud-Systeme wie ein Entwickler zu denken.
In diesem Lernprogramm lernst du, wie du ein AWS CDK-Projekt mit Python einrichtest. Wir gehen durch den Prozess, wie du deinen ersten Stack schreibst, eine wichtige AWS-Ressource hinzufügst und ihn in deinem AWS-Konto bereitstellst. Am Ende wirst du genau verstehen, wie CDK funktioniert und wie du es nutzen kannst, um die Infrastruktur auf eine entwicklerfreundliche Art und Weise mit Code zu verwalten.
Um die Praktiken hinter Tools wie AWS CDK besser zu verstehen, solltest du die grundlegenden Prinzipien in unserem Kurs DevOps-Konzepte kennenlernen.
Bevor wir mit dem Schreiben von Code mit AWS CDK beginnen, solltest du sicherstellen, dass deine Umgebung richtig eingerichtet ist. Das wirst du brauchen:
Du brauchst Zugang zu einem AWS-Konto, um die Anwendung, die wir erstellen werden, bereitzustellen. Wenn dein System bereits mit den Anmeldeinformationen für einen Administrator konfiguriert ist, kannst du den Schritt überspringen.
Wenn dunoch kein AWS-Konto hast, kannst du es hier erstellen.
Für einen strukturierten Lernpfad, der die AWS-Grundlagen abdeckt, ist der AWS Cloud Practitioner Track ein hervorragender Einstieg.
Du brauchst einen Benutzer mit programmatischem Zugriff und vollen Rechten, um mitzumachen.
Auf dem letzten Bildschirm notierst du dir deine Zugangsschlüssel-ID und deinen geheimen Zugangsschlüssel. Du brauchst sie im nächsten Schritt.
Öffne ein Terminal und führe es aus:
aws configureDu wirst aufgefordert, die Anmeldedaten von der IAM-Konsole einzugeben:
AWS Access Key ID [None]: <your access key ID>
AWS Secret Access Key [None]: <your secret access key>
Default region name [None]: us-east-1
Default output format [None]: Das AWS CDK ermöglicht es Entwicklern, in einer vollständigen Programmierumgebung zu arbeiten, anstatt mit YAML- oder JSON-Vorlagen. Mit dieser voll ausgestatteten Umgebung kannst du deine bevorzugte IDE verwenden und gleichzeitig von Code-Vervollständigungsfunktionen, Echtzeit-Linting und Refactoring-Tools für ein effizientes Infrastruktur-Code-Management profitieren.
Um die beste Entwicklungserfahrung mit dem Python CDK zu machen, empfehle ich, eine IDE zu verwenden, die Folgendes unterstützt:
Um AWS CDK mit Python zu verwenden, musst du Python in der Version 3.8 oder höher auf deinem System installiert haben. Wenn du sie noch nicht hast, kannst du die neueste Version von der offiziellen Python-Website herunterladen.
Unter Windows musst du sicherstellen, dass Python in der Umgebungsvariablen PATH eingetragen ist. Um das zu überprüfen, öffne ein Terminal oder eine Eingabeaufforderung und führe aus:
python --versionWenn du einen "Befehl nicht gefunden" oder eine ähnliche Fehlermeldung siehst, ist Python wahrscheinlich nicht auf deiner PATH. Die einfachste Lösung ist, während der Installation das Kästchen "Python 3.x zu PATH hinzufügen" zu aktivieren.
Außerdem brauchst du pip, das Python-Paketinstallationsprogramm, um später die AWS CDK-Abhängigkeiten zu installieren. Bei den meisten modernen Python-Distributionen ist pip bereits vorinstalliert.
pip --versionWenn sie nicht installiert ist, folge der offiziellen Pip-Installationsanleitung.
Bevor wir Code schreiben, ist es wichtig zu verstehen, was AWS CDK ist, warum es existiert und wie es in die Welt von Infrastructure as Code (IaC) passt. In diesem Abschnitt lernst du die Kernkonzepte von CDK kennen und erfährst, wie es im Vergleich zu anderen gängigen IaC-Tools funktioniert.
Das AWS Cloud Development Kit (CDK) ist ein Open-Source-Framework, das es Nutzern ermöglicht, Cloud-Infrastrukturen mit vertrauten Programmiersprachen wie Python, TypeScript, Java und C# zu erstellen.
Das CDK ermöglicht es Nutzern, CloudFormation-Vorlagen programmatisch durch aktuellen Code zu generieren, anstatt JSON- oder YAML-Vorlagen manuell schreiben zu müssen.
Das heißt, du kannst:
Im Kern geht es bei der CDK um drei Hauptkonzepte:
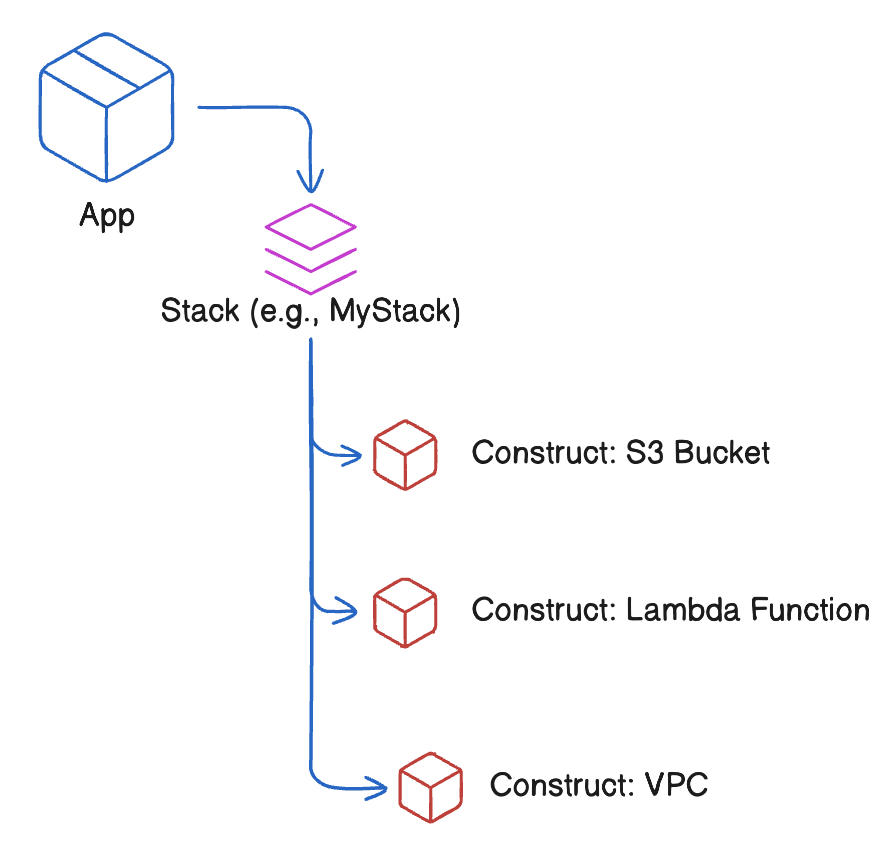
Visuelle Hierarchie einer AWS CDK App
Die folgende Tabelle beschreibt die Unterschiede zwischen den in AWS verfügbaren Tools zur Verwaltung der Infrastruktur.
|
Feature |
AWS CDK |
Terraform |
AWS CloudFormation |
|
Sprachunterstützung |
Python, TypeScript, Java, C# |
HCL (deklarativ) |
YAML / JSON |
|
Abstraktionsebene |
Hoch (OOP + Bibliotheken) |
Medium |
Niedrig |
|
Modularität |
Stark (Konstrukte, Klassen) |
Stark (Module) |
Schwach (verschachtelte Stapel) |
|
Staatliches Management |
Verwaltet von CloudFormation |
Wird von Terraform (tfstate) verwaltet |
Verwaltet von CloudFormation |
|
Multi-cloud |
Nur AWS |
Ja |
Nur AWS |
Das AWS CDK unterstützt mehrere Programmiersprachen, so dass die Entwickler die Sprache wählen können, mit der sie am besten zurechtkommen:
In diesem Lernprogramm konzentrieren wir uns auf Python, aber die grundlegenden Konzepte gelten für alle unterstützten Sprachen.
Jetzt, wo deine Umgebung bereit ist, kannst du Python verwenden, um deine erste AWS CDK-App zu erstellen. Der Befehl CDK init richtet die gesamte Projektstruktur ein, einschließlich Dateien, Verzeichnissen und einer virtuellen Umgebung, damit du schnell loslegen kannst.
Öffne dein Terminal und führe den folgenden Befehl aus, um ein neues Verzeichnis zu erstellen und dorthin zu navigieren:
mkdir cdk_datacamp && cd cdk_datacampcdk init sample-app --language pythonDadurch wird ein Starterprojekt mit einem grundlegenden Beispiel erstellt, das Folgendes enthält:
cdk_datacamp_stack)cdk.json Datei, die konfiguriert, wie deine CDK-App läuft.venv) für Python-AbhängigkeitenWenn der Befehl abgeschlossen ist, siehst du eine ähnliche Ausgabe wie diese:

CDK Python Projektgerüst
Einrichtung der virtuellen Umgebung
Wenn der cdk init Prozess nicht automatisch eine virtuelle Umgebung erstellt, kannst du dies manuell tun:
python3 -m venv .venv
source .venv/bin/activateNach der Aktivierung installierst du die erforderlichen Abhängigkeiten:
pip install -r requirements.txtBevor wir tiefer in den Code eintauchen, wollen wir uns ansehen, wie die Kernkomponenten von AWS CDK - Apps, Stacks und Konstrukte - in der Praxis zusammenarbeiten. Jetzt, wo du weißt, wofür die einzelnen Elemente stehen, ist es wichtig zu sehen, wie sie zusammenwirken, um eine skalierbare, modulare Infrastruktur zu bilden.
Wir werden auch die verschiedenen Ebenen der Konstrukte (L1, L2, L3) aufschlüsseln und die CDK-Bibliotheken untersuchen, die dies möglich machen.
Da du nun weißt, was App, Stack und Construct aus den vorherigen Abschnitten sind, wollen wir nun verstehen, wie sie in einer CDK-Anwendung zusammenarbeiten.
Stell dir das so vor, als würdest du ein Haus bauen:
Im Code sieht die Beziehung folgendermaßen aus:
# app.py
from aws_cdk import App
from my_project.my_stack import MyStack
# Initialize the CDK application
app = App()
# Instantiate the stack and add it to the app
MyStack(app, "MyFirstStack")
# Synthesize the CloudFormation template
app.synth()# my_stack.py
from aws_cdk import Stack
from aws_cdk import aws_s3 as s3
from constructs import Construct
class MyStack(Stack):
def __init__(self, scope: Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
# Define an Amazon S3 bucket with default settings
s3.Bucket(self, "MyBucket")Hier instanziiert die App einen Stack, der Konstrukte wie einen S3-Bucket enthält.
In AWS CDK gibt es Konstrukte in drei Abstraktionsebenen, die dir Flexibilität bieten, je nachdem wie viel Kontrolle oder Einfachheit du brauchst.
Level 1 (L1) – CloudFormation Constructs
Dies sind die Rohbausteine, die direkt aus der AWS CloudFormation-Spezifikation generiert werden. Jede AWS-Ressource in CloudFormation hat ein entsprechendes L1-Konstrukt in CDK; ihre Namen beginnen immer mit "Cfn".
L1-Konstrukte stellen alle möglichen Konfigurationsoptionen zur Verfügung, bieten aber keine Abstraktionen oder Voreinstellungen. Sie sind ideal, wenn du die volle Kontrolle brauchst oder neuere AWS-Funktionen verwendest, die noch nicht durch übergeordnete Konstrukte abgedeckt sind.
s3.CfnBucketLevel 2 (L2) - AWS CDK-native Konstrukte
L2-Konstrukte bieten eine höhere, entwicklerfreundliche Abstraktion als L1-Konstrukte. Das sind eigenwillige Komponenten mit sinnvollen Voreinstellungen und eingebauten Methoden, die alltägliche Aufgaben vereinfachen. Sie sind für den täglichen Gebrauch konzipiert und helfen dabei, Standardformulierungen zu reduzieren, während sie gleichzeitig ein hohes Maß an Anpassungsmöglichkeiten bieten.
s3.Bucket - Du kannst einen versionierten Bucket mit nur einer Zeile Code erstellen.Stufe 3 (L3) - Musterkonstruktionen
L3-Konstrukte sind Abstraktionen, die mehrere AWS-Ressourcen in gemeinsamen Architekturmustern bündeln. Sie können von AWS bereitgestellt oder als wiederverwendbare Komponenten von der Community oder von dir gebaut werden. Nutze L3-Konstrukte, um Komplexität zu kapseln und Infrastrukturmuster projekt- oder teamübergreifend wiederzuverwenden.
aws_s3_deployment.BucketDeployment - Kombiniert einen S3-Bucket und eine Bereitstellungsstrategie, um das Hochladen von Assets zu automatisieren.Die meisten Entwickler beginnen mit L2-Konstrukten und führen L1 nur bei Bedarf ein. L3 wird praktisch, wenn dein Projekt wächst und du wiederkehrende Muster in wiederverwendbare Komponenten abstrahieren willst.
Wenn du mit AWS CDK baust, interagierst du nicht direkt mit CloudFormation. Stattdessen verwendest du die modularen Bibliotheken von CDK, die Konstrukte für AWS-Services wie S3, Lambda, IAM und mehr bieten. Alle AWS-Servicemodule werden unter dem Kernpaket aws-cdk-lib gebündelt und sind weiter nach Services gegliedert.
Im Folgenden findest du einige der am häufigsten verwendeten Bibliotheken (oder Module) von aws-cdk-lib in Python-Projekten:
aws_cdk.aws_s3 - Zum Erstellen von S3-Bucketsaws_cdk.aws_lambda - Zur Definition von Lambda-Funktionenaws_cdk.aws_iam - Zur Verwaltung von Rollen und Berechtigungenaws_cdk.aws_dynamodb - Für die Arbeit mit DynamoDB-Tabellenaws_cdk.aws_ec2 - Für Netzwerkkomponenten wie VPCs und Sicherheitsgruppenaws_cdk.aws_sns / aws_cdk.aws_sns_subscriptions - Für SNS-Themen und ihre AbonnentenDiese Module werden nur bei Bedarf importiert, damit dein Projekt schlank und modular bleibt.
Um einen bestimmten AWS-Service zu nutzen, importierst du sein Modul und rufst seine Konstruktionsklassen auf. Zum Beispiel, um einen S3-Bucket zu erstellen:
from aws_cdk import aws_s3 as s3
# Inside your stack
bucket = s3.Bucket(self, "MyBucket")In diesem Beispiel wird das L2-Konstrukt s3.Bucket verwendet, das eingebaute Voreinstellungen wie Verschlüsselungs- und Versionierungsoptionen enthält.
Wenn du einen anderen Dienst nutzen willst, importiere einfach dessen Modul auf die gleiche Weise:
from aws_cdk import aws_lambda as lambda_
from aws_cdk import aws_iam as iamHinweis: In deinem requirements.txt brauchst du normalerweise nur:
aws-cdk-lib==2.179.0
constructs>=10.0.0,<11.0.0Diese beiden Pakete geben dir Zugriff auf alle AWS CDK-Konstrukte und die Kernfunktionen des Frameworks.
Nachdem du die internen Abläufe von AWS CDK kennengelernt hast, kannst du dieses Wissen umsetzen. Der folgende Abschnitt führt dich durch den Aufbau eines einsatzfähigen CDK-Stacks mit Python. Bevor du sie in deinem AWS-Konto bereitstellst, erstellst du eine Projektstruktur durch Code und implementierst tatsächliche AWS-Ressourcen, wie S3-Buckets und Lambda-Funktionen.
Wenn du den Befehl cdk init mit dem Flag --language python ausführst, wird eine vollständige Projektstruktur erstellt, die in etwa so aussieht:

Ordnerstruktur eines AWS CDK Python Projekts
In der Datei app.py wird die App definiert, und in der Datei cdk_datacamp_stack.py schreibst du den Code für deinen Stack und deine Konstrukte.
Tipp: Du kannst die Stack-Datei oder -Klasse umbenennen, damit sie dem Zweck deiner App entspricht, z. B. storage_stack.py oder monitoring_stack.py.
Fügen wir nun einige AWS-Ressourcen zu deinem CDK-Stack hinzu. Das schreibst du in die Methode __init__() deiner Klasse Stack in der Datei cdk_datacamp_stack.py.
S3-Eimer
from aws_cdk import aws_s3 as s3
# Create an S3 bucket with versioning and managed encryption
bucket = s3.Bucket(
self,
"MyBucket",
versioned=True,
encryption=s3.BucketEncryption.S3_MANAGED
)Lambda-Funktion
from aws_cdk import aws_lambda as lambda_
# Define a Lambda function using Python 3.9 runtime
lambda_function = lambda_.Function(
self,
"MyFunction",
runtime=lambda_.Runtime.PYTHON_3_9,
handler="index.handler",
code=lambda_.Code.from_asset("lambda") # Load code from local folder named 'lambda'
)Sobald du deine Ressourcen hinzugefügt hast, ist es an der Zeit, sie in AWS bereitzustellen.
Aktiviere in deinem Terminal deine virtuelle Umgebung und führe sie aus:
cdk deployDas wird:
Wenn du den Stack zum ersten Mal bereitstellst, wirst du aufgefordert, die Änderungen zu genehmigen.
Nach dem Einsatz kannst du:
AWS CDK-Anwendungen beruhen auf Konstrukten als ihren wesentlichen Strukturelementen. Dein Infrastrukturcode wird modularer, wartbarer und lesbarer, wenn du die Konstrukte beherrschst, egal ob du eingebaute Service-Konstrukte verwendest oder eigene wiederverwendbare Muster erstellst.
In diesem Abschnitt lernst du, wie du L2-Konstrukte (High-Level-Konstrukte) verwendest und benutzerdefinierte Konstrukte entwickelst, die sich wiederholende Muster reduzieren.
L2-Konstrukte sind CDK-native Abstraktionen, die einfacher zu verwenden sind als die rohe CloudFormation (L1). Sie haben sinnvolle Standardeinstellungen und Typsicherheit und benötigen oft weniger Codezeilen, um eine AWS-Ressource einzurichten.
Warum L2-Konstruktionen verwenden?
.add_to_role_policy() oder .add_event_notification()Beispiel: Erstellen eines S3-Buckets mit L2
from aws_cdk import aws_s3 as s3
# Create a versioned and encrypted S3 bucket
bucket = s3.Bucket(
self,
"MyBucket",
versioned=True,
encryption=s3.BucketEncryption.S3_MANAGED
)Für das entsprechende L1-Konstrukt s3.CfnBucket müssten alle Eigenschaften manuell festgelegt und die Konfiguration als rohe Dict definiert werden - das ist viel weniger intuitiv.
Andere gängige L2-Konstrukte sind:
lambda_.Function() für AWS Lambdadynamodb.Table() für DynamoDBsqs.Queue() für SQSsns.Topic() für SNSDeine Infrastruktur wird mit wiederkehrenden Mustern erweitert, wie z.B. dem Erstellen von Lambda-Funktionen mit bestimmten Berechtigungen und S3-Buckets. Benutzerdefinierte Konstrukte sind die ideale Lösung für dieses spezielle Szenario.
Mit benutzerdefinierten Konstrukten kannst du verwandte Ressourcen zu einer einzigen logischen Einheit zusammenfassen, die über Stapel oder Projekte hinweg wiederverwendet werden kann.
Wann du ein benutzerdefiniertes Konstrukt erstellen solltest:
Beispiel: Ein wiederverwendbares S3 + Lambda Muster
from constructs import Construct
from aws_cdk import aws_s3 as s3, aws_lambda as lambda_
class StorageWithLambda(Construct):
def __init__(self, scope: Construct, id: str) -> None:
super().__init__(scope, id)
# S3 bucket
self.bucket = s3.Bucket(self, "MyBucket")
# Lambda function
self.function = lambda_.Function(
self,
"MyFunction",
runtime=lambda_.Runtime.PYTHON_3_9,
handler="index.handler",
code=lambda_.Code.from_asset("lambda")
)
# Grant Lambda access to the S3 bucket
self.bucket.grant_read_write(self.function)Du kannst dieses Konstrukt jetzt in jedem Stapel wie folgt verwenden:
from my_project.storage_with_lambda import StorageWithLambda
storage = StorageWithLambda(self, "ReusableComponent")Bevor du die obigen Schritte ausführst, erstelle einen Ordner namens lambda im Stammverzeichnis des Projekts und erstelle eine Datei index.py mit dem folgenden Inhalt:
def handler(event, context):
return {
"statusCode": 200,
"body": "Hello from Lambda!"
}Tipps zur Wiederverwendbarkeit
construct_ vor die Dateien oder platziere sie in einem constructs/ Ordner.self.bucket oder self.function für mehr Flexibilität freiNachdem du deinen Infrastrukturcode geschrieben hast, ist es wichtig zu prüfen, was das CDK bereitstellen wird und idealerweise zu testen, ob sich deine Stacks wie erwartet verhalten. Das AWS CDK bietet Tools, um CloudFormation-Vorlagen zu synthetisieren und automatisierte Tests zu schreiben, um Fehlkonfigurationen vor der Bereitstellung zu erkennen.
Der Befehl cdk synth generiert die CloudFormation-Vorlage aus deinem CDK-Code.
cdk synthWenn du dies ausführst, wird die CDK:
app.py)
Synthetisierte CloudFormation-Vorlage
Standardmäßig geht die Ausgabe in dein Terminal, aber du kannst sie bei Bedarf auch in eine Datei ausgeben:
cdk synth > template.yamlDies ist nützlich, wenn:
Obwohl das Testen der Infrastruktur als Code ungewöhnlich klingen mag, ist es von Vorteil, vor allem, wenn deine Stacks groß werden oder bedingte Logik, Schleifen oder wiederverwendbare Konstrukte enthalten.
Das AWS CDK bietet das Assertions-Modul, um synthetisierte Stacks zu testen.
Einen einfachen Test schreiben mit pytest
Hier ist ein Beispieltest, der überprüft, ob eine bestimmte Ressource (wie ein S3-Bucket) im Stack enthalten ist:
# test/test_cdk_datacamp_stack.py
import aws_cdk as cdk
from aws_cdk.assertions import Template
from cdk_datacamp.cdk_datacamp_stack import CdkDatacampStack
def test_s3_bucket_created():
app = cdk.App()
stack = CdkDatacampStack(app, "TestStack")
template = Template.from_stack(stack)
# Assert that an S3 bucket exists
template.resource_count_is("AWS::S3::Bucket", 1)Um die Tests durchzuführen, stelle sicher, dass pytest installiert ist:
pip install -U pytestDann lauf:
pytestWenn alles in Ordnung ist, siehst du ein grünes Häkchen. Wenn nicht, wird dir die Testausgabe sagen, was fehlt.

Die Pytest-Ausgabe zeigt die erfolgreiche Ausführung aller Testfälle für den AWS CDK-Stack
Du kannst die Validierung auch in deinen CDK-Stack aufnehmen. Validierungstests sind Laufzeitprüfungen innerhalb deines Konstrukt- oder Stack-Codes, die Eingaben validieren, bevor die Bereitstellung erfolgt. Sie helfen dabei, Fehlkonfigurationen aufzuspüren oder Beschränkungen frühzeitig im Entwicklungszyklus durchzusetzen.
Nehmen wir an, wir wollen die bucket_name als Kontextvariable übergeben, aber wir wollen das validieren:
Erstelle eine Datei namens test/test_storage_with_lambda.py und füge Folgendes hinzu:
import pytest
from aws_cdk import App, Stack
from cdk_datacamp.storage_with_lambda import StorageWithLambda
def test_missing_bucket_name():
app = App()
stack = Stack(app, "TestStack")
with pytest.raises(ValueError, match="bucket_name is required"):
StorageWithLambda(stack, "FailingConstruct", bucket_name=None)
def test_bucket_name_uppercase():
app = App()
stack = Stack(app, "TestStack")
with pytest.raises(ValueError, match="must be lowercase"):
StorageWithLambda(stack, "FailingConstruct", bucket_name="InvalidName")Um die Validierung zu testen, führe den folgenden Befehl aus:
test/test_storage_with_lambda.py
Die Pytest-Ausgabe zeigt die erfolgreiche Ausführung aller Testfälle für den AWS CDK-Stack
Wann du Tests durchführen solltest:
Willst du dein CDK-Wissen in einem Vorstellungsgespräch auffrischen? Diese Top AWS DevOps-Interview-Fragen können dir bei der Vorbereitung helfen.
Nachdem du die Erstellung und den Einsatz des CDK-Stacks gemeistert hast, solltest du Best Practices befolgen, um deinen Infrastrukturcode sauber, sicher und skalierbar zu halten. In diesem Abschnitt wird erörtert, wie man große Projekte strukturiert, die Sicherheit richtig handhabt und CDK in CI/CD-Pipelines integriert.
Wenn deine CDK-Anwendung wächst, ist es wichtig, den Code in überschaubaren Einheiten zu organisieren.
Teile deine Infrastruktur nach Anliegen auf. Zum Beispiel:
So kannst du Teile deiner Infrastruktur unabhängig voneinander einsetzen, testen oder zerstören. So kann sie in app.py eingebunden werden:
network_stack = NetworkingStack(app, "NetworkingStack")
compute_stack = ComputeStack(app, "ComputeStack")Du kannst auch Ressourcen zwischen Stapeln mit Hilfe von Ausgängen oder Referenzen übergeben.
Kapseln Sie zusammenhängende Ressourcen (wie ein Lambda und seine Berechtigungen) in einem benutzerdefinierten Konstrukt, wie Sie es mit StorageWithLambda getan haben. Das verbessert die Lesbarkeit und Wiederverwendbarkeit über Stacks oder Apps hinweg.
Unterstütze mehrere Umgebungen (Dev, Staging, Prod) mit:
cdk.json mit Kontextwertencdk deploy -c env=prodenv = app.node.try_get_context("env")
if env == "prod":
bucket_name = "mycompany-prod-logs"Jedes Infrastrukturprojekt muss der Sicherheit während der automatisierten Bereitstellungsprozesse von AWS CDK Priorität einräumen. Der folgende Abschnitt demonstriert die sichere IAM-Ressourcenverwaltung durch die Prinzipien der geringsten Privilegien.
CDK-Konstrukte, die Lambda- oder ECS-Aufgaben enthalten, erstellen automatisch IAM-Rollen. Das ist zwar praktisch, aber es kann deine Kontrolle über Berechtigungen und Namensgebung einschränken.
Definiere stattdessen explizit Rollen:
from aws_cdk import aws_iam as iam
execution_role = iam.Role(
self,
"LambdaExecutionRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com"),
description="Custom role for Lambda with least privilege",
managed_policies=[
iam.ManagedPolicy.from_aws_managed_policy_name("service-role/AWSLambdaBasicExecutionRole")
]
)Diese Rolle erlaubt standardmäßig nur die Protokollierung und nichts anderes.
Vermeide es, "*" in actions oder resources zu verwenden, wenn es nicht unbedingt notwendig ist.
Beispiel:
lambda_fn.add_to_role_policy(
iam.PolicyStatement(
actions=["*"],
resources=["*"]
)
)Du kannst auch ressourcenspezifische Zuschüsse nutzen, wenn sie verfügbar sind:
bucket.grant_read(lambda_fn)Dadurch wird automatisch die notwendige Richtlinie mit beschränktem Zugriff auf den S3-Bucket erstellt.
Von AWS verwaltete Richtlinien vereinfachen die Wartung und verringern das Risiko von Fehlern.
iam.ManagedPolicy.from_aws_managed_policy_name("AmazonSQSReadOnlyAccess")Du kannst sie mit benutzerdefinierten Rollen für Dienste wie ECS, Batch oder Step Functions verknüpfen.
Das AWS CDK ist besonders leistungsstark, da es sich in moderne CI/CD-Pipelines integrieren lässt. CDK unterstützt die automatisierte Bereitstellung der Infrastruktur durch versionsgesteuerte Codebereitstellung, die mit GitHub, GitLab und AWS-nativen Diensten, einschließlich CodePipeline, funktioniert. Das System verringert menschliche Fehler, verkürzt die Feedback-Zyklen und ermöglicht den Einsatz in verschiedenen Umgebungen.
Du kannst GitHub Actions nutzen, um CDK-Stacks bei jedem Push- oder Pull-Request zu synthetisieren, zu diffundieren, zu testen und einzusetzen.
Sieh dir das an .github/workflows/deploy.yml:
name: Deploy CDK App
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
with:
python-version: 3.11
- name: Install dependencies
run: |
pip install -r requirements.txt
npm install -g aws-cdk
- name: Run unit tests
run: pytest
- name: CDK Synth
run: cdk synth -c environment=prod
- name: Deploy to AWS
run: cdk deploy --require-approval never
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}Verwende cdk diff in PRs, um infra-Änderungen vor dem Zusammenführen anzuzeigen.
Für vollständig verwaltete Bereitstellungen innerhalb von AWS bietet CDK ein Modul namens aws_cdk.pipelines, mit dem du deine gesamte CI/CD-Pipeline als Code definieren kannst, genau wie die Infrastruktur.
Hier ist ein vereinfachtes Beispiel:
from aws_cdk import pipelines, SecretValue, Stack
from constructs import Construct
from my_app_stage import MyAppStage # replace with your actual stage import
class PipelineStack(Stack):
def __init__(
self,
scope: Construct,
construct_id: str,
**kwargs
) -> None:
super().__init__(scope, construct_id, **kwargs)
# Define the source of the pipeline from a GitHub repository
source = pipelines.CodePipelineSource.git_hub(
repo_string="your-org/your-repo", # GitHub org/repo
branch="main",
authentication=SecretValue.secrets_manager("GITHUB_TOKEN")
)
# Define the CodePipeline and its synthesis step
pipeline = pipelines.CodePipeline(
self,
"MyAppPipeline",
synth=pipelines.ShellStep(
"Synth",
input=source,
commands=[
"pip install -r requirements.txt",
"npm install -g aws-cdk",
"cdk synth"
]
)
)
# Add an application stage (e.g., production deployment)
pipeline.add_stage(
MyAppStage(self, "ProdStage")
)Im obigen Code:
SecretValue.secrets_manager("GITHUB_TOKEN") holt dein GitHub-Token sicher aus dem Secrets Manager.MyAppStage sollte eine Klasse sein, die Stage erweitert und deine eigentlichen CDK-Stapel umhüllt.Wenn du Systeme für maschinelles Lernen bereitstellst, wird die Integration von CDK mit kontinuierlichen Bereitstellungspraktiken in unserem Kurs CI/CD für maschinelles Lernen behandelt.
In diesem Lernprogramm hast du gelernt, wie du mit dem AWS Cloud Development Kit (CDK) eine Cloud-Infrastruktur in Python aufbaust und bereitstellst. Du hast gelernt, wie es geht:
Jetzt, wo du deine erste CDK-App eingesetzt hast, gibt es ein paar Möglichkeiten, dich weiterzuentwickeln:
aws_s3_deployment, aws_ecs_patterns, und cdk.pipelinesUm weiter zu lernen und zu bauen, schauden Kurs Einführung in AWS Boto in Python an!
Lerne mehr über AWS mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
