
Course
AWS Concepts
2 hr
47.5K
Managing cloud infrastructure with raw JSON or YAML templates can be tedious and error-prone. The AWS Cloud Development Kit (CDK) changes that by allowing you to define cloud resources using modern programming languages such as Python, TypeScript, Java, and C#.
With CDK, infrastructure becomes code reusable, testable, and version-controlled. It enables you to think like a developer even when provisioning complex cloud systems.
In this tutorial, you'll learn how to set up an AWS CDK project using Python. We'll walk through the process of writing your first stack, adding an essential AWS resource, and deploying it to your AWS account. By the end, you'll clearly understand how CDK works and how to use it to manage infrastructure in a developer-friendly way, with code.
To better understand the practices behind tools like AWS CDK, explore the foundational principles in our DevOps Concepts course.
Before we dive into writing code with AWS CDK, make sure your environment is set up correctly. Here’s what you’ll need:
You need access to an AWS account to deploy the application we'll build. If your system is already configured with credentials for an administrator-level user, feel free to skip ahead.
If you don’t have an AWS account yet, create one here.
For a structured learning path covering AWS fundamentals, the AWS Cloud Practitioner track is an excellent place to start.
You’ll need a user with programmatic access and full permissions to follow along.
On the final screen, note down your Access key ID and Secret access key. You’ll need these in the next step.
Open a terminal and run:
aws configureYou'll be prompted to enter the credentials from the IAM console:
AWS Access Key ID [None]: <your access key ID>
AWS Secret Access Key [None]: <your secret access key>
Default region name [None]: us-east-1
Default output format [None]: The AWS CDK allows developers to work within a complete programming environment instead of YAML or JSON templates. This full-featured environment allows you to use your preferred IDE while benefiting from code completion features, real-time linting, and refactoring tools for efficient infrastructure code management.
To achieve the best development experience with the Python CDK, I suggest using an IDE that supports the following:
To use AWS CDK with Python, you’ll need to have Python version 3.8 or higher installed on your system. If you don’t have it yet, you can download the latest version from the official Python website.
If you're on Windows, make sure Python is added to your system’s PATH environment variable. To check, open a terminal or command prompt and run:
python --versionIf you see a “command not found” or similar error, Python likely isn’t on your PATH. The easiest fix is to check the “Add Python 3.x to PATH” box during installation.
You'll also need pip, the Python package installer, to install AWS CDK dependencies later. Most modern Python distributions come with pip pre-installed.
pip --versionIf it’s not installed, follow the official pip installation guide.
Before we write any code, it’s essential to understand what AWS CDK is, why it exists, and how it fits into the broader world of infrastructure as code (IaC). This section will introduce you to the core concepts behind CDK and show how it compares to other popular IaC tools.
AWS Cloud Development Kit (CDK) is an open-source framework that enables users to create cloud infrastructure through familiar programming languages, including Python, TypeScript, Java, and C#.
The CDK allows users to generate CloudFormation templates programmatically through actual code instead of requiring manual JSON or YAML template writing.
This means you can:
At its core, the CDK revolves around three main concepts:
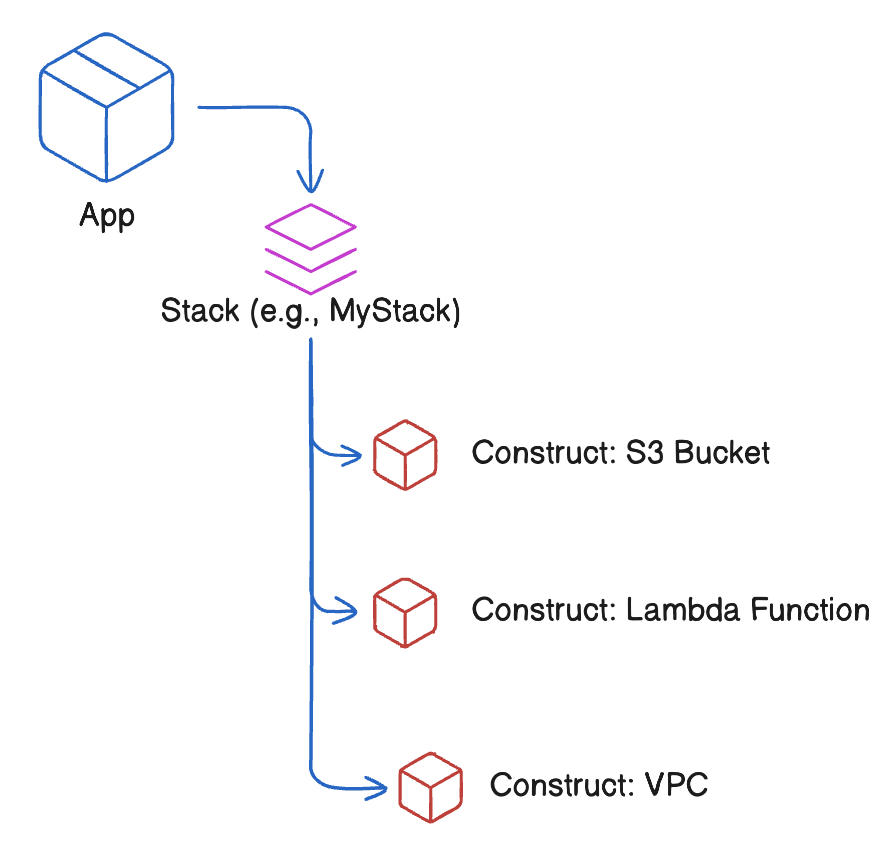
Visual hierarchy of an AWS CDK app
The following table describes the differences between the tools available in AWS to manage infrastructure.
|
Feature |
AWS CDK |
Terraform |
AWS CloudFormation |
|
Language Support |
Python, TypeScript, Java, C# |
HCL (declarative) |
YAML / JSON |
|
Abstraction Level |
High (OOP + libraries) |
Medium |
Low |
|
Modularity |
Strong (constructs, classes) |
Strong (modules) |
Weak (nested stacks) |
|
State Management |
Handled by CloudFormation |
Handled by Terraform (tfstate) |
Handled by CloudFormation |
|
Multi-cloud |
AWS only |
Yes |
AWS only |
The AWS CDK supports multiple programming languages, allowing developers to choose the one they're most comfortable with:
In this tutorial, we'll focus on Python, but the core concepts apply across all supported languages.
Now that your environment is ready, it’s time to use Python to scaffold your first AWS CDK app. The CDK init command sets up the entire project structure, including files, directories, and a virtual environment, to help you get started quickly.
Open your terminal and run the following command to create a new directory and navigate into it:
mkdir cdk_datacamp && cd cdk_datacampcdk init sample-app --language pythonThis creates a starter project pre-configured with a basic example that includes:
cdk_datacamp_stack)cdk.json file that configures how your CDK app runs.venv) for Python dependenciesWhen the command completes, you’ll see output similar to this:

CDK Python project scaffold
Virtual Environment Setup
If the cdk init process doesn't automatically create a virtual environment, you can do it manually:
python3 -m venv .venv
source .venv/bin/activateOnce activated, install the required dependencies:
pip install -r requirements.txtBefore diving deeper into code, let's explore how the core components of AWS CDK—apps, stacks, and constructs—work together in practice. Now that you're familiar with what each represents, it's essential to see how they interact to form a scalable, modular infrastructure.
We'll also break down the different levels of constructs (L1, L2, L3) and examine the CDK libraries that make this possible.
Now that you know what App, Stack, and Construct from the previous sections are, let’s understand how they work together in a CDK application.
Think of it like building a house:
In code, the relationship looks like this:
# app.py
from aws_cdk import App
from my_project.my_stack import MyStack
# Initialize the CDK application
app = App()
# Instantiate the stack and add it to the app
MyStack(app, "MyFirstStack")
# Synthesize the CloudFormation template
app.synth()# my_stack.py
from aws_cdk import Stack
from aws_cdk import aws_s3 as s3
from constructs import Construct
class MyStack(Stack):
def __init__(self, scope: Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
# Define an Amazon S3 bucket with default settings
s3.Bucket(self, "MyBucket")Here, the App instantiates a Stack, which includes Constructs like an S3 bucket.
In AWS CDK, constructs come in three levels of abstraction, giving you flexibility based on how much control or simplicity you need.
Level 1 (L1) – CloudFormation Constructs
These are the raw building blocks generated directly from the AWS CloudFormation specification. Every AWS resource in CloudFormation has an equivalent L1 construct in CDK; their names always start with “Cfn”.
L1 constructs expose every possible configuration option but offer no abstractions or defaults. They're ideal when you need complete control or use newer AWS features not yet wrapped by higher-level constructs.
s3.CfnBucketLevel 2 (L2) – AWS CDK-native Constructs
L2 constructs provide a higher-level, developer-friendly abstraction over L1 constructs. These are opinionated components with sensible defaults and built-in methods that simplify everyday tasks. They're designed for day-to-day use and help reduce boilerplate while still offering a good level of customization.
s3.Bucket – You can create a versioned bucket with just one line of code.Level 3 (L3) – Pattern Constructs
L3 constructs are abstractions that bundle multiple AWS resources into common architectural patterns. They can be provided by AWS or built as reusable components by the community or you. Use L3 constructs to encapsulate complexity and reuse infrastructure patterns across projects or teams.
aws_s3_deployment.BucketDeployment – Combines an S3 bucket and a deployment strategy to automate asset uploads.Most developers start with L2 constructs and introduce L1 only when needed. L3 becomes handy as your project grows and you want to abstract repeated patterns into reusable components.
You don't interact directly with raw CloudFormation when building with AWS CDK. Instead, you use CDK's modular libraries, which provide constructs for AWS services like S3, Lambda, IAM, and more. All AWS service modules are bundled under the core package called aws-cdk-lib, and these are further organized by service.
Below are some of the most frequently used libraries (or modules) from aws-cdk-lib in Python projects:
aws_cdk.aws_s3 – For creating S3 bucketsaws_cdk.aws_lambda – For defining Lambda functionsaws_cdk.aws_iam – For managing roles and permissionsaws_cdk.aws_dynamodb – For working with DynamoDB tablesaws_cdk.aws_ec2 – For networking components like VPCs and security groupsaws_cdk.aws_sns / aws_cdk.aws_sns_subscriptions – For SNS topics and their subscribersThese modules are imported only as needed, keeping your project lightweight and modular.
To use a specific AWS service, you import its module and call its construct classes. For example, to create an S3 bucket:
from aws_cdk import aws_s3 as s3
# Inside your stack
bucket = s3.Bucket(self, "MyBucket")This example uses the L2 construct s3.Bucket, which includes built-in defaults like encryption and versioning options.
If you need to use another service, just import its module in the same way:
from aws_cdk import aws_lambda as lambda_
from aws_cdk import aws_iam as iamNote: In your requirements.txt, you typically only need:
aws-cdk-lib==2.179.0
constructs>=10.0.0,<11.0.0These two packages give you access to all AWS CDK constructs and the core framework functionality.
After learning about AWS CDK internal operations, you can implement this knowledge. The following section guides you through building an operational CDK stack using Python. Before deploying them to your AWS account, you will create a project structure through code and implement actual AWS resources, such as S3 buckets and Lambda functions.
When you run the cdk init command with the --language python flag, it sets up a full project structure that looks something like this:

Folder structure of an AWS CDK Python project
The app.py file is where the App is defined, and the cdk_datacamp_stack.py file is where you write the code for your Stack and Constructs.
Tip: You can rename the stack file or class to match the purpose of your app, such as storage_stack.py or monitoring_stack.py.
Now let’s add some AWS resources to your CDK stack. You'll write this inside the __init__() method of your Stack class in the cdk_datacamp_stack.py file.
S3 bucket
from aws_cdk import aws_s3 as s3
# Create an S3 bucket with versioning and managed encryption
bucket = s3.Bucket(
self,
"MyBucket",
versioned=True,
encryption=s3.BucketEncryption.S3_MANAGED
)Lambda function
from aws_cdk import aws_lambda as lambda_
# Define a Lambda function using Python 3.9 runtime
lambda_function = lambda_.Function(
self,
"MyFunction",
runtime=lambda_.Runtime.PYTHON_3_9,
handler="index.handler",
code=lambda_.Code.from_asset("lambda") # Load code from local folder named 'lambda'
)Once you’ve added your resources, it’s time to deploy them to AWS.
In your terminal, activate your virtual environment and run:
cdk deployThis will:
You’ll be prompted to approve the changes if it’s your first time deploying the stack.
After deployment, you can:
AWS CDK apps rely on constructs as their essential structural elements. Your infrastructure code will become more modular, maintainable, and readable when you master constructs, whether you use built-in service constructs or create your reusable patterns.
This section teaches you about using L2 (high-level) constructs and how to develop custom constructs that reduce repetitive patterns.
L2 constructs are CDK-native abstractions that are easier to use than raw CloudFormation (L1). They have sensible defaults and type safety, often requiring fewer lines of code to set up an AWS resource.
Why use L2 constructs?
.add_to_role_policy() or .add_event_notification()Example: Creating an S3 bucket using L2
from aws_cdk import aws_s3 as s3
# Create a versioned and encrypted S3 bucket
bucket = s3.Bucket(
self,
"MyBucket",
versioned=True,
encryption=s3.BucketEncryption.S3_MANAGED
)The equivalent L1 construct, s3.CfnBucket, would need all properties manually set up and configuration defined as raw dicts—much less intuitive.
Other common L2 constructs include:
lambda_.Function() for AWS Lambdadynamodb.Table() for DynamoDBsqs.Queue() for SQSsns.Topic() for SNSYour infrastructure will expand with recurring patterns, such as creating Lambda functions with particular permissions and S3 buckets. Custom constructs serve as the ideal solution for this specific scenario.
Custom constructs enable you to combine related resources into a single logical unit, which can be reused across stacks or projects.
When to create a custom construct:
Example: A reusable S3 + Lambda pattern
from constructs import Construct
from aws_cdk import aws_s3 as s3, aws_lambda as lambda_
class StorageWithLambda(Construct):
def __init__(self, scope: Construct, id: str) -> None:
super().__init__(scope, id)
# S3 bucket
self.bucket = s3.Bucket(self, "MyBucket")
# Lambda function
self.function = lambda_.Function(
self,
"MyFunction",
runtime=lambda_.Runtime.PYTHON_3_9,
handler="index.handler",
code=lambda_.Code.from_asset("lambda")
)
# Grant Lambda access to the S3 bucket
self.bucket.grant_read_write(self.function)You can now use this construct inside any stack like this:
from my_project.storage_with_lambda import StorageWithLambda
storage = StorageWithLambda(self, "ReusableComponent")Before running the above, create a folder named lambda in the project root and create a file index.py with the following content:
def handler(event, context):
return {
"statusCode": 200,
"body": "Hello from Lambda!"
}Reusability tips
construct_ or place inside a constructs/ folderself.bucket or self.function for flexibilityAfter writing your infrastructure code, it is essential to check what the CDK will deploy and ideally test that your stacks behave as expected. The AWS CDK provides tools to synthesize CloudFormation templates and write automated tests to catch misconfigurations before deployment.
The cdk synth command generates the CloudFormation template from your CDK code.
cdk synthWhen you run this, the CDK:
app.py)
Synthesized CloudFormation template
By default, the output goes to your terminal, but you can also output to a file if needed:
cdk synth > template.yamlThis is useful when:
Although testing infrastructure as code might sound unusual, it is beneficial, especially when your stacks get large or include conditional logic, loops, or reusable constructs.
The AWS CDK offers the assertions module to test synthesized stacks.
Writing a simple test with pytest
Here's an example test that checks if a specific resource (like an S3 bucket) is included in the stack:
# test/test_cdk_datacamp_stack.py
import aws_cdk as cdk
from aws_cdk.assertions import Template
from cdk_datacamp.cdk_datacamp_stack import CdkDatacampStack
def test_s3_bucket_created():
app = cdk.App()
stack = CdkDatacampStack(app, "TestStack")
template = Template.from_stack(stack)
# Assert that an S3 bucket exists
template.resource_count_is("AWS::S3::Bucket", 1)To run the tests, make sure pytest is installed:
pip install -U pytestThen run:
pytestIf everything passes, you’ll see a green checkmark. If not, the test output will tell you what's missing.

Pytest output showing successful execution of all test cases for the AWS CDK stack
You can also include validation in your CDK stack. Validation tests are runtime checks inside your construct or stack code that validate inputs before deployment happens. They help catch misconfigurations or enforce constraints early in the development lifecycle.
Let’s say we want to pass the bucket_name as a context variable, but we want to validate that:
Create a file named test/test_storage_with_lambda.py and add the following:
import pytest
from aws_cdk import App, Stack
from cdk_datacamp.storage_with_lambda import StorageWithLambda
def test_missing_bucket_name():
app = App()
stack = Stack(app, "TestStack")
with pytest.raises(ValueError, match="bucket_name is required"):
StorageWithLambda(stack, "FailingConstruct", bucket_name=None)
def test_bucket_name_uppercase():
app = App()
stack = Stack(app, "TestStack")
with pytest.raises(ValueError, match="must be lowercase"):
StorageWithLambda(stack, "FailingConstruct", bucket_name="InvalidName")To test the validation, run the below command:
test/test_storage_with_lambda.py
Pytest output showing successful execution of all test cases for the AWS CDK stack
When to use testing:
Want to reinforce your CDK knowledge in an interview setting? These top AWS DevOps interview questions can help you prepare.
After mastering CDK stack creation and deployment, you should follow best practices to keep your infrastructure code clean, secure, and scalable. This section will discuss how to structure large projects, handle security correctly, and integrate CDK into CI/CD pipelines.
As your CDK app grows, organizing code into manageable units becomes essential.
Split your infrastructure by concern. For example:
This allows you to deploy, test, or destroy parts of your infrastructure independently. Here’s how it can be included in app.py:
network_stack = NetworkingStack(app, "NetworkingStack")
compute_stack = ComputeStack(app, "ComputeStack")You can also pass resources between stacks using outputs or references.
Encapsulate related resources (like a Lambda and its permissions) into a custom construct, as you did with StorageWithLambda. This improves readability and reusability across stacks or apps.
Support multiple environments (dev, staging, prod) using:
cdk.json with context valuescdk deploy -c env=prodenv = app.node.try_get_context("env")
if env == "prod":
bucket_name = "mycompany-prod-logs"Any infrastructure project must prioritize security during AWS CDK automated deployment processes. The following section demonstrates secure IAM resource management through least privilege principles.
CDK constructs, which include Lambda or ECS tasks, will automatically create IAM roles. Although convenient, it can limit your control over permissions and naming.
Instead, define roles explicitly:
from aws_cdk import aws_iam as iam
execution_role = iam.Role(
self,
"LambdaExecutionRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com"),
description="Custom role for Lambda with least privilege",
managed_policies=[
iam.ManagedPolicy.from_aws_managed_policy_name("service-role/AWSLambdaBasicExecutionRole")
]
)This role only allows logging and nothing else by default.
Avoid using "*" in actions or resources unless absolutely necessary.
Example:
lambda_fn.add_to_role_policy(
iam.PolicyStatement(
actions=["*"],
resources=["*"]
)
)You can also use resource-specific grants when available:
bucket.grant_read(lambda_fn)This automatically generates the necessary policy with scoped access to the S3 bucket.
AWS-managed policies simplify maintenance and reduce the chance of errors.
iam.ManagedPolicy.from_aws_managed_policy_name("AmazonSQSReadOnlyAccess")You can attach these to custom roles for services like ECS, Batch, or Step Functions.
The AWS CDK delivers exceptional power through its ability to integrate with contemporary CI/CD pipelines. CDK supports automated infrastructure delivery through version-controlled code deployment, which works with GitHub, GitLab, and AWS-native services, including CodePipeline. The system decreases human mistakes while shortening feedback cycles and enables deployment across multiple environments.
You can use GitHub Actions to synthesize, diff, test, and deploy CDK stacks on every push or pull request.
Take a look at this .github/workflows/deploy.yml:
name: Deploy CDK App
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
with:
python-version: 3.11
- name: Install dependencies
run: |
pip install -r requirements.txt
npm install -g aws-cdk
- name: Run unit tests
run: pytest
- name: CDK Synth
run: cdk synth -c environment=prod
- name: Deploy to AWS
run: cdk deploy --require-approval never
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}Use cdk diff in PRs to preview infra changes before merging.
For fully-managed deployments within AWS, CDK provides a module called aws_cdk.pipelines, which lets you define your entire CI/CD pipeline as code, just like infrastructure.
Here’s a simplified example:
from aws_cdk import pipelines, SecretValue, Stack
from constructs import Construct
from my_app_stage import MyAppStage # replace with your actual stage import
class PipelineStack(Stack):
def __init__(
self,
scope: Construct,
construct_id: str,
**kwargs
) -> None:
super().__init__(scope, construct_id, **kwargs)
# Define the source of the pipeline from a GitHub repository
source = pipelines.CodePipelineSource.git_hub(
repo_string="your-org/your-repo", # GitHub org/repo
branch="main",
authentication=SecretValue.secrets_manager("GITHUB_TOKEN")
)
# Define the CodePipeline and its synthesis step
pipeline = pipelines.CodePipeline(
self,
"MyAppPipeline",
synth=pipelines.ShellStep(
"Synth",
input=source,
commands=[
"pip install -r requirements.txt",
"npm install -g aws-cdk",
"cdk synth"
]
)
)
# Add an application stage (e.g., production deployment)
pipeline.add_stage(
MyAppStage(self, "ProdStage")
)In the above code:
SecretValue.secrets_manager("GITHUB_TOKEN") securely pulls your GitHub token from Secrets Manager.MyAppStage should be a class that extends Stage and wraps your actual CDK stacks.If you're deploying machine learning systems, integrating CDK with continuous deployment practices is covered in our CI/CD for Machine Learning course.
This tutorial showed you how to construct and deploy cloud infrastructure in Python through AWS Cloud Development Kit (CDK) operations. You learned how to:
Now that you’ve deployed your first CDK app, here are a few ways to level up:
aws_s3_deployment, aws_ecs_patterns, and cdk.pipelinesTo keep learning and building, check out the Introduction to AWS Boto in Python course!
Learn more about AWS with these courses!
Course
Course
Course
blog
Thalia Barrera
15 min
Tutorial
Moez Ali
Tutorial
Emmanuel Akor
Tutorial
Joleen Bothma
Tutorial
Alexis Perrier
Tutorial
DataCamp Team