
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Wir werden einen Gradio-basierten Research Paper Analyzer entwickeln, der es den Nutzern ermöglicht:
Um die Kosten für die Claude 3.7 Sonnet API zu optimieren, müssen wir ihre Nutzung an die Projektbedürfnisse anpassen, denn Input-Token kosten $3/M und Output-Token, einschließlich Thinking Mode, kosten $15/M.
Wir müssen die Kosten reduzieren, indem wir prompte Zwischenspeicherung, Stapelverarbeitung und Streaming-Modus für lange Antworten. Wir können den Thinking Mode sogar optimieren, indem wir ein niedrigeres Token-Budget festlegen (ab 1.024 Token) und es nur bei Bedarf erhöhen.
Mehr über die Optimierung der API-Kosten erfährst du in der offiziellen Dokumentation von Anthropic Dokumentation.
Bevor wir anfangen, wollen wir erst einmal klären, was der Denkmodus ist, falls du ihn nicht kennst. Der Denkmodus ist eine neue Funktion in Claude 3.7 Sonnet, die es ermöglicht, Schritt für Schritt zu denken, bevor die endgültige Antwort generiert wird. Es ermöglicht dem Modell,..:
Kurz gesagt: So funktioniert es:
Bevor wir beginnen, müssen wir den Anthropic-API-Schlüssel einrichten:
1. Beginne damit, dich in der Anthropic-Konsole anzumelden: https://console.anthropic.com/
2. Klicke auf Get API Keys.
3. Du wirst zur Registerkarte "API-Schlüssel" weitergeleitet. Klicke auf APIerstellen Schlüssel und gib deinen Schlüsselnamen ein.
4. Kopiere diesen Schlüssel und speichere ihn für spätere Zwecke.
5. Füge deinem Rechnungskonto auf der Registerkarte Abrechnung ein Guthaben hinzu. Klicke einfach auf Credits kaufen und füge deinem Konto etwa 5$ hinzu (das reicht für dieses Projekt).
Wir haben jetzt den API-Schlüssel. Stellen wir nun sicher, dass wir die erforderlichen Abhängigkeiten installiert haben.
pip install anthropic gradio PyPDF2Nach der Installation importierst du die erforderlichen Bibliotheken:
import anthropic
import PyPDF2
import os
import gradio as grNachdem wir nun alle erforderlichen Bibliotheken importiert haben, richten wir als Nächstes die Claude-API ein.
Wenn du Google Colab verwendest, kannst du den API-Schlüssel in der RegisterkarteSecrets speichern und dann die Funktion get() verwenden, um darauf zuzugreifen. Andernfalls kannst du den API-Schlüssel direkt an deinen Code übergeben (nicht empfohlen).
Dann initialisieren wir den Claude-Client mit der Anthropic-Bibliothek und geben den API-Schlüssel ein.
# If using Google Colab Secrets
from google.colab import userdata
API_KEY = userdata.get('claude-3.7-sonnet')
client = anthropic.Anthropic(
api_key=API_KEY,
)Damit ist der Teil der Einrichtung abgeschlossen. Als Nächstes arbeiten wir an der Textextraktion.
Wir werden PyPDF2 verwenden, um Text aus hochgeladenen PDF-Dateien zu extrahieren. Claude 3.7 Sonnet akzeptiert nur Text und Bilder als Eingabe. Deshalb extrahieren wir den Text vorher, um ihn effizient zu verarbeiten und gleichzeitig die Fähigkeiten von Claude 3.7 Sonnet with Thinking Mode zu maximieren.
# Function to extract text from a PDF file
def extract_text_from_pdf(pdf_path):
"""Extracts text from a given PDF file."""
text = ""
with open(pdf_path, "rb") as f:
reader = PyPDF2.PdfReader(f)
for page in reader.pages:
text += page.extract_text() + "\n"
return text.strip()Die Funktion extract_text_from_pdf() liest eine PDF-Datei, extrahiert mit PyPDF2.PdfReader() Text aus jeder Seite und gibt den kombinierten Text als String zurück.
Jetzt, da wir den extrahierten Text haben, fahren wir damit fort, Claude 3.7 Sonnets Denk- und Streaming-Modus um mehrere Texte zu analysieren und eine strukturierte Forschungsidee zu entwickeln.
Der Streaming-Modus sorgt für eine effiziente Bearbeitung großer Antworten, indem er die Ergebnisse nach und nach liefert, Wartezeiten verkürzt und API-Timeouts verhindert. Der Denkmodus verbessert das komplexe Denken, indem er es dem Modell ermöglicht, strukturierte interne Gedanken zu entwickeln, bevor es eine endgültige Antwort formuliert, um gut begründete Erkenntnisse zu erhalten.
# Function to analyze research papers with streaming
def analyze_papers_streaming(paper_texts, paper_count):
"""Uses Claude 3.7 Sonnet with Thinking Mode in streaming mode to analyze papers, find drawbacks, and generate a research project."""
formatted_papers = "\n\n".join([f"### Paper {i+1}:\n{paper}" for i, paper in enumerate(paper_texts)])
prompt = f"""
You are an AI research assistant. You have been provided with {paper_count} research papers.
Your task is to analyze these papers and perform the following:
1. **Summarize each paper** with its core contributions and findings.
2. **Identify key drawbacks** of each paper, focusing on limitations, gaps, or areas needing improvement.
3. **Find interconnections and citations** between the papers—what ideas, methods, or datasets do they share?
4. **Propose a novel research idea** that addresses a major limitation across these papers.
- Suggest how techniques from different papers can be combined to solve a problem.
- Ensure the idea is practical and feasible for further research.
- Justify why this approach is promising.
Below are the research papers
{formatted_papers}
"""
results = {"thinking": "", "research_idea": ""}
with client.messages.stream(
model="claude-3-7-sonnet-20250219",
max_tokens=25000,
thinking={
"type": "enabled",
"budget_tokens": 16000 # Large budget for deep reasoning
},
messages=[{"role": "user", "content": prompt}]
) as stream:
current_block_type = None
for event in stream:
if event.type == "content_block_start":
current_block_type = event.content_block.type
elif event.type == "content_block_delta":
if event.delta.type == "thinking_delta":
results["thinking"] += event.delta.thinking
elif event.delta.type == "text_delta":
results["research_idea"] += event.delta.text
elif event.type == "message_stop":
break
return results["thinking"], results["research_idea"]Die Funktion analyze_papers_streaming() führt die folgenden Schritte aus:
client.messages.stream() , um die Anfrage an Claude 3.7 Sonnet zu senden. Dies ermöglicht den Denkmodus mit budget_tokens=16000 und max_tokens=25000 für eine längere Reaktionszeit.content_block_start Ereignisse, die den Beginn eines Antwortblocks anzeigen. Während das Modell Ergebnisse erzeugt, enthalten die thinking_delta Ereignisse Zwischenschritte, während die text_delta Ereignisse die endgültigen Forschungsergebnisse liefern. Der Prozess wird fortgesetzt, bis ein message_stop Ereignis den Abschluss der Antwort signalisiert.Du kannst mehr über die Verfeinerung von Souffleurtechniken für erweitertes Denken erfahren hier.
Jetzt, wo unsere Hauptlogik aufgebaut ist, fahren wir damit fort, sie in Gradio zu integrieren, damit die Nutzer/innen Forschungsarbeiten hochladen und strukturierte Einblicke erhalten können.
# Gradio UI function
def gradio_interface(pdfs):
paper_texts = [extract_text_from_pdf(pdf.name) for pdf in pdfs]
paper_count = len(paper_texts) # Count number of provided papers
thinking, research_idea = analyze_papers_streaming(paper_texts, paper_count)
return thinking, research_idea
# Set up the Gradio app
demo = gr.Interface(
fn=gradio_interface,
inputs=gr.File(file_types=[".pdf"], label="Upload Research Papers", file_count="multiple"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Research Idea")],
title="Claude 3.7 Sonnet - Powered Research Paper Analyzer",
description="Upload multiple research papers to extract insights, identify key limitations, and generate a novel research idea."
)
if __name__ == "__main__":
demo.launch(debug=True)Der obige Code richtet eine Gradio-Benutzeroberfläche ein, auf der Benutzer mehrere PDFs hochladen können, die verarbeitet werden, um Text zu extrahieren, wichtige Erkenntnisse zu analysieren und neue Forschungsideen zu generieren. Denk- und Streaming-Modus.
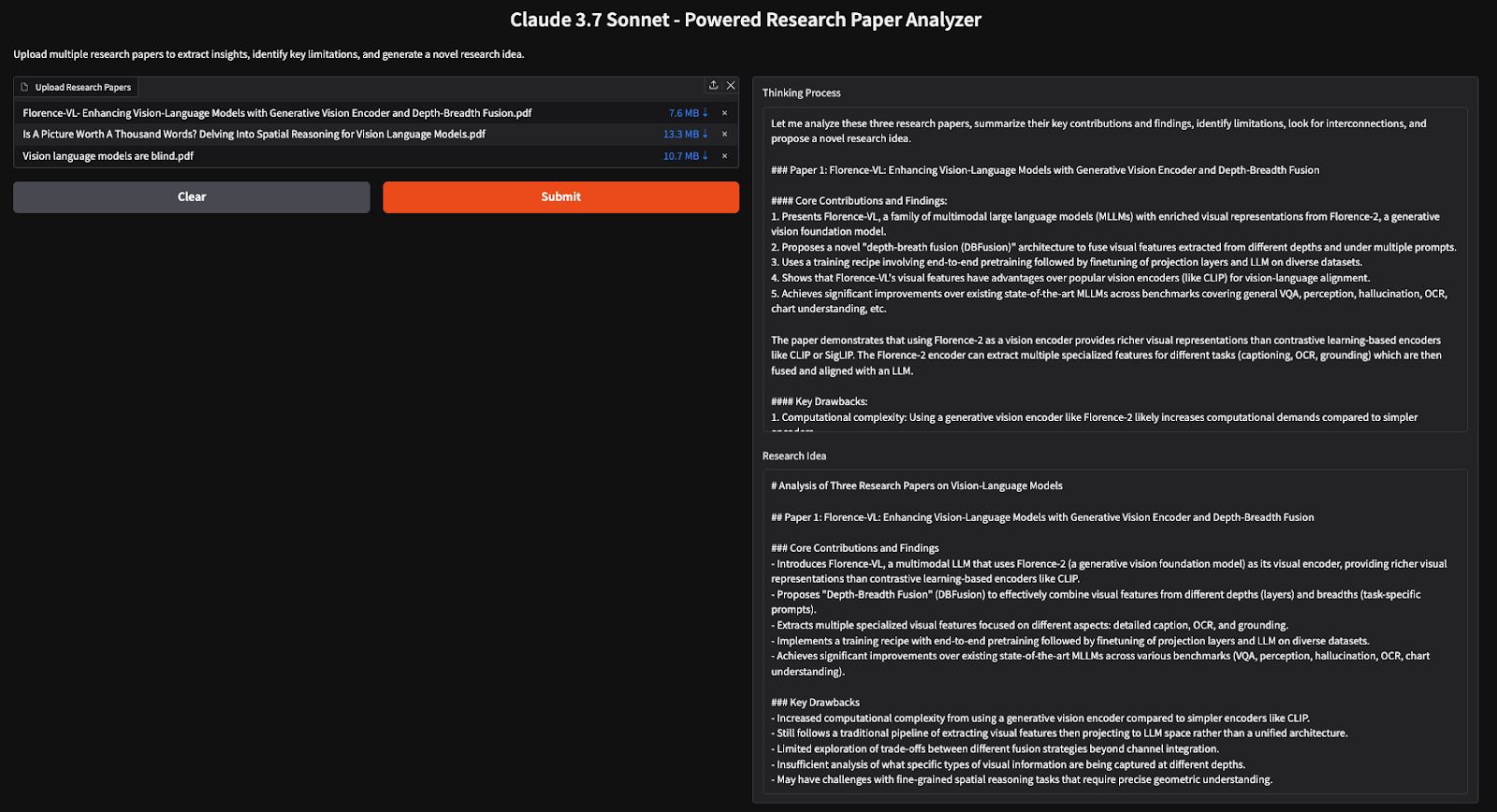
In diesem Tutorial haben wir mit Claude 3.7 Sonnet einen KI-gestützten Research Paper Analyzer entwickelt, der es Forschern ermöglicht, effizient Erkenntnisse zu gewinnen, Einschränkungen zu erkennen und neue Forschungsideen aus mehreren Papieren zu entwickeln. Durch die Verwendung des Denkmodus führt das Modell tiefgreifende Überlegungen durch, was es zu einem effektiven Werkzeug für Literaturübersichten und Forschungssynthesen macht.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Tutorial
Moez Ali
Tutorial
Derrick Mwiti
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree