
Lernpfad
KI-Grundlagen für Unternehmen
12 Std.
Reasoning-Modelle werden immer wichtiger und verbreiteter, und wir können sehen, warum. Wenn du dir die Grafik unten ansiehst, wirst du feststellen, dass 37,2 % der Nutzerinnen und Nutzer Claude für Programmier- und Mathefragen nutzen, wie der Anthropischen Wirtschaftsindex. Das sagt mir eines: Starke Argumentationsmodelle können einen echten geschäftlichen Nutzen bringen, vor allem, da KI in Unternehmen noch wenig verbreitet ist.
Quelle: Antrophic Economic Index
Gleichzeitig ist der Claude 3.7 nicht nur ein Argumentationsmodell, sondern ein Hybrid. Wir können zwischen dem Denkmodus (für strukturierte Denkaufgaben) und einem Standard-Chatmodus für allgemeine Konversation, Schreiben und Zusammenfassungen wechseln.
Claude 3.7 Sonnet ist ein viel größeres Upgrade, als die Versionsnummer vermuten lässt. Die Benchmark-Daten bestätigen, dass es Claude 3.5 Sonnet beim Denken, Codieren und bei der Ausführung von Aufgaben in der realen Welt übertrifft.
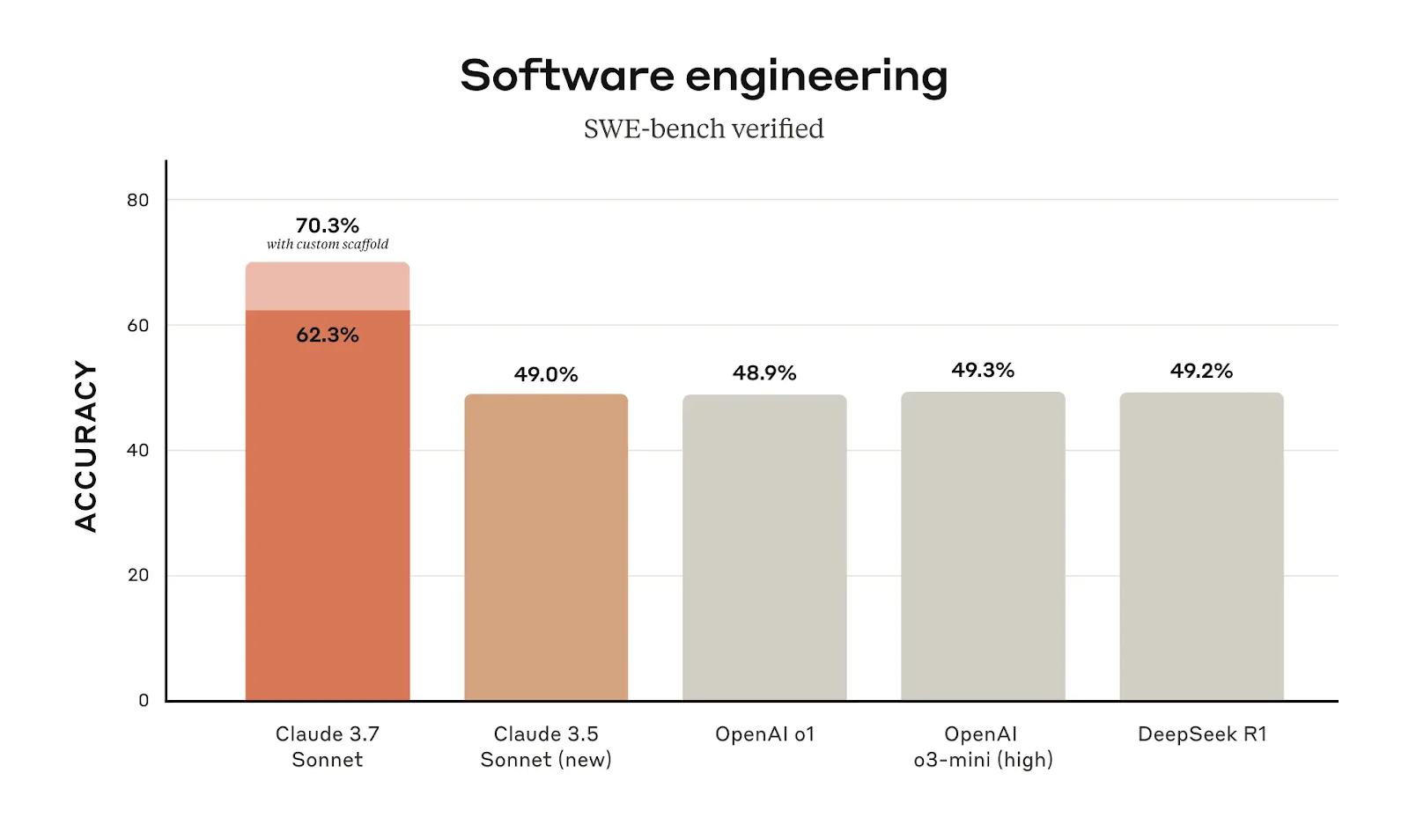
Claude 3.7 Sonnet zeigt einen klaren Vorteil in der Softwareentwicklung, mit einer Genauigkeit von 62,3 % im SWE-Bench Verified, ein deutlicher Sprung gegenüber den 49,0 % von Claude 3.5 Sonnet. Bei Verwendung eines benutzerdefinierten Gerüsts (eine strukturierte Aufforderung oder ein zusätzlicher Kontext, der die Antwort des Modells auf eine genauere Lösung lenkt) erhöht sich die Genauigkeit auf 70,3 %, womit es das beste Modell in dieser Kategorie ist.
Quelle: Anthropisch
Eine Verbesserung der Genauigkeit um fast 13% zwischen den Modellversionen ist nicht nur eine kleine Verbesserung. Das deutet darauf hin, dass Claude 3.7 Sonnet für ein besseres Verständnis und eine bessere Ausführung von programmierbezogenen Aufgaben optimiert wurde. Für Benutzer, die Claude für die Softwareentwicklung, das Debugging oder die Automatisierung nutzen, macht das Upgrade einen spürbaren Unterschied.
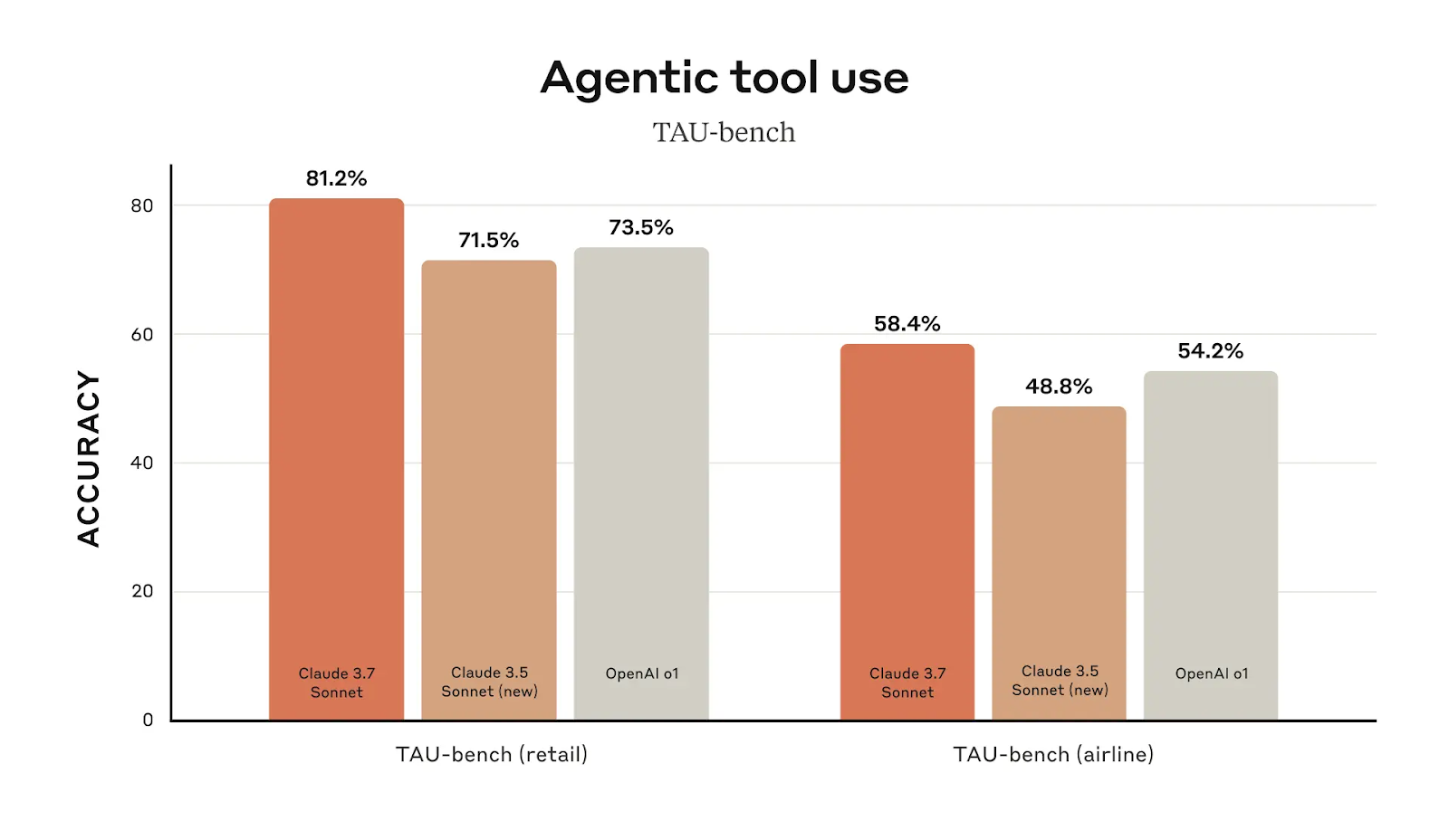
Die Leistung bei der Verwendung von Agententools ist ein weiterer Bereich, in dem Claude 3.7 Sonnet seinen Vorgänger übertrifft. Bei einzelhandelsbezogenen Aufgaben erreicht er eine Genauigkeit von 81,2 %, gegenüber 71,5 % bei Claude 3.5 Sonnet. Bei den flugzeugbezogenen Aufgaben erreicht sie 58,4 %, was eine Verbesserung von fast zehn Punkten gegenüber der Vorgängerversion bedeutet.
Quelle: Anthropisch
Bei allen Benchmarks sind die größten Zuwächse im erweiterten Denkmodus zu verzeichnen, mit dem Claude 3.7 bei komplexen Denkaufgaben ein viel höheres Niveau erreicht. Nutzer, die sich bei strukturierten Arbeitsabläufen, beim Codieren oder bei der Problemlösung auf KI verlassen, werden einen deutlichen Unterschied zwischen Claude 3.5 und Claude 3.7 feststellen, vor allem wenn es um erweitertes Denken geht.
Quelle: Anthropisch
Der größte Teil dieses Fortschritts kommt von Claudes erweitertem Denken, also lass uns mehr darüber herausfinden.
Wenn er aktiviert ist, erhöht der erweiterte Denkmodus die Anzahl der Denkschritte, die Claude benötigt, um eine Antwort zu finden. Die Entwickler/innen können diesen Prozess feinabstimmen, indem sie ein Denkbudget festlegen, das bestimmt, wie viele Token das Modell bei der Bearbeitung eines Problems verwenden kann. Wie in der AIME 2024-Leistungsgrafik unten zu sehen ist, verbessert sich die Genauigkeit, je mehr Token zugewiesen werden, und folgt einem logarithmischen Trend.
Quelle: Anthropisch
Dieser Ansatz spiegelt die kognitive Anstrengung des Menschen wider: Bei einfachen Aufgaben reichen schnelle Antworten aus, aber bei komplexen Aufgaben führt eine tiefere Analyse zu besseren Ergebnissen. Claude kann jetzt entscheiden, wann er innehalten, neu bewerten und seine Überlegungen verfeinern muss, anstatt sofort zu reagieren.
Einer der interessantesten Aspekte des erweiterten Denkmodus ist, dass der Denkprozess von Claude für den Benutzer sichtbar ist. Diese Funktion bringt jedoch einige Herausforderungen mit sich. Obwohl es einen Einblick in die Denkweise der KI gibt, stimmt der dargestellte Denkprozess nicht immer perfekt mit der tatsächlichen Entscheidungsfindung des Modells überein. Das "Treueproblem" - ob die selbstberichteten Gedanken einer KI ihre internen Mechanismen richtig wiedergeben - ist immer noch eine offene Forschungsfrage.
Claude 3.7 Sonnets Fähigkeit zu langfristigem, iterativem Denken wird in Bewertungen wie OSWorld und Pokémon Red Gameplay getestet. In Pokémon Rot zum Beispiel erreicht Claude 3.7 Sonnet einen viel größeren Spielfortschritt als frühere Versionen und schafft es durch mehrere Meilensteine, während frühere Modelle früh im Spiel stecken bleiben.
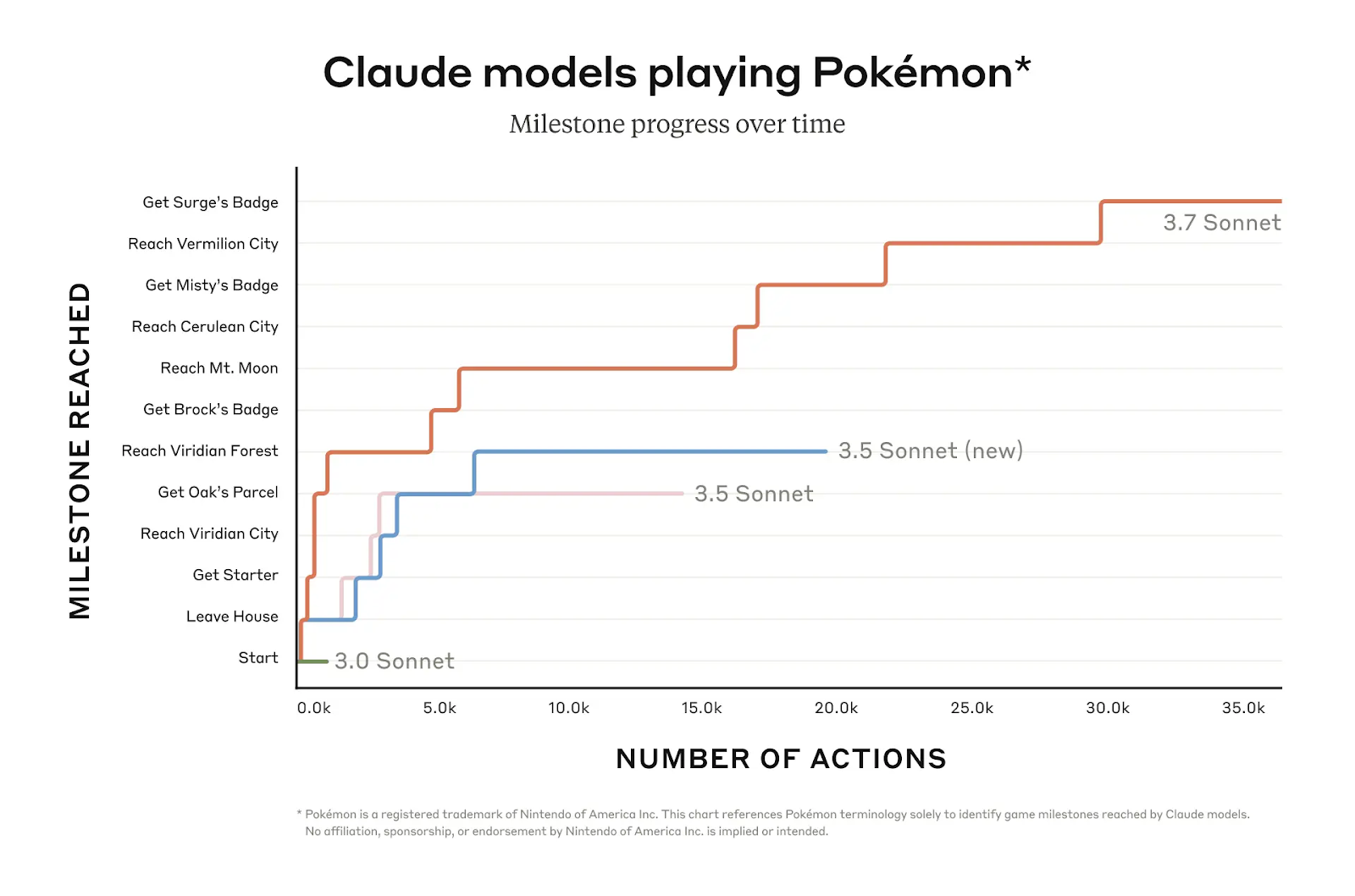
Quelle: Anthropisch
Wir haben gesehen, wie Claude 3.7 Sonnet im Vergleich zu seiner Vorgängerversion abschneidet. Aber wie schneidet es im Vergleich zu OpenAIs o3-mini, DeepSeek-R1 oder Grok 3 ab?
In den aktualisierten Benchmarks hat sich Claude 3.7 Sonnet als eines der leistungsstärksten Modelle positioniert, vor allem bei schlussfolgernden Aufgaben, beim Codieren und bei der Nutzung von Agententools.
Beim logischen Denken auf Graduiertenebene (GPQA Diamond) erreicht Claude 3.7 Sonnet 68,0 % im Standardmodus und 84,8 % im erweiterten Denkmodus und ist damit eines der stärksten Modelle in dieser Kategorie. Es übertrifft OpenAIs o1 (78,0 %) und DeepSeek-R1 (71,5 %) um einiges und Grok 3 Beta (84,6 %) nur um einen kleinen Abstand.
|
Benchmark |
Claude 3.7 Sonett (Standard) |
Claude 3.7 Sonett (Erweitertes Denken) |
OpenAI o1 |
OpenAI o3-mini (hoch) |
DeepSeek R1 |
Grok 3 Beta |
|
GPQA Diamond (Argumentation auf Graduiertenebene) |
68.0% |
84.8% |
78.0% |
79.7% |
71.5% |
84.6% |
|
AIME 2024 (Mathematikwettbewerb für Gymnasien) |
23.3% |
80.0% |
83.3% |
87.3% |
79.8% |
93.3% |
|
Mathematisches Problemlösen (MATH 500) |
82.2% |
96.2% |
96.4% |
97.9% |
97.3% |
- |
Der AIME 2024 Benchmark, der Mathematik-Wettbewerbsaufgaben der Oberstufe testet, zeigt einen ähnlichen Trend. Claude 3.7 Sonnet macht einen riesigen Sprung im Vergleich zu früheren Versionen und erreicht 80,0 %, wenn das erweiterte Denken aktiviert ist. Er übertrifft DeepSeek-R1 (79,8 %) zwar knapp, liegt aber immer noch hinter OpenAIs o3-mini (87,3 %) und Grok 3 Beta (93,3 %) zurück.
Beim Lösen von Mathematikaufgaben (MATH 500) erreicht Claude 3.7 Sonnet 96,2 % und liegt damit dicht hinter OpenAIs o3-mini (97,9 %) und DeepSeek R1 (97,3 %).
Claude 3.7 Sonnet macht seine größten Fortschritte bei den Coding-Benchmarks. Im SWE-Bench Verified (der KI-Modelle für Software-Engineering-Aufgaben bewertet) erreicht Claude 3.7 Sonnet 62,3 % und steigt mit einem benutzerdefinierten Gerüst auf 70,3 %. Damit liegt er weit vor dem o1 (48,9 %) und dem o3-mini (49,3 %) von OpenAI sowie dem DeepSeek R1 (49,2 %), der speziell für das Codieren entwickelt wurde. Das bestätigt, dass Claude 3.7 jetzt eines der besten KI-Modelle für programmierbezogene Aufgaben ist.
|
Benchmark |
Claude 3.7 Sonett (Standard) |
Claude 3.7 Sonett (Custom Scaffold) |
OpenAI o1 |
OpenAI o3-mini (hoch) |
DeepSeek R1 |
|
SWE-Bench Verified (Kodierung) |
62.3% |
70.3% |
48.9% |
49.3% |
49.2% |
|
TAU-bench Einzelhandel (Werkzeuggebrauch) |
81.2% |
- |
73.5% |
- |
- |
|
TAU-bench Airline (Tool Use) |
58.4% |
- |
54.2% |
- |
- |
Neben der Programmierung ist Claude 3.7 Sonnet führend bei der Nutzung von Agententools, was es zu einer guten Wahl für die Automatisierung und Ausführung von Arbeitsabläufen macht. Im TAU-Bench (der die Fähigkeit der KI testet, mit externen Tools in strukturierten Umgebungen zu interagieren) erreicht Claude 3.7 81,2 % bei Aufgaben im Einzelhandel und übertrifft damit OpenAI o1 (73,5 %). Bei flugzeugbezogenen Aufgaben erreicht Claude 3.7 58,4 % und übertrifft damit erneut OpenAI o1 (54,2 %).
Das deutet darauf hin, dass Claude 3.7 gut für Geschäftsanwendungen und strukturierte Arbeitsabläufe geeignet ist, was es zu einer guten Wahl für Unternehmensanwender macht, die KI in ihre Entscheidungs- und Betriebsprozesse integrieren wollen.
Claude 3.7 Sonnet ist über verschiedene Kanäle verfügbar, darunter das Webinterface von Anthropic, die Integration von Claude in verschiedene Apps und der API-Zugang für Entwickler. Das Modell ist zwar ein bedeutendes Upgrade, aber seine Verfügbarkeit ist mit einigen Einschränkungen verbunden - vor allem, wenn du den Thinking Mode nutzen willst, der derzeit noch hinter einer kostenpflichtigen Stufe versteckt ist.
Für allgemeine Benutzer ist Claude 3.7 Sonnet über die offizielle Website von Anthropic zugänglich (claude.ai) und die Claude-App. Sie ist in der kostenlosen Version verfügbar, allerdings mit Einschränkungen:
Um den Thinking Mode zu aktivieren, musst du auf Erweitert aus dem Dropdown-Menü des Modells klicken:
Entwickler können Claude 3.7 Sonnet in ihre Anwendungen integrieren, indem sie die API von Anthropic nutzen, die über das Anthropic's Entwicklerportal. Die API unterstützt ein Pay-as-you-go-Preismodell, das auf der Nutzung von Token basiert.
Hier findest du einen Überblick über die API-Angebote von Anthropic:
|
Feature |
Claude 3.7 Sonett |
Claude 3.5 Sonett |
Claude 3.5 Haiku |
Claude 3 Opus |
Claude 3 Haiku |
|
Beschreibung |
Unser intelligentestes Modell |
Unser bisher intelligentestes Modell |
Unser schnellstes Modell |
Leistungsstarkes Modell für komplexe Aufgaben |
Schnellstes und kompaktestes Modell für nahezu sofortige Reaktionsfähigkeit |
|
Stärken |
Höchste Intelligenz und Fähigkeit mit zuschaltbarem erweiterten Denken |
Hohes Maß an Intelligenz und Fähigkeiten |
Intelligenz in rasender Geschwindigkeit |
Intelligenz, Sprachgewandtheit und Verständnis auf höchstem Niveau |
Schnelle und genaue Zielerreichung |
|
Mehrsprachig |
Ja |
Ja |
Ja |
Ja |
Ja |
|
Vision |
Ja |
Ja |
Ja |
Ja |
Ja |
|
Ja |
Nein |
Nein |
Nein |
Nein |
|
|
API-Modellname |
claude-3-7-sonnet-20250219 |
Aktualisierte Version: claude-3-5-sonnet-20241022 Vorherige Version: claude-3-5-sonnet-20240620 |
claude-3-5-haiku-20241022 |
claude-3-opus-20240229 |
claude-3-haiku-20240307 |
|
Latenzzeit im Vergleich |
Schnell |
Schnell |
Schnellste |
Mäßig schnell |
Schnellste |
|
Kontextfenster |
200K |
200K |
200K |
200K |
200K |
|
Maximale Leistung |
Normal: 8192 Token Erweitertes Denken:64000 Token |
8192 Token |
8192 Token |
4096 Token |
4096 Token |
|
Kosten (Input / Output pro MTok) |
$3.00 / $15.00 |
$3.00 / $15.00 |
$0.80 / $4.00 |
$15.00 / $75.00 |
$0.25 / $1.25 |
|
Abschneiden der Trainingsdaten |
Okt 2024 |
Apr 2024 |
Juli 2024 |
Aug 2023 |
Aug 2023 |
Quelle: Anthropisch
Achte darauf, immer die neuesten API-Preise zu prüfen.
Anthropic hat gerade mit Claude 3.7 Sonnet seinen größten Schritt seit langem gemacht, ein Modell, das es endlich in den Bereich der KI bringt. Anhand der Benchmarks können wir sehen, dass er ein legitimer Konkurrent von OpenAIs o3-mini, DeepSeek-R1 und Grok 3 ist, mit einer starken Leistung bei der Programmierung, dem strukturierten Lösen von Problemen und der Nutzung von Agententools.
Die Möglichkeit, zwischen dem Generalisten- und dem Denkmodus zu wechseln, macht ihn vielseitiger, aber den Denkmodus hinter eine Bezahlschranke zu sperren, ist ein Fehler, vor allem weil es kostenlose Alternativen gibt. Trotzdem ist Claude 3.7 ein großer Schritt nach vorne.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Laiba Siddiqui
