
Cursus
Développer des applications d'IA
21 h
Nous allons développer un analyseur de documents de recherche basé sur Gradio qui permet aux utilisateurs de.. :
Pour optimiser les coûts de l'API Claude 3.7 Sonnet, nous devons aligner son utilisation sur les besoins du projet, car les jetons d'entrée coûtent 3 $/M et les jetons de sortie, y compris le mode de pensée, coûtent 15 $/M.
Nous devons réduire les dépenses en utilisant la mise en cache rapidele traitement par lots et le mode continu pour les réponses longues. Nous pouvons même optimiser Thinking Mode en fixant un budget de jetons plus bas (à partir de 1 024 jetons) et en ne l'augmentant qu'en cas de besoin.
Vous pouvez en savoir plus sur l'optimisation du coût de l'API en consultant la officielle d'Anthropic.
Avant de commencer, expliquons ce qu'est le mode réflexion, au cas où vous ne le connaîtriez pas. Le mode réflexion est une nouvelle fonctionnalité de Claude 3.7 Sonnet qui permet de raisonner étape par étape avant de générer la réponse finale. Il permet au modèle de :
En bref, voici comment cela fonctionne :
Avant de commencer, nous devons configurer la clé API d'Anthropic :
1. Commencez par vous connecter à la console Anthropic : https://console.anthropic.com/
2. Cliquez sur Get API Keys.
3. Vous serez redirigé vers l'onglet Clés API. Cliquez sur Create API Key et saisissez votre nom de clé.
4. Copiez cette clé et conservez-la pour référence ultérieure.
5. Ajoutez maintenant un crédit à votre compte de facturation, sous l'onglet Billing. Il suffit de cliquer sur acheter des crédits et d'ajouter environ 5 $ à votre compte (ce qui est suffisant pour ce projet).
Nous avons maintenant la clé API en place. Assurons-nous maintenant que les dépendances nécessaires sont installées.
pip install anthropic gradio PyPDF2Une fois installé, importez les bibliothèques nécessaires :
import anthropic
import PyPDF2
import os
import gradio as grMaintenant que nous avons importé toutes les bibliothèques nécessaires, nous allons configurer l'API Claude.
Si vous utilisez Google Colab, vous pouvez enregistrer la clé API dans l'ongletSecrets et utiliser ensuite la fonction get() pour y accéder. Sinon, vous pouvez transmettre la clé API directement à votre code (ce qui n'est pas recommandé).
Nous initialisons ensuite le client Claude à l'aide de la bibliothèque Anthropic et lui transmettons la clé API.
# If using Google Colab Secrets
from google.colab import userdata
API_KEY = userdata.get('claude-3.7-sonnet')
client = anthropic.Anthropic(
api_key=API_KEY,
)Ceci complète notre partie d'installation. Ensuite, nous procédons à l'extraction du texte.
Nous utiliserons PyPDF2 pour extraire le texte des fichiers PDF téléchargés. Claude 3.7 Sonnet n'accepte que du texte et des images en entrée. Nous extrayons donc le texte à l'avance pour un traitement efficace tout en maximisant les capacités de Claude 3.7 Sonnet avec le mode réflexion.
# Function to extract text from a PDF file
def extract_text_from_pdf(pdf_path):
"""Extracts text from a given PDF file."""
text = ""
with open(pdf_path, "rb") as f:
reader = PyPDF2.PdfReader(f)
for page in reader.pages:
text += page.extract_text() + "\n"
return text.strip()La fonction extract_text_from_pdf() lit un fichier PDF, extrait le texte de chaque page à l'aide de PyPDF2.PdfReader() et renvoie le texte combiné sous la forme d'une chaîne.
Maintenant que nous disposons du texte extrait, nous allons utiliser le mode de pensée et d'écoute du sonnet de Claude 3.7. de Claude Sonnet pour analyser plusieurs documents et générer une idée de recherche structurée. pour analyser plusieurs documents et générer une idée de recherche structurée.
Le mode de diffusion en continu garantit un traitement efficace des réponses volumineuses en fournissant progressivement les résultats, en réduisant les temps d'attente et en évitant les dépassements de délai de l'API. Le mode réflexion améliore le raisonnement complexe en permettant au modèle de générer des pensées internes structurées avant de formuler une réponse finale, ce qui garantit des idées bien justifiées.
# Function to analyze research papers with streaming
def analyze_papers_streaming(paper_texts, paper_count):
"""Uses Claude 3.7 Sonnet with Thinking Mode in streaming mode to analyze papers, find drawbacks, and generate a research project."""
formatted_papers = "\n\n".join([f"### Paper {i+1}:\n{paper}" for i, paper in enumerate(paper_texts)])
prompt = f"""
You are an AI research assistant. You have been provided with {paper_count} research papers.
Your task is to analyze these papers and perform the following:
1. **Summarize each paper** with its core contributions and findings.
2. **Identify key drawbacks** of each paper, focusing on limitations, gaps, or areas needing improvement.
3. **Find interconnections and citations** between the papers—what ideas, methods, or datasets do they share?
4. **Propose a novel research idea** that addresses a major limitation across these papers.
- Suggest how techniques from different papers can be combined to solve a problem.
- Ensure the idea is practical and feasible for further research.
- Justify why this approach is promising.
Below are the research papers
{formatted_papers}
"""
results = {"thinking": "", "research_idea": ""}
with client.messages.stream(
model="claude-3-7-sonnet-20250219",
max_tokens=25000,
thinking={
"type": "enabled",
"budget_tokens": 16000 # Large budget for deep reasoning
},
messages=[{"role": "user", "content": prompt}]
) as stream:
current_block_type = None
for event in stream:
if event.type == "content_block_start":
current_block_type = event.content_block.type
elif event.type == "content_block_delta":
if event.delta.type == "thinking_delta":
results["thinking"] += event.delta.thinking
elif event.delta.type == "text_delta":
results["research_idea"] += event.delta.text
elif event.type == "message_stop":
break
return results["thinking"], results["research_idea"]La fonction analyze_papers_streaming() exécute les étapes suivantes :
client.messages.stream() pour envoyer la demande à Claude 3.7 Sonnet. Cela permet un mode de réflexion avec budget_tokens=16000 et max_tokens=25000 pour une réponse plus longue.content_block_start pour indiquer le début d'un bloc de réponse. Au fur et à mesure que le modèle génère des résultats, les événements thinking_delta contiennent des étapes de raisonnement intermédiaires, tandis que les événements text_delta fournissent les conclusions finales de la recherche. Le processus se poursuit jusqu'à ce qu'un événement message_stop signale la fin de la réponse.Vous pouvez en savoir plus sur l'affinement des techniques d'incitation à la réflexion approfondie ici.
Maintenant que notre logique principale est construite, nous continuons à l'intégrer dans Gradio, ce qui permet aux utilisateurs de télécharger des documents de recherche et de recevoir des informations structurées.
# Gradio UI function
def gradio_interface(pdfs):
paper_texts = [extract_text_from_pdf(pdf.name) for pdf in pdfs]
paper_count = len(paper_texts) # Count number of provided papers
thinking, research_idea = analyze_papers_streaming(paper_texts, paper_count)
return thinking, research_idea
# Set up the Gradio app
demo = gr.Interface(
fn=gradio_interface,
inputs=gr.File(file_types=[".pdf"], label="Upload Research Papers", file_count="multiple"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Research Idea")],
title="Claude 3.7 Sonnet - Powered Research Paper Analyzer",
description="Upload multiple research papers to extract insights, identify key limitations, and generate a novel research idea."
)
if __name__ == "__main__":
demo.launch(debug=True)Le code ci-dessus met en place une interface utilisateur Gradio dans laquelle les utilisateurs peuvent télécharger plusieurs PDF, qui sont traités pour extraire le texte, analyser les informations clés et générer de nouvelles idées de recherche à l'aide des modes de en mode réflexion et en mode flux.
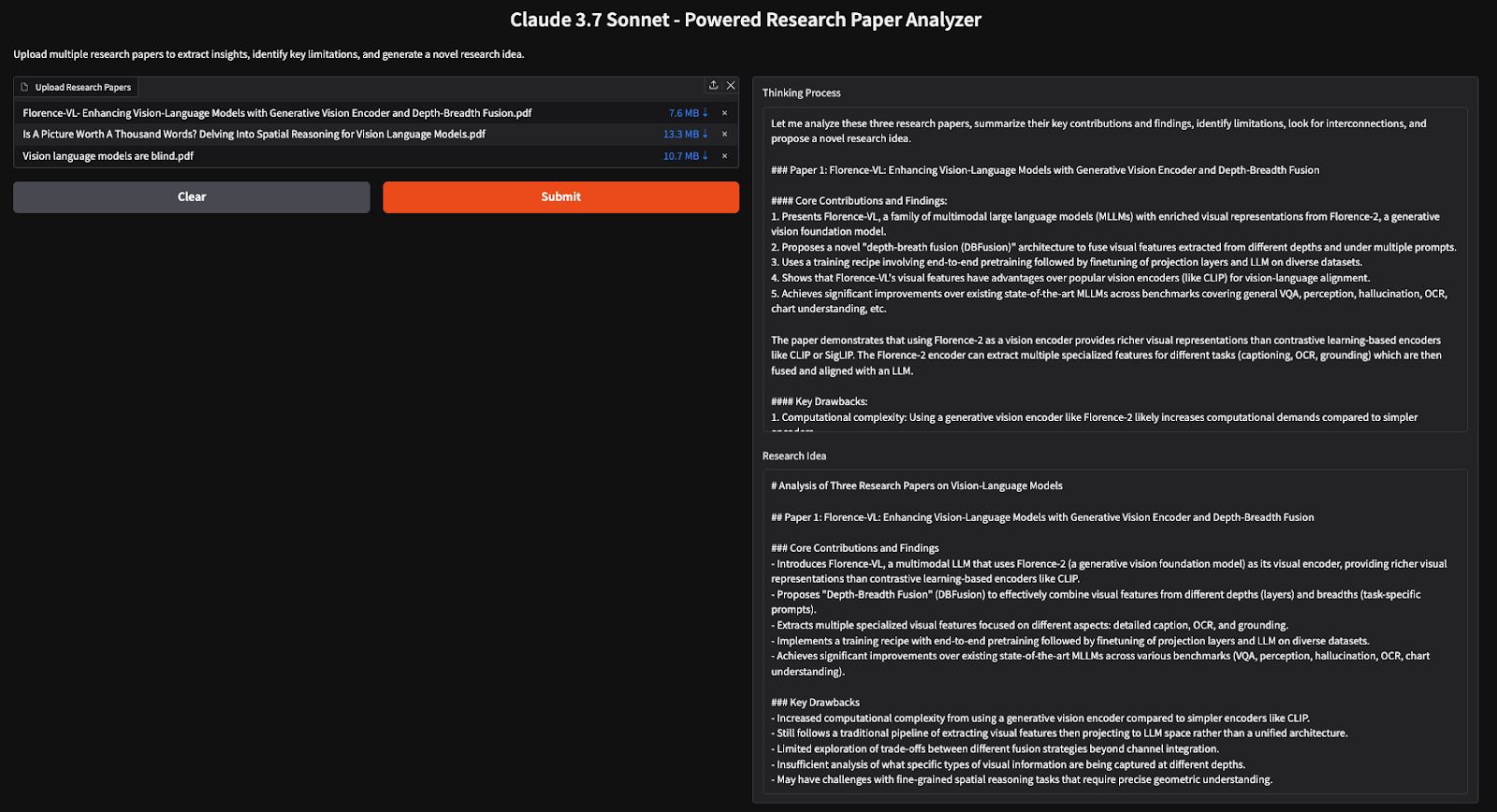
Dans ce tutoriel, nous avons construit un analyseur d'articles de recherche alimenté par l'IA en utilisant Claude 3.7 Sonnet, permettant aux chercheurs d'extraire efficacement des informations, d'identifier les limites et de générer de nouvelles idées de recherche à partir de plusieurs articles. En utilisant le mode de réflexion, le modèle effectue un raisonnement approfondi, ce qui en fait un outil efficace pour les analyses documentaires et les synthèses de recherche.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Moez Ali
Tutoriel
Mark Pedigo
Tutoriel
Laiba Siddiqui
Tutoriel
Matt Crabtree
