
Programa
Desenvolvimento de aplicativos de IA
21 h
Desenvolveremos um analisador de trabalhos de pesquisa com base no Gradio que permite aos usuários:
Para otimizar os custos da API Sonnet do Claude 3.7, precisamos alinhar seu uso com as necessidades do projeto, pois os tokens de entrada custam US$ 3/M e os tokens de saída, incluindo o Thinking Mode, custam US$ 15/M.
Precisamos reduzir as despesas usando cache imediatoprocessamento em lote e modo de streaming para respostas longas. Podemos até mesmo otimizar o Thinking Mode definindo um orçamento de tokens menor (a partir de 1.024 tokens) e aumentando-o somente quando necessário.
Você pode saber mais sobre como otimizar o custo da API na documentação oficial do Anthropic documentação.
Antes de começarmos, vamos esclarecer o que é o modo de pensamento, caso você não esteja familiarizado com ele. O Thinking Mode é um novo recurso do Claude 3.7 Sonnet que permite o raciocínio passo a passo antes de gerar a resposta final. Ele permite que o modelo:
Em poucas palavras, é assim que funciona:
Antes de começar, precisamos configurar a chave da API do Anthropic:
1. Comece fazendo login no console do Anthropic: https://console.anthropic.com/
2. Clique em Get API Keys (Obter chaves de API).
3. Você será redirecionado para a guia API Keys (Chaves de API). Clique em Create API Key e digite o nome da chave.
4. Copie essa chave e salve-a para referência futura.
5. Agora, adicione algum crédito à sua conta de faturamento, na guia Billing. Basta clicar em comprar créditos e adicionar cerca de US$ 5 à sua conta (suficiente para este projeto).
Agora você tem a chave de API instalada. Agora, vamos nos certificar de que temos as dependências necessárias instaladas.
pip install anthropic gradio PyPDF2Depois de instalado, importe as bibliotecas necessárias:
import anthropic
import PyPDF2
import os
import gradio as grAgora que importamos todas as bibliotecas necessárias, vamos configurar a API do Claude.
Se estiver usando o Google Colab, você poderá salvar a chave da API na guiaSecrets e, em seguida, usar a função get() para acessá-la. Caso contrário, você pode passar a chave da API diretamente para o seu código (não recomendado).
Em seguida, inicializamos o cliente Claude usando a biblioteca Anthropic e passamos a chave da API.
# If using Google Colab Secrets
from google.colab import userdata
API_KEY = userdata.get('claude-3.7-sonnet')
client = anthropic.Anthropic(
api_key=API_KEY,
)Isso conclui nossa parte de configuração. Em seguida, trabalhamos na parte de extração de texto.
Usaremos o PyPDF2 para extrair texto de arquivos PDF carregados. Claude 3.7 O Sonnet aceita apenas texto e imagens como entrada. Portanto, extraímos o texto antecipadamente para um processamento eficiente e, ao mesmo tempo, maximizamos os recursos do Claude 3.7 Sonnet with Thinking Mode.
# Function to extract text from a PDF file
def extract_text_from_pdf(pdf_path):
"""Extracts text from a given PDF file."""
text = ""
with open(pdf_path, "rb") as f:
reader = PyPDF2.PdfReader(f)
for page in reader.pages:
text += page.extract_text() + "\n"
return text.strip()A função extract_text_from_pdf() lê um arquivo PDF, extrai o texto de cada página usando PyPDF2.PdfReader() e retorna o texto combinado como uma cadeia de caracteres.
Agora que temos o texto extraído, passamos a usar o modo de pensamento do Soneto de Claude 3.7 modo de pensamento e fluxo para analisar vários documentos e gerar uma ideia de pesquisa estruturada.
O modo de streaming garante o tratamento eficiente de grandes respostas, fornecendo resultados progressivamente, reduzindo os tempos de espera e evitando o tempo limite da API. O modo de pensamento aprimora o raciocínio complexo, permitindo que o modelo gere pensamentos internos estruturados antes de formular uma resposta final, garantindo insights bem justificados.
# Function to analyze research papers with streaming
def analyze_papers_streaming(paper_texts, paper_count):
"""Uses Claude 3.7 Sonnet with Thinking Mode in streaming mode to analyze papers, find drawbacks, and generate a research project."""
formatted_papers = "\n\n".join([f"### Paper {i+1}:\n{paper}" for i, paper in enumerate(paper_texts)])
prompt = f"""
You are an AI research assistant. You have been provided with {paper_count} research papers.
Your task is to analyze these papers and perform the following:
1. **Summarize each paper** with its core contributions and findings.
2. **Identify key drawbacks** of each paper, focusing on limitations, gaps, or areas needing improvement.
3. **Find interconnections and citations** between the papers—what ideas, methods, or datasets do they share?
4. **Propose a novel research idea** that addresses a major limitation across these papers.
- Suggest how techniques from different papers can be combined to solve a problem.
- Ensure the idea is practical and feasible for further research.
- Justify why this approach is promising.
Below are the research papers
{formatted_papers}
"""
results = {"thinking": "", "research_idea": ""}
with client.messages.stream(
model="claude-3-7-sonnet-20250219",
max_tokens=25000,
thinking={
"type": "enabled",
"budget_tokens": 16000 # Large budget for deep reasoning
},
messages=[{"role": "user", "content": prompt}]
) as stream:
current_block_type = None
for event in stream:
if event.type == "content_block_start":
current_block_type = event.content_block.type
elif event.type == "content_block_delta":
if event.delta.type == "thinking_delta":
results["thinking"] += event.delta.thinking
elif event.delta.type == "text_delta":
results["research_idea"] += event.delta.text
elif event.type == "message_stop":
break
return results["thinking"], results["research_idea"]A função analyze_papers_streaming() executa as seguintes etapas:
client.messages.stream() para enviar a solicitação ao Claude 3.7 Sonnet. Isso permite o modo de raciocínio com budget_tokens=16000 e max_tokens=25000 para aumentar a duração da resposta.content_block_start para indicar o início de um bloco de resposta. À medida que o modelo gera resultados, os eventos thinking_delta contêm etapas intermediárias de raciocínio, enquanto os eventos text_delta fornecem os insights finais da pesquisa. O processo continua até que um evento message_stop sinalize a conclusão da resposta.Você pode saber mais sobre como refinar as técnicas de estímulo para o pensamento ampliado aqui.
Agora que nossa lógica principal foi criada, continuamos a integrá-la ao Gradio, permitindo que os usuários façam upload de artigos de pesquisa e recebam insights estruturados.
# Gradio UI function
def gradio_interface(pdfs):
paper_texts = [extract_text_from_pdf(pdf.name) for pdf in pdfs]
paper_count = len(paper_texts) # Count number of provided papers
thinking, research_idea = analyze_papers_streaming(paper_texts, paper_count)
return thinking, research_idea
# Set up the Gradio app
demo = gr.Interface(
fn=gradio_interface,
inputs=gr.File(file_types=[".pdf"], label="Upload Research Papers", file_count="multiple"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Research Idea")],
title="Claude 3.7 Sonnet - Powered Research Paper Analyzer",
description="Upload multiple research papers to extract insights, identify key limitations, and generate a novel research idea."
)
if __name__ == "__main__":
demo.launch(debug=True)O código acima configura uma UI do Gradio em que os usuários podem carregar vários PDFs, que são processados para extrair texto, analisar insights importantes e gerar novas ideias de pesquisa usando o modo pensamento e modo de fluxo.
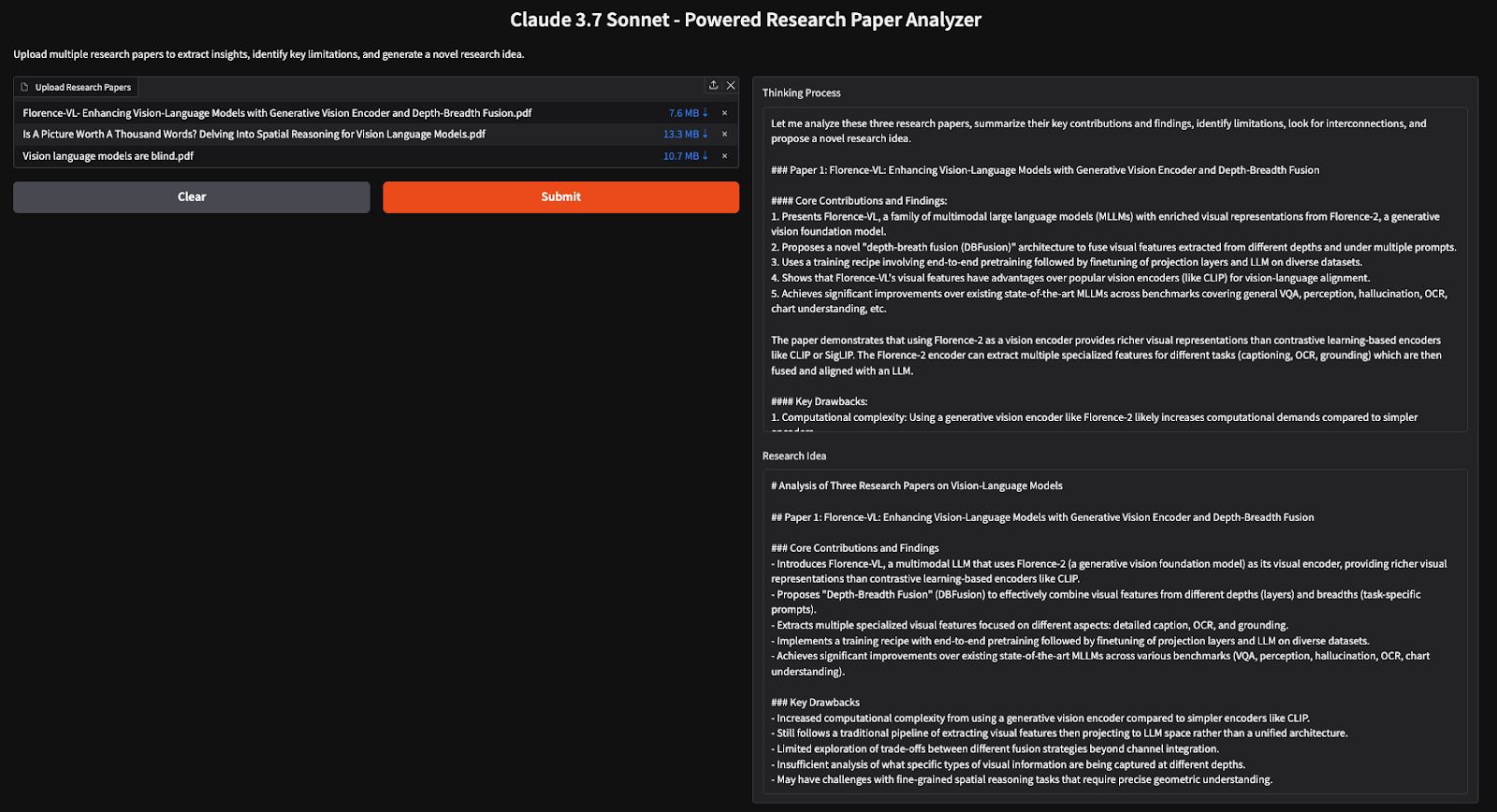
Neste tutorial, criamos um analisador de artigos de pesquisa com tecnologia de IA usando o Claude 3.7 Sonnet, permitindo que os pesquisadores extraiam insights com eficiência, identifiquem limitações e gerem novas ideias de pesquisa a partir de vários artigos. Ao usar o modo de pensamento, o modelo executa um raciocínio profundo, tornando-o uma ferramenta eficaz para revisões de literatura e síntese de pesquisa.
Aprenda IA com estes cursos!
Programa
Programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Zoumana Keita


