
Kurs
Einstieg in die Netzwerkanalyse mit Python
4 Std.
74.1K
Dijkstra ist der beliebteste Algorithmus, um den kürzesten Weg zwischen zwei Punkten in einem Netzwerk zu finden, und hat viele Anwendungen. Sie ist grundlegend für die Informatik und die Graphentheorie. Sie zu verstehen und zu lernen, sie zu implementieren, öffnet die Türen zu fortgeschritteneren Graphenalgorithmen und Anwendungen.
Durch den Greedy-Algorithmus, bei dem in jedem Schritt eine optimale Entscheidung auf der Grundlage der aktuellen Informationen getroffen wird, wird außerdem ein wertvoller Problemlösungsansatz vermittelt.
Diese Fähigkeit ist auf andere Optimierungsalgorithmen übertragbar. Der Dijkstra-Algorithmus ist vielleicht nicht in allen Fällen der effizienteste, aber er kann eine gute Grundlage für die Lösung von Problemen mit der kürzesten Entfernung sein.
Beispiele dafür sind:
Auch wenn du dich nicht für diese Dinge interessierst, kannst du mit der Implementierung von Dijkstras Algorithmus in Python wichtige Konzepte üben, wie zum Beispiel:
Um Dijkstras Algorithmus in Python zu implementieren, müssen wir ein paar wichtige Konzepte aus der Graphentheorie auffrischen. Zunächst einmal haben wir die Diagramme selbst:
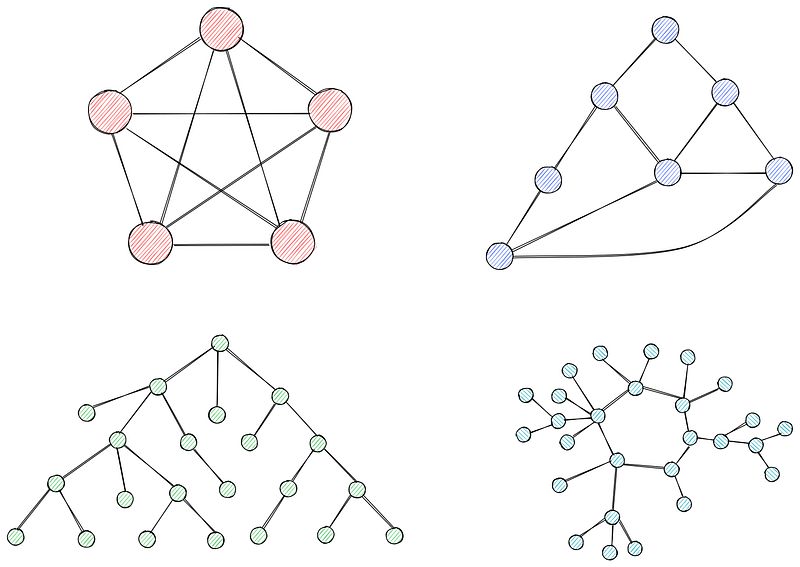
Graphen sind Sammlungen von Knoten (Vertices), die durch Kanten verbunden sind. Knoten repräsentieren Entitäten oder Punkte in einem Netzwerk, während Kanten die Verbindung oder Beziehungen zwischen ihnen darstellen.
Diagramme können gewichtet oder ungewichtet sein. In ungewichteten Graphen haben alle Kanten das gleiche Gewicht (oft auf 1 gesetzt). In gewichteten Graphen (du hast es erraten) ist jeder Kante ein Gewicht zugeordnet, das oft die Kosten, die Entfernung oder die Zeit angibt.
Wir werden in diesem Tutorium gewichtete Graphen verwenden, da sie für den Dijkstra-Algorithmus erforderlich sind.
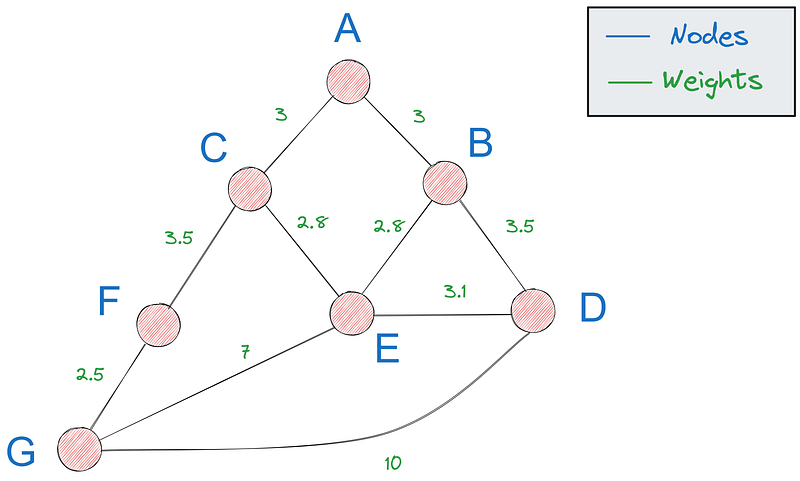
Ein Pfad in einem Graphen ist eine Folge von Knoten, die durch Kanten verbunden sind und an bestimmten Knoten beginnen und enden. Der kürzeste Weg, um den es in diesem Lernprogramm geht, ist der Weg mit dem geringsten Gesamtgewicht (Entfernung, Kosten usw.).
Für den Rest des Tutoriums werden wir das letzte Diagramm verwenden, das wir gesehen haben:
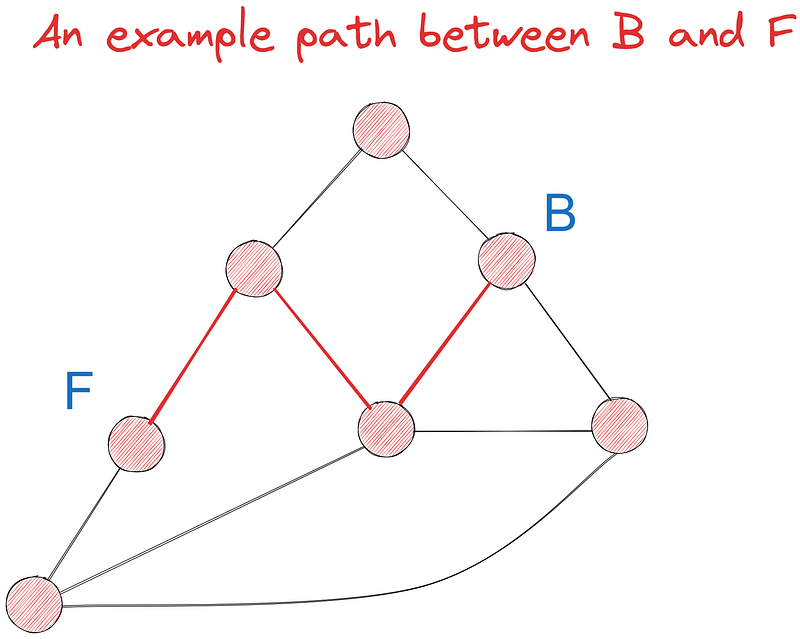
Versuchen wir, den kürzesten Weg zwischen den Punkten B und F mit dem Dijkstra-Algorithmus aus mindestens sieben möglichen Wegen zu finden. Zunächst werden wir die Aufgabe visuell erledigen und sie später in Code umsetzen.
Zuerst initialisieren wir den Algorithmus wie folgt:
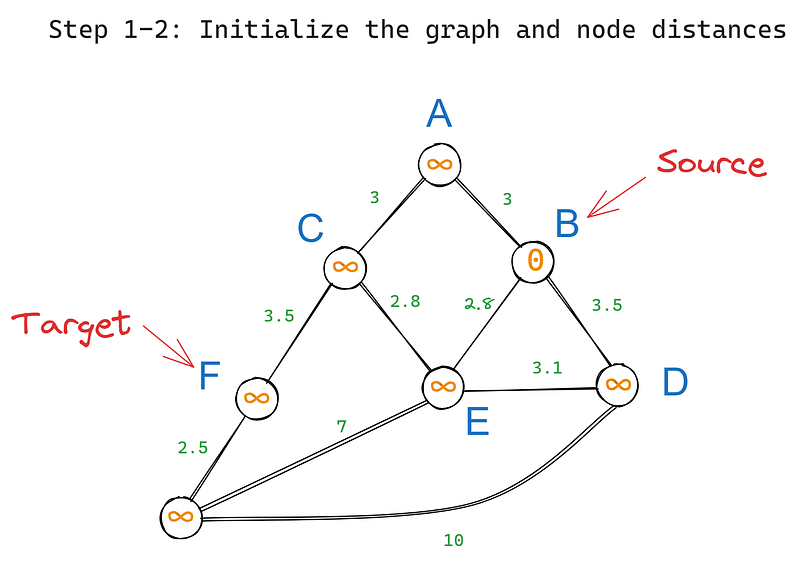
Dann führen wir die folgenden Schritte iterativ aus:
In unserem Graphen hat B drei Nachbarn - A, D und E. Wir besuchen jeden von ihnen, beginnend mit dem Wurzelknoten, und aktualisieren ihre Werte (Iteration 1) anhand ihrer Kantengewichte:
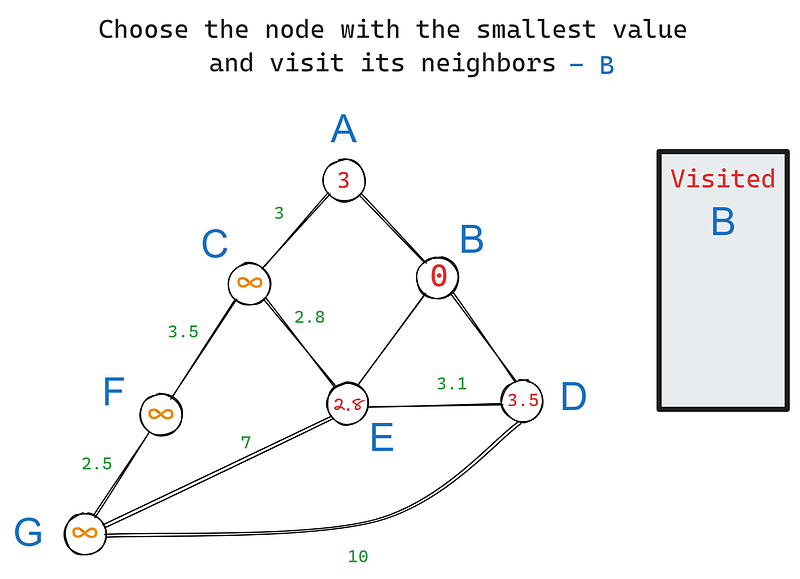
In Iteration 2 wählen wir wieder den Knoten mit dem kleinsten Wert, dieses Mal E. Seine Nachbarn sind C, D und G. B ist ausgeschlossen, weil wir ihn bereits besucht haben. Aktualisieren wir die Werte der Nachbarn von E:
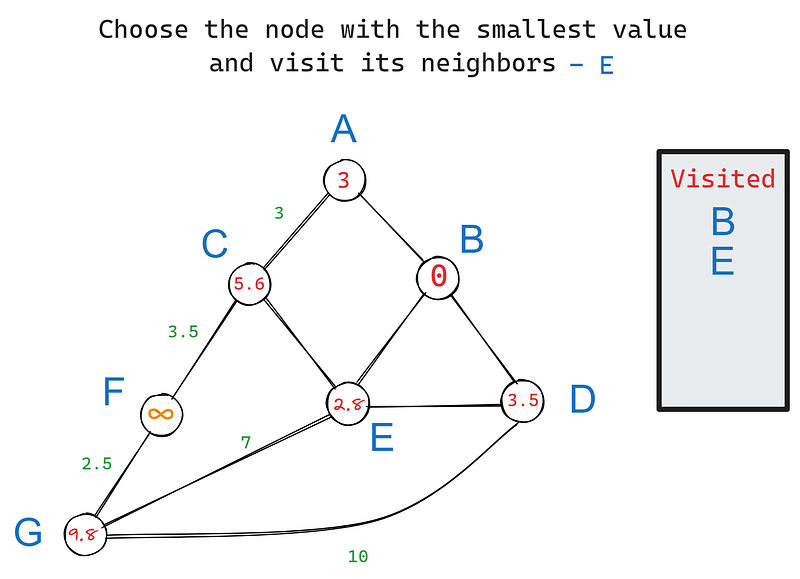
Wir setzen den Wert von C auf 5,6, weil sein Wert die kumulative Summe der Gewichte von B bis C ist. Dasselbe gilt für G. Wie du siehst, bleibt der Wert von D jedoch bei 3,5, obwohl er wie bei den anderen Knoten 3,5 + 2,8 = 6,3 sein sollte.
Die Regel lautet: Wenn die neue kumulative Summe größer ist als der aktuelle Wert des Knotens, aktualisieren wir ihn nicht, weil der Knoten bereits die kürzeste Entfernung zur Wurzel angibt. In diesem Fall hat D mit seinem aktuellen Wert von 3,5 bereits die kürzeste Entfernung zu B, weil sie Nachbarn sind.
Wir machen so weiter, bis alle Knotenpunkte besucht sind. Wenn das endlich passiert, haben wir die kürzeste Entfernung zu jedem Knoten von B und können einfach den Wert von B nach F nachschlagen.
Zusammengefasst sind das folgende Schritte:
Um dein Verständnis von Dijkstras Algorithmus zu festigen, werden wir nun lernen, ihn Schritt für Schritt in Python zu implementieren.
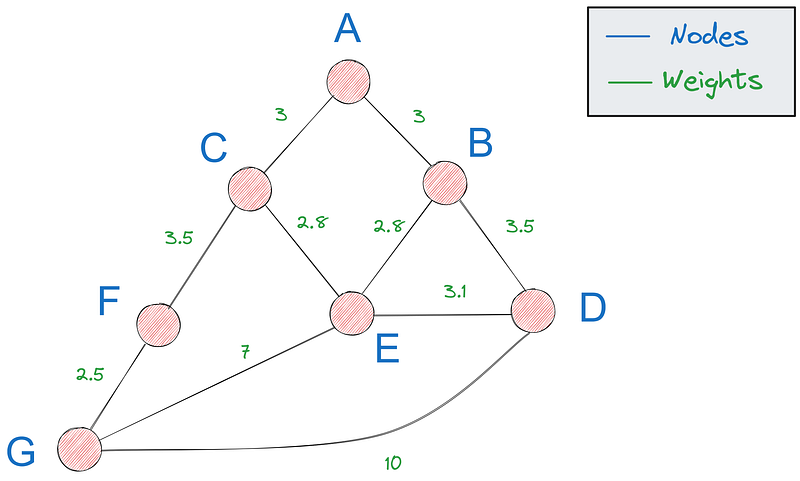
Zunächst brauchen wir eine Möglichkeit, Graphen in Python darzustellen - die beliebteste Option ist die Verwendung eines Wörterbuchs. Wenn das unser Diagramm ist:
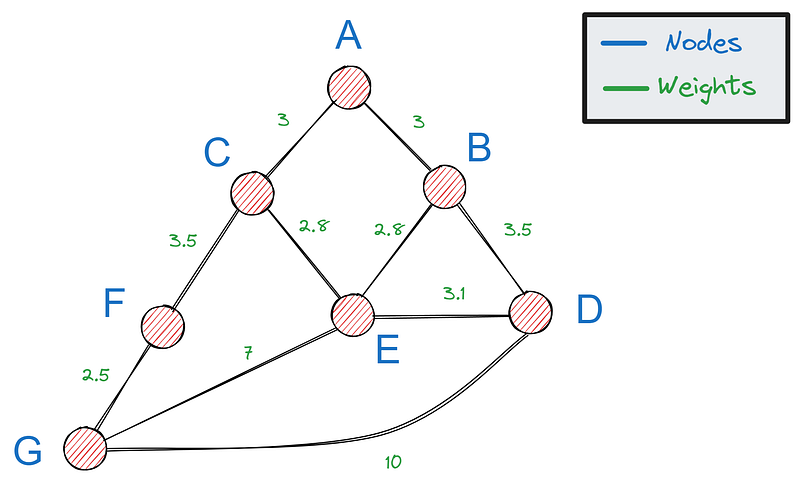
Wir können es mit dem folgenden Wörterbuch darstellen:
graph = {
"A": {"B": 3, "C": 3},
"B": {"A": 3, "D": 3.5, "E": 2.8},
"C": {"A": 3, "E": 2.8, "F": 3.5},
"D": {"B": 3.5, "E": 3.1, "G": 10},
"E": {"B": 2.8, "C": 2.8, "D": 3.1, "G": 7},
"F": {"G": 2.5, "C": 3.5},
"G": {"F": 2.5, "E": 7, "D": 10},
}
Jeder Schlüssel des Wörterbuchs ist ein Knoten und jeder Wert ist ein Wörterbuch, das die Nachbarn des Schlüssels und die Entfernungen zu ihm enthält. Unser Graph hat sieben Knoten, was bedeutet, dass das Wörterbuch sieben Schlüssel haben muss.
In anderen Quellen wird das obige Wörterbuch oft als Wörterbuch-Adjazenzliste bezeichnet. Wir werden diesen Begriff auch in Zukunft beibehalten.
Graph KlasseUm unseren Code modularer und übersichtlicher zu gestalten, werden wir eine einfache Graph Klasse implementieren, um Graphen darzustellen. Unter der Haube wird eine Wörterbuch-Adjazenzliste verwendet. Außerdem wird es eine Methode geben, mit der du ganz einfach Verbindungen zwischen zwei Knotenpunkten hinzufügen kannst:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph # A dictionary for the adjacency list
def add_edge(self, node1, node2, weight):
if node1 not in self.graph: # Check if the node is already added
self.graph[node1] = {} # If not, create the node
self.graph[node1][node2] = weight # Else, add a connection to its neighbor
Mit dieser Klasse können wir unseren Graphen iterativ von Grund auf neu konstruieren:
G = Graph()
# Add A and its neighbors
G.add_edge("A", "B", 3)
G.add_edge("A", "C", 3)
# Add B and its neighbors
G.add_edge("B", "A", 3)
G.add_edge("B", "D", 3.5)
G.add_edge("B", "E", 2.8)
...
Wir können aber auch direkt eine Wörterbuch-Adjazenzliste übergeben, was eine schnellere Methode ist:
# Use the dictionary we defined earlier
G = Graph(graph=graph)
G.graph
{'A': {'B': 3, 'C': 3},
'B': {'A': 3, 'D': 3.5, 'E': 2.8},
'C': {'A': 3, 'E': 2.8, 'F': 3.5},
'D': {'B': 3.5, 'E': 3.1, 'G': 10},
'E': {'B': 2.8, 'C': 2.8, 'D': 3.1, 'G': 7},
'F': {'G': 2.5, 'C': 3.5},
'G': {'F': 2.5, 'E': 7, 'D': 10}}
Wir erstellen eine weitere Klassenmethode - dieses Mal für den Algorithmus selbst -shortest_distances:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph
# The add_edge method omitted for space
def shortest_distances(self, source: str):
# Initialize the values of all nodes with infinity
distances = {node: float("inf") for node in self.graph}
distances[source] = 0 # Set the source value to 0
...
Das erste, was wir innerhalb der Methode tun, ist, ein Wörterbuch zu definieren, das Knoten-Werte-Paare enthält. Dieses Wörterbuch wird jedes Mal aktualisiert, wenn wir einen Knoten und seine Nachbarn besuchen. Wie in der visuellen Erklärung des Algorithmus erwähnt, werden die Anfangswerte aller Knoten auf unendlich gesetzt, während der Wert der Quelle 0 ist.
Wenn wir mit dem Schreiben der Methode fertig sind, wird dieses Wörterbuch zurückgegeben und enthält die kürzesten Entfernungen zu allen Knoten von der Quelle. So können wir die Entfernung von B nach F ermitteln:
# Sneak-peek - find the shortest paths from B
distances = G.shortest_distances("B")
to_F = distances["F"]
print(f"The shortest distance from B to F is {to_F}")
Jetzt brauchen wir einen Weg, um eine Schleife über die Knoten des Graphen zu ziehen, die auf den Regeln des Dijkstra-Algorithmus basiert. Wenn du dich erinnerst, müssen wir in jeder Iteration den Knoten mit dem kleinsten Wert auswählen und seine Nachbarn besuchen.
Du könntest sagen, dass wir einfach eine Schleife über die Wörterbuchschlüssel machen können:
for node in graph.keys():
...
Diese Methode funktioniert nicht, da sie uns keine Möglichkeit gibt, die Knoten nach ihrem Wert zu sortieren. Einfache Arrays reichen also nicht aus. Um diesen Teil des Problems zu lösen, verwenden wir eine sogenannte Prioritätswarteschlange.
Eine Prioritäts-Warteschlange ist wie eine normale Liste (Array), aber jedes ihrer Elemente hat einen zusätzlichen Wert, der ihre Priorität darstellt. Dies ist ein Beispiel für eine Prioritätswarteschlange:
pq = [(3, "A"), (1, "C"), (7, "D")]Diese Warteschlange enthält drei Elemente - A, C und D - und jedes von ihnen hat einen Prioritätswert, der bestimmt, wie die Operationen in der Warteschlange durchgeführt werden. Python bietet eine integrierte heapq Bibliothek, um mit Prioritätswarteschlangen zu arbeiten:
from heapq import heapify, heappop, heappushDie Bibliothek hat drei Funktionen, die uns interessieren:
heapify: Verwandelt eine Liste von Tupeln mit Priorität-Wert-Paaren in eine Prioritätswarteschlange.heappush: Fügt der Warteschlange ein Element mit der entsprechenden Priorität hinzu.heappop: Entfernt und gibt das Element mit der höchsten Priorität zurück (das Element mit dem kleinsten Wert).pq = [(3, "A"), (1, "C"), (7, "D")]
# Convert into a queue object
heapify(pq)
# Return the highest priority value
heappop(pq)
(1, 'C')Wie du siehst, konnten wir, nachdem wir pq mit heapify in eine Warteschlange umgewandelt haben, C anhand seiner Priorität extrahieren. Lass uns versuchen, einen Wert zu drücken:
heappush(pq, (0, "B"))
heappop(pq)
(0, 'B')Die Warteschlange wird anhand der Priorität des neuen Elements korrekt aktualisiert, da heappop das neue Element mit der Priorität 0 zurückgegeben hat.
Beachte, dass ein Element nicht mehr Teil der Warteschlange ist, nachdem wir es herausgenommen haben.
Zurück zu unserem Algorithmus: Nachdem wir distances initialisiert haben, erstellen wir eine neue Prioritätswarteschlange, die zunächst nur den Quellknoten enthält:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph
def shortest_distances(self, source: str):
# Initialize the values of all nodes with infinity
distances = {node: float("inf") for node in self.graph}
distances[source] = 0 # Set the source value to 0
# Initialize a priority queue
pq = [(0, source)]
heapify(pq)
# Create a set to hold visited nodes
visited = set()
Die Priorität eines jeden Elements innerhalb von pq ist sein aktueller Wert. Wir initialisieren auch eine leere Menge, um die besuchten Knoten aufzuzeichnen.
while SchleifeJetzt beginnen wir, mit einer while Schleife über alle nicht besuchten Knoten zu iterieren:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph
def shortest_distances(self, source: str):
# Initialize the values of all nodes with infinity
distances = {node: float("inf") for node in self.graph}
distances[source] = 0 # Set the source value to 0
# Initialize a priority queue
pq = [(0, source)]
heapify(pq)
# Create a set to hold visited nodes
visited = set()
while pq: # While the priority queue isn't empty
current_distance, current_node = heappop(
pq
) # Get the node with the min distance
if current_node in visited:
continue # Skip already visited nodes
visited.add(current_node) # Else, add the node to visited set
Solange die Prioritäts-Warteschlange nicht leer ist, lassen wir den Knoten mit der höchsten Priorität (mit dem niedrigsten Wert) fallen und extrahieren seinen Wert und Namen auf current_distance und current_node. Wenn die current_node innerhalb von visited liegt, überspringen wir sie. Andernfalls markieren wir ihn als besucht und fahren dann mit dem Besuch seiner Nachbarn fort:
while pq: # While the priority queue isn't empty
current_distance, current_node = heappop(pq)
if current_node in visited:
continue
visited.add(current_node)
for neighbor, weight in self.graph[current_node].items():
# Calculate the distance from current_node to the neighbor
tentative_distance = current_distance + weight
if tentative_distance < distances[neighbor]:
distances[neighbor] = tentative_distance
heappush(pq, (tentative_distance, neighbor))
return distances
Für jeden Nachbarn berechnen wir die vorläufige Entfernung zum aktuellen Knoten, indem wir den aktuellen Wert des Nachbarn zum Gewicht der Verbindungskante addieren. Dann prüfen wir, ob der Abstand kleiner ist als der Abstand des Nachbarn in distances. Wenn ja, aktualisieren wir das distances Wörterbuch und fügen den Nachbarn mit seiner vorläufigen Entfernung in die Prioritätswarteschlange ein.
Das war's! Wir haben den Algorithmus von Dijkstra implementiert. Testen wir es:
G = Graph(graph)
distances = G.shortest_distances("B")
print(distances, "\n")
to_F = distances["F"]
print(f"The shortest distance from B to F is {to_F}")
{'A': 3, 'B': 0, 'C': 5.6, 'D': 3.5, 'E': 2.8, 'F': 9.1, 'G': 9.8}
The shortest distance from B to F is 9.1
Die Entfernung von B nach F ist also 9,1. Aber halt: Welcher Weg ist es?
Wir haben also nur die kürzesten Entfernungen und nicht die Wege, wodurch unser Diagramm so aussieht:
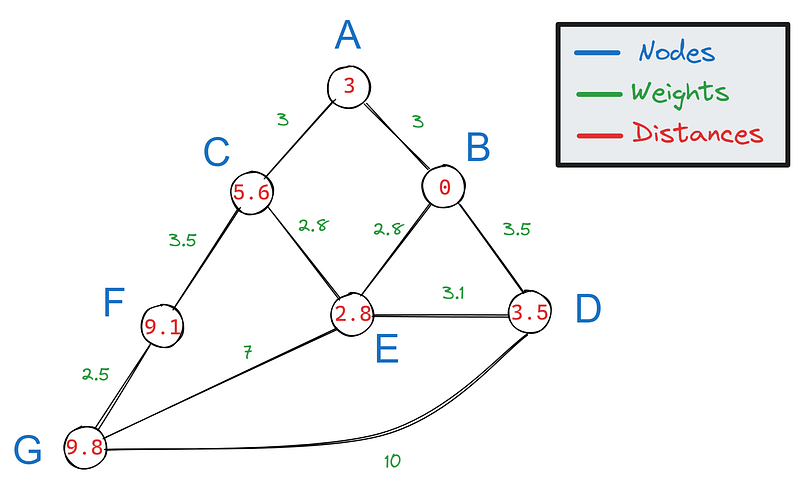
Um den kürzesten Weg aus der berechneten kürzesten Entfernung zu konstruieren, können wir unsere Schritte vom Ziel aus zurückverfolgen. Für jede Kante, die mit F verbunden ist, ziehen wir ihr Gewicht ab:
Dann schauen wir, ob eines der Ergebnisse mit dem Wert der Nachbarn von F übereinstimmt. Nur 5,6 stimmt mit dem Wert von C überein, was bedeutet, dass C Teil des kürzesten Weges ist.
Wir wiederholen diesen Vorgang für die Nachbarn von C, A und E:
Da 2,8 mit dem Wert von E übereinstimmt, ist er Teil des kürzesten Weges. E ist auch der Nachbar von B, so dass der kürzeste Weg zwischen B und F - BECF ist.
Fügen wir die Implementierung dieses Prozesses zu unserer Klasse hinzu. Der Code selbst unterscheidet sich ein wenig von der obigen Erklärung, da er die kürzesten Wege zwischen B und allen anderen Knotenpunkten findet, nicht nur F.
Es geht auch umgekehrt, aber die Idee ist die gleiche.
Füge die folgenden Codezeilen am Ende der Methode shortest_distances hinzu und lösche die alte Anweisung return:
predecessors = {node: None for node in self.graph}
for node, distance in distances.items():
for neighbor, weight in self.graph[node].items():
if distances[neighbor] == distance + weight:
predecessors[neighbor] = node
return distances, predecessors
Wenn der Code ausgeführt wird, enthält das predecessors Wörterbuch die unmittelbaren Eltern jedes Knotens, der am kürzesten Weg zur Quelle beteiligt ist. Lass es uns versuchen:
G = Graph(graph)
distances, predecessors = G.shortest_distances("B")
print(predecessors)
{'A': 'B', 'B': None, 'C': 'E', 'D': 'B', 'E': 'B', 'F': 'C', 'G': 'E'}Zuerst wollen wir den kürzesten Weg manuell mit dem predecessors Wörterbuch finden, indem wir von F aus zurückgehen:
# Check the predecessor of F
predecessors["F"]
'C' # It is C# Check the predecessor of C
predecessors["C"]
'E' # It is E# Check the predecessor of E
predecessors["E"]
'B' # It is BSo geht's! Das Wörterbuch sagt uns richtig, dass der kürzeste Weg zwischen B und F BECF ist.
Aber wir haben die Methode halb-manuell gefunden. Wir wollen eine Methode, die automatisch den kürzesten Pfad aus dem predecessors Wörterbuch von einer beliebigen Quelle zu einem beliebigen Ziel liefert. Wir definieren diese Methode als shortest_path (füge sie an das Ende der Klasse an):
def shortest_path(self, source: str, target: str):
# Generate the predecessors dict
_, predecessors = self.shortest_distances(source)
path = []
current_node = target
# Backtrack from the target node using predecessors
while current_node:
path.append(current_node)
current_node = predecessors[current_node]
# Reverse the path and return it
path.reverse()
return path
Mit der Funktion shortest_distances erstellen wir das Wörterbuch predecessors. Dann starten wir eine while-Schleife, die in jeder Iteration einen Knoten vom aktuellen Knoten zurückgeht, bis der Ausgangsknoten erreicht ist. Dann geben wir die umgekehrte Liste zurück, die den Pfad von der Quelle zum Ziel enthält.
Testen wir es:
G = Graph(graph)
G.shortest_path("B", "F")
['B', 'E', 'C', 'F']Es funktioniert! Versuchen wir es mit einer anderen:
G.shortest_path("A", "G")['A', 'C', 'F', 'G']Richtig so.
In diesem Tutorium haben wir einen der grundlegendsten Algorithmen der Graphentheorie kennengelernt - den Dijkstra-Algorithmus. Er ist oft der bevorzugte Algorithmus, um den kürzesten Weg zwischen zwei Punkten in graphenähnlichen Strukturen zu finden. Aufgrund seiner Einfachheit wird es in vielen Branchen eingesetzt, z. B. in
Ich hoffe, die Implementierung von Dijkstras Algorithmus in Python hat dein Interesse an der wunderbaren Welt der Graphenalgorithmen geweckt. Wenn du mehr erfahren möchtest, empfehle ich dir die folgenden Ressourcen:
Setze deine Python-Reise heute fort!
Kurs
Kurs
Kurs