Curso
Introdução à Análise de Redes em Python
4 h
74.1K
O algoritmo de Dijkstra é o algoritmo ideal para encontrar o caminho mais curto entre dois pontos em uma rede, o que tem muitas aplicações. É fundamental na ciência da computação e na teoria dos gráficos. Compreender e aprender a implementá-lo abre as portas para algoritmos e aplicativos de gráficos mais avançados.
Ele também ensina uma valiosa abordagem de solução de problemas por meio de seu algoritmo guloso, que envolve fazer a escolha ideal em cada etapa com base nas informações atuais.
Essa habilidade pode ser transferida para outros algoritmos de otimização. O algoritmo de Dijkstra pode não ser o mais eficiente em todos os cenários, mas pode ser uma boa base para resolver problemas de "distância mais curta".
Os exemplos incluem:
Mesmo que você não esteja interessado em nenhuma dessas coisas, a implementação do algoritmo de Dijkstra em Python permitirá que você pratique conceitos importantes, como:
Para implementar o algoritmo de Dijkstra em Python, precisamos atualizar alguns conceitos essenciais da teoria dos gráficos. Em primeiro lugar, temos os próprios gráficos:
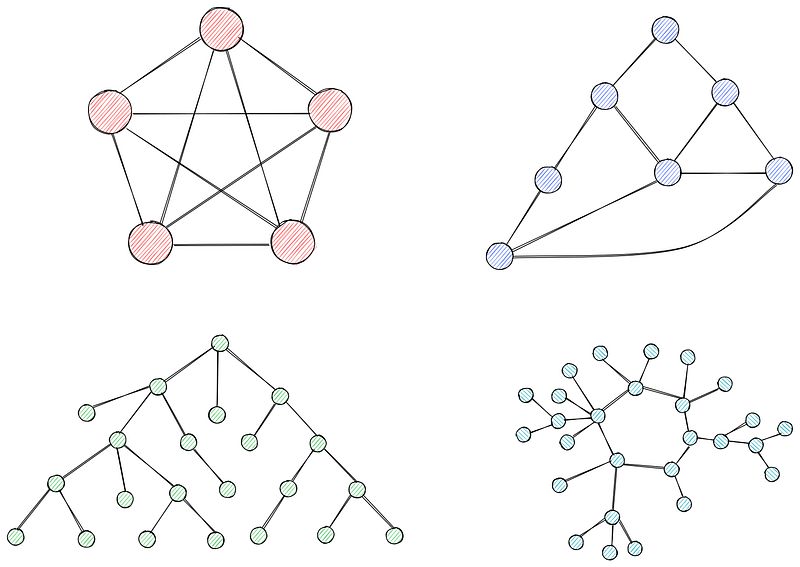
Os gráficos são coleções de nós (vértices) conectados por bordas. Os nós representam entidades ou pontos em uma rede, enquanto as bordas representam a conexão ou os relacionamentos entre eles.
Os gráficos podem ser ponderados ou não ponderados. Em gráficos não ponderados, todas as bordas têm o mesmo peso (geralmente definido como 1). Em gráficos ponderados (você adivinhou), cada borda tem um peso associado a ela, geralmente representando custo, distância ou tempo.
No tutorial, usaremos gráficos ponderados, pois eles são necessários para o algoritmo de Dijkstra.
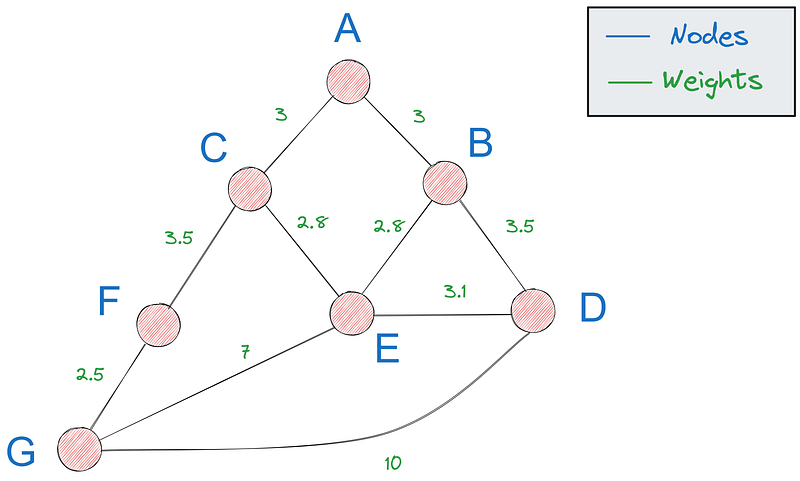
Um caminho em um gráfico refere-se a uma sequência de nós conectados por bordas, começando e terminando em nós específicos. O caminho mais curto, com o qual nos preocupamos neste tutorial, é o caminho com o peso total mínimo (distância, custo, etc.).
No restante do tutorial, usaremos o último gráfico que vimos:
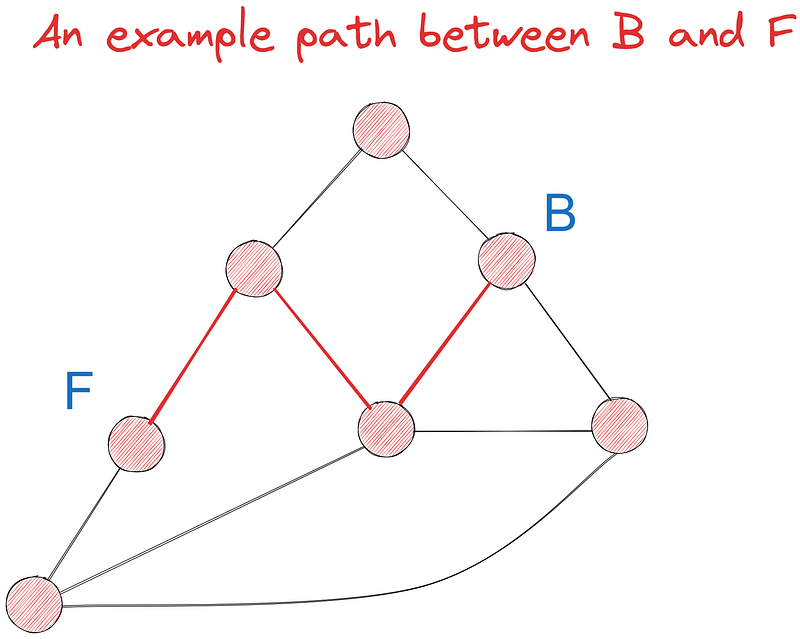
Vamos tentar encontrar o caminho mais curto entre os pontos B e F usando o algoritmo de Dijkstra, dentre pelo menos sete caminhos possíveis. Inicialmente, faremos a tarefa visualmente e a implementaremos no código mais tarde.
Primeiro, inicializamos o algoritmo da seguinte forma:
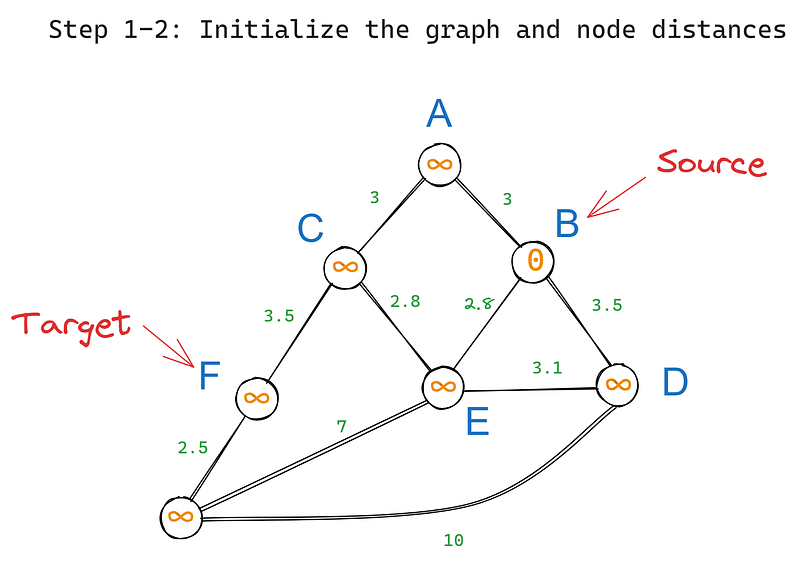
Em seguida, executamos as seguintes etapas de forma iterativa:
Em nosso gráfico, B tem três vizinhos - A, D e E. Vamos visitar cada um deles começando pelo nó raiz e atualizar seus valores (iteração 1) com base em seus pesos de borda:
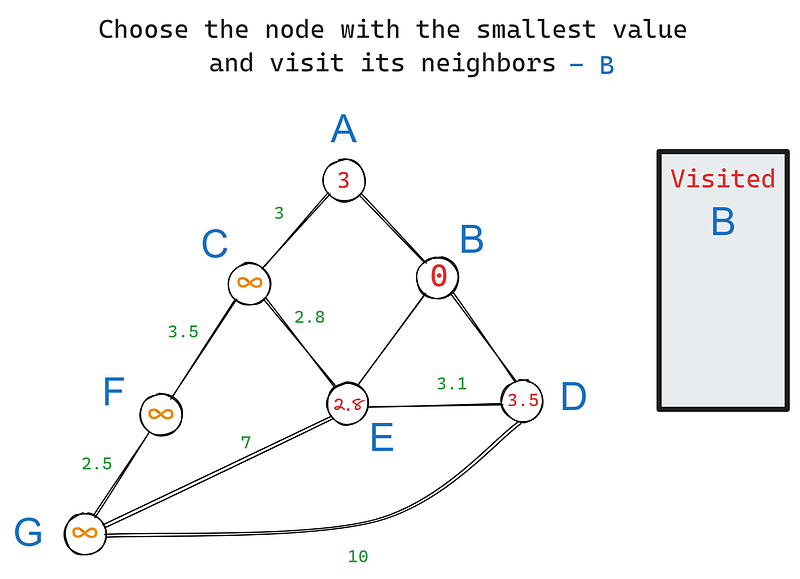
Na iteração 2, escolhemos novamente o nó com o menor valor, desta vez - E. Seus vizinhos são C, D e G. B é excluído porque já o visitamos. Seus vizinhos são C, D e G. B é excluído porque já o visitamos. Vamos atualizar os valores dos vizinhos de E:
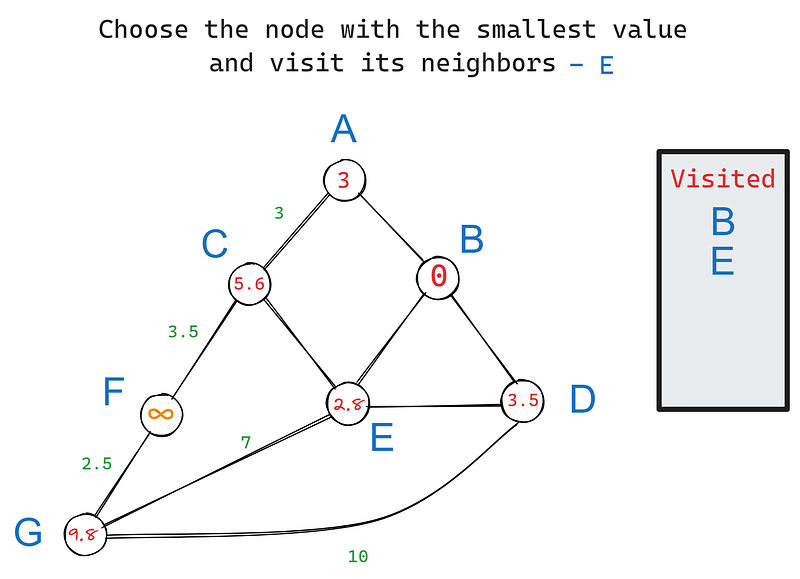
Definimos o valor de C como 5,6 porque seu valor é a soma cumulativa dos pesos de B a C. O mesmo vale para G. No entanto, se você observar, o valor de D permanece 3,5 quando deveria ser 3,5 + 2,8 = 6,3, como nos outros nós.
A regra é que, se a nova soma cumulativa for maior que o valor atual do nó, não a atualizaremos porque o nó já lista a distância mais curta até a raiz. Nesse caso, o valor atual de 3,5 de D já indica a distância mais curta até B porque eles são vizinhos.
Continuamos dessa forma até que todos os nós sejam visitados. Quando isso finalmente acontecer, você terá a distância mais curta para cada nó a partir de B e poderá simplesmente procurar o valor de B a F.
Em resumo, as etapas são:
Agora, para solidificar a compreensão que você tem do algoritmo de Dijkstra, aprenderemos a implementá-lo em Python passo a passo.
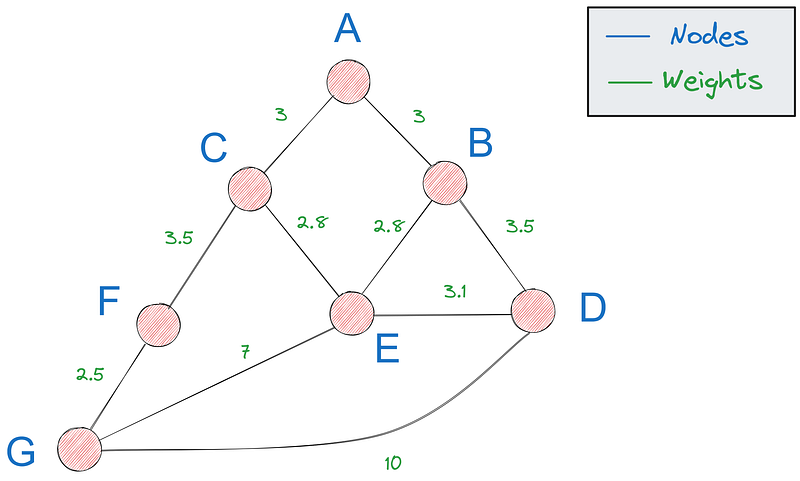
Primeiro, precisamos de uma maneira de representar gráficos em Python - a opção mais popular é usar um dicionário. Se esse for o nosso gráfico:
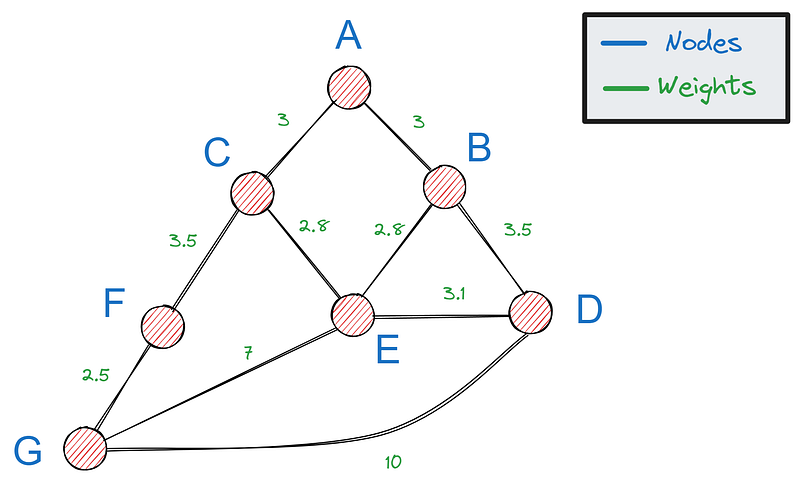
Podemos representá-lo com o seguinte dicionário:
graph = {
"A": {"B": 3, "C": 3},
"B": {"A": 3, "D": 3.5, "E": 2.8},
"C": {"A": 3, "E": 2.8, "F": 3.5},
"D": {"B": 3.5, "E": 3.1, "G": 10},
"E": {"B": 2.8, "C": 2.8, "D": 3.1, "G": 7},
"F": {"G": 2.5, "C": 3.5},
"G": {"F": 2.5, "E": 7, "D": 10},
}
Cada chave do dicionário é um nó e cada valor é um dicionário que contém os vizinhos da chave e as distâncias até ela. Nosso gráfico tem sete nós, o que significa que o dicionário deve ter sete chaves.
Outras fontes geralmente se referem ao dicionário acima como uma lista de adjacência de dicionário. Também usaremos esse termo a partir de agora.
Graph classePara tornar nosso código mais modular e fácil de acompanhar, implementaremos uma classe Graph simples para representar gráficos. Por baixo do capô, ele usará uma lista de adjacência de dicionário. Ele também terá um método para adicionar facilmente conexões entre dois nós:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph # A dictionary for the adjacency list
def add_edge(self, node1, node2, weight):
if node1 not in self.graph: # Check if the node is already added
self.graph[node1] = {} # If not, create the node
self.graph[node1][node2] = weight # Else, add a connection to its neighbor
Usando essa classe, podemos construir nosso gráfico iterativamente a partir do zero, assim:
G = Graph()
# Add A and its neighbors
G.add_edge("A", "B", 3)
G.add_edge("A", "C", 3)
# Add B and its neighbors
G.add_edge("B", "A", 3)
G.add_edge("B", "D", 3.5)
G.add_edge("B", "E", 2.8)
...
Ou podemos passar uma lista de adjacência de dicionário diretamente, o que é um método mais rápido:
# Use the dictionary we defined earlier
G = Graph(graph=graph)
G.graph
{'A': {'B': 3, 'C': 3},
'B': {'A': 3, 'D': 3.5, 'E': 2.8},
'C': {'A': 3, 'E': 2.8, 'F': 3.5},
'D': {'B': 3.5, 'E': 3.1, 'G': 10},
'E': {'B': 2.8, 'C': 2.8, 'D': 3.1, 'G': 7},
'F': {'G': 2.5, 'C': 3.5},
'G': {'F': 2.5, 'E': 7, 'D': 10}}
Criamos outro método de classe - desta vez para o próprio algoritmo -shortest_distances:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph
# The add_edge method omitted for space
def shortest_distances(self, source: str):
# Initialize the values of all nodes with infinity
distances = {node: float("inf") for node in self.graph}
distances[source] = 0 # Set the source value to 0
...
A primeira coisa que fazemos dentro do método é definir um dicionário que contenha pares de valores de nós. Esse dicionário é atualizado sempre que visitamos um nó e seus vizinhos. Como mencionamos na explicação visual do algoritmo, os valores iniciais de todos os nós são definidos como infinitos, enquanto o valor da fonte é 0.
Quando terminarmos de escrever o método, esse dicionário será retornado e terá as distâncias mais curtas para todos os nós da origem. Poderemos encontrar a distância de B a F da seguinte forma:
# Sneak-peek - find the shortest paths from B
distances = G.shortest_distances("B")
to_F = distances["F"]
print(f"The shortest distance from B to F is {to_F}")
Agora, precisamos de uma maneira de percorrer os nós do gráfico com base nas regras do algoritmo de Dijkstra. Se você se lembrar, em cada iteração, precisamos escolher o nó com o menor valor e visitar seus vizinhos.
Você pode dizer que podemos simplesmente fazer um loop sobre as chaves do dicionário:
for node in graph.keys():
...
Esse método não funciona, pois não nos dá nenhuma maneira de classificar os nós com base em seu valor. Portanto, matrizes simples não serão suficientes. Para resolver essa parte do problema, usaremos algo chamado fila de prioridade.
Uma fila de prioridade é como uma lista normal (matriz), mas cada um de seus elementos tem um valor extra para representar sua prioridade. Este é um exemplo de fila de prioridade:
pq = [(3, "A"), (1, "C"), (7, "D")]Essa fila contém três elementos - A, C e D - e cada um deles tem um valor de prioridade que determina como as operações são realizadas na fila. O Python fornece uma biblioteca integrada heapq para que você trabalhe com filas de prioridade:
from heapq import heapify, heappop, heappushA biblioteca tem três funções que nos interessam:
heapify: Transforma uma lista de tuplas com pares de valores de prioridade em uma fila de prioridade.heappush: Adiciona um elemento à fila com sua prioridade associada.heappop: Remove e retorna o elemento com a prioridade mais alta (o elemento com o menor valor).pq = [(3, "A"), (1, "C"), (7, "D")]
# Convert into a queue object
heapify(pq)
# Return the highest priority value
heappop(pq)
(1, 'C')Como você pode ver, depois de converter pq em uma fila usando heapify, conseguimos extrair C com base em sua prioridade. Vamos tentar empurrar um valor:
heappush(pq, (0, "B"))
heappop(pq)
(0, 'B')A fila é atualizada corretamente com base na prioridade do novo elemento porque heappop retornou o novo elemento com prioridade 0.
Observe que, depois de abrirmos um item, ele não fará mais parte da fila.
Agora, voltando ao nosso algoritmo, depois de inicializarmos distances, criamos uma nova fila de prioridade que contém apenas o nó de origem inicialmente:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph
def shortest_distances(self, source: str):
# Initialize the values of all nodes with infinity
distances = {node: float("inf") for node in self.graph}
distances[source] = 0 # Set the source value to 0
# Initialize a priority queue
pq = [(0, source)]
heapify(pq)
# Create a set to hold visited nodes
visited = set()
A prioridade de cada elemento em pq será seu valor atual. Também inicializamos um conjunto vazio para registrar os nós visitados.
while loopAgora, começamos a iterar sobre todos os nós não visitados usando um loop while:
class Graph:
def __init__(self, graph: dict = {}):
self.graph = graph
def shortest_distances(self, source: str):
# Initialize the values of all nodes with infinity
distances = {node: float("inf") for node in self.graph}
distances[source] = 0 # Set the source value to 0
# Initialize a priority queue
pq = [(0, source)]
heapify(pq)
# Create a set to hold visited nodes
visited = set()
while pq: # While the priority queue isn't empty
current_distance, current_node = heappop(
pq
) # Get the node with the min distance
if current_node in visited:
continue # Skip already visited nodes
visited.add(current_node) # Else, add the node to visited set
Enquanto a fila de prioridades não estiver vazia, continuaremos a abrir o nó de prioridade mais alta (com o valor mínimo) e a extrair seu valor e nome para current_distance e current_node. Se o current_node estiver dentro de visited, você o ignorará. Caso contrário, nós o marcamos como visitado e, em seguida, passamos a visitar seus vizinhos:
while pq: # While the priority queue isn't empty
current_distance, current_node = heappop(pq)
if current_node in visited:
continue
visited.add(current_node)
for neighbor, weight in self.graph[current_node].items():
# Calculate the distance from current_node to the neighbor
tentative_distance = current_distance + weight
if tentative_distance < distances[neighbor]:
distances[neighbor] = tentative_distance
heappush(pq, (tentative_distance, neighbor))
return distances
Para cada vizinho, calculamos a distância provisória do nó atual adicionando o valor atual do vizinho ao peso da borda de conexão. Em seguida, verificamos se a distância é menor do que a distância do vizinho em distances. Em caso afirmativo, atualizamos o dicionário distances e adicionamos o vizinho com sua distância provisória à fila de prioridades.
É isso aí! Implementamos o algoritmo de Dijkstra. Vamos testá-lo:
G = Graph(graph)
distances = G.shortest_distances("B")
print(distances, "\n")
to_F = distances["F"]
print(f"The shortest distance from B to F is {to_F}")
{'A': 3, 'B': 0, 'C': 5.6, 'D': 3.5, 'E': 2.8, 'F': 9.1, 'G': 9.8}
The shortest distance from B to F is 9.1
Portanto, a distância de B a F é 9,1. Mas espere: qual é o caminho?
Portanto, temos apenas as distâncias mais curtas, não os caminhos, o que faz com que nosso gráfico tenha a seguinte aparência:
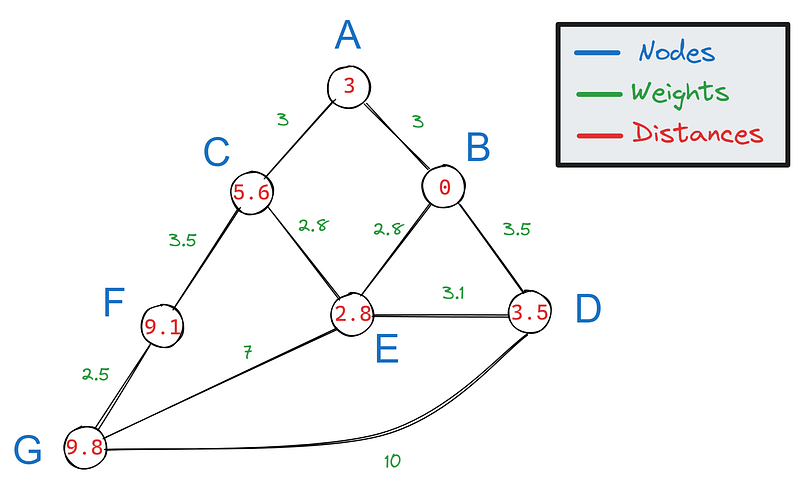
Para construir o caminho mais curto a partir da distância mais curta calculada, podemos retroceder nossas etapas a partir do alvo. Para cada borda conectada a F, subtraímos seu peso:
Em seguida, verificamos se algum dos resultados corresponde ao valor dos vizinhos de F. Apenas 5,6 corresponde ao valor de C, o que significa que C faz parte do caminho mais curto.
Repetimos esse processo novamente para os vizinhos de C, A e E:
Como 2,8 corresponde ao valor de E, ele faz parte do caminho mais curto. E também é vizinho de B, o que torna o caminho mais curto entre B e F - BECF.
Vamos adicionar a implementação desse processo à nossa classe. O código em si é um pouco diferente da explicação acima, pois ele encontra os caminhos mais curtos entre B e todos os outros nós, não apenas F. Você pode encontrar os caminhos mais curtos entre B e todos os outros nós.
Além disso, ele faz isso de forma inversa, mas a ideia é a mesma.
Adicione as seguintes linhas de código ao final do método shortest_distances, excluindo a antiga instrução return:
predecessors = {node: None for node in self.graph}
for node, distance in distances.items():
for neighbor, weight in self.graph[node].items():
if distances[neighbor] == distance + weight:
predecessors[neighbor] = node
return distances, predecessors
Quando o código é executado, o dicionário predecessors contém o pai imediato de cada nó envolvido no caminho mais curto para a origem. Vamos tentar:
G = Graph(graph)
distances, predecessors = G.shortest_distances("B")
print(predecessors)
{'A': 'B', 'B': None, 'C': 'E', 'D': 'B', 'E': 'B', 'F': 'C', 'G': 'E'}Primeiro, vamos encontrar o caminho mais curto manualmente usando o dicionário predecessors, retrocedendo a partir de F. Você pode encontrar o caminho mais curto manualmente usando o dicionário :
# Check the predecessor of F
predecessors["F"]
'C' # It is C# Check the predecessor of C
predecessors["C"]
'E' # It is E# Check the predecessor of E
predecessors["E"]
'B' # It is BLá vamos nós! O dicionário nos diz corretamente que o caminho mais curto entre B e F é BECF.
Mas descobrimos o método de forma semi-manual. Queremos um método que retorne automaticamente o caminho mais curto construído a partir do dicionário predecessors de qualquer origem para qualquer destino. Definimos esse método como shortest_path (adicione-o ao final da classe):
def shortest_path(self, source: str, target: str):
# Generate the predecessors dict
_, predecessors = self.shortest_distances(source)
path = []
current_node = target
# Backtrack from the target node using predecessors
while current_node:
path.append(current_node)
current_node = predecessors[current_node]
# Reverse the path and return it
path.reverse()
return path
Usando a função shortest_distances, geramos o dicionário predecessors. Em seguida, iniciamos um loop while que volta um nó a partir do nó atual em cada iteração até que o nó de origem seja alcançado. Em seguida, retornamos a lista invertida, que contém o caminho da origem até o destino.
Vamos testá-lo:
G = Graph(graph)
G.shortest_path("B", "F")
['B', 'E', 'C', 'F']Funciona! Vamos tentar outra:
G.shortest_path("A", "G")['A', 'C', 'F', 'G']É como se você estivesse na chuva.
Neste tutorial, aprendemos um dos algoritmos mais fundamentais da teoria dos gráficos: o algoritmo de Dijkstra. Geralmente, ele é o algoritmo de referência para encontrar o caminho mais curto entre dois pontos em estruturas semelhantes a gráficos. Devido à sua simplicidade, ele tem aplicações em muitos setores, como:
Espero que a implementação do algoritmo de Dijkstra em Python tenha despertado em você o interesse pelo maravilhoso mundo dos algoritmos de gráfico. Se você quiser saber mais, recomendo fortemente os seguintes recursos:
Continue sua jornada com o Python hoje mesmo!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Amberle McKee
Tutorial
Arunn Thevapalan
