
Kurs
Effizientes KI-Modelltraining mit PyTorch
4 Std.
1.5K
Google hat kürzlich Gemma 3 270Mveröffentlicht , ein superkompaktes Modell mit 270 Millionen Parametern, das ein neues Paradigma für den effizienten Einsatz von KI darstellt. Im Gegensatz zu riesigen Allzweckmodellen ist Gemma 3 270M für die Feinabstimmung auf bestimmte Aufgaben ausgelegt, ohne dass man die Befehlsausführung anpassen muss.
In diesem Tutorial zeige ich dir, wie du mit Gemma 3 270M loslegen kannst, und warum es eine super Wahl für Entwickler ist, die Folgendes brauchen:
Wir halten unsere Leser über die neuesten Entwicklungen im Bereich KI auf dem Laufenden, indem wir ihnen jeden Freitag unseren kostenlosen Newsletter„The Median “ schicken , der die wichtigsten Meldungen der Woche zusammenfasst. Abonniere unseren Newsletter und bleib in nur wenigen Minuten pro Woche auf dem Laufenden:
Gemma 3 270M ist ein kompaktes Basismodell, das mit nur 270 Millionen Parametern eine starke Befehlsausführung und strukturierte Textgenerierung bietet. Es ist das kleinste Mitglied der Gemma 3-Familie, hat aber die gleiche Architektur und Trainingsrezepte wie die größeren Varianten wie Gemma 3 1B und 4B.
Im Gegensatz zu den großen Allzweckmodellen ist Gemma 3 270M auf Effizienz und Spezialisierung ausgelegt. Hier sind ein paar wichtige Hinweise zu diesem Modell:
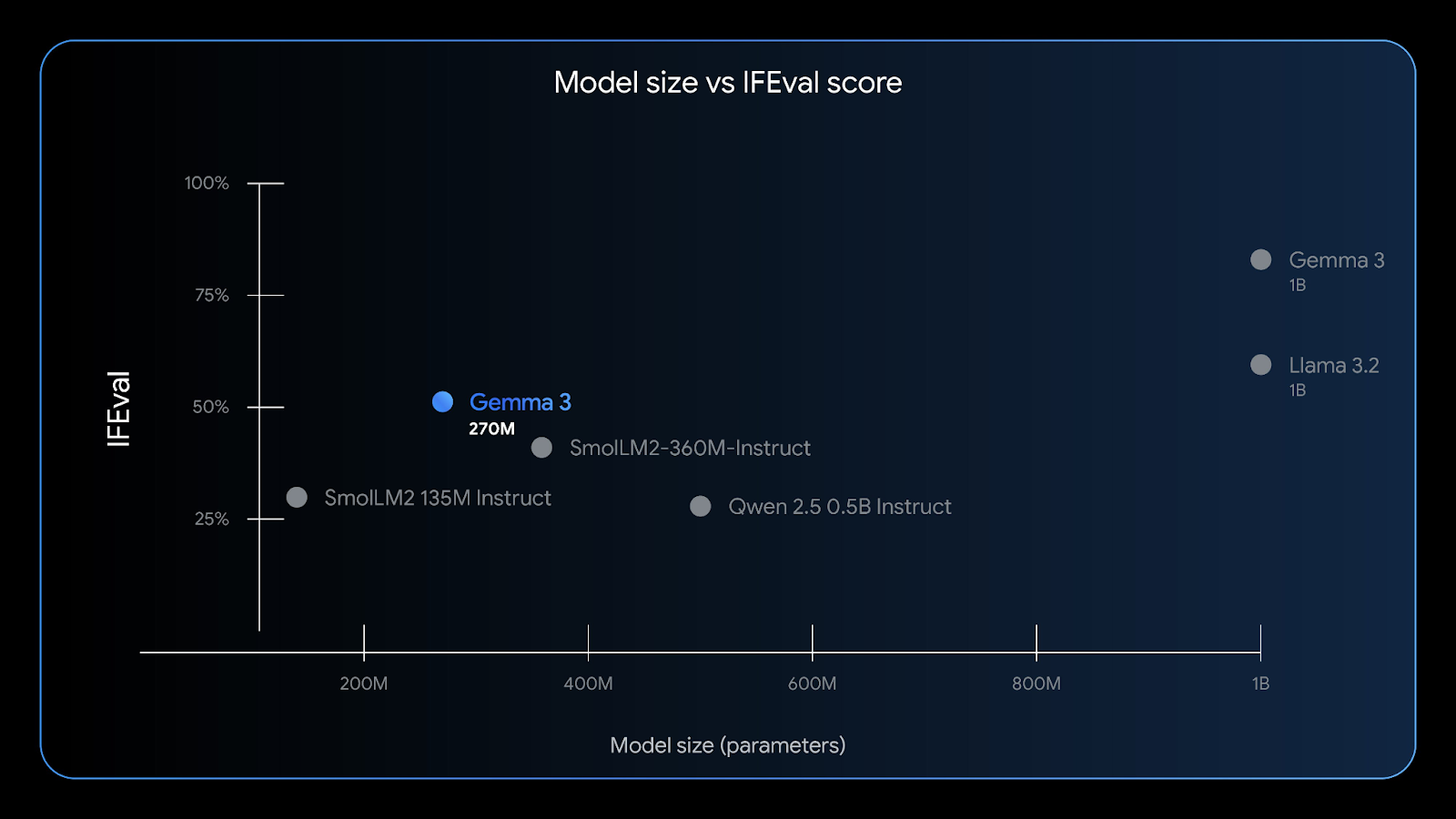
Gemma 3 270M kann gut Anweisungen befolgen – der IFEval-Benchmark testet, wie gut ein Modell verifizierbare Infos befolgen kann. Quelle: Google
Mit einem 32K-Kontextfenster, geringem Speicherverbrauch und robuster Genauigkeit bei Aufgaben wie Entitätsextraktion, Klassifizierung und einfachen Konformitätsprüfungen eignet sich Gemma 3 270M perfekt für Edge-KI , die Wert auf Datenschutz, Geschwindigkeit und Kosteneffizienz legen.
Es gibt mehrere einfache Möglichkeiten, mit Gemma 3 270M loszulegen, je nachdem, welche Plattform du bevorzugst:
Du kannst Gemma 3 auf Google Cloud Run bereitstellen. Google Cloud Run mit einem vorgefertigten GPU-beschleunigten Container für skalierbare Inferenz einsetzen. Für Gemma 3 270M musst du deinen Container aus dem Gemma-on-CloudRun GitHub-Repo, da nur größere Varianten (1B+) vorgefertigt sind. Mach einfach die Anweisungen im offiziellen Google Cloud Run-Handbuch mit. offiziellen Anleitung, um schnelle, sichere und kostengünstige Inferenz für Web- oder Backend-Anwendungen zu aktivieren.
Die beste Benutzererfahrung bekommst du direkt auf dem Gerät mit einer quantisierten Version von Gemma 3 270M (gemma3-270m-it-q8) und der offiziellen Gemma Gallery App von Google. Dieser Ansatz sorgt für extrem schnelle Offline-Inferenz, starken Datenschutz und minimalen Akkuverbrauch.
Du kannst Gemma 3 270M auch auf deinem Laptop mit Tools wie diesen ausführen:
.gguf “ oder „ .litertlm “ in deine LM Studio-Umgebung runter und starte es direkt über die Chat-Oberfläche oder host es lokal.ollama run gemma:270m “ verwenden, um dieses Modell lokal auf deinem Rechner auszuführen.Gemma 3 270M ist auch in Hugging Face Transformers, JAX oder Unsloth verfügbar, um auf deine domänenspezifischen Daten abstimmen auf deine spezifischen Daten anzupassen. Das Modell ist klein, also perfekt für schnelle, günstige Experimente, und dank QAT-Checkpoints kannst du INT4 direkt nach der Feinabstimmung einsetzen.
Als Nächstes zeige ich dir, wie du eine funktionierende Android-App baust, die das Modell Gemma 3 270M zum Verarbeiten von Textbefehlen nutzt. Wir nehmen das offizielle Google Gallery-Repository als Basis und passen es an.
Lass uns erst mal ein neues Projekt anlegen und das Original-Repository von Google klonen.
Öffne auf deinem Laptop das Projekt als neues Projekt in Android Studio und wähle eine leere Aktivität aus.
Als Nächstes gibst du den Namen deiner Aktivität ein (z. B. „Gemma 3 270M“) und lässt den Rest so, wie er ist. Klick dann auf „Fertig stellen“.
Öffne jetzt das Terminal in Android Studio (unten links) und gib die folgenden Bash-Befehle ein:
git clone https://github.com/google-ai-edge/gallery
cd gallery/android
Damit wird dein Projekt geöffnet. Du kannst alle Projektdateien auf der linken Seite der Registerkarte anzeigen.
Um das Modell Gemma 3 270M mit deiner Android-App zu verbinden, musst du es als neue Aufgabe in der Datei „ Tasks.kt “ der App registrieren.
Geh zum Ordner „ data/ “ und öffne die Datei „ Tasks.kt “. Dort legst du einen neuen Aufgabeneintrag speziell für die quantisierte Variante Q8 des Modells „ gemma3-270m-it-q8 “ an, die für wenig Speicherplatz und Inferenz auf dem Gerät optimiert ist. Dieses Format ist für Handys mit wenig Arbeitsspeicher gut geeignet.
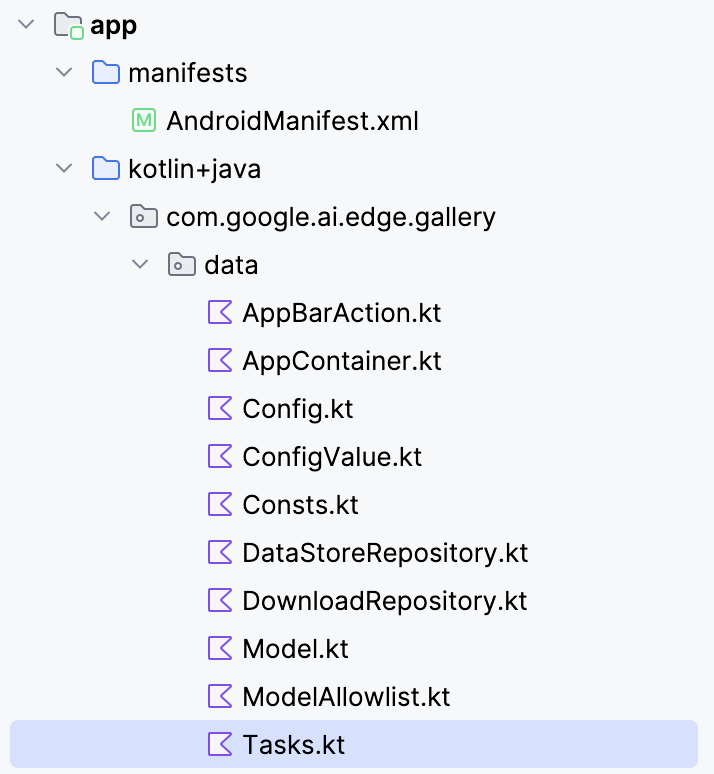
Hinweis: Für dieses Tutorial benutze ich eine Q8-Modellkonfiguration, die weniger Speicher braucht. Du kannst dieses Modell hier finden: https://huggingface.co/litert-community/gemma-3-270m-it
val TASK_GEMMA_3_270M = Task(
type = TaskType.LLM_PROMPT_LAB,
icon = Icons.Outlined.Widgets,
models = mutableListOf(
Model(
name = "gemma3-270m-it-q8",
downloadFileName = "gemma3-270m-it-q8.task",
url = "https://huggingface.co/litert-community/gemma-3-270m-it/resolve/main/gemma3-270m-it-q8.task",
sizeInBytes = 318_767_104L
)
),
description = "Gemma 3 270M (Q8): On-device instruction-following LLM",
docUrl = "https://ai.google.dev/gemma",
sourceCodeUrl = "https://github.com/google-ai-edge/gallery",
textInputPlaceHolderRes = R.string.chat_textinput_placeholder
)Dann speicher die neue Aufgabe in der App, indem du sie in die Hauptaufgabenliste packst:
/** All tasks */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE,
TASK_LLM_CHAT,
TASK_LLM_PROMPT_LAB,
TASK_IMAGE_CLASSIFICATION,
TASK_TEXT_CLASSIFICATION,
TASK_IMAGE_GENERATION,
TASK_GEMMA_3_270M
)Hier ist eine Übersicht darüber, was die neue LiteRT-Aufgabendefinition im Code macht:
TASK_GEMMA_3_270M “ speichert Gemma 3 270M als wählbare Option in der Datei „ Tasks.kt “ der App, sodass sie in der Aufgabenliste angezeigt wird..task “ mit „ “: Der obige Code verweist auf das Bundle „ gemma3-270m-it-q8.task “, das auf Hugging Face gehostet wird, innerhalb der App heruntergeladen und zur Laufzeit verwendet wird..task “ hat die quantisierten Modellgewichte, den Tokenizer, die Metadaten und die Konfigurationen, die LiteRT braucht, um das Modell effizient auszuführen.TASK_GEMMA_3_270M “ aufgeführt wird.Standardmäßig füllt die Galerie-App ihre Modelllisten aus einer Remote-JSON-Zulassungsliste. Wenn dein benutzerdefinierter Eintrag „Gemma 3 270M“ nicht dabei ist, wird er nicht in der Benutzeroberfläche angezeigt, auch wenn du „ TASK_GEMMA_3_270M “ im Code hinzugefügt hast. Mit diesem Schritt wird dein 270M-Modell in die LLM-Prompt-Lab-Aufgabe„ “ eingefügt, nachdem die Zulassungsliste geladen wurde, sodass es jedes Mal ausgewählt werden kann.
Öffne „ modelmanager/ModelManagerViewModel.kt “, such die Funktion „ loadModelAllowlist() “ und füge nach der Schleife, die die Modelle aus der Zulassungsliste konvertiert, Folgendes hinzu:
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}Hier ist der Grund, warum dieser Code nötig ist:
TASK_LLM_PROMPT_LAB.models “ aus der Allowlist des Servers und erstellt sie neu. Dein lokales Modell wird gelöscht, wenn du es nicht erneut einfügst.any { it.name == gemmaModel.name } verhindert, dass es zu Duplikaten kommt, wenn die Funktion loadModelAllowlist() wieder ausgeführt wird.Hier ist die komplette Funktion:
fun loadModelAllowlist() {
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = true, loadingModelAllowlistError = ""
)
}
viewModelScope.launch(Dispatchers.IO) {
try {
withTimeoutOrNull(30000L) { // 30 second timeout
// Load model allowlist json.
Log.d(TAG, "Loading model allowlist from internet...")
val data = getJsonResponse<ModelAllowlist>(url = MODEL_ALLOWLIST_URL)
var modelAllowlist: ModelAllowlist? = data?.jsonObj
if (modelAllowlist == null) {
Log.d(TAG, "Failed to load model allowlist from internet. Trying to load it from disk")
modelAllowlist = readModelAllowlistFromDisk()
} else {
Log.d(TAG, "Done: loading model allowlist from internet")
saveModelAllowlistToDisk(modelAllowlistContent = data?.textContent ?: "{}")
}
if (modelAllowlist == null) {
Log.e(TAG, "Failed to load model allowlist from both internet and disk")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list"
)
}
return@withTimeoutOrNull
}
Log.d(TAG, "Allowlist: $modelAllowlist")
// Convert models in the allowlist.
TASK_LLM_CHAT.models.clear()
TASK_LLM_PROMPT_LAB.models.clear()
TASK_LLM_ASK_IMAGE.models.clear()
try {
for (allowedModel in modelAllowlist.models) {
if (allowedModel.disabled == true) {
continue
}
val model = allowedModel.toModel()
if (allowedModel.taskTypes.contains(TASK_LLM_CHAT.type.id)) {
TASK_LLM_CHAT.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_PROMPT_LAB.type.id)) {
TASK_LLM_PROMPT_LAB.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_ASK_IMAGE.type.id)) {
TASK_LLM_ASK_IMAGE.models.add(model)
}
}
// Add models from TASK_GEMMA_3_270M to LLM_PROMPT_LAB
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error processing model allowlist", e)
}
// Pre-process all tasks.
try {
processTasks()
} catch (e: Exception) {
Log.e(TAG, "Error processing tasks", e)
}
// Update UI state.
val newUiState = createUiState()
_uiState.update {
newUiState.copy(
loadingModelAllowlist = false,
)
}
// Process pending downloads.
try {
processPendingDownloads()
} catch (e: Exception) {
Log.e(TAG, "Error processing pending downloads", e)
}
} ?: run {
// Timeout occurred
Log.e(TAG, "Model allowlist loading timed out")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Model list loading timed out"
)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error in loadModelAllowlist", e)
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list: ${e.message}"
)
}
}
}
}Standardmäßig geht die App davon aus, dass die aktuell ausgewählte Aufgabe zum angeklickten Modell passt. Sobald du Gemma 3 270M in die Prompt Lab-Aufgabe einfügst (Schritt 3), kann diese Annahme hinfällig werden. Dieser Schritt macht die Navigation modellorientiert, sodass Klicks, Deep Links und wiederhergestellte Zustände immer auf dem richtigen Bildschirm landen.
Öffnen navigation/GalleryNavGraph.kt und aktualisiere die Modellnavigationssteuerungslogik wie folgt:
Vorher:
onModelClicked = { model ->
navigateToTaskScreen(
navController = navController, taskType = curPickedTask.type, model = model
)
}Nachher:
onModelClicked = { model ->
Log.d("GalleryNavGraph", "Model clicked: ${model.name}, current task: ${curPickedTask.type}")
val actualTask = when {
TASK_LLM_CHAT.models.any { it.name == model.name } -> TASK_LLM_CHAT
TASK_LLM_PROMPT_LAB.models.any { it.name == model.name } -> TASK_LLM_PROMPT_LAB
TASK_LLM_ASK_IMAGE.models.any { it.name == model.name } -> TASK_LLM_ASK_IMAGE
TASK_TEXT_CLASSIFICATION.models.any { it.name == model.name } -> TASK_TEXT_CLASSIFICATION
TASK_IMAGE_CLASSIFICATION.models.any { it.name == model.name } -> TASK_IMAGE_CLASSIFICATION
TASK_IMAGE_GENERATION.models.any { it.name == model.name } -> TASK_IMAGE_GENERATION
else -> curPickedTask
}
Log.d("GalleryNavGraph", "Navigating to task: ${actualTask.type} for model: ${model.name}")
navigateToTaskScreen(
navController = navController, taskType = actualTask.type, model = model
)
}Wenn ein Modell in einer anderen Aufgabe als der aktuell ausgewählten auftaucht (oder dort eingefügt wurde), sorgt dieser Code dafür, dass der Bildschirm zu den Funktionen des Modells passt.
Bei Deep Links oder wiederhergestellten Zuständen kann die App versuchen, ein Modell zu öffnen, das nicht mehr verfügbar ist. Ohne die richtige Handhabung würde das zu einem leeren Bildschirm führen. Um das zu vermeiden, machen wir eine Sicherheitscheck: Wenn das Modell fehlt, schreiben wir eine Warnung und leiten den Nutzer weiter. So machen wir das:
// Added error handling for model not found:
if (model != null) {
Log.d("GalleryNavGraph", "Model found for LlmChat: ${model.name}")
modelManagerViewModel.selectModel(model)
LlmChatScreen(/* ... */)
} else {
Log.w("GalleryNavGraph", "Model not found for LlmChat, modelName: ${it.arguments?.getString("modelName")}")
// Handle case where model is not found
androidx.compose.runtime.LaunchedEffect(Unit) {
navController.navigateUp()
}
}Dieser Code sorgt dafür, dass die App immer funktioniert. Anstatt einzufrieren oder einen leeren Bildschirm anzuzeigen, navigiert es sicher zurück, indem es „ navController “ verwendet. So läuft alles reibungslos weiter, auch wenn mal ein Modell fehlt, und das Gesamterlebnis bleibt cool.
Ein großes Sprachmodell auf einem mobilen Gerät zu nutzen ist anders als auf einem Desktop-Computer. Speicher kann mal unzuverlässig sein, Speicherplatz ist knapp und Initialisierungsfehler müssen behoben werden, damit Apps nicht abstürzen. Um Gemma 3 270M (Q8, ~304 MB) auf Android stabil laufen zu lassen, habe ich ein paar zusätzliche Sicherheitschecks und Ausfallsicherungsstrategien eingebaut.
Bevor das Modell geladen wird, überprüft die App die Datei „ .task “ auf Fehler. Damit stellst du sicher, dass die Modelldatei da ist, gelesen werden kann und ungefähr die erwartete Größe hat (±10 %). Diese Toleranz berücksichtigt kleine Unterschiede durch Komprimierung oder Verpackung und fängt trotzdem beschädigte oder unvollständige Downloads ab.
// File validation and logging
Log.d(TAG, "Checking model file: $modelPath")
Log.d(TAG, "Model file exists: ${modelFile.exists()}")
Log.d(TAG, "Model file can read: ${modelFile.canRead()}")
Log.d(TAG, "Model file size: ${modelFile.length()} bytes")
Log.d(TAG, "Model file absolute path: ${modelFile.absolutePath}")
// Size validation with tolerance (10%)
val expectedSize = model.sizeInBytes
val fileSize = modelFile.length()
val sizeDifference = kotlin.math.abs(fileSize - expectedSize)
val sizeTolerance = (expectedSize * 0.1).toLong()
if (!modelFile.exists() || !modelFile.canRead() || sizeDifference > sizeTolerance) {
onDone("Model file invalid (missing/unreadable/wrong size).")
return
}Dieser Ausschnitt überprüft eine Modelldatei, bevor sie geladen wird. Es speichert grundlegende Infos wie Pfad, Lesbarkeit und Größe und checkt dann, ob die Datei da ist, gelesen werden kann und die erwartete Größe hat. Wenn eine dieser Prüfungen nicht klappt, wird die Funktion über die Methode „ onDone() “ abgebrochen, anstatt eine Schlussfolgerung zu versuchen und einen Absturz zu riskieren.
Große Modelle können Out-Of-Memory-Fehler (OOM) verursachen, wenn du sie aggressiv startest (lange Ausgaben, GPU-Zuweisungsspitzen). Um das zu vermeiden, hab ich eine Funktion eingebaut, die je nach Dateigröße und Gerätekonfiguration automatisch das sicherste Backend (CPU vs. GPU/NPU) auswählt und gleichzeitig die maximale Tokenanzahl für zu große Binärdateien reduziert.
val preferredBackend = when {
fileSize > 200_000_000L -> {
Log.d(TAG, "Model is large (${fileSize / 1024 / 1024}MB), using CPU backend for safety")
LlmInference.Backend.CPU
}
accelerator == Accelerator.CPU.label -> LlmInference.Backend.CPU
accelerator == Accelerator.GPU.label -> LlmInference.Backend.GPU
else -> LlmInference.Backend.CPU
}
val baseMaxTokens = 1024 // your default; tune to taste
val maxTokens = if (fileSize > 200_000_000L) {
kotlin.math.min(baseMaxTokens, 512)
} else {
baseMaxTokens
}Dadurch wird sichergestellt, dass große Modelle standardmäßig auf die CPU zurückgreifen (sicherer, aber langsamer). Der Code checkt die Byte-Größe der Datei „ .task “ (fileSize) und vergleicht sie mit einem Schwellenwert (maxTokens). Wenn es 200 MB überschreitet, wechselt es die Inferenz zur CPU und halbiert das Token-Budget. Das schützt vor Speicherauslastungen (durch gleichzeitige GPU-Zuweisung) und übergroßen Generierungsanforderungen.
Beim Starten von LiteRT ist es wichtig, zwischen der Erstellung der Laufzeitumgebung und der Sitzung zu unterscheiden. Wenn die Sitzung nicht erstellt werden kann, du aber die Laufzeitumgebung offen lässt, können Ressourcen verloren gehen und Speicher blockiert werden, was zu einer ganzen Reihe von Fehlern führen kann. Um das Problem zu beheben, habe ich den Code in try/catch-Blöcke mit expliziter Bereinigung eingeschlossen.
val llmInference = try {
LlmInference.createFromOptions(context, options)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInference instance", e)
onDone("Failed to create model instance: ${e.message}")
return
}
val session = try {
LlmInferenceSession.createFromOptions(/* ... */)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInferenceSession", e)
try {
llmInference.close()
} catch (closeException: Exception) {
Log.e(TAG, "Failed to close LlmInference after session creation failure", closeException)
}
onDone("Failed to create model session: ${e.message}")
return
}Dieser try/catch sorgt dafür, dass alles sauber zurückgesetzt wird, d. h., wenn die Laufzeitumgebung nicht erstellt werden kann, geht nichts weiter, aber wenn die Sitzung nicht erstellt werden kann, wird die Laufzeitumgebung explizit geschlossen. Es stellt sicher, dass das heap-allocated- llmInference -Objekt über „ .close() “ entsorgt wird, wodurch Speicher und Datei-Handles freigegeben werden. Ohne das riskierst du JNI-Referenzen, die beim nächsten Laden des Modells abstürzen.
Selbst wenn ein Modell erfolgreich geladen wird, kann die Inferenz aufgrund von Race Conditions, Nullreferenzen oder nicht initialisierten Instanzen fehlschlagen. Um diesen Schritt zu sichern, habe ich Null-Prüfungen und Ausnahmebehandlungen rund um den gesamten Inferenzblock eingefügt.
try {
Log.d(TAG, "Starting inference for model '${model.name}' with input: '${input.take(50)}...'")
val instance = model.instance as LlmModelInstance? ?: run {
Log.e(TAG, "Model instance is null for '${model.name}'")
resultListener("Error: Model not initialized", true)
return
}
} catch (e: Exception) {
Log.e(TAG, "Error during inference for model '${model.name}'", e)
resultListener("Error during inference: ${e.message}", true)
}Der obige Code sorgt dafür, dass die Inferenz nur mit einer gültigen Modellinstanz weiterläuft und Laufzeitfehler sauber abgefangen werden. Der Cast „ as LlmModelInstance? ” checkt, ob die Modellinstanz richtig typisiert ist, und der Elvis-ähnliche Fallback bricht die Ausführung ab, wenn sie null ist. Wenn du den Block in try/catch einpackst, werden alle Ausnahmen abgefangen und als Fehlermeldungen angezeigt, die der Benutzer sehen kann.
Sobald du alle notwendigen Änderungen vorgenommen hast, starten wir die App. Um deine App auf deinem Android-Gerät zu starten, verbinde dein Android-Gerät über WLAN mit Android Studio. Hier sind die Schritte:
Öffne die Einstellungen auf deinem Android-Gerät und aktiviere die Entwickleroptionen. Dann schalte„ “ ein. Wähle„Wireless debugging“ und dann „ “. Du solltest einen Bildschirm mit zwei Pairing-Optionen sehen.
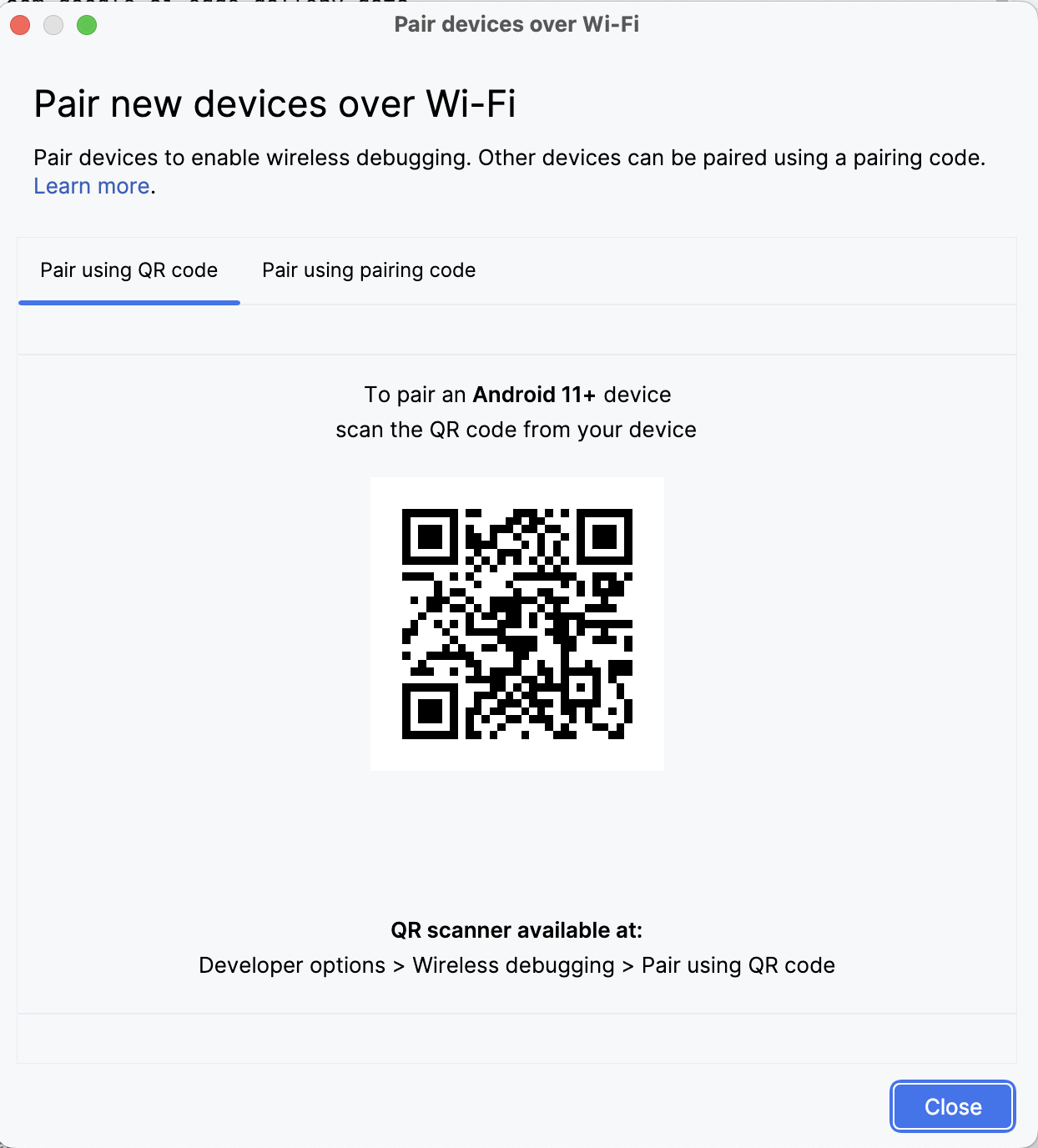
Öffne in Android Studio den Geräte-Manager (das Symbol sieht aus wie ein Telefon mit einem Android-Logo) und klick auf Über QR-Code verbinden.
Scanne den QR-Code mit deinem Gerät und schließe die Kopplung ab. Sobald dein Gerät verbunden ist, siehst du den Namen deines Geräts unter „Geräte-Manager“. Stell sicher, dass dein System und dein Android-Gerät mit demselben WLAN-Netzwerk verbunden sind.
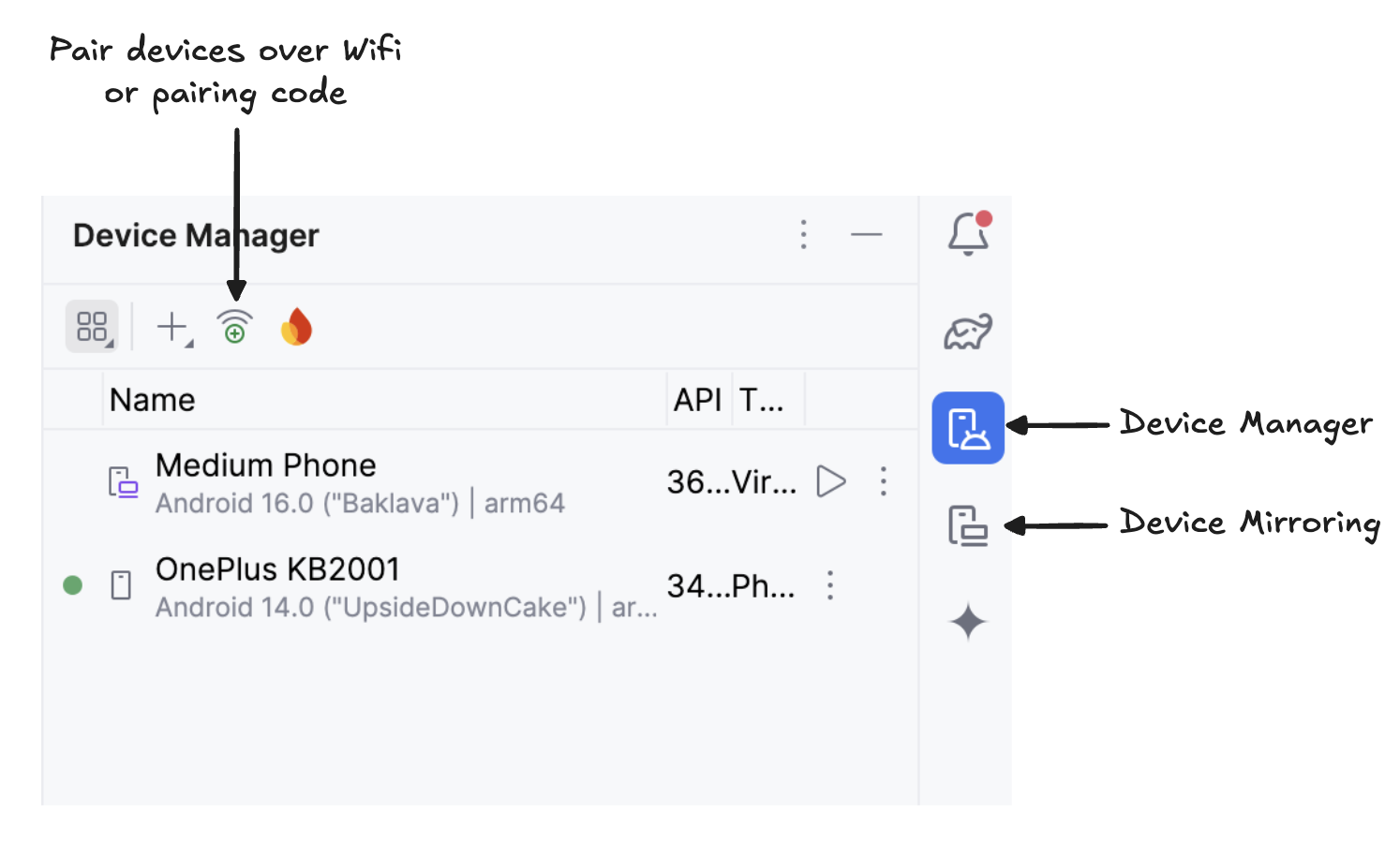
Starte die Spiegelung deines Android-Geräts, indem du auf das Symbol„Gerätespiegelung“( ) klickst (das einen Desktop-Bildschirm und einen Telefonbildschirm zeigt). Sobald du den Bildschirm deines Geräts gespiegelt siehst, klick auf das grüne Symbol„ “ ausführen, um die App auf deinem Gerät zu installieren.
Die App startet und ein Browserfenster öffnet sich, in dem du aufgefordert wirst, dich mit einem „ write ”-Token bei Hugging Face anzumelden, um die Modelldatei sicher herunterzuladen.
Wenn du bei HuggingFace eingeloggt bist, klick beim gewünschten Modell auf„Start download“ und „ “, und schon geht der Download los. Für dieses Beispiel benutze ich das Standardmodell „ gemma3-270m-it-q8 ”. Jetzt kannst du mit diesem Modell loslegen.
Für dieses Tutorial habe ich vier Experimente gemacht:
In diesem Versuch habe ich das Modell dazu gebracht, eine freie Geschichte zu schreiben, und hier sind die Ergebnisse:
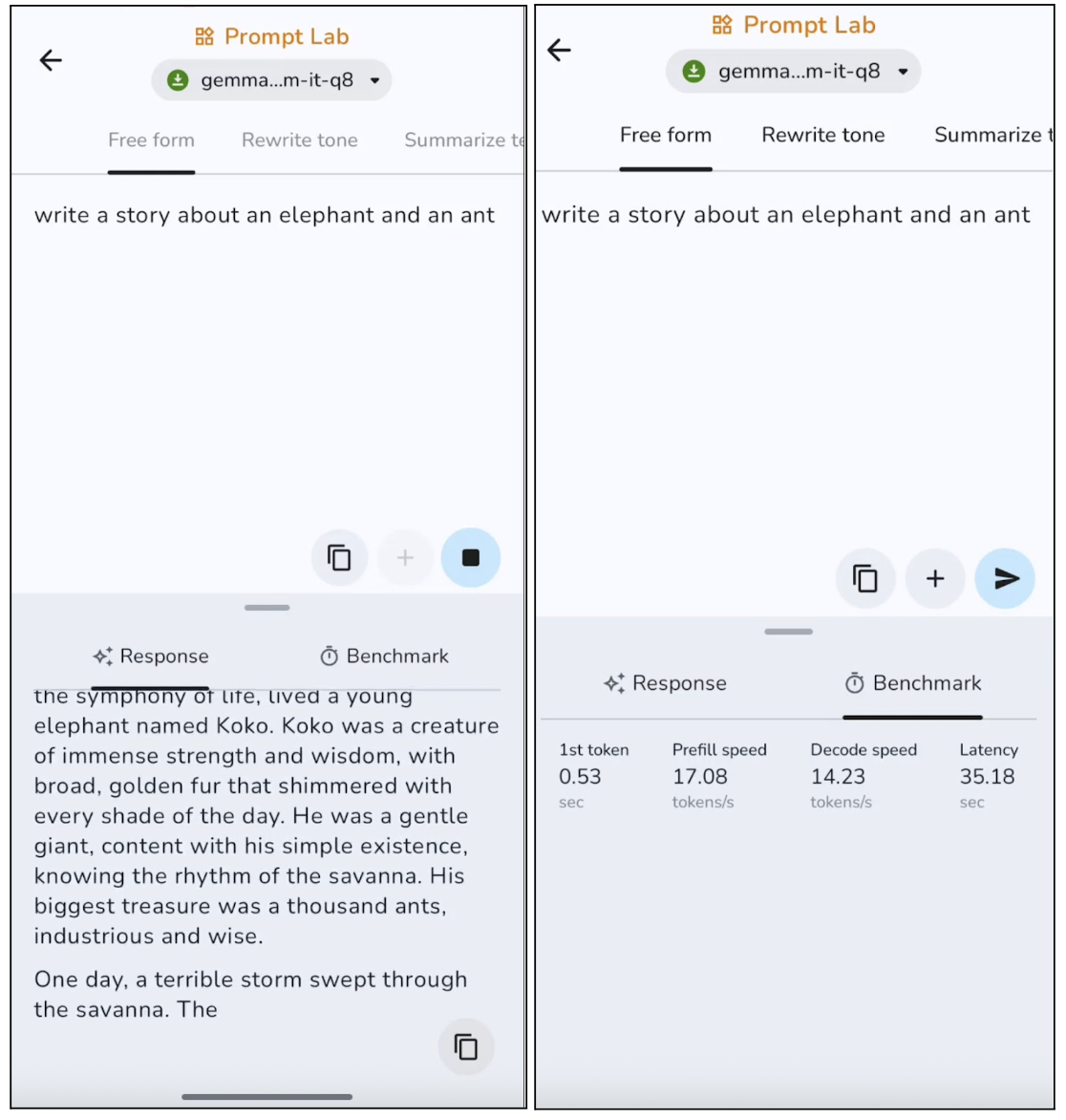
Das Modell erstellt themenbezogene Texte mit einer klaren Struktur, geht dabei aber eher auf Nummer sicher und klingt etwas generisch. Bei längeren Texten wiederholt das Modell normalerweise bestimmte Sätze. Das macht es super für kurze Posts, Beschreibungen und Übersichten. Die Generierung des ersten Tokens geht aber mit etwa 0,53 Sekunden ziemlich schnell und die Dekodierungsgeschwindigkeit ist auch für die Inferenz auf dem Gerät gut.
Als Nächstes habe ich einen vorformulierten Absatz genommen und Gemma 3 270M gebeten, den Absatz in einem freundlichen Ton umzuschreiben.

Die Befolgung von Anweisungen ist gut, mit klaren Übergängen zwischen formellem, ungezwungenem und freundlichem Ton, ohne dass dabei die Bedeutung verloren geht. Bei kurzen Texten geht das echt schnell, also ist es super, um E-Mails auf Vordermann zu bringen oder Texte in andere Formate zu bringen.
Ich hab den Text, der schon da war, auch in Stichpunkten zusammengefasst. Du kannst mit Zusammenfassungen, Stichpunkten, Schlussfolgerungen und vielem mehr experimentieren.
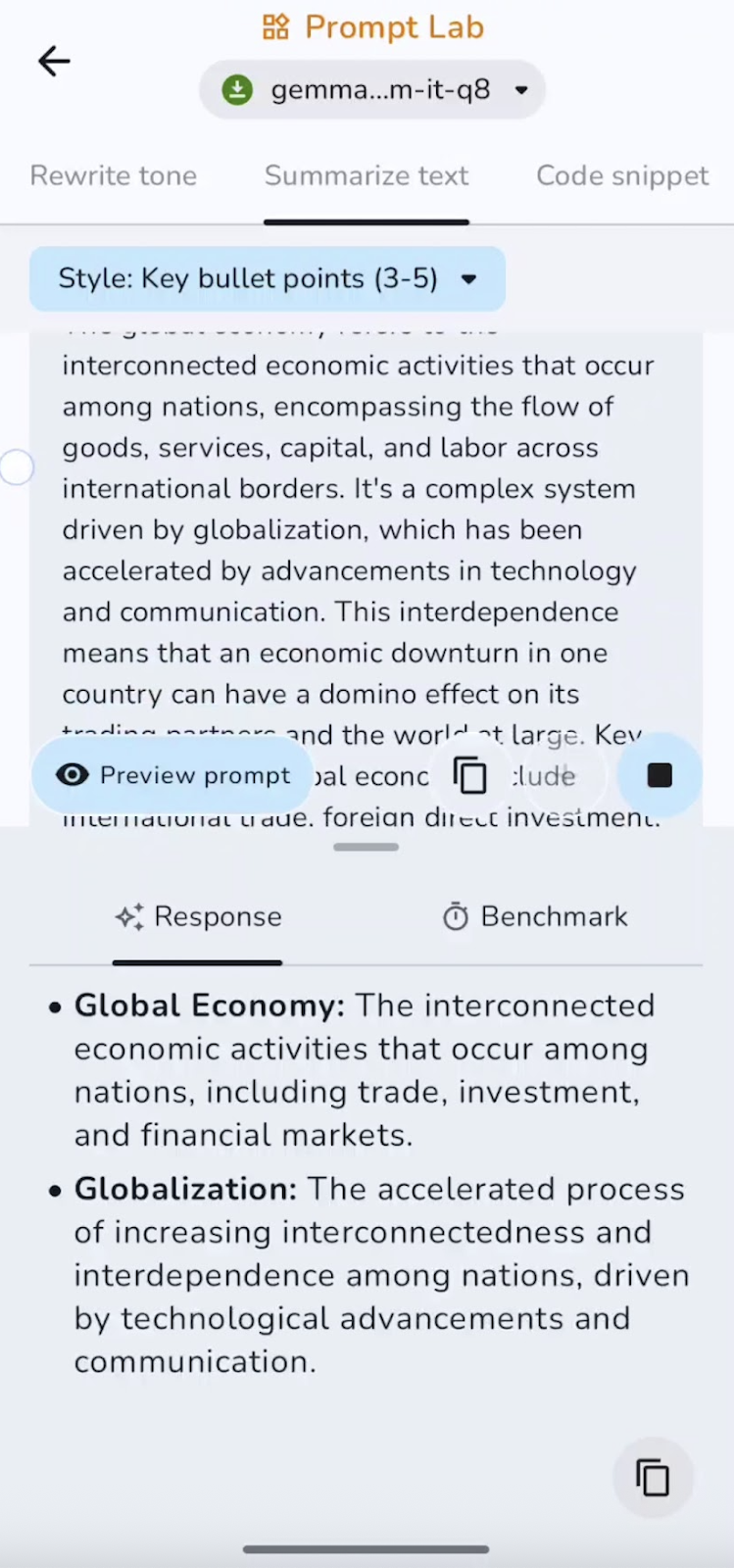
In diesem Experiment fasst das Modell die wichtigsten Punkte zusammen und hält sie fest. Die Geschwindigkeit ist super für kurze und mittellange Dokumente. Einige der Anwendungsfälle können Zusammenfassungen, Stichpunkte oder TL;DRs sein.
Zum Schluss hab ich das Model gebeten, einen kleinen Code-Schnipsel zu schreiben. Hier ist, was ich gefunden habe:
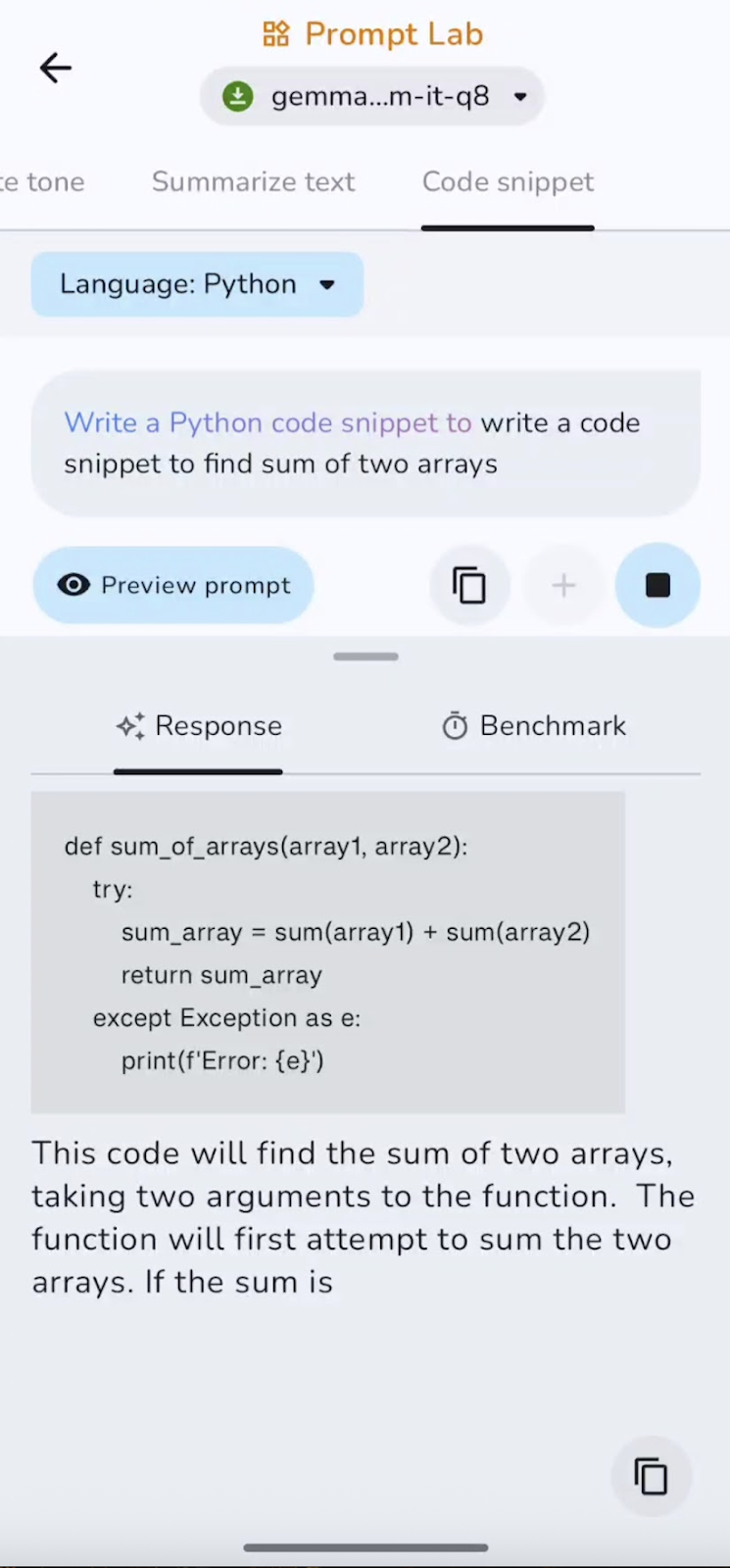
Das Modell ist super, um Standardcode und kleine Hilfsprogramme zu erstellen, kann aber ohne Anleitung Importe, Sonderfälle oder komplexe Logik übersehen. Kurze Ausschnitte werden schnell generiert, während längere Vervollständigungen etwas langsamer werden, wenn der Kontext wächst. Das funktioniert am besten für Hilfsfunktionen und Konfigurationen.
Ich hab dieses GitHub-Repository eingerichtet, falls du den kompletten Projektcode anschauen möchtest.
In diesem Handbuch haben wir dir Schritt für Schritt gezeigt, wie du das Modell Gemma 3 270M einrichtest, angefangen vom Download und der Verkabelung des Modells in einer benutzerdefinierten Android-App bis hin zur Navigation, Zuverlässigkeit und Sicherheit während der Inferenz.
Gemma 3 bietet schnelle Schlussfolgerungen mit geringem Rechenaufwand, verbraucht wenig Strom, unterstützt INT4-Quantisierung mit minimalen Auswirkungen auf die Leistung und läuft komplett auf dem Gerät, um die Privatsphäre zu schützen.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
