
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Google DeepMind hat gerade Gemma 3 veröffentlicht, die nächste Iteration seiner Open-Source-Modelle. Gemma 3 ist so konzipiert, dass es direkt auf ressourcenarmen Geräten wie Handys und Laptops läuft. Diese Modelle sind für eine schnelle Leistung auf einer einzelnen GPU oder TPU optimiert und es gibt sie in verschiedenen Größen, um unterschiedlichen Hardwareanforderungen gerecht zu werden.
In diesem Tutorial erkläre ich dir Schritt für Schritt, wie du Gemma 3 lokal mit Ollama einrichtest und ausführst. Danach zeige ich dir, wie du mit Gemma 3 und Python einen Dateiassistenten erstellen kannst.
Ein großes Sprachmodell (LLM) wie Gemma 3 lokal zu betreiben, hat mehrere Vorteile:
Ollama ist eine Plattform für Windows, Mac und Linux, die das Ausführen und Verteilen von KI-Modellen unterstützt und es Entwicklern erleichtert, diese Modelle in ihre Projekte zu integrieren. Wir werden es benutzen, um Gemma 3 herunterzuladen und lokal zu starten.
Der erste Schritt ist der Download und die Installation von der der offiziellen Ollama-Website.
Achte bei der Installation darauf, dass du die Kommandozeile installierst:
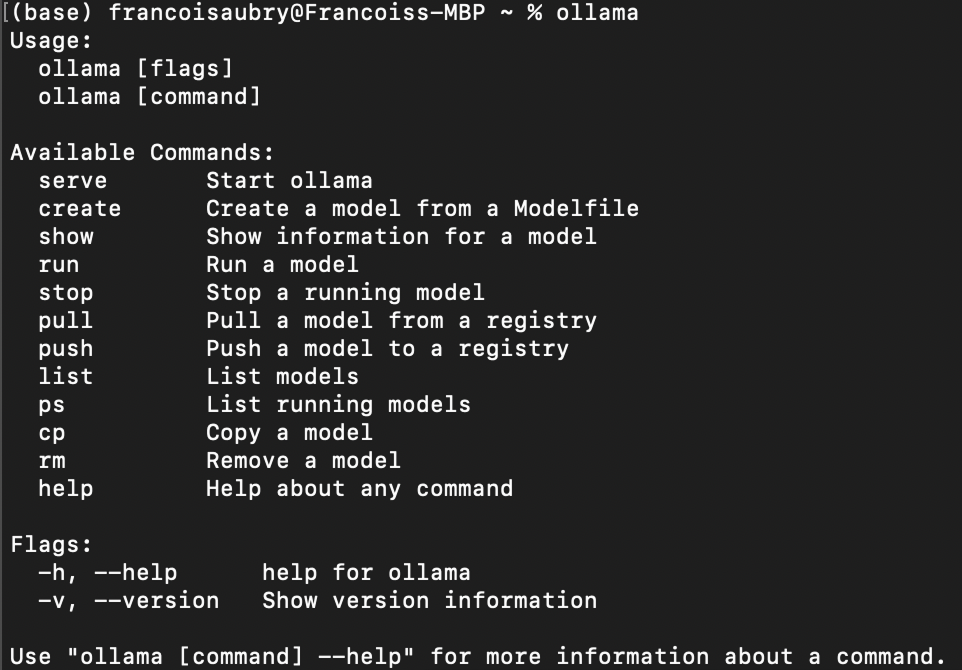
Nachdem die Installation abgeschlossen ist, können wir mit dem Befehl ollama im Terminal überprüfen, ob sie korrekt installiert wurde. So sollte das Ergebnis aussehen:
Um ein Modell mit Ollama herunterzuladen, verwende den Befehl pull:
ollama pull <model_name>:<model_version>Die Liste der verfügbaren Modelle findest du in der Ollama's Bibliothek.
Gemma 3hat vier Modelle zur Verfügung: 1b 4b , 12b und 27b, wobei b für eine Milliarde steht, die sich auf die Anzahl der Parameter des Modells bezieht.
Um zum Beispiel gemma3 mit den Parametern 1b herunterzuladen, verwenden wir den Befehl:
ollama pull gemma3:1bWenn wir die Modellversion nicht angeben, wird standardmäßig das Modell 4b heruntergeladen:
ollama pull gemma3Wir können die Modelle, die wir lokal haben, mit dem folgenden Befehl auflisten:
ollama listIn meinem Fall zeigt die Ausgabe, dass ich zwei Modelle habe:
NAME ID SIZE MODIFIED
gemma3:1b 2d27a774bc62 815 MB 38 seconds ago
gemma3:latest c0494fe00251 3.3 GB 22 minutes ago Wir können Ollama benutzen, um mit einem Modell zu chatten, indem wir den Befehl run verwenden:
ollama run gemma3
Wenn wir den Befehl run mit einem Modell verwenden, das wir nicht heruntergeladen haben, wird es automatisch mit pull heruntergeladen.
Um Gemma 3 mit Python zu verwenden, müssen wir es im Hintergrund laufen lassen. Das können wir mit dem Befehl serve tun:
ollama serveWenn du beim Ausführen des Befehls die folgende Fehlermeldung erhältst, bedeutet das wahrscheinlich, dass Ollama bereits läuft:
Error: listen tcp 127.0.0.1:11434: bind: address already in useDieser Fehler kann auftreten, wenn Ollama im Hintergrund weiterläuft.
Ollama bietet ein Python-Paket an, mit dem du dich ganz einfach mit den Modellen auf unserem Computer verbinden kannst.
Wir verwenden Anaconda um eine Python-Umgebung einzurichten und die notwendigen Abhängigkeiten hinzuzufügen. Auf diese Weise lassen sich mögliche Probleme mit anderen Python-Paketen vermeiden, die wir bereits haben.
Sobald Anaconda installiert ist, können wir die Umgebung mit dem Befehl einrichten:
conda create -n gemma3-demo -y python=3.9Dieser Befehl richtet eine Umgebung namens gemma3-demo mit der Python-Version 3.9 ein. Die Option -y sorgt dafür, dass alle Fragen während der Einrichtung automatisch mit Ja beantwortet werden.
Als Nächstes aktivieren wir die Umgebung mit:
conda activate gemma3-demoSchließlich installieren wir das Paket ollama mit dem Befehl:
pip install ollamaSo können wir mit Python eine Nachricht an Gemma 3 senden:
from ollama import chat
response = chat(
model="gemma3",
messages=[
{
"role": "user",
"content": "Why is the sky blue?",
},
],
)
print(response.message.content)Je nach deiner Hardware kann es eine Weile dauern, bis das Modell antwortet, also habe Geduld, wenn du das Skript ausführst.
Wir haben bereits gesehen, dass gemma3 standardmäßig auf die gemma3:4b verweist. Wenn wir also model="gemma3" als Modell angeben, wird dieses Modell verwendet.
Um ein anderes Modell - zum Beispiel das Modell 1B - zu verwenden, müssen wir stattdessen das Argument model=”gemma3:1b” übergeben (vorausgesetzt, wir haben es vorher mit dem Befehl ollama pull gemma3:1b gezogen). Um die verfügbaren Modelle aufzulisten, können wir den Befehl ollama list verwenden.
Wenn wir die Antwort Wort für Wort streamen wollen, können wir stattdessen stream=True verwenden und die Antwort Chunk für Chunk ausgeben:
from ollama import chat
stream = chat(
model="gemma3",
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)Das sorgt für ein besseres Nutzererlebnis, weil der Nutzer nicht darauf warten muss, dass die vollständige Antwort generiert wird.
Um mehr über das Paket ollama zu erfahren, schau dir die ihre Dokumentation.
In diesem Abschnitt lernst du, wie du ein Python-Skript erstellst, mit dem du Fragen zum Inhalt einer Textdatei direkt im Terminal stellen kannst. Dieses Skript ist praktisch für Aufgaben wie die Suche nach Fehlern in einer Codedatei oder die Abfrage von Informationen aus einem beliebigen Dokument.
Unser Ziel ist es, mit Python ein Kommandozeilentool zu erstellen, das eine Textdatei liest und mit Gemma 3 Fragen zu ihrem Inhalt beantwortet. Hier ist die Schritt-für-Schritt-Anleitung, um dies zu erreichen:
Zuerst müssen wir das Python-Skript mit den notwendigen Importen und der Grundstruktur einrichten:
import sys
from ollama import chat
def ask_questions_from_file(file_path):
# Read the content of the text file
with open(file_path, "r") as file:
content = file.read()
# Loop to keep asking questions
while True:
question = input("> ")
print()
if question.lower() == "exit":
break
# Use Gemma 3 to get answers
stream = chat(
model="gemma3",
messages=[
{"role": "user", "content": content},
{"role": "user", "content": question},
],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python ask_file.py <path_to_text_file>")
else:
file_path = sys.argv[1]
ask_questions_from_file(file_path)Die Kernfunktionalität ist in der Funktion ask_questions_from_file() gekapselt. Diese Funktion nimmt einen Dateipfad als Argument und beginnt mit dem Öffnen und Lesen des Inhalts der angegebenen Textdatei. Diese Inhalte werden als Hintergrundinformationen verwendet, um Fragen zu beantworten.
Sobald der Inhalt der Datei geladen ist, tritt das Skript in eine Schleife ein, in der es uns kontinuierlich auffordert, Fragen einzugeben. Wenn wir eine Frage eingeben, sendet das Skript den Inhalt der Datei zusammen mit unserer Frage an das Gemma 3-Modell, das diese Informationen verarbeitet, um eine Antwort zu generieren.
Die Interaktion mit dem Modell erfolgt über einen Streaming-Mechanismus, so dass die Antworten in Echtzeit angezeigt werden können, während sie generiert werden. Wenn wir exit eingeben, wird die Schleife unterbrochen und das Skript läuft nicht weiter.
Am Ende des Skripts wird geprüft, ob das Skript mit einem Kommandozeilenargument, das der Pfad zu der Textdatei sein sollte, korrekt ausgeführt wird. Wenn das Argument nicht angegeben wird, zeigt es eine Benutzungsmeldung an, um uns den richtigen Weg zur Ausführung des Skripts zu zeigen. Auf diese Weise können wir das Skript effektiv von der Kommandozeile aus steuern.
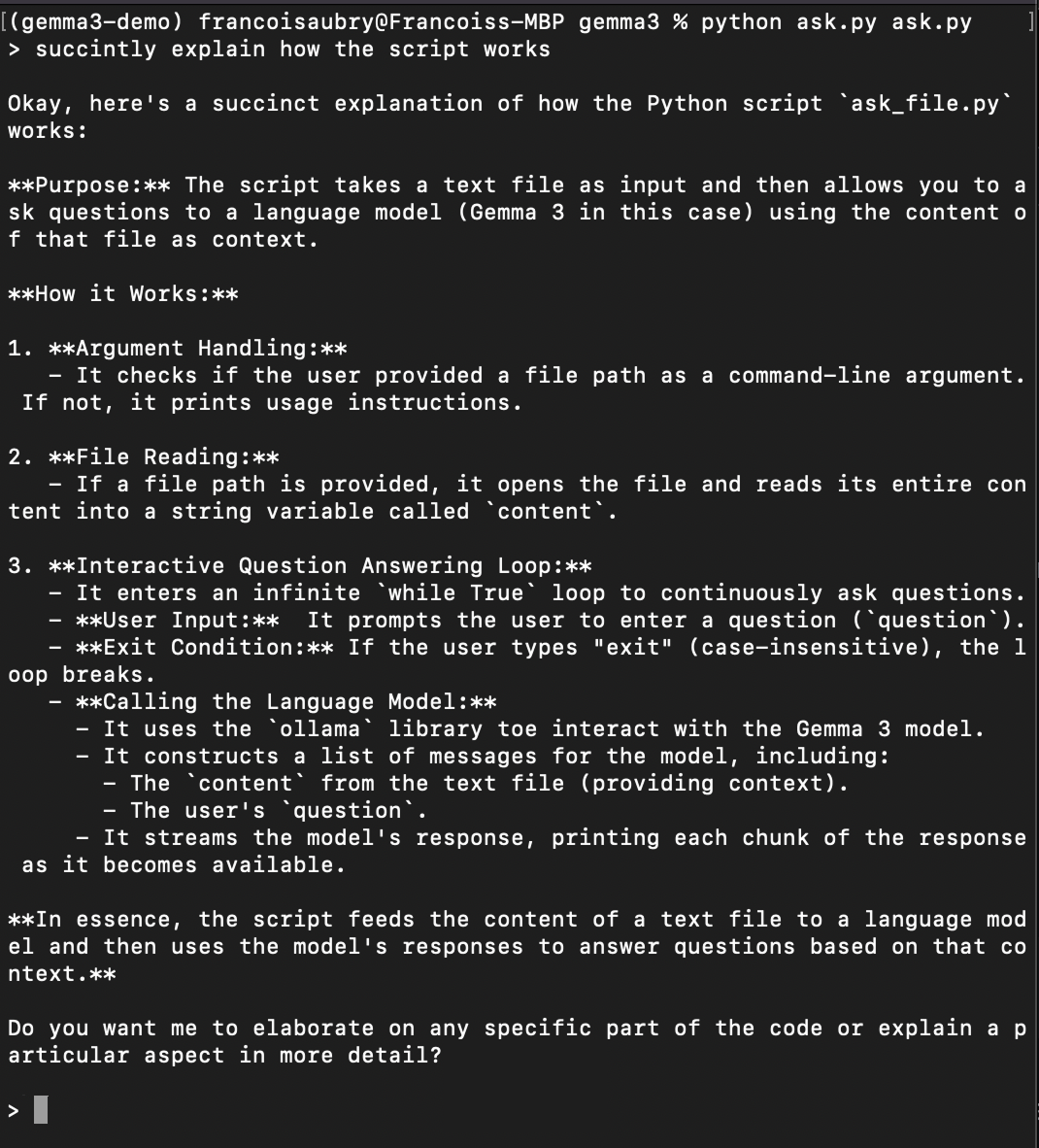
Speichere den obigen Code in einer Datei mit dem Namen, zum Beispiel: ask.py. Um das Skript zu testen, führe den Befehl aus:
python ask.py ask.pyDadurch wird das Skript ausgeführt, um Fragen über sich selbst zu stellen (deshalb erscheint ask.py zweimal im obigen Befehl). Hier ist ein Beispiel, in dem du ihn bittest zu erklären, wie das Skript funktioniert:
Wir haben Gemma 3 erfolgreich eingerichtet und gelernt, wie man es mit Ollama und Python lokal betreibt. Dieser Ansatz gewährleistet den Schutz unserer Daten, bietet eine geringe Latenzzeit, bietet Anpassungsmöglichkeiten und kann zu Kosteneinsparungen führen. Die Schritte, die wir beschrieben haben, sind nicht nur auf Gemma 3 beschränkt - sie können auch auf andere Modelle auf Ollama angewendet werden.
Wenn wir die Funktionalität unseres Skripts verbessern wollen, können wir es z.B. um die Verarbeitung von PDFs erweitern. Der beste Weg, das zu tun, wäre die Verwendung der Mistral OCR API. Wir können PDF-Dateien in Text umwandeln, damit unser Skript Fragen zu PDFs beantworten kann, was es noch vielseitiger und leistungsfähiger macht.
Mit diesen Tools sind wir jetzt in der Lage, große Modelle direkt von unseren eigenen Geräten aus zu erkunden und mit ihnen zu interagieren.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
