
Curso
Treinamento Eficiente de Modelos de IA com PyTorch
4 h
1.5K
O Google lançou recentemente o Gemma 3 270M, um modelo ultracompacto com 270 milhões de parâmetros que representa um novo paradigma na implantação eficiente de IA. Diferente dos modelos genéricos enormes, o Gemma 3 270M foi feito pra ajustar tarefas específicas, mantendo a capacidade de seguir instruções logo de cara.
Neste tutorial, vou mostrar como começar a usar o Gemma 3 270M e explicar por que ele é uma ótima escolha para desenvolvedores que precisam de:
A gente mantém nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito às sextas-feiras, que traz as principais notícias da semana. Inscreva-se e fique por dentro em só alguns minutos por semana:
O Gemma 3 270M é um modelo básico compacto, feito pra seguir instruções direitas e gerar textos bem estruturados, tudo isso com só 270 milhões de parâmetros. É o menor membro da família Gemma 3, mas tem a mesma arquitetura e receitas de treinamento das versões maiores, como a Gemma 3 1B e 4B.
Diferente dos modelos grandes de uso geral, o Gemma 3 270M é focado em eficiência e especialização. Aqui estão algumas dicas importantes sobre esse modelo:
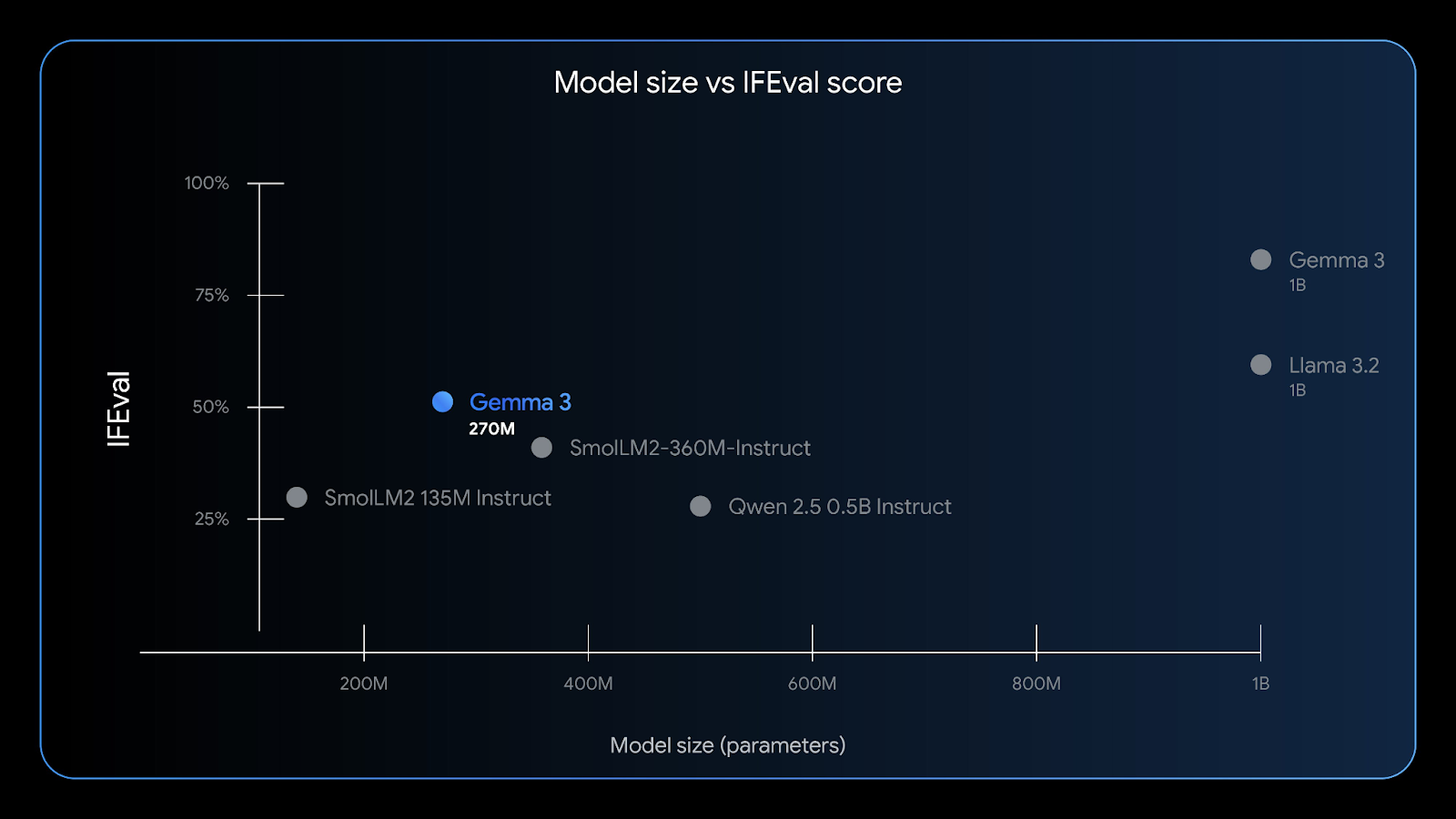
O Gemma 3 270M tem uma boa capacidade de seguir instruções — o benchmark IFEval testa a capacidade de um modelo de seguir informações verificáveis. Fonte: Google
Com uma janela de contexto de 32K, baixo uso de memória e precisão robusta em tarefas como extração de entidades, classificação e verificações de conformidade leves, o Gemma 3 270M é perfeito para desenvolvedores de IA de ponta que buscam privacidade, velocidade e eficiência de custos.
Tem várias maneiras fáceis de começar a usar o Gemma 3 270M, dependendo da sua plataforma preferida:
Você pode usar o Gemma 3 no Google Cloud Run usando um contêiner pré-construído acelerado por GPU para inferência escalável. Para o Gemma 3 270M, você precisa criar seu contêiner a partir do repositório GitHub do Gemma-on-CloudRun, já que só as versões maiores (1B+) já vêm prontas. Siga as instruções no guia oficial do Google Cloud Run guia oficial para habilitar inferências rápidas, seguras e econômicas para aplicativos da web ou de back-end.
A melhor experiência de usuário é no próprio dispositivo, usando uma versão quantizada do Gemma 3 270M (gemma3-270m-it-q8) e o aplicativo oficial aplicativo Gemma Gallery do Google. Essa abordagem oferece inferência offline super rápida, privacidade forte e uso mínimo da bateria.
Você também pode rodar o Gemma 3 270M no seu laptop usando ferramentas como:
.gguf ou .litertlm no seu ambiente LM Studio e execute-o imediatamente na interface de chat ou hospede-o localmente.ollama run gemma:270m ” para rodar esse modelo localmente na sua máquina.O Gemma 3 270M também está disponível no Hugging Face Transformers, JAX ou Unsloth para ajustar em seus dados específicos do domínio. O tamanho pequeno do modelo é ideal para experimentos rápidos e baratos, e os pontos de verificação QAT permitem a implantação direta do INT4 após o ajuste fino.
Depois, vou te mostrar como criar um aplicativo Android que funciona e usa o modelo Gemma 3 270M pra processar comandos de texto. Vamos usar o repositório oficial da Galeria do Google como base e personalizá-lo.
Vamos começar criando um novo projeto e copiando o repositório original do Google.
No seu laptop, comece abrindo o projeto como um novo projeto no Android Studio e selecione uma Atividade vazia.
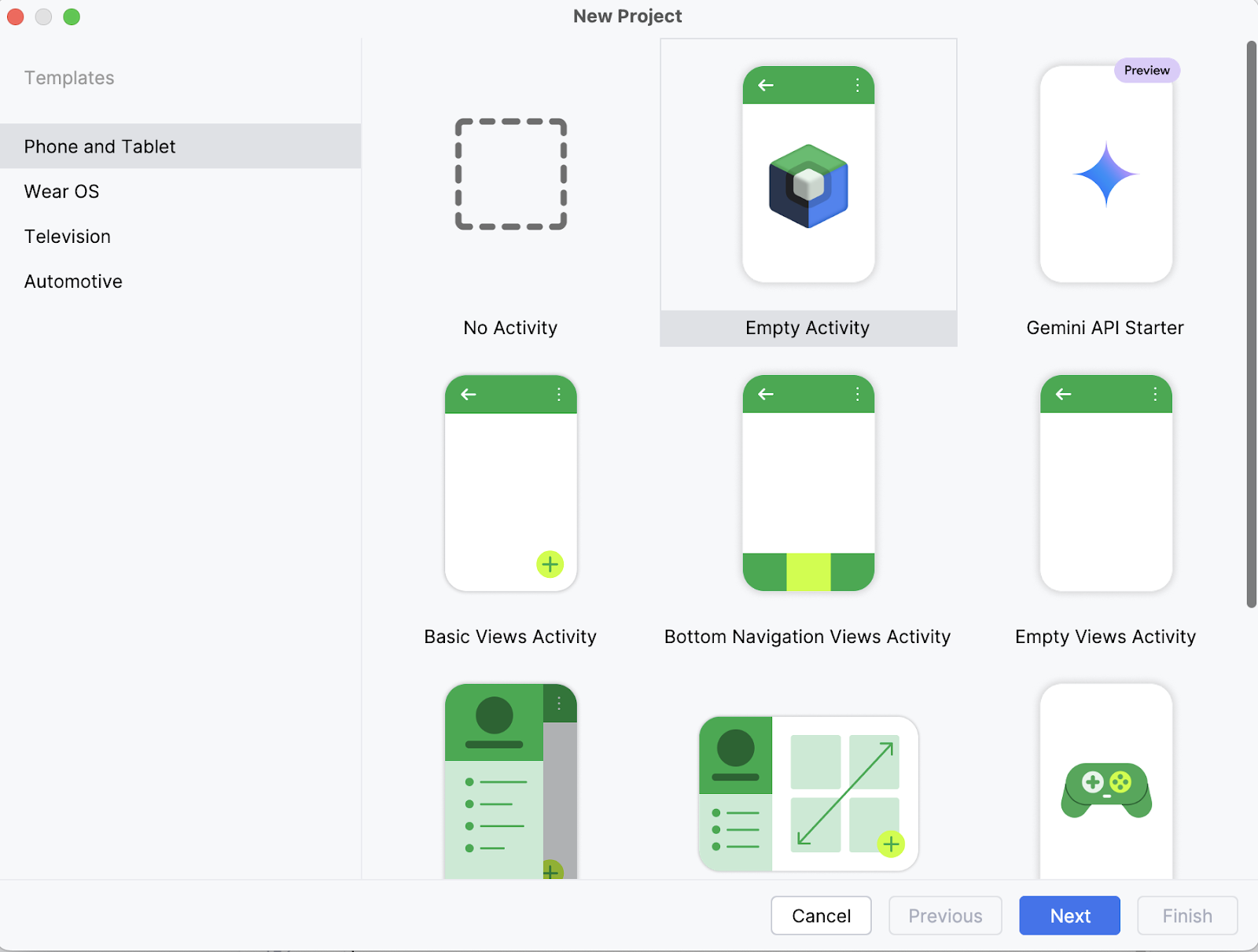
Depois, coloca o nome da tua atividade (por exemplo, “Gemma 3 270M”) e deixa o resto como está. Depois, clica em Concluir.
Agora, abre o terminal dentro do Android Studio (canto inferior esquerdo) e executa os seguintes comandos bash:
git clone https://github.com/google-ai-edge/gallery
cd gallery/android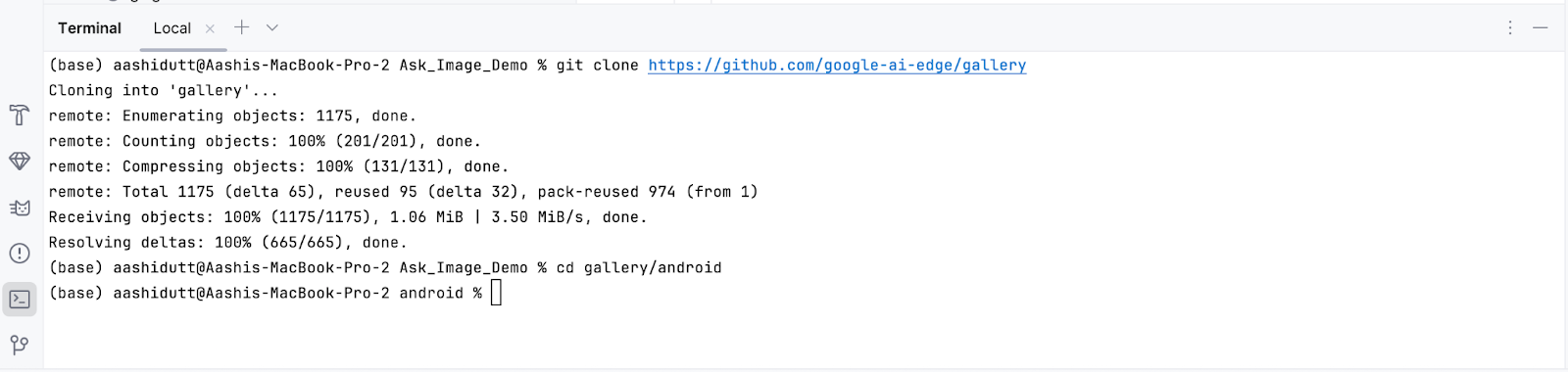
Isso vai abrir o seu projeto. Você pode ver todos os arquivos do projeto no lado esquerdo da aba.
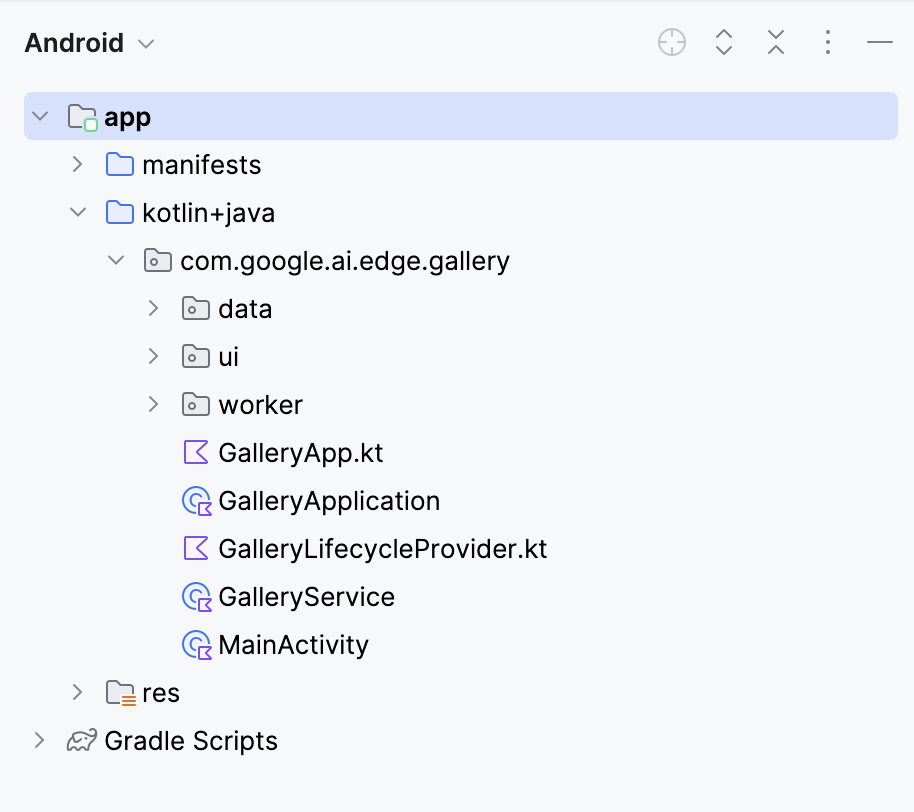
Para conectar o modelo Gemma 3 270M ao seu aplicativo Android, você precisa registrá-lo como uma nova tarefa dentro do arquivo Tasks.kt do aplicativo.
Vá até a pasta “ data/ ” e abra o arquivo “ Tasks.kt ”. Lá, você vai definir uma nova entrada de tarefa só para a variante quantizada Q8 do modelo gemma3-270m-it-q8, que é otimizada para pouca memória e inferência no dispositivo. Esse formato é ideal para dispositivos móveis com pouca memória RAM.
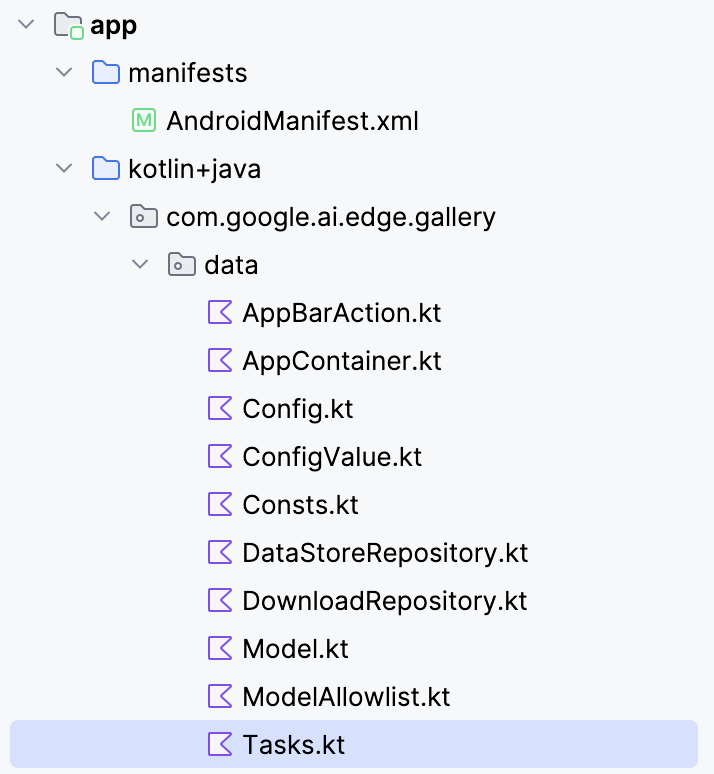
Observação: Pra esse tutorial, vou usar uma configuração do modelo Q8, que precisa de menos memória. Você pode acessar esse modelo aqui: https://huggingface.co/litert-community/gemma-3-270m-it
val TASK_GEMMA_3_270M = Task(
type = TaskType.LLM_PROMPT_LAB,
icon = Icons.Outlined.Widgets,
models = mutableListOf(
Model(
name = "gemma3-270m-it-q8",
downloadFileName = "gemma3-270m-it-q8.task",
url = "https://huggingface.co/litert-community/gemma-3-270m-it/resolve/main/gemma3-270m-it-q8.task",
sizeInBytes = 318_767_104L
)
),
description = "Gemma 3 270M (Q8): On-device instruction-following LLM",
docUrl = "https://ai.google.dev/gemma",
sourceCodeUrl = "https://github.com/google-ai-edge/gallery",
textInputPlaceHolderRes = R.string.chat_textinput_placeholder
)Depois, cadastra essa nova tarefa no aplicativo, colocando-a na lista principal de tarefas:
/** All tasks */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE,
TASK_LLM_CHAT,
TASK_LLM_PROMPT_LAB,
TASK_IMAGE_CLASSIFICATION,
TASK_TEXT_CLASSIFICATION,
TASK_IMAGE_GENERATION,
TASK_GEMMA_3_270M
)Aqui tá um resumo do que a nova definição de tarefa do LiteRT faz no código:
TASK_GEMMA_3_270M registra o Gemma 3 270M como uma opção selecionável dentro do arquivo Tasks.kt do aplicativo, para que ele apareça na lista de tarefas..task : O código acima aponta para o pacote gemma3-270m-it-q8.task hospedado no Hugging Face, que é baixado dentro do aplicativo e usado em tempo de execução..task tem os pesos do modelo quantizados, o tokenizador, os metadados e as configurações que o LiteRT precisa pra rodar o modelo direitinho.TASK_GEMMA_3_270M.Por padrão, o app Galeria preenche suas listas de modelos a partir de uma lista de permissões JSON remota. Se a sua entrada personalizada Gemma 3 270M não estiver lá, ela não vai aparecer na interface do usuário, mesmo que você tenha adicionado TASK_GEMMA_3_270M no código. Essa etapa insere seu modelo 270M na tarefaLLM Prompt Lab do depois que a lista de permissões é carregada, garantindo que ele possa ser selecionado sempre.
Abra modelmanager/ModelManagerViewModel.kt, encontre a função “ loadModelAllowlist() ” e (depois do loop que converte os modelos da lista de permissões) acrescente:
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}Eis porque esse código é necessário:
TASK_LLM_PROMPT_LAB.models ” da lista de permissões do servidor ao iniciar. Seu modelo local vai ser apagado, a menos que você o injete de novo.any { it.name == gemmaModel.name } ” evita que a função “ loadModelAllowlist() ” seja executada de novo.Aqui está a função completa:
fun loadModelAllowlist() {
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = true, loadingModelAllowlistError = ""
)
}
viewModelScope.launch(Dispatchers.IO) {
try {
withTimeoutOrNull(30000L) { // 30 second timeout
// Load model allowlist json.
Log.d(TAG, "Loading model allowlist from internet...")
val data = getJsonResponse<ModelAllowlist>(url = MODEL_ALLOWLIST_URL)
var modelAllowlist: ModelAllowlist? = data?.jsonObj
if (modelAllowlist == null) {
Log.d(TAG, "Failed to load model allowlist from internet. Trying to load it from disk")
modelAllowlist = readModelAllowlistFromDisk()
} else {
Log.d(TAG, "Done: loading model allowlist from internet")
saveModelAllowlistToDisk(modelAllowlistContent = data?.textContent ?: "{}")
}
if (modelAllowlist == null) {
Log.e(TAG, "Failed to load model allowlist from both internet and disk")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list"
)
}
return@withTimeoutOrNull
}
Log.d(TAG, "Allowlist: $modelAllowlist")
// Convert models in the allowlist.
TASK_LLM_CHAT.models.clear()
TASK_LLM_PROMPT_LAB.models.clear()
TASK_LLM_ASK_IMAGE.models.clear()
try {
for (allowedModel in modelAllowlist.models) {
if (allowedModel.disabled == true) {
continue
}
val model = allowedModel.toModel()
if (allowedModel.taskTypes.contains(TASK_LLM_CHAT.type.id)) {
TASK_LLM_CHAT.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_PROMPT_LAB.type.id)) {
TASK_LLM_PROMPT_LAB.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_ASK_IMAGE.type.id)) {
TASK_LLM_ASK_IMAGE.models.add(model)
}
}
// Add models from TASK_GEMMA_3_270M to LLM_PROMPT_LAB
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error processing model allowlist", e)
}
// Pre-process all tasks.
try {
processTasks()
} catch (e: Exception) {
Log.e(TAG, "Error processing tasks", e)
}
// Update UI state.
val newUiState = createUiState()
_uiState.update {
newUiState.copy(
loadingModelAllowlist = false,
)
}
// Process pending downloads.
try {
processPendingDownloads()
} catch (e: Exception) {
Log.e(TAG, "Error processing pending downloads", e)
}
} ?: run {
// Timeout occurred
Log.e(TAG, "Model allowlist loading timed out")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Model list loading timed out"
)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error in loadModelAllowlist", e)
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list: ${e.message}"
)
}
}
}
}Por padrão, o aplicativo assume que a tarefa selecionada no momento corresponde ao modelo clicado. Depois de colocar o Gemma 3 270M na tarefa do Prompt Lab (Passo 3), essa suposição pode não ser mais válida. Essa etapa faz com que a navegação reconheça o modelo, de modo que toques, links profundos e estados restaurados sempre levem à tela certa.
Abrir navigation/GalleryNavGraph.kt e atualize a lógica de controle de navegação do modelo da seguinte maneira:
Antes:
onModelClicked = { model ->
navigateToTaskScreen(
navController = navController, taskType = curPickedTask.type, model = model
)
}Depois:
onModelClicked = { model ->
Log.d("GalleryNavGraph", "Model clicked: ${model.name}, current task: ${curPickedTask.type}")
val actualTask = when {
TASK_LLM_CHAT.models.any { it.name == model.name } -> TASK_LLM_CHAT
TASK_LLM_PROMPT_LAB.models.any { it.name == model.name } -> TASK_LLM_PROMPT_LAB
TASK_LLM_ASK_IMAGE.models.any { it.name == model.name } -> TASK_LLM_ASK_IMAGE
TASK_TEXT_CLASSIFICATION.models.any { it.name == model.name } -> TASK_TEXT_CLASSIFICATION
TASK_IMAGE_CLASSIFICATION.models.any { it.name == model.name } -> TASK_IMAGE_CLASSIFICATION
TASK_IMAGE_GENERATION.models.any { it.name == model.name } -> TASK_IMAGE_GENERATION
else -> curPickedTask
}
Log.d("GalleryNavGraph", "Navigating to task: ${actualTask.type} for model: ${model.name}")
navigateToTaskScreen(
navController = navController, taskType = actualTask.type, model = model
)
}Se um modelo aparecer (ou for colocado) em uma tarefa diferente da que está selecionada no momento, esse código garante que a tela vai combinar com o que o modelo pode fazer.
Quando você estiver lidando com links profundos ou estado restaurado, o aplicativo pode tentar abrir um modelo que não está mais disponível. Sem o manuseio correto, isso deixaria a tela em branco. Para evitar isso, adicionamos uma verificação de segurança que, se o modelo estiver faltando, registra um aviso e redireciona o usuário. É assim que a gente faz:
// Added error handling for model not found:
if (model != null) {
Log.d("GalleryNavGraph", "Model found for LlmChat: ${model.name}")
modelManagerViewModel.selectModel(model)
LlmChatScreen(/* ... */)
} else {
Log.w("GalleryNavGraph", "Model not found for LlmChat, modelName: ${it.arguments?.getString("modelName")}")
// Handle case where model is not found
androidx.compose.runtime.LaunchedEffect(Unit) {
navController.navigateUp()
}
}Esse código garante que o aplicativo continue funcionando. Em vez de travar ou mostrar uma tela em branco, ele volta com segurança usando navController. Assim, mesmo que um modelo esteja faltando, o fluxo do usuário continua tranquilo, sem atrapalhar a experiência geral.
Executar um modelo de linguagem grande em um dispositivo móvel é diferente de executá-lo em um computador desktop. O armazenamento pode ser meio instável, o espaço de memória é mais limitado e as falhas de inicialização precisam ser resolvidas pra evitar que os apps caiam. Pra deixar o Gemma 3 270M (Q8, ~304 MB) mais estável no Android, eu adicionei mais verificações de segurança e estratégias de failover.
Antes de carregar o modelo, o aplicativo faz uma verificação de integridade no arquivo “ .task ”. Isso garante que o arquivo do modelo existe, pode ser lido e está próximo do tamanho esperado (dentro de ±10%). Essa tolerância leva em conta pequenas diferenças por causa da compressão ou da embalagem, mas ainda assim detecta downloads corrompidos ou parciais.
// File validation and logging
Log.d(TAG, "Checking model file: $modelPath")
Log.d(TAG, "Model file exists: ${modelFile.exists()}")
Log.d(TAG, "Model file can read: ${modelFile.canRead()}")
Log.d(TAG, "Model file size: ${modelFile.length()} bytes")
Log.d(TAG, "Model file absolute path: ${modelFile.absolutePath}")
// Size validation with tolerance (10%)
val expectedSize = model.sizeInBytes
val fileSize = modelFile.length()
val sizeDifference = kotlin.math.abs(fileSize - expectedSize)
val sizeTolerance = (expectedSize * 0.1).toLong()
if (!modelFile.exists() || !modelFile.canRead() || sizeDifference > sizeTolerance) {
onDone("Model file invalid (missing/unreadable/wrong size).")
return
}Esse trecho valida um arquivo de modelo antes de carregá-lo. Ele registra detalhes básicos como caminho, legibilidade e tamanho, depois verifica se o arquivo existe, se é legível e se tem o tamanho esperado. Se alguma dessas verificações falhar, a função para logo através do método onDone(), em vez de tentar a inferência e arriscar uma falha.
Modelos grandes podem dar erros de memória insuficiente (OOM) se você começar de forma agressiva (saídas longas, picos de alocação de GPU). Pra resolver isso, eu adicionei uma lógica pra escolher dinamicamente o backend mais seguro (CPU vs GPU/NPU) com base no tamanho do arquivo e na configuração do dispositivo, enquanto também reduzia o número máximo de tokens pra binários muito grandes.
val preferredBackend = when {
fileSize > 200_000_000L -> {
Log.d(TAG, "Model is large (${fileSize / 1024 / 1024}MB), using CPU backend for safety")
LlmInference.Backend.CPU
}
accelerator == Accelerator.CPU.label -> LlmInference.Backend.CPU
accelerator == Accelerator.GPU.label -> LlmInference.Backend.GPU
else -> LlmInference.Backend.CPU
}
val baseMaxTokens = 1024 // your default; tune to taste
val maxTokens = if (fileSize > 200_000_000L) {
kotlin.math.min(baseMaxTokens, 512)
} else {
baseMaxTokens
}Isso garante que modelos grandes usem a CPU por padrão (mais seguro, mas mais lento). O código verifica o tamanho em bytes do arquivo .task (fileSize) e compara com um limite (maxTokens). Se passar de 200 MB, a inferência muda para a CPU e o orçamento de tokens cai pela metade. Isso evita picos de memória (por causa da alocação simultânea da GPU) e pedidos de geração muito grandes.
Ao inicializar o LiteRT, é importante saber a diferença entre criação de tempo de execução e criação de sessão. Se a criação da sessão falhar, mas você deixar o tempo de execução aberto, você pode perder recursos e bloquear a memória, causando falhas em cascata. Pra resolver isso, eu coloquei o código dentro de blocos try/catch com limpeza explícita.
val llmInference = try {
LlmInference.createFromOptions(context, options)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInference instance", e)
onDone("Failed to create model instance: ${e.message}")
return
}
val session = try {
LlmInferenceSession.createFromOptions(/* ... */)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInferenceSession", e)
try {
llmInference.close()
} catch (closeException: Exception) {
Log.e(TAG, "Failed to close LlmInference after session creation failure", closeException)
}
onDone("Failed to create model session: ${e.message}")
return
}Esse try/catch garante um rollback limpo, ou seja, se a criação em tempo de execução falhar, nada mais vai rolar, mas se a criação da sessão falhar, o tempo de execução é explicitamente fechado. Isso garante que o objeto llmInference alocado na pilha seja descartado por meio de .close(), liberando memória e identificadores de arquivo. Sem isso, você corre o risco de ter referências JNI que travam na próxima carga do modelo.
Mesmo que um modelo carregue com sucesso, a inferência pode falhar por causa de condições de corrida, referências nulas ou instâncias não inicializadas. Pra deixar essa etapa mais segura, eu adicionei verificações nulas e exceções de captura em todo o bloco de inferência.
try {
Log.d(TAG, "Starting inference for model '${model.name}' with input: '${input.take(50)}...'")
val instance = model.instance as LlmModelInstance? ?: run {
Log.e(TAG, "Model instance is null for '${model.name}'")
resultListener("Error: Model not initialized", true)
return
}
} catch (e: Exception) {
Log.e(TAG, "Error during inference for model '${model.name}'", e)
resultListener("Error during inference: ${e.message}", true)
}O código acima garante que a inferência só rola com uma instância válida do modelo e pega erros de tempo de execução direitinho. O cast de ` as LlmModelInstance? ` verifica se a instância do modelo está digitada corretamente e o fallback tipo Elvis interrompe a execução se for nulo. Envolver o bloco em try/catch garante que todas as exceções sejam capturadas e redirecionadas como mensagens de erro visíveis ao usuário.
Depois de fazer todas as mudanças necessárias, vamos rodar o aplicativo. Para rodar seu app no seu dispositivo Android local, emparelhe seu dispositivo Android com o Android Studio usando a depuração sem fio com as etapas a seguir.
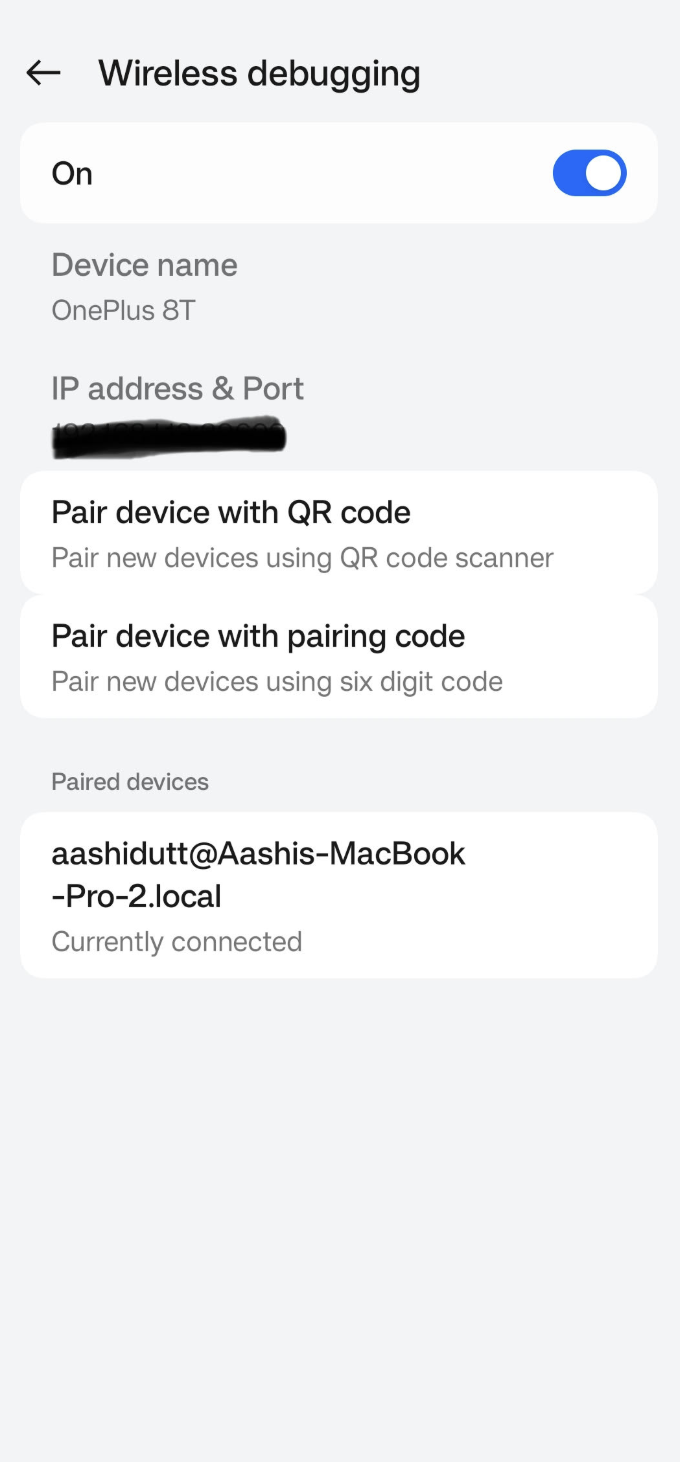
Acesse o aplicativo Configurações no seu dispositivo Android e habilite as opções de desenvolvedor. Depois, ligaa depuração sem fio n . Você deve ver uma tela com duas opções de emparelhamento.
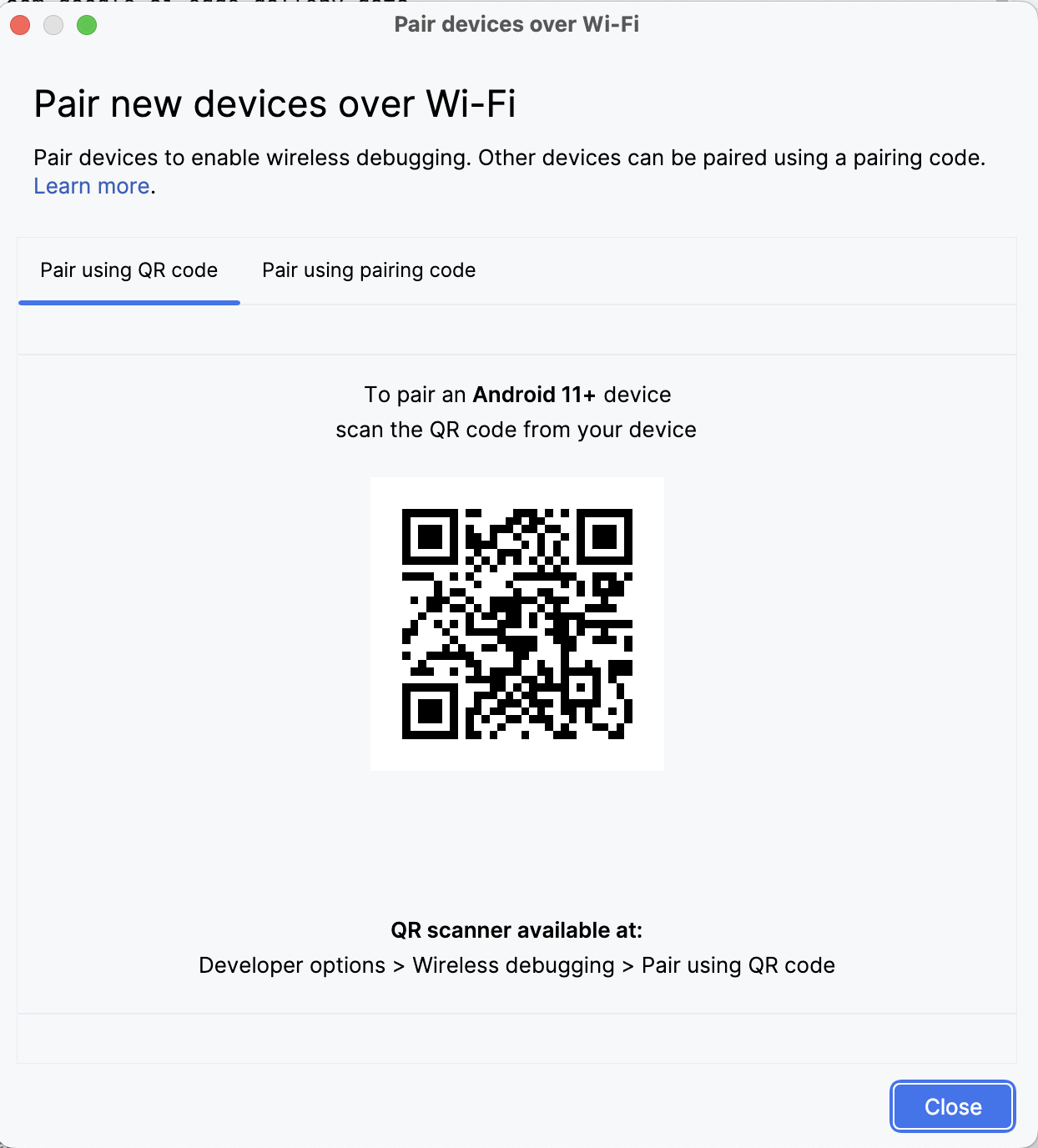
No Android Studio, abra o Gerenciador de dispositivos (o ícone parece um telefone com o logotipo do Android) e clique em Emparelhar usando código QR.
Dá uma olhada no código QR com o seu aparelho e faz o emparelhamento. Depois que o dispositivo estiver conectado, você vai ver o nome dele em Gerenciador de dispositivos. Tá ligado que o seu sistema e o seu aparelho Android precisam estar conectados na mesma rede Wi-Fi?
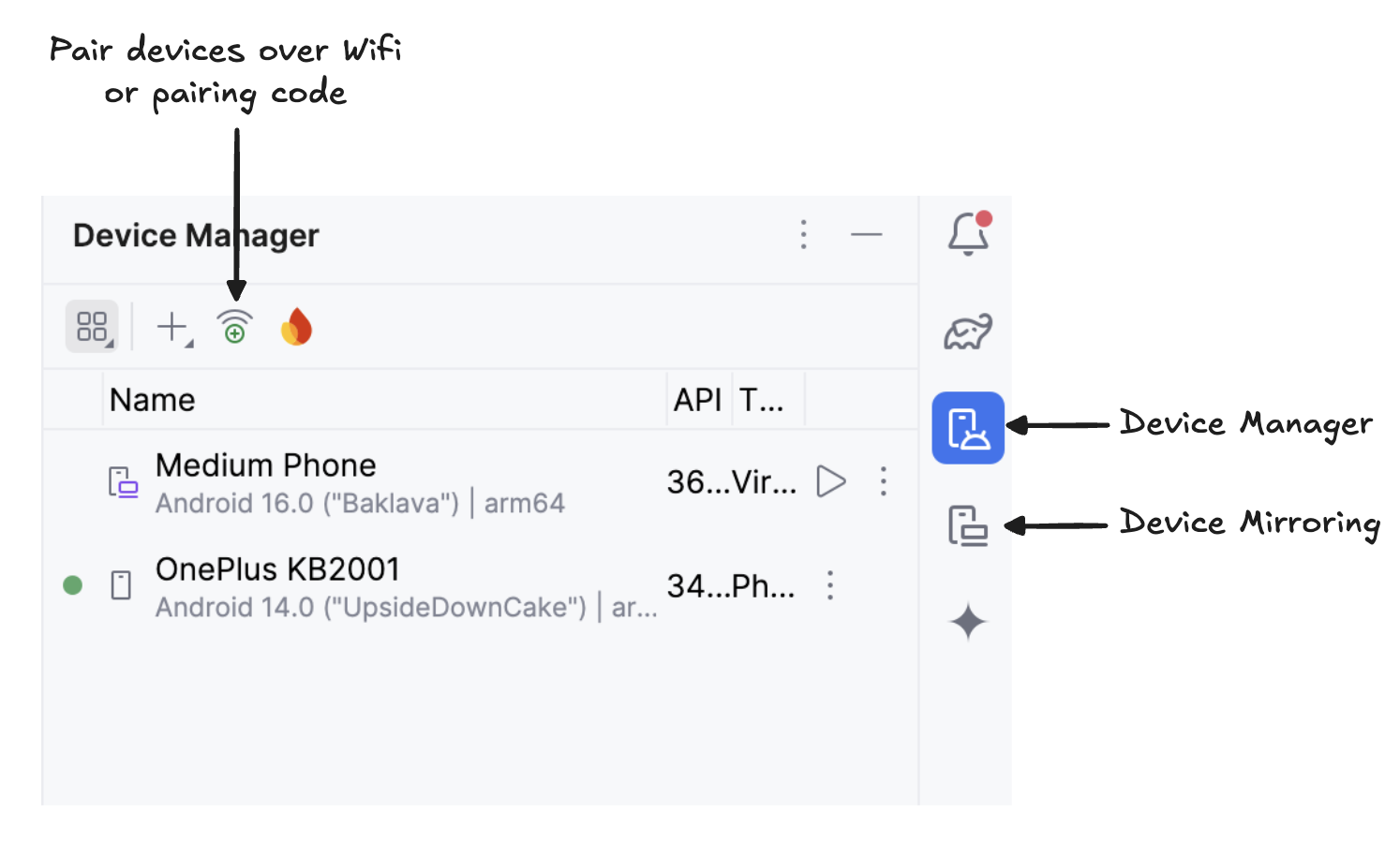
Comece a espelhar seu dispositivo Android clicando no íconeEspelhamento de dispositivo ( ) (que mostra uma tela de desktop e uma tela de telefone). Quando você vir a tela do seu dispositivo espelhada, clique no ícone verde“ ” para instalar o aplicativo no seu dispositivo.
O aplicativo vai abrir e uma janela do navegador vai aparecer, pedindo pra você entrar no Hugging Face usando um token write pra baixar o arquivo do modelo com segurança.
Depois de entrar no HuggingFace, clica em “start download” (começar download) no modelo que você quer e o download vai começar. Neste exemplo, estou usando o modelo padrão gemma3-270m-it-q8. Agora você pode começar a experimentar esse modelo.
Para este tutorial, fiz quatro experimentos:
Nessa experiência, pedi pro modelo escrever uma história livre, e aqui estão os resultados:
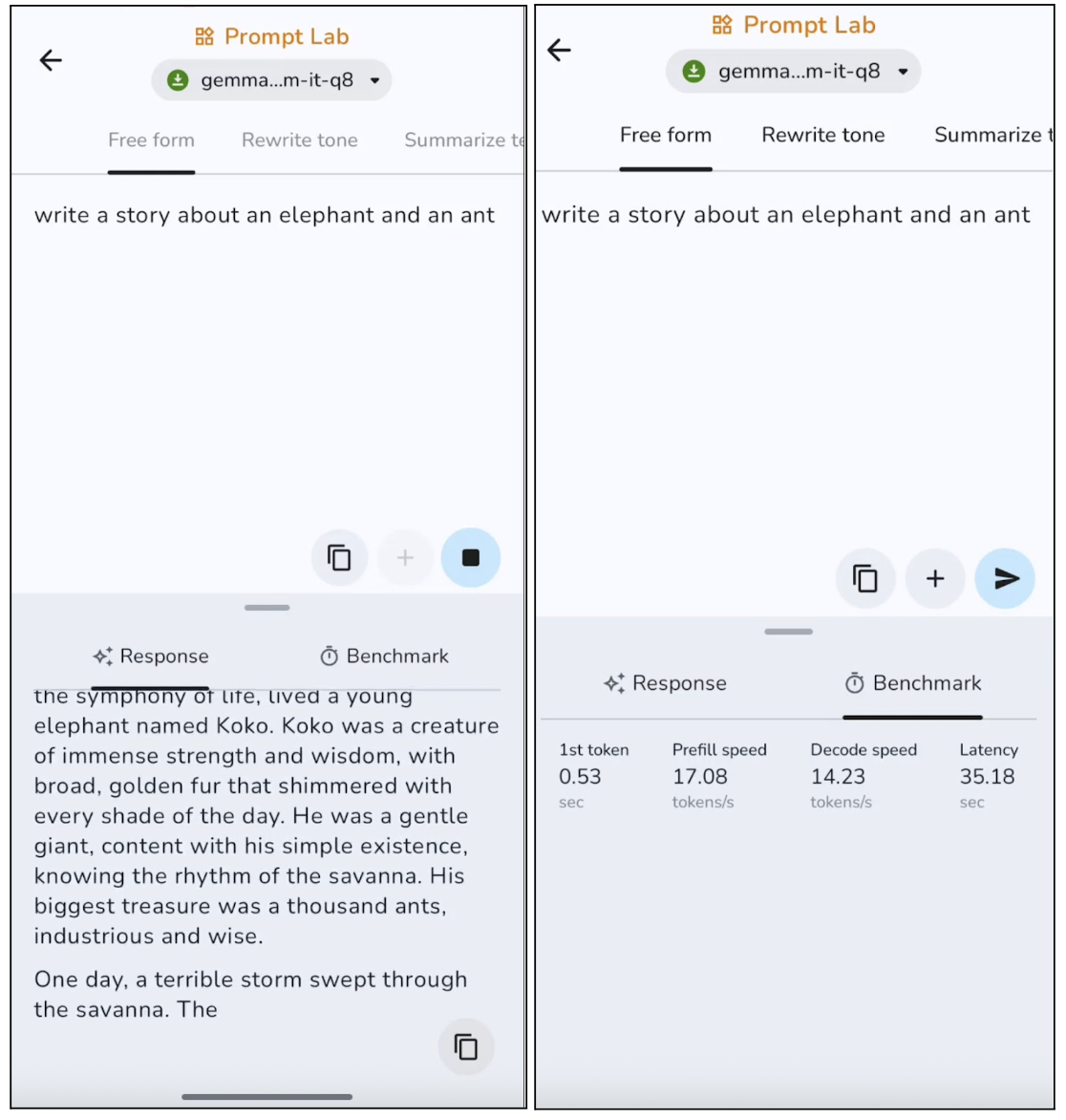
O modelo gera textos que falam do que é preciso, com uma estrutura clara, mas tende a ser meio genérico, pra não arriscar. Em saídas mais longas, o modelo geralmente repete certas frases. Isso faz com que seja mais legal para posts curtos, descrições e resumos. Mas, a geração do primeiro token é bem rápida, em torno de 0,53 segundos, e a velocidade de decodificação também é boa para inferência no dispositivo.
Depois, usei um parágrafo que já tinha escrito e pedi pra Gemma 3 270M reescrever o parágrafo num tom amigável.

A capacidade de seguir instruções é forte, com mudanças claras entre tons formais, informais e amigáveis, mantendo o significado. A velocidade é quase instantânea para trechos curtos, o que é ótimo para dar um toque final em e-mails ou converter textos entre estilos.
Também resumi o texto pré-escrito em pontos-chave. Você pode experimentar resumos, pontos, conclusões e muito mais.
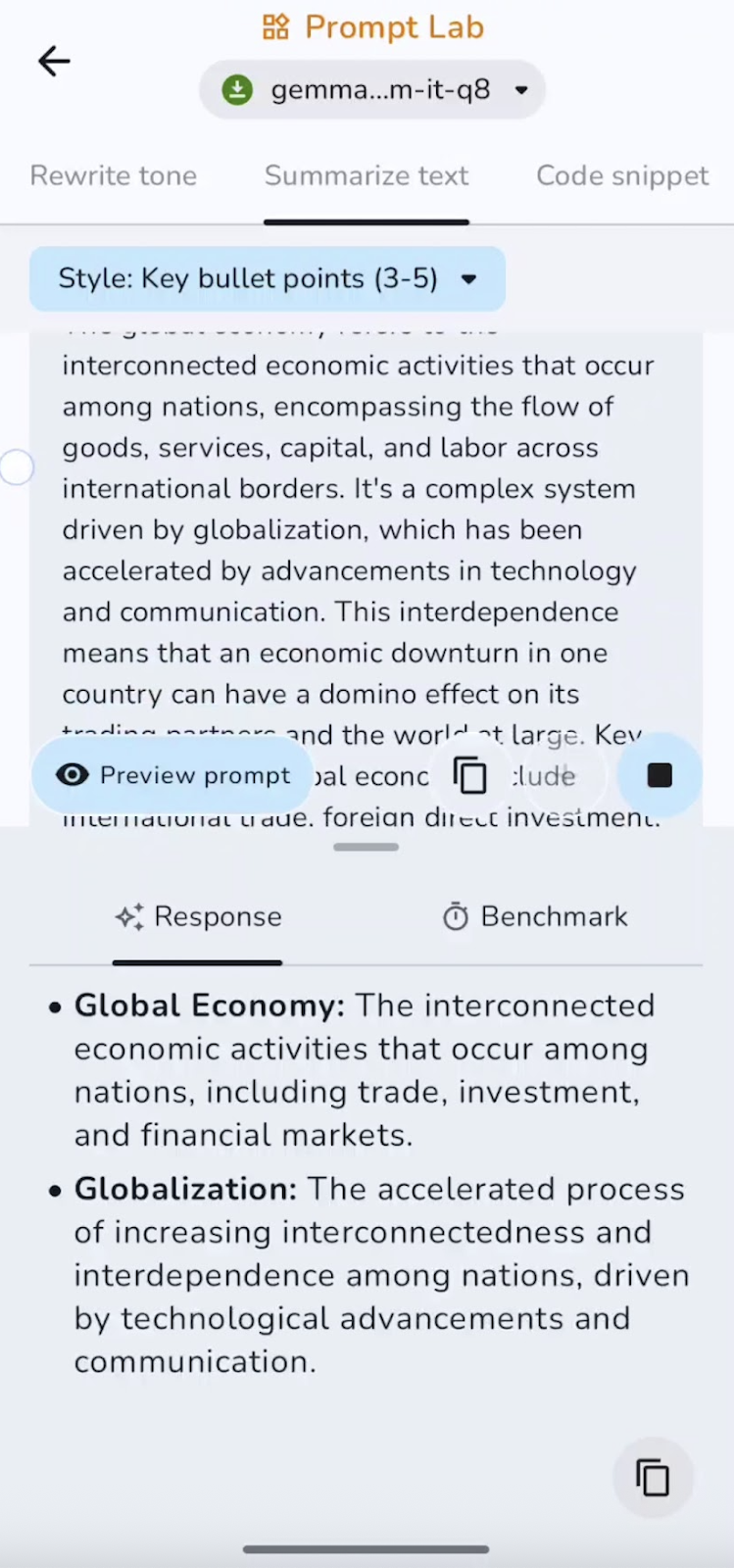
Nessa experiência, o modelo resume e capta os pontos principais. A velocidade é excelente para documentos curtos e médios. Alguns dos casos de uso podem ser resumos executivos, destaques em tópicos ou TL;DRs.
Por fim, pedi pra modelo escrever um pequeno trecho de código. Eis o que descobri:
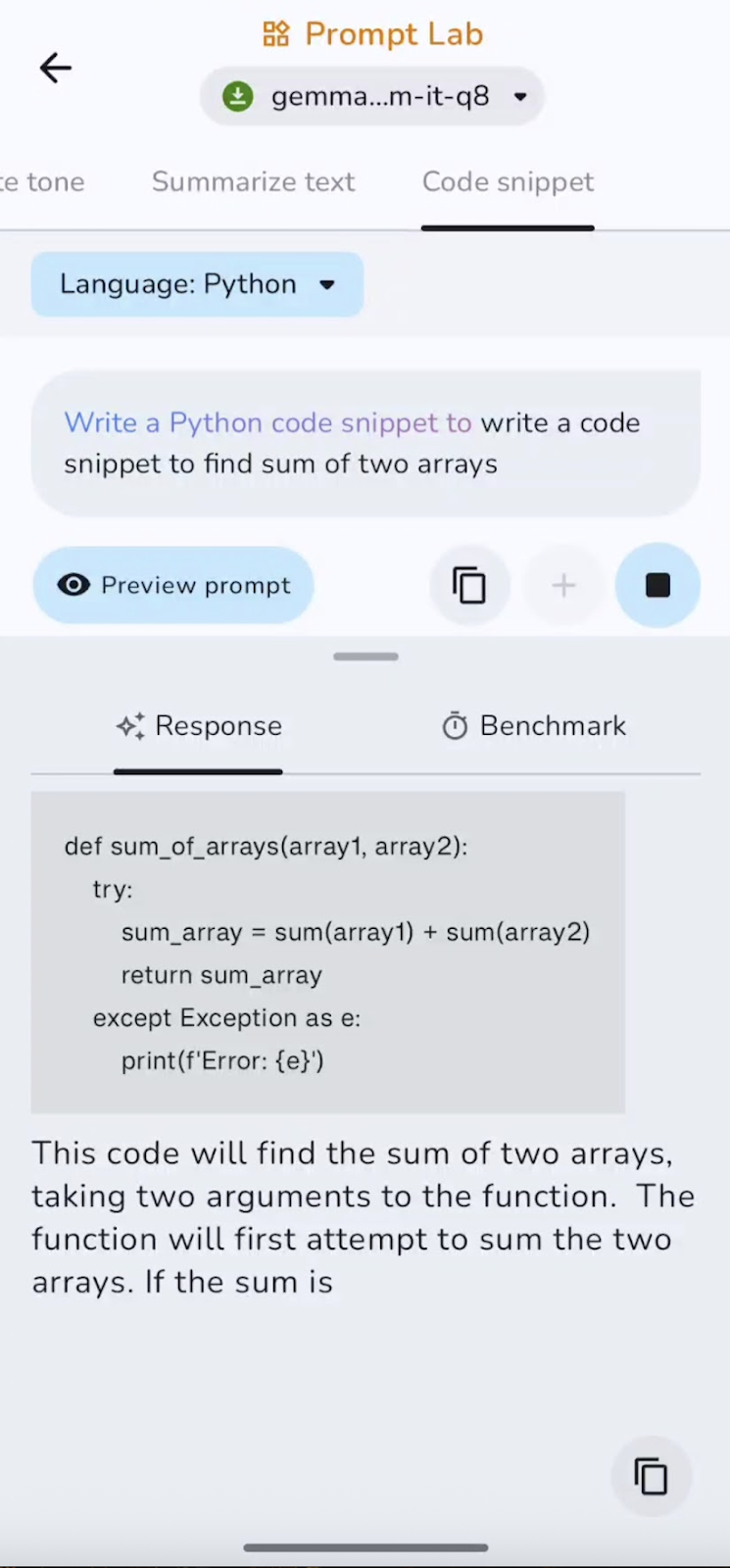
O modelo é bom pra gerar código padrão e pequenos utilitários, mas pode deixar passar importações, casos extremos ou lógica complexa sem uma orientação. Trechos curtos são gerados rapidinho, enquanto os mais longos demoram um pouco mais, conforme o contexto vai aumentando. Funciona melhor para funções auxiliares e configurações.
Eu criei esse repositório GitHub se você quiser dar uma olhada no código completo do projeto.
Neste guia, mostramos passo a passo como usar o modelo Gemma 3 270M, desde o download e a conexão do modelo em um aplicativo Android personalizado até como lidar com a navegação, a confiabilidade e a segurança durante a inferência.
O Gemma 3 oferece inferência rápida com baixo consumo de energia, usa pouquíssima energia, suporta quantização INT4 com impacto mínimo no desempenho e funciona totalmente no dispositivo para manter a privacidade.
Aprenda IA com esses cursos!
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Ryan Ong
Tutorial
Moez Ali




