
Curso
Entrenamiento eficiente de modelos de IA con PyTorch
4 h
1.5K
Google ha lanzado recientemente Gemma 3 270M, un modelo ultracompacto de 270 millones de parámetros que representa un nuevo paradigma en el despliegue eficiente de la IA. A diferencia de los modelos genéricos masivos, Gemma 3 270M está diseñado para un ajuste preciso para tareas específicas, al tiempo que mantiene la capacidad de seguir instrucciones desde el primer momento.
En este tutorial, te mostraré cómo empezar a utilizar Gemma 3 270M y te demostraré por qué es una excelente opción para los programadores que necesitan:
Mantenemos a nuestros lectores al día sobre las últimas novedades en IA mediante el envío de The Median, nuestro boletín informativo gratuito de los viernes que resume las noticias más importantes de la semana. Suscríbete y mantente al día en solo unos minutos a la semana:
Gemma 3 270M es un modelo básico compacto, diseñado para ofrecer un seguimiento preciso de las instrucciones y una generación de texto estructurada, todo ello con solo 270 millones de parámetros. Es el miembro más pequeño de la familia Gemma 3, pero hereda la misma arquitectura y las mismas recetas de entrenamiento que las variantes más grandes, como Gemma 3 1B y 4B.
A diferencia de los modelos grandes de uso general, Gemma 3 270M se centra en la eficiencia y la especialización. A continuación, se incluyen algunas indicaciones clave sobre este modelo:
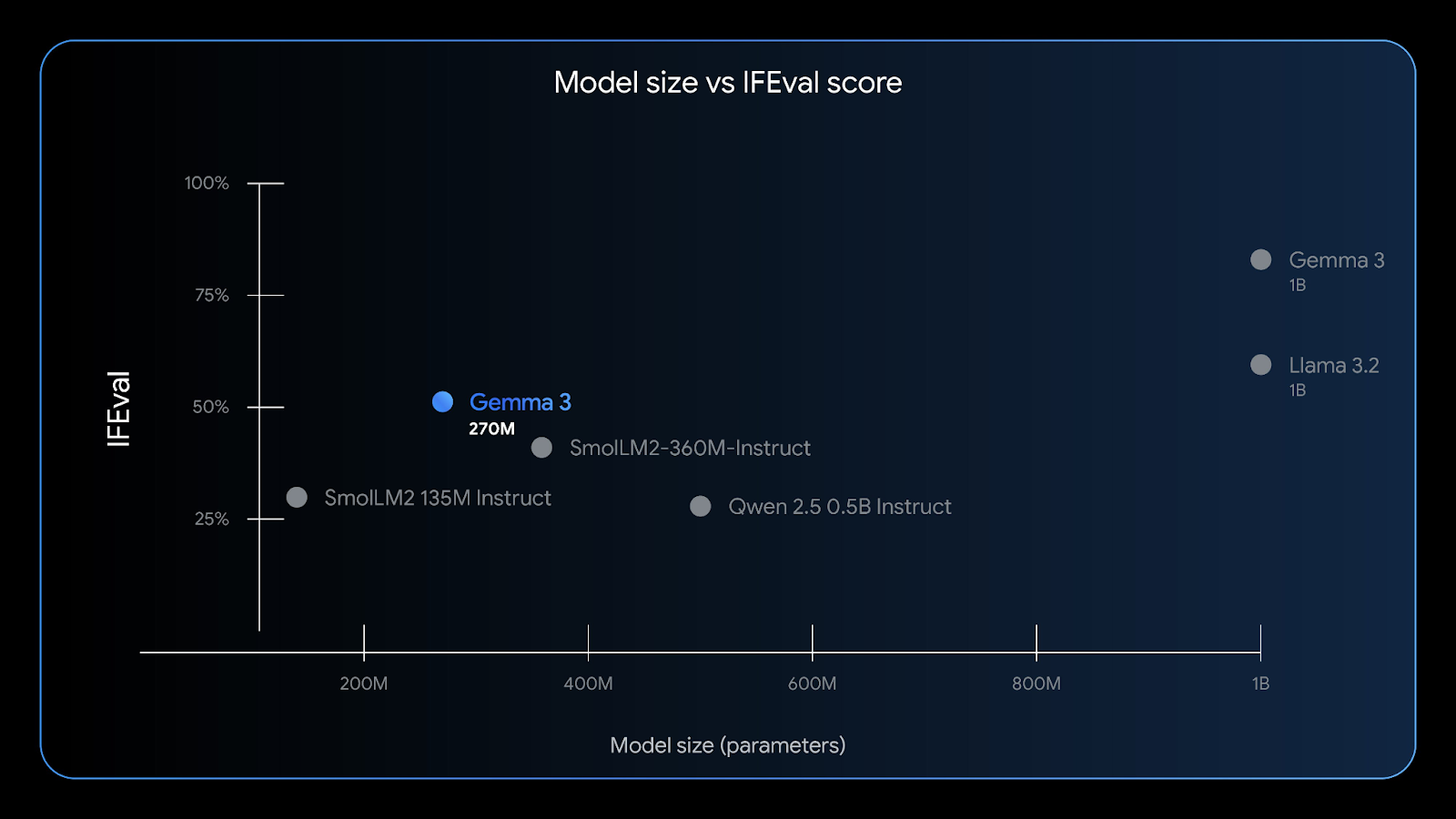
El Gemma 3 270M tiene una buena capacidad para seguir instrucciones: la prueba de referencia IFEval evalúa la capacidad de un modelo para seguir información verificable. Fuente: Google
Con una ventana de contexto de 32K, un bajo consumo de memoria y una gran precisión en tareas como la extracción de entidades, la clasificación y las comprobaciones de cumplimiento ligeras, Gemma 3 270M es perfecta para la desarrolladores de IA de vanguardia que buscan privacidad, velocidad y rentabilidad.
Hay varias formas sencillas de empezar a utilizar Gemma 3 270M, dependiendo de tu plataforma preferida:
Puedes implementar Gemma 3 en Google Cloud Run utilizando un contenedor acelerado por GPU precompilado para una inferencia escalable. Para Gemma 3 270M, debes crear tu contenedor desde el repositorio GitHub de repositorio GitHub de Gemma-on-CloudRun, ya que solo las variantes más grandes (1B+) están precompiladas. Sigue las instrucciones de la guía oficial de Google Cloud Run oficial de Google Cloud Run para habilitar una inferencia rápida, segura y rentable para aplicaciones web o de backend.
La mejor experiencia de usuario se obtiene en el dispositivo, utilizando una versión cuantificada de Gemma 3 270M (gemma3-270m-it-q8) y la aplicación oficial aplicación Gemma Gallery de Google. Este enfoque ofrece una inferencia offline extremadamente rápida, una gran privacidad y un consumo mínimo de batería.
También puedes ejecutar Gemma 3 270M en tu ordenador portátil utilizando herramientas como:
.gguf o .litertlm en tu entorno LM Studio y ejecútalo inmediatamente en su interfaz de chat o alójalo localmente.ollama run gemma:270m » para ejecutar este modelo localmente en tu equipo.Gemma 3 270M también está disponible en Hugging Face Transformers, JAX o Unsloth para ajustar en tus datos específicos del dominio. El pequeño tamaño del modelo lo hace ideal para experimentos rápidos y de bajo coste, y los puntos de control QAT permiten la implementación directa de INT4 tras el ajuste fino.
A continuación, te guiaré por el proceso de creación de una aplicación Android funcional que utiliza el modelo Gemma 3 270M para procesar indicaciones de texto. Usaremos el repositorio oficial de Google Gallery como base y lo personalizaremos.
Empecemos por configurar un nuevo proyecto y clonar el repositorio original de Google.
En tu ordenador portátil, empieza abriendo el proyecto como un proyecto nuevo en Android Studio y selecciona una actividad vacía.
A continuación, introduce el nombre de tu actividad (por ejemplo, «Gemma 3 270M») y deja el resto tal cual. A continuación, haz clic en Finalizar.
Ahora, abre el terminal dentro de Android Studio (esquina inferior izquierda) y ejecuta los siguientes comandos bash:
git clone https://github.com/google-ai-edge/gallery
cd gallery/android
Esto abrirá tu proyecto. Puedes ver todos los archivos del proyecto en la parte izquierda de la pestaña.
Para conectar el modelo Gemma 3 270M con tu aplicación Android, deberás registrarlo como una nueva tarea dentro del archivo Tasks.kt de la aplicación.
Ve a la carpeta « data/ » y abre el archivo « Tasks.kt ». Allí, definirás una nueva entrada de tarea específica para la variante cuantificada Q8 del modelo gemma3-270m-it-q8, que está optimizada para inferencias con poca memoria y en el dispositivo. Este formato es adecuado para dispositivos móviles con RAM limitada.
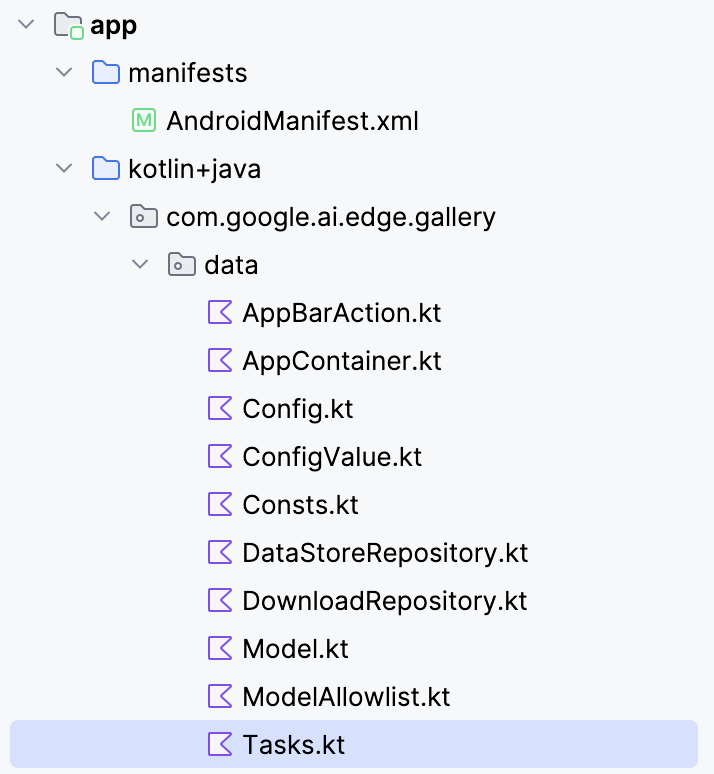
Nota: Para este tutorial, utilizaré una configuración de modelo Q8, que requiere menos memoria. Puedes acceder a este modelo aquí: https://huggingface.co/litert-community/gemma-3-270m-it
val TASK_GEMMA_3_270M = Task(
type = TaskType.LLM_PROMPT_LAB,
icon = Icons.Outlined.Widgets,
models = mutableListOf(
Model(
name = "gemma3-270m-it-q8",
downloadFileName = "gemma3-270m-it-q8.task",
url = "https://huggingface.co/litert-community/gemma-3-270m-it/resolve/main/gemma3-270m-it-q8.task",
sizeInBytes = 318_767_104L
)
),
description = "Gemma 3 270M (Q8): On-device instruction-following LLM",
docUrl = "https://ai.google.dev/gemma",
sourceCodeUrl = "https://github.com/google-ai-edge/gallery",
textInputPlaceHolderRes = R.string.chat_textinput_placeholder
)A continuación, registra esta nueva tarea en la aplicación incluyéndola en la lista de tareas principales:
/** All tasks */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE,
TASK_LLM_CHAT,
TASK_LLM_PROMPT_LAB,
TASK_IMAGE_CLASSIFICATION,
TASK_TEXT_CLASSIFICATION,
TASK_IMAGE_GENERATION,
TASK_GEMMA_3_270M
)A continuación se detalla lo que hace la nueva definición de tarea LiteRT en el código:
TASK_GEMMA_3_270M registra Gemma 3 270M como una opción seleccionable dentro del archivo Tasks.kt de la aplicación para que aparezca en la lista de tareas..task » (): El código anterior apunta al paquete gemma3-270m-it-q8.task alojado en Hugging Face, que se descarga dentro de la aplicación y se utiliza en tiempo de ejecución..task contiene los pesos cuantificados del modelo, el tokenizador, los metadatos y las configuraciones necesarias para que LiteRT ejecute el modelo de manera eficiente.TASK_GEMMA_3_270M ».De forma predeterminada, la aplicación Galería rellena sus listas de modelos desde un archivo JSON remoto de lista de permitidos. Si tu entrada personalizada Gemma 3 270M no aparece ahí, no aparecerá en la interfaz de usuario, aunque hayas añadido TASK_GEMMA_3_270M en el código. Este paso injerta tu modelo 270M en la tareaLLM Prompt Lab de después de que se cargue la lista de permitidos, lo que garantiza que se pueda seleccionar en todo momento.
Abre modelmanager/ModelManagerViewModel.kt, busca la función « loadModelAllowlist() » y (después del bucle que convierte los modelos de la lista de permitidos) añade:
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}He aquí por qué es necesario este código:
TASK_LLM_PROMPT_LAB.models desde la lista de permitidos del servidor al iniciarse. Tu modelo local se borraría a menos que lo vuelvas a introducir.any { it.name == gemmaModel.name } ) evita que se produzcan duplicados cuando se vuelve a ejecutar la función loadModelAllowlist().Aquí está la función completa:
fun loadModelAllowlist() {
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = true, loadingModelAllowlistError = ""
)
}
viewModelScope.launch(Dispatchers.IO) {
try {
withTimeoutOrNull(30000L) { // 30 second timeout
// Load model allowlist json.
Log.d(TAG, "Loading model allowlist from internet...")
val data = getJsonResponse<ModelAllowlist>(url = MODEL_ALLOWLIST_URL)
var modelAllowlist: ModelAllowlist? = data?.jsonObj
if (modelAllowlist == null) {
Log.d(TAG, "Failed to load model allowlist from internet. Trying to load it from disk")
modelAllowlist = readModelAllowlistFromDisk()
} else {
Log.d(TAG, "Done: loading model allowlist from internet")
saveModelAllowlistToDisk(modelAllowlistContent = data?.textContent ?: "{}")
}
if (modelAllowlist == null) {
Log.e(TAG, "Failed to load model allowlist from both internet and disk")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list"
)
}
return@withTimeoutOrNull
}
Log.d(TAG, "Allowlist: $modelAllowlist")
// Convert models in the allowlist.
TASK_LLM_CHAT.models.clear()
TASK_LLM_PROMPT_LAB.models.clear()
TASK_LLM_ASK_IMAGE.models.clear()
try {
for (allowedModel in modelAllowlist.models) {
if (allowedModel.disabled == true) {
continue
}
val model = allowedModel.toModel()
if (allowedModel.taskTypes.contains(TASK_LLM_CHAT.type.id)) {
TASK_LLM_CHAT.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_PROMPT_LAB.type.id)) {
TASK_LLM_PROMPT_LAB.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_ASK_IMAGE.type.id)) {
TASK_LLM_ASK_IMAGE.models.add(model)
}
}
// Add models from TASK_GEMMA_3_270M to LLM_PROMPT_LAB
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error processing model allowlist", e)
}
// Pre-process all tasks.
try {
processTasks()
} catch (e: Exception) {
Log.e(TAG, "Error processing tasks", e)
}
// Update UI state.
val newUiState = createUiState()
_uiState.update {
newUiState.copy(
loadingModelAllowlist = false,
)
}
// Process pending downloads.
try {
processPendingDownloads()
} catch (e: Exception) {
Log.e(TAG, "Error processing pending downloads", e)
}
} ?: run {
// Timeout occurred
Log.e(TAG, "Model allowlist loading timed out")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Model list loading timed out"
)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error in loadModelAllowlist", e)
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list: ${e.message}"
)
}
}
}
}De forma predeterminada, la aplicación asume que la tarea seleccionada actualmente coincide con el modelo en el que has hecho clic. Una vez que inyectas Gemma 3 270M en la tarea Prompt Lab (paso 3), esa suposición puede romperse. Este paso hace que la navegación reconozca el modelo, por lo que los toques, los enlaces profundos y el estado restaurado siempre llegan a la pantalla correcta.
Abrir navigation/GalleryNavGraph.kt y actualiza la lógica de control de navegación del modelo de la siguiente manera:
Antes:
onModelClicked = { model ->
navigateToTaskScreen(
navController = navController, taskType = curPickedTask.type, model = model
)
}Después:
onModelClicked = { model ->
Log.d("GalleryNavGraph", "Model clicked: ${model.name}, current task: ${curPickedTask.type}")
val actualTask = when {
TASK_LLM_CHAT.models.any { it.name == model.name } -> TASK_LLM_CHAT
TASK_LLM_PROMPT_LAB.models.any { it.name == model.name } -> TASK_LLM_PROMPT_LAB
TASK_LLM_ASK_IMAGE.models.any { it.name == model.name } -> TASK_LLM_ASK_IMAGE
TASK_TEXT_CLASSIFICATION.models.any { it.name == model.name } -> TASK_TEXT_CLASSIFICATION
TASK_IMAGE_CLASSIFICATION.models.any { it.name == model.name } -> TASK_IMAGE_CLASSIFICATION
TASK_IMAGE_GENERATION.models.any { it.name == model.name } -> TASK_IMAGE_GENERATION
else -> curPickedTask
}
Log.d("GalleryNavGraph", "Navigating to task: ${actualTask.type} for model: ${model.name}")
navigateToTaskScreen(
navController = navController, taskType = actualTask.type, model = model
)
}Si un modelo aparece (o se ha inyectado) en una tarea diferente a la seleccionada actualmente, este código garantiza que la pantalla se ajusta a las capacidades del modelo.
Al tratar enlaces profundos o estados restaurados, es posible que la aplicación intente abrir un modelo que ya no está disponible. Sin un manejo adecuado, esto provocaría una pantalla en blanco. Para evitarlo, añadimos una comprobación de seguridad que, si el modelo no existe, registra una advertencia y redirige al usuario. Así es como lo hacemos:
// Added error handling for model not found:
if (model != null) {
Log.d("GalleryNavGraph", "Model found for LlmChat: ${model.name}")
modelManagerViewModel.selectModel(model)
LlmChatScreen(/* ... */)
} else {
Log.w("GalleryNavGraph", "Model not found for LlmChat, modelName: ${it.arguments?.getString("modelName")}")
// Handle case where model is not found
androidx.compose.runtime.LaunchedEffect(Unit) {
navController.navigateUp()
}
}Este código garantiza que la aplicación siga funcionando. En lugar de bloquearse o mostrar una pantalla en blanco, vuelve a navegar de forma segura utilizando navController. De esta forma, aunque falte un modelo, el flujo de usuarios continúa con normalidad sin interrumpir la experiencia general.
Ejecutar un modelo de lenguaje grande en un dispositivo móvil es diferente a ejecutarlo en un ordenador de sobremesa. El almacenamiento puede ser poco fiable, los presupuestos para memoria son más ajustados y es necesario gestionar los fallos de inicialización para evitar que las aplicaciones se bloqueen. Para que Gemma 3 270M (Q8, ~304 MB) sea estable en Android, he introducido comprobaciones de seguridad adicionales y estrategias de conmutación por error.
Antes de cargar el modelo, la aplicación realiza comprobaciones de integridad en el archivo .task. Esto garantiza que el archivo del modelo existe, es legible y tiene un tamaño similar al esperado (con una diferencia máxima del ±10 %). Esta tolerancia tiene en cuenta ligeras diferencias debidas a la compresión o al embalaje, al tiempo que detecta descargas corruptas o parciales.
// File validation and logging
Log.d(TAG, "Checking model file: $modelPath")
Log.d(TAG, "Model file exists: ${modelFile.exists()}")
Log.d(TAG, "Model file can read: ${modelFile.canRead()}")
Log.d(TAG, "Model file size: ${modelFile.length()} bytes")
Log.d(TAG, "Model file absolute path: ${modelFile.absolutePath}")
// Size validation with tolerance (10%)
val expectedSize = model.sizeInBytes
val fileSize = modelFile.length()
val sizeDifference = kotlin.math.abs(fileSize - expectedSize)
val sizeTolerance = (expectedSize * 0.1).toLong()
if (!modelFile.exists() || !modelFile.canRead() || sizeDifference > sizeTolerance) {
onDone("Model file invalid (missing/unreadable/wrong size).")
return
}Este fragmento de código valida un archivo de modelo antes de cargarlo. Registra detalles básicos como la ruta, la legibilidad y el tamaño, y luego comprueba si el archivo existe, es legible y coincide con el tamaño esperado. Si alguna de estas comprobaciones falla, la función se detiene prematuramente mediante el método « onDone() » en lugar de intentar la inferencia y arriesgarse a que se produzca un fallo.
Los modelos grandes pueden dar errores de memoria insuficiente (OOM) si se inician de forma agresiva (salidas largas, picos de asignación de GPU). Para mitigar esto, añadí una lógica para elegir dinámicamente el backend más seguro (CPU frente a GPU/NPU) en función del tamaño del archivo y la configuración del dispositivo, al tiempo que recortaba los tokens máximos para los binarios de gran tamaño.
val preferredBackend = when {
fileSize > 200_000_000L -> {
Log.d(TAG, "Model is large (${fileSize / 1024 / 1024}MB), using CPU backend for safety")
LlmInference.Backend.CPU
}
accelerator == Accelerator.CPU.label -> LlmInference.Backend.CPU
accelerator == Accelerator.GPU.label -> LlmInference.Backend.GPU
else -> LlmInference.Backend.CPU
}
val baseMaxTokens = 1024 // your default; tune to taste
val maxTokens = if (fileSize > 200_000_000L) {
kotlin.math.min(baseMaxTokens, 512)
} else {
baseMaxTokens
}Esto garantiza que los modelos grandes se ejecuten por defecto en la CPU (más seguro pero más lento). El código comprueba el tamaño en bytes del archivo .task (fileSize) y lo compara con un umbral (maxTokens). Si supera los 200 MB, cambia la inferencia a la CPU y reduce a la mitad el presupuesto de tokens. Esto protege contra picos de memoria (debido a la asignación simultánea de la GPU) y solicitudes de generación de gran tamaño.
Al inicializar LiteRT, es importante distinguir entre la creación en tiempo de ejecución y la creación de sesiones. Si la creación de la sesión falla pero dejás el tiempo de ejecución abierto, podés perder recursos y bloquear la memoria, lo que provocaría fallos en cadena. Para solucionarlo, envolví el código en bloques try/catch con limpieza explícita.
val llmInference = try {
LlmInference.createFromOptions(context, options)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInference instance", e)
onDone("Failed to create model instance: ${e.message}")
return
}
val session = try {
LlmInferenceSession.createFromOptions(/* ... */)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInferenceSession", e)
try {
llmInference.close()
} catch (closeException: Exception) {
Log.e(TAG, "Failed to close LlmInference after session creation failure", closeException)
}
onDone("Failed to create model session: ${e.message}")
return
}Este try/catch garantiza una reversión limpia, es decir, si falla la creación en tiempo de ejecución, no se continúa con nada más, pero si falla la creación de la sesión, se cierra explícitamente el tiempo de ejecución. Garantiza que el objeto llmInference asignado en el montón se elimine mediante .close(), liberando memoria y manejadores de archivos. Sin esto, corres el riesgo de que las referencias JNI se bloqueen en la próxima carga del modelo.
Incluso si un modelo se carga correctamente, la inferencia puede fallar debido a condiciones de carrera, referencias nulas o instancias no inicializadas. Para reforzar este paso, he añadido comprobaciones nulas y excepciones de captura alrededor del bloque de inferencia completo.
try {
Log.d(TAG, "Starting inference for model '${model.name}' with input: '${input.take(50)}...'")
val instance = model.instance as LlmModelInstance? ?: run {
Log.e(TAG, "Model instance is null for '${model.name}'")
resultListener("Error: Model not initialized", true)
return
}
} catch (e: Exception) {
Log.e(TAG, "Error during inference for model '${model.name}'", e)
resultListener("Error during inference: ${e.message}", true)
}El código anterior garantiza que la inferencia solo se realice con una instancia de modelo válida y detecta los errores de tiempo de ejecución de forma clara. El cast e as LlmModelInstance? comprueba si la instancia del modelo está correctamente tipada y el fallback tipo Elvis interrumpe la ejecución si es nula. Envolver el bloque en try/catch garantiza que cualquier excepción sea detectada y redirigida como mensajes de error visibles para el usuario.
Una vez que hayas realizado todos los cambios necesarios, ejecutaremos la aplicación. Para ejecutar la aplicación en tu dispositivo Android local, empareja tu dispositivo Android con Android Studio mediante la depuración inalámbrica siguiendo estos pasos.
Ve a la aplicación Ajustes de tu dispositivo Android y activa las opciones de programadore. A continuación, activala depuración inalámbrica en . Deberías ver una pantalla con dos opciones de emparejamiento.
En Android Studio, abre Administrador de dispositivos (el icono se parece a un teléfono con el logotipo de Android) y haz clic en Emparejar mediante código QR.
Escanea el código QR con tu dispositivo y completa la configuración del emparejamiento. Una vez conectado el dispositivo, verás su nombre en el Administrador de dispositivos. Asegúrate de que tu sistema y tu dispositivo Android estén conectados a la misma red WiFi.
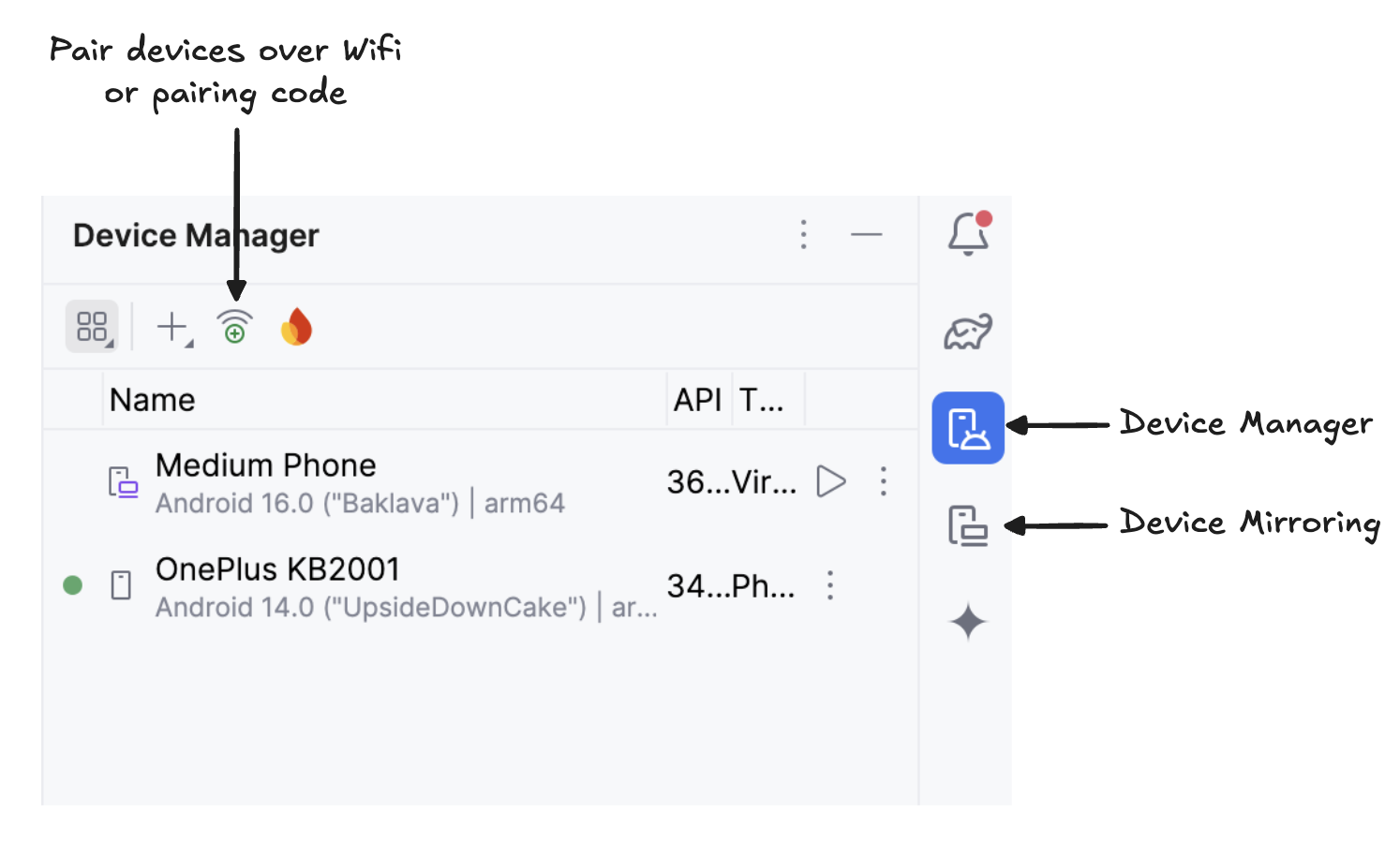
Empieza a duplicar tu dispositivo Android haciendo clic en el iconoDuplicación de dispositivos ( ) (que representa una pantalla de escritorio y una pantalla de teléfono). Una vez que veas la pantalla de tu dispositivo duplicada, haz clic en el icono verde« » (Ejecutar) para instalar la aplicación en tu dispositivo.
Se iniciará la aplicación y se abrirá una ventana del navegador, en la que se te pedirá que inicies sesión en Hugging Face con un token write para descargar de forma segura el archivo del modelo.
Una vez que hayas iniciado sesión en HuggingFace, haz clic en «Start download» (Iniciar descarga) en el modelo que elijas, en la parte superior de la página, y tu modelo comenzará a descargarse. Para este ejemplo, estoy utilizando el modelo gemma3-270m-it-q8 por defecto. Ahora puedes empezar a experimentar con este modelo.
Para este tutorial, realicé cuatro experimentos:
En este experimento, le pedí al modelo que escribiera una historia libre, y estos son los resultados:
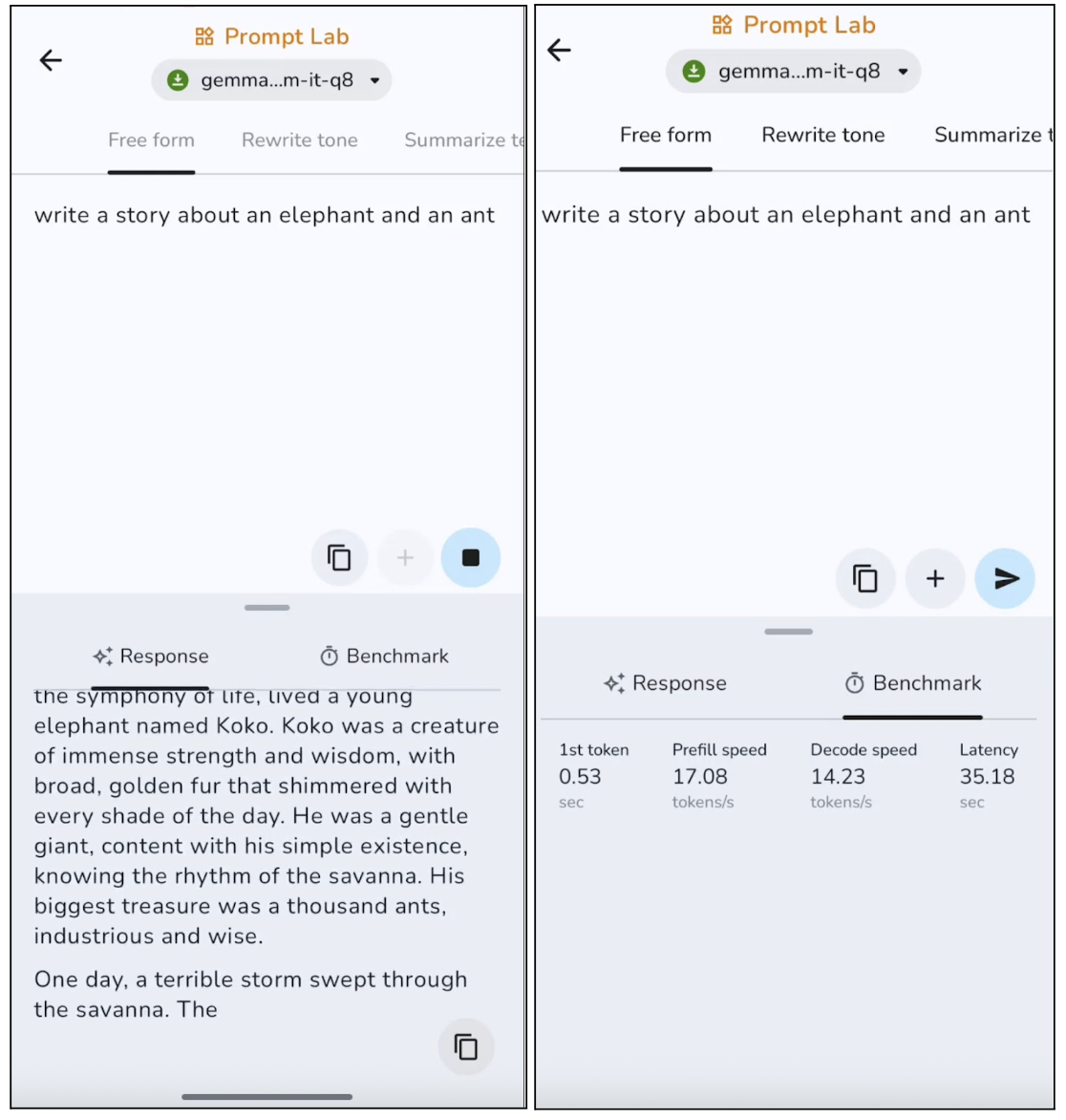
El modelo produce textos pertinentes con una estructura clara, aunque tiende a ir sobre seguro y a resultar algo genérico. En salidas más largas, el modelo suele repetir ciertas frases. Esto lo hace ideal para publicaciones cortas, descripciones y resúmenes. Sin embargo, la generación del primer token es bastante rápida, alrededor de 0,53 segundos, y la velocidad de decodificación también es buena para la inferencia en el dispositivo.
A continuación, utilicé un párrafo ya escrito y le pedí a Gemma 3 270M que lo reescribiera en un tono amistoso.

La capacidad para seguir instrucciones es buena, con cambios claros entre tonos formales, informales y amistosos, sin perder el significado. La velocidad es casi instantánea para pasajes cortos, lo que lo hace ideal para pulir correos electrónicos o convertir texto entre diferentes estilos.
También resumí el texto escrito previamente en puntos clave. Puedes experimentar con resúmenes, puntos clave, conclusiones y mucho más.
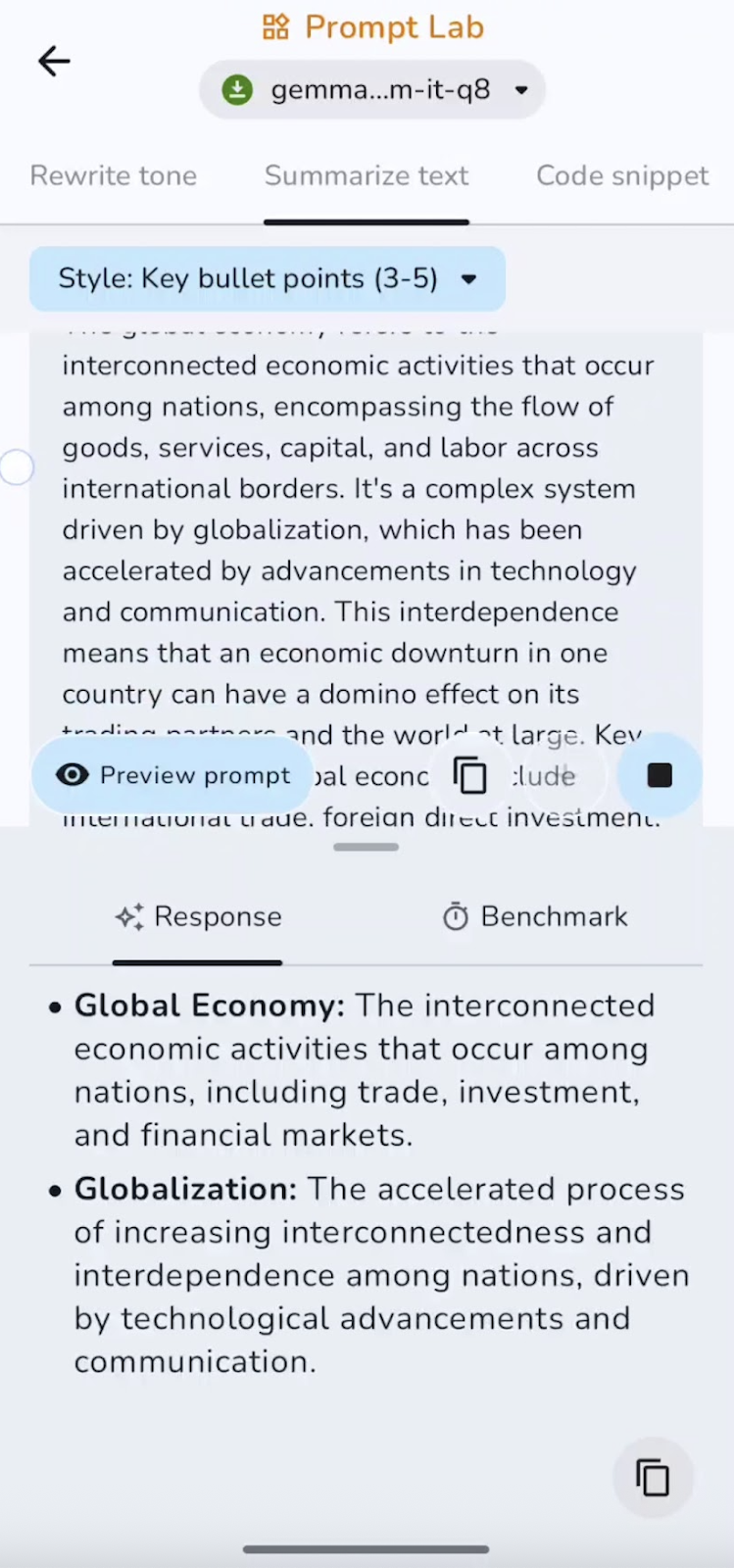
En este experimento, el modelo resume y captura los puntos clave. La velocidad es excelente para documentos cortos y medianos. Algunos de los casos de uso pueden ser resúmenes ejecutivos, puntos destacados o TL;DR.
Por último, le pedí al modelo que escribiera un pequeño fragmento de código. Esto es lo que he encontrado:
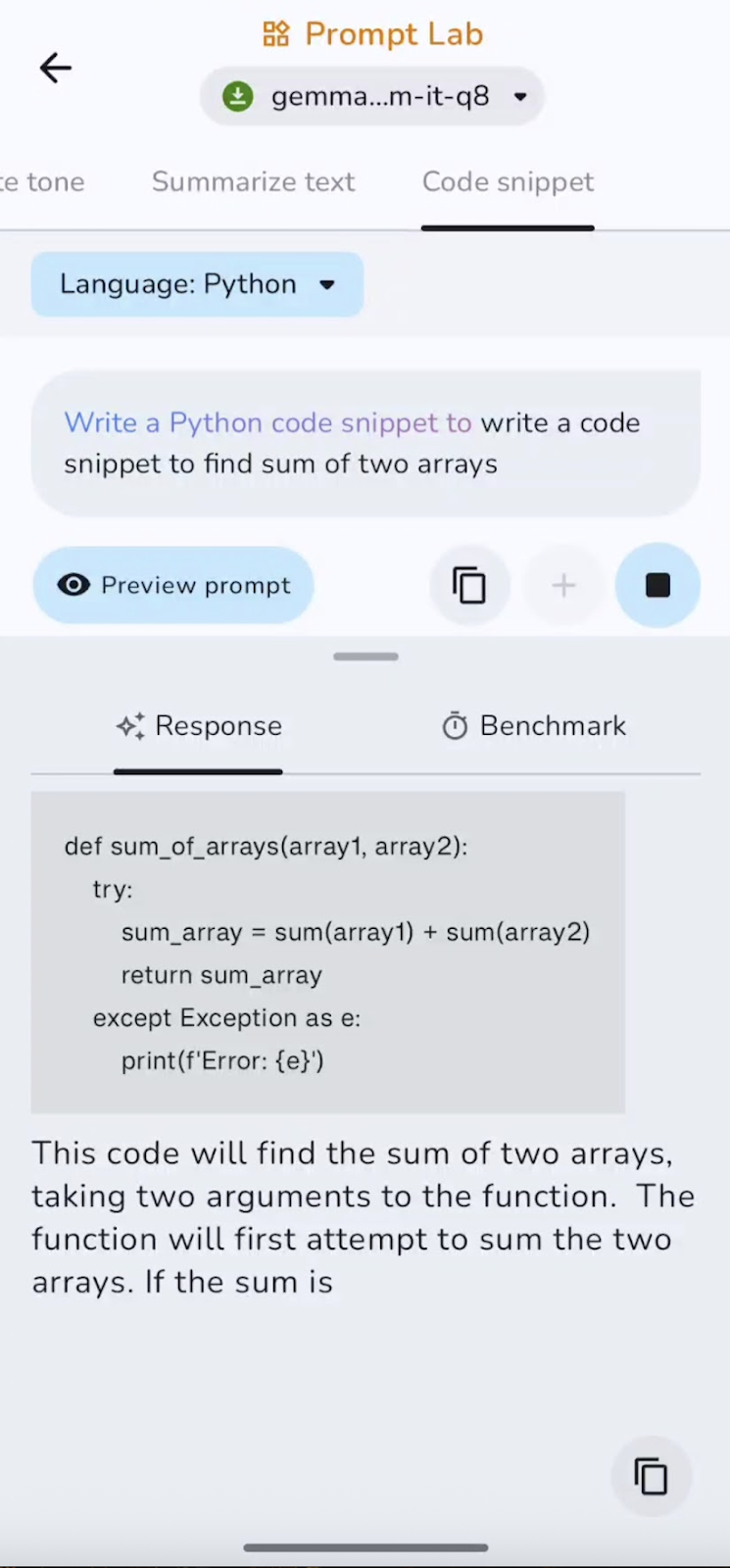
El modelo es eficaz para generar código repetitivo y pequeñas utilidades, aunque puede pasar por alto importaciones, casos extremos o lógica compleja sin orientación. Los fragmentos cortos se generan rápidamente, mientras que las completaciones más largas se ralentizan ligeramente a medida que aumenta el contexto. Funciona mejor para funciones auxiliares y configuraciones.
He creado este repositorio GitHub por si quieres explorar el código completo del proyecto.
En esta guía, hemos explicado paso a paso cómo ejecutar el modelo Gemma 3 270M, desde la descarga y la conexión del modelo a una aplicación Android personalizada, hasta la gestión de la navegación, la fiabilidad y la seguridad en el tiempo de inferencia.
Gemma 3 ofrece una inferencia rápida con una baja sobrecarga computacional, consume muy poca energía, admite la cuantificación INT4 con un impacto mínimo en el rendimiento y se ejecuta íntegramente en el dispositivo para mantener la privacidad.
¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Ryan Ong
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali




