
Cours
Entraîner efficacement des modèles d’IA avec PyTorch
4 h
1.5K
Google a récemment publié Gemma 3 270M, un modèle ultra-compact de 270 millions de paramètres qui représente un nouveau paradigme dans le déploiement efficace de l'IA. Contrairement aux modèles généraux de grande envergure, Gemma 3 270M est conçu pour un réglage précis en fonction des tâches à accomplir, tout en conservant ses capacités d'exécution des instructions dès sa sortie de l'emballage.
Dans ce tutoriel, je vais vous montrer comment démarrer avec Gemma 3 270M et vous expliquer pourquoi il s'agit d'un excellent choix pour les développeurs qui ont besoin :
Nous tenons nos lecteurs informés des dernières actualités en matière d'IA grâce à The Median, notre newsletter hebdomadaire gratuite qui résume les articles les plus importants de la semaine. Abonnez-vous et restez informé en quelques minutes par semaine :
Gemma 3 270M est un modèle de base compact, conçu pour offrir une excellente capacité à suivre des instructions et à générer des textes structurés, le tout avec seulement 270 millions de paramètres. C'est le plus petit membre de la famille Gemma 3, mais il hérite de la même architecture et des mêmes recettes de formation que les variantes plus grandes telles que Gemma 3 1B et 4B.
Contrairement aux modèles généraux de grande taille, le Gemma 3 270M est axé sur l'efficacité et la spécialisation. Voici quelques points importants concernant ce modèle :
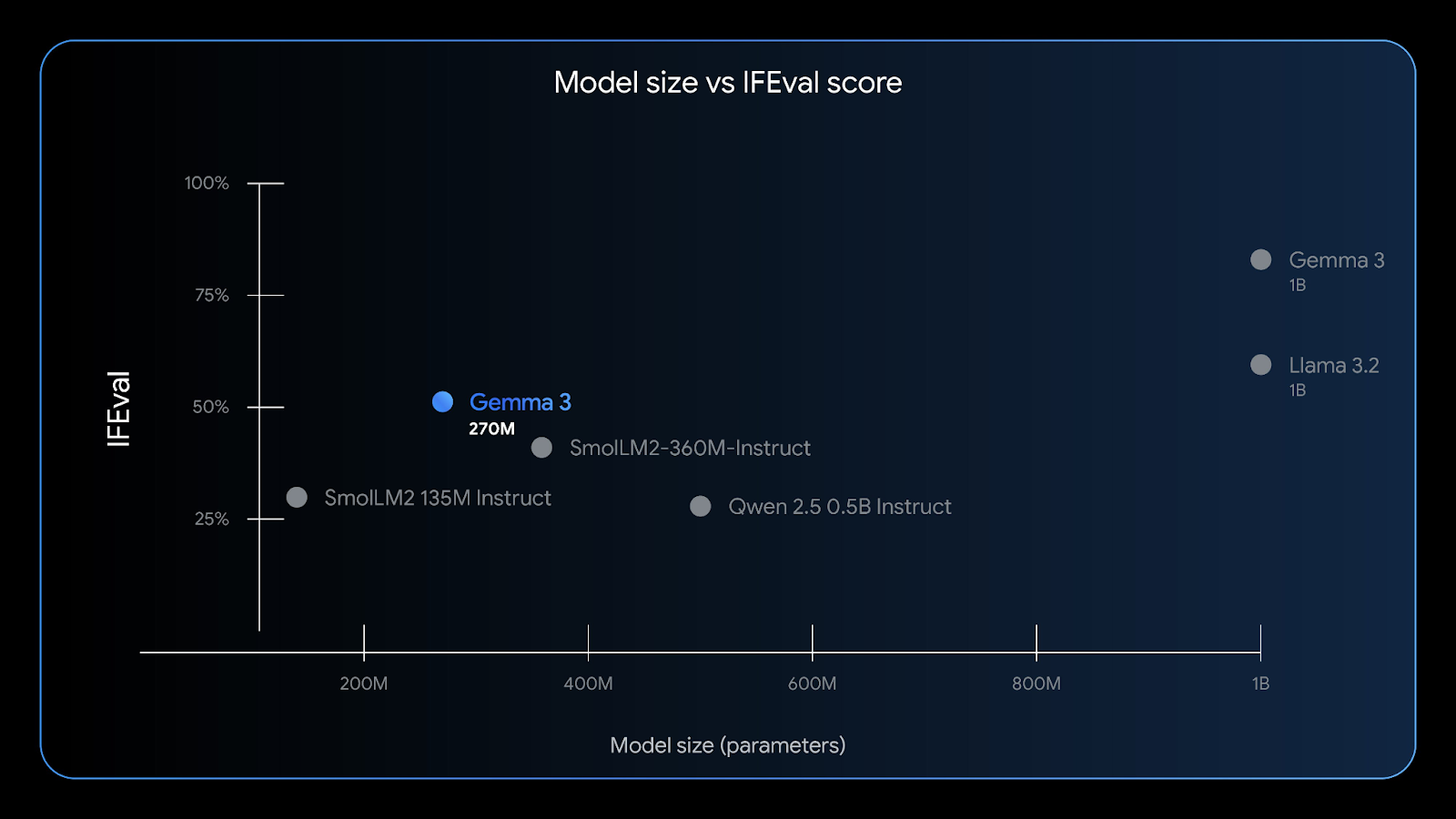
Gemma 3 270M présente de bonnes capacités de suivi des instructions : le benchmark IFEval teste la capacité d'un modèle à suivre des informations vérifiables. Source : Google
Avec une fenêtre contextuelle de 32 Ko, une faible consommation de mémoire et une grande précision dans des tâches telles que l'extraction d'entités, la classification et les contrôles de conformité légers, Gemma 3 270M est idéal pour l' développeurs d'IA de pointe à la recherche de confidentialité, de rapidité et de rentabilité.
Il existe plusieurs façons simples de commencer à utiliser Gemma 3 270M, selon votre plateforme préférée :
Vous pouvez déployer Gemma 3 sur Google Cloud Run. Google Cloud Run à l'aide d'un conteneur pré-intégré accéléré par GPU pour une inférence évolutive. Pour Gemma 3 270M, vous devez créer votre conteneur à partir du référentiel GitHub Gemma-on-CloudRun, car seules les variantes plus volumineuses (1B+) sont précompilées. Veuillez suivre les instructions fournies dans le guide officiel Google Cloud Run. officiel de Google Cloud Run pour activer une inférence rapide, sécurisée et économique pour les applications Web ou backend.
La meilleure expérience utilisateur est obtenue sur l'appareil, en utilisant une version quantifiée de Gemma 3 270M (gemma3-270m-it-q8) et l'application officielle Gemma Gallery. application Gemma Gallery de Google. Cette approche offre une inférence hors ligne extrêmement rapide, une confidentialité renforcée et une consommation minimale de la batterie.
Vous pouvez également exécuter Gemma 3 270M sur votre ordinateur portable à l'aide d'outils tels que :
.gguf ou .litertlm dans votre environnement LM Studio et l'exécuter immédiatement dans son interface de chat ou l'héberger localement.ollama run gemma:270m » pour exécuter ce modèle localement sur votre ordinateur.Gemma 3 270M est également disponible dans Hugging Face Transformers, JAX ou Unsloth pour ajuster sur vos données spécifiques à votre domaine. La petite taille du modèle le rend idéal pour des expériences rapides et peu coûteuses, et les points de contrôle QAT permettent un déploiement INT4 direct après le réglage fin.
Ensuite, je vais vous expliquer comment créer une application Android fonctionnelle qui utilise le modèle Gemma 3 270M pour traiter des invites textuelles. Nous utiliserons le référentiel officiel Gallery de Google comme base et le personnaliserons.
Commençons par créer un nouveau projet et cloner le dépôt original à partir de Google.
Sur votre ordinateur portable, commencez par ouvrir le projet en tant que nouveau projet dans Android Studio et sélectionnez une activité vide.
Ensuite, veuillez saisir le nom de votre activité (par exemple, « Gemma 3 270M ») et conservez le reste tel quel. Ensuite, veuillez cliquer sur Terminer.
Maintenant, veuillez ouvrir le terminal dans Android Studio (coin inférieur gauche) et exécuter les commandes bash suivantes :
git clone https://github.com/google-ai-edge/gallery
cd gallery/android
Cela ouvrira votre projet. Vous pouvez afficher tous les fichiers du projet sur le côté gauche de l'onglet.
Pour connecter le modèle Gemma 3 270M à votre application Android, vous devez l'enregistrer en tant que nouvelle tâche dans le fichier Tasks.kt de l'application.
Accédez au dossier « data/ » et ouvrez le fichier « Tasks.kt ». Vous y définirez une nouvelle entrée de tâche spécifiquement pour la variante quantifiée Q8 du modèle gemma3-270m-it-q8, qui est optimisée pour une inférence à faible mémoire et sur appareil. Ce format est adapté aux appareils mobiles disposant d'une mémoire vive limitée.
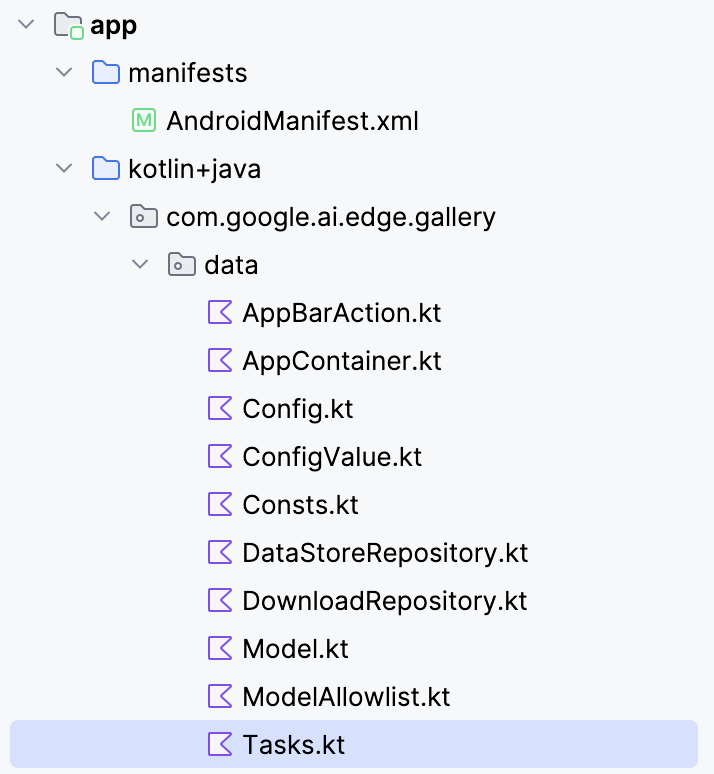
Remarque : Pour ce tutoriel, j'utiliserai une configuration de modèle Q8, qui nécessite moins de mémoire. Vous pouvez accéder à ce modèle ici : https://huggingface.co/litert-community/gemma-3-270m-it
val TASK_GEMMA_3_270M = Task(
type = TaskType.LLM_PROMPT_LAB,
icon = Icons.Outlined.Widgets,
models = mutableListOf(
Model(
name = "gemma3-270m-it-q8",
downloadFileName = "gemma3-270m-it-q8.task",
url = "https://huggingface.co/litert-community/gemma-3-270m-it/resolve/main/gemma3-270m-it-q8.task",
sizeInBytes = 318_767_104L
)
),
description = "Gemma 3 270M (Q8): On-device instruction-following LLM",
docUrl = "https://ai.google.dev/gemma",
sourceCodeUrl = "https://github.com/google-ai-edge/gallery",
textInputPlaceHolderRes = R.string.chat_textinput_placeholder
)Ensuite, enregistrez cette nouvelle tâche dans l'application en l'ajoutant à la liste des tâches principales :
/** All tasks */
val TASKS: List<Task> = listOf(
TASK_LLM_ASK_IMAGE,
TASK_LLM_CHAT,
TASK_LLM_PROMPT_LAB,
TASK_IMAGE_CLASSIFICATION,
TASK_TEXT_CLASSIFICATION,
TASK_IMAGE_GENERATION,
TASK_GEMMA_3_270M
)Voici une description détaillée de ce que fait la nouvelle définition de tâche LiteRT dans le code :
TASK_GEMMA_3_270M enregistre Gemma 3 270M comme option sélectionnable dans le fichier Tasks.kt de l'application afin qu'elle apparaisse dans la liste des tâches..task : Le code ci-dessus pointe vers le bundle gemma3-270m-it-q8.task hébergé sur Hugging Face, qui est téléchargé dans l'application et utilisé lors de l'exécution..task contient les poids du modèle quantifié, le tokenizer, les métadonnées et les configurations nécessaires à LiteRT pour exécuter le modèle de manière efficace.TASK_GEMMA_3_270M ».Par défaut, l'application Galerie remplit ses listes de modèles à partir d'un fichier JSON de liste blanche distant. Si votre entrée Gemma 3 270M personnalisée n'y figure pas, elle n'apparaîtra pas dans l'interface utilisateur, même si vous avez ajouté TASK_GEMMA_3_270M dans le code. Cette étape greffe votre modèle 270M dans la tâcheLLM Prompt Lab de l' après le chargement de la liste blanche, garantissant ainsi qu'il soit sélectionnable à chaque fois.
Ouvrez le fichier modelmanager/ModelManagerViewModel.kt, recherchez la fonction loadModelAllowlist() et ajoutez ce qui suit après la boucle qui convertit les modèles autorisés :
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}Voici pourquoi ce code est nécessaire :
TASK_LLM_PROMPT_LAB.models s à partir de la liste blanche du serveur au démarrage. Votre modèle local sera effacé à moins que vous ne le réinjectiez.any { it.name == gemmaModel.name } empêche les doublons lorsque la fonction loadModelAllowlist() est exécutée à nouveau.Voici la fonction complète :
fun loadModelAllowlist() {
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = true, loadingModelAllowlistError = ""
)
}
viewModelScope.launch(Dispatchers.IO) {
try {
withTimeoutOrNull(30000L) { // 30 second timeout
// Load model allowlist json.
Log.d(TAG, "Loading model allowlist from internet...")
val data = getJsonResponse<ModelAllowlist>(url = MODEL_ALLOWLIST_URL)
var modelAllowlist: ModelAllowlist? = data?.jsonObj
if (modelAllowlist == null) {
Log.d(TAG, "Failed to load model allowlist from internet. Trying to load it from disk")
modelAllowlist = readModelAllowlistFromDisk()
} else {
Log.d(TAG, "Done: loading model allowlist from internet")
saveModelAllowlistToDisk(modelAllowlistContent = data?.textContent ?: "{}")
}
if (modelAllowlist == null) {
Log.e(TAG, "Failed to load model allowlist from both internet and disk")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list"
)
}
return@withTimeoutOrNull
}
Log.d(TAG, "Allowlist: $modelAllowlist")
// Convert models in the allowlist.
TASK_LLM_CHAT.models.clear()
TASK_LLM_PROMPT_LAB.models.clear()
TASK_LLM_ASK_IMAGE.models.clear()
try {
for (allowedModel in modelAllowlist.models) {
if (allowedModel.disabled == true) {
continue
}
val model = allowedModel.toModel()
if (allowedModel.taskTypes.contains(TASK_LLM_CHAT.type.id)) {
TASK_LLM_CHAT.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_PROMPT_LAB.type.id)) {
TASK_LLM_PROMPT_LAB.models.add(model)
}
if (allowedModel.taskTypes.contains(TASK_LLM_ASK_IMAGE.type.id)) {
TASK_LLM_ASK_IMAGE.models.add(model)
}
}
// Add models from TASK_GEMMA_3_270M to LLM_PROMPT_LAB
Log.d(TAG, "Adding TASK_GEMMA_3_270M models to LLM_PROMPT_LAB")
for (gemmaModel in TASK_GEMMA_3_270M.models) {
if (!TASK_LLM_PROMPT_LAB.models.any { it.name == gemmaModel.name }) {
Log.d(TAG, "Adding model ${gemmaModel.name} to LLM_PROMPT_LAB")
TASK_LLM_PROMPT_LAB.models.add(gemmaModel)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error processing model allowlist", e)
}
// Pre-process all tasks.
try {
processTasks()
} catch (e: Exception) {
Log.e(TAG, "Error processing tasks", e)
}
// Update UI state.
val newUiState = createUiState()
_uiState.update {
newUiState.copy(
loadingModelAllowlist = false,
)
}
// Process pending downloads.
try {
processPendingDownloads()
} catch (e: Exception) {
Log.e(TAG, "Error processing pending downloads", e)
}
} ?: run {
// Timeout occurred
Log.e(TAG, "Model allowlist loading timed out")
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Model list loading timed out"
)
}
}
} catch (e: Exception) {
Log.e(TAG, "Error in loadModelAllowlist", e)
_uiState.update {
uiState.value.copy(
loadingModelAllowlist = false,
loadingModelAllowlistError = "Failed to load model list: ${e.message}"
)
}
}
}
}Par défaut, l'application suppose que la tâche actuellement sélectionnée correspond au modèle sur lequel vous avez cliqué. Une fois que vous avez injecté Gemma 3 270M dans la tâche Prompt Lab (étape 3), cette hypothèse peut être invalidée. Cette étape permet au modèle de navigation de reconnaître les modèles, de sorte que les appuis, les liens profonds et les états restaurés aboutissent toujours à l'écran approprié.
Ouvrir navigation/GalleryNavGraph.kt et mettez à jour la logique de contrôle de navigation du modèle comme suit :
Avant :
onModelClicked = { model ->
navigateToTaskScreen(
navController = navController, taskType = curPickedTask.type, model = model
)
}Après :
onModelClicked = { model ->
Log.d("GalleryNavGraph", "Model clicked: ${model.name}, current task: ${curPickedTask.type}")
val actualTask = when {
TASK_LLM_CHAT.models.any { it.name == model.name } -> TASK_LLM_CHAT
TASK_LLM_PROMPT_LAB.models.any { it.name == model.name } -> TASK_LLM_PROMPT_LAB
TASK_LLM_ASK_IMAGE.models.any { it.name == model.name } -> TASK_LLM_ASK_IMAGE
TASK_TEXT_CLASSIFICATION.models.any { it.name == model.name } -> TASK_TEXT_CLASSIFICATION
TASK_IMAGE_CLASSIFICATION.models.any { it.name == model.name } -> TASK_IMAGE_CLASSIFICATION
TASK_IMAGE_GENERATION.models.any { it.name == model.name } -> TASK_IMAGE_GENERATION
else -> curPickedTask
}
Log.d("GalleryNavGraph", "Navigating to task: ${actualTask.type} for model: ${model.name}")
navigateToTaskScreen(
navController = navController, taskType = actualTask.type, model = model
)
}Si un modèle apparaît (ou a été injecté) dans une tâche différente de celle actuellement sélectionnée, ce code garantit que l'écran correspond aux capacités du modèle.
Lorsqu'elle traite des liens profonds ou un état restauré, l'application peut tenter d'ouvrir un modèle qui n'est plus disponible. Sans une manipulation adéquate, cela entraînerait un écran vide. Pour éviter cela, nous ajoutons un contrôle de sécurité qui, si le modèle est manquant, enregistre un avertissement et redirige l'utilisateur. Voici comment nous procédons :
// Added error handling for model not found:
if (model != null) {
Log.d("GalleryNavGraph", "Model found for LlmChat: ${model.name}")
modelManagerViewModel.selectModel(model)
LlmChatScreen(/* ... */)
} else {
Log.w("GalleryNavGraph", "Model not found for LlmChat, modelName: ${it.arguments?.getString("modelName")}")
// Handle case where model is not found
androidx.compose.runtime.LaunchedEffect(Unit) {
navController.navigateUp()
}
}Ce code garantit le bon fonctionnement de l'application. Au lieu de se bloquer ou d'afficher un écran vide, il revient en toute sécurité à l'aide de l'navController. De cette manière, même si un modèle est manquant, le flux utilisateur se poursuit sans interruption et sans nuire à l'expérience globale.
L'exécution d'un modèle linguistique volumineux sur un appareil mobile diffère de son exécution sur un ordinateur de bureau. Le stockage peut être peu fiable, les budgets mémoire sont plus restreints et les échecs d'initialisation doivent être gérés pour éviter les plantages d'applications. Afin de garantir la stabilité de Gemma 3 270M (Q8, ~304 Mo) sur Android, j'ai intégré des contrôles de sécurité supplémentaires et des stratégies de basculement.
Avant de charger le modèle, l'application effectue des vérifications de cohérence sur le fichier .task. Cela garantit que le fichier modèle existe, qu'il est lisible et que sa taille est proche de la taille attendue (à ±10 % près). Cette tolérance permet de tenir compte des légères différences dues à la compression ou à l'emballage, tout en détectant les téléchargements corrompus ou partiels.
// File validation and logging
Log.d(TAG, "Checking model file: $modelPath")
Log.d(TAG, "Model file exists: ${modelFile.exists()}")
Log.d(TAG, "Model file can read: ${modelFile.canRead()}")
Log.d(TAG, "Model file size: ${modelFile.length()} bytes")
Log.d(TAG, "Model file absolute path: ${modelFile.absolutePath}")
// Size validation with tolerance (10%)
val expectedSize = model.sizeInBytes
val fileSize = modelFile.length()
val sizeDifference = kotlin.math.abs(fileSize - expectedSize)
val sizeTolerance = (expectedSize * 0.1).toLong()
if (!modelFile.exists() || !modelFile.canRead() || sizeDifference > sizeTolerance) {
onDone("Model file invalid (missing/unreadable/wrong size).")
return
}Cet extrait valide un fichier modèle avant de le charger. Il enregistre des informations de base telles que le chemin d'accès, la lisibilité et la taille, puis vérifie si le fichier existe, s'il est lisible et s'il correspond à la taille attendue. Si l'un de ces contrôles échoue, la fonction s'arrête prématurément via la méthode onDone() au lieu de tenter une inférence et de risquer un plantage.
Les modèles volumineux peuvent générer des erreurs « Out-Of-Memory » (OOM) si vous démarrez de manière intensive (sorties longues, pics d'allocation GPU). Pour atténuer ce problème, j'ai ajouté une logique permettant de choisir dynamiquement le backend le plus sûr (CPU ou GPU/NPU) en fonction de la taille du fichier et de la configuration de l'appareil, tout en réduisant le nombre maximal de tokens pour les fichiers binaires trop volumineux.
val preferredBackend = when {
fileSize > 200_000_000L -> {
Log.d(TAG, "Model is large (${fileSize / 1024 / 1024}MB), using CPU backend for safety")
LlmInference.Backend.CPU
}
accelerator == Accelerator.CPU.label -> LlmInference.Backend.CPU
accelerator == Accelerator.GPU.label -> LlmInference.Backend.GPU
else -> LlmInference.Backend.CPU
}
val baseMaxTokens = 1024 // your default; tune to taste
val maxTokens = if (fileSize > 200_000_000L) {
kotlin.math.min(baseMaxTokens, 512)
} else {
baseMaxTokens
}Cela garantit que les modèles volumineux utilisent par défaut le CPU (plus sûr mais plus lent). Le code vérifie la taille en octets du fichier .task (fileSize) et la compare à un seuil (maxTokens). Si elle dépasse 200 Mo, l'inférence est transférée vers le processeur et le budget de jetons est divisé par deux. Cela permet d'éviter les pics de mémoire (résultant d'une allocation simultanée du GPU) et les demandes de génération trop importantes.
Lors de l'initialisation de LiteRT, il est important de distinguer la création d'un runtime de la création d'une session. Si la création de la session échoue mais que vous laissez le runtime ouvert, vous risquez de perdre des ressources et de bloquer la mémoire, ce qui entraînera des échecs en cascade. Pour résoudre ce problème, j'ai encapsulé le code dans des blocs try/catch avec un nettoyage explicite.
val llmInference = try {
LlmInference.createFromOptions(context, options)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInference instance", e)
onDone("Failed to create model instance: ${e.message}")
return
}
val session = try {
LlmInferenceSession.createFromOptions(/* ... */)
} catch (e: Exception) {
Log.e(TAG, "Failed to create LlmInferenceSession", e)
try {
llmInference.close()
} catch (closeException: Exception) {
Log.e(TAG, "Failed to close LlmInference after session creation failure", closeException)
}
onDone("Failed to create model session: ${e.message}")
return
}Cette instruction try/catch garantit une restauration propre, c'est-à-dire que si la création du runtime échoue, rien d'autre ne se produit, mais si la création de la session échoue, le runtime est explicitement fermé. Cela garantit que l'objet d'llmInference alloué dans le tas est supprimé via l'.close(), libérant ainsi la mémoire et les descripteurs de fichiers. Sans cela, vous risquez que les références JNI provoquent un plantage lors du prochain chargement du modèle.
Même si un modèle se charge correctement, l'inférence peut échouer en raison de conditions de concurrence, de références nulles ou d'instances non initialisées. Pour renforcer cette étape, j'ai ajouté des vérifications null et des exceptions catch autour du bloc d'inférence complet.
try {
Log.d(TAG, "Starting inference for model '${model.name}' with input: '${input.take(50)}...'")
val instance = model.instance as LlmModelInstance? ?: run {
Log.e(TAG, "Model instance is null for '${model.name}'")
resultListener("Error: Model not initialized", true)
return
}
} catch (e: Exception) {
Log.e(TAG, "Error during inference for model '${model.name}'", e)
resultListener("Error during inference: ${e.message}", true)
}Le code ci-dessus garantit que l'inférence ne se poursuit qu'avec une instance de modèle valide et détecte clairement les erreurs d'exécution. La conversion de type as LlmModelInstance? vérifie si l'instance du modèle est correctement typée et le mécanisme de repli de type Elvis interrompt l'exécution si la valeur est nulle. En encapsulant le bloc dans try/catch, vous vous assurez que toutes les exceptions sont interceptées et renvoyées sous forme de messages d'erreur visibles par l'utilisateur.
Une fois que vous aurez effectué toutes les modifications nécessaires, nous lancerons l'application. Pour exécuter votre application sur votre appareil Android local, veuillez connecter votre appareil Android à Android Studio à l'aide du débogage sans fil en suivant les étapes ci-dessous.
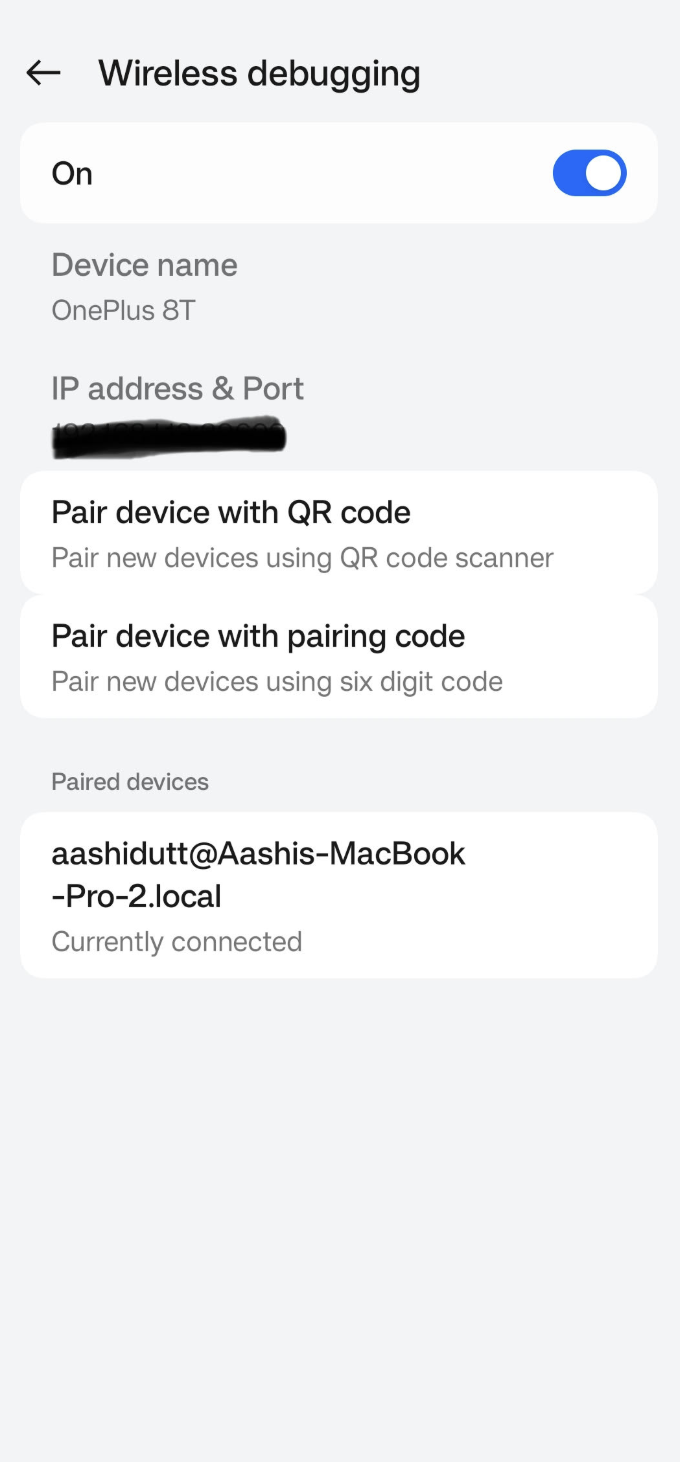
Veuillez accéder à l'application Paramètres sur votre appareil Android et activez les options pour les développeurs. Veuillez appuy. Ensuite, activez l'option «Débogage sans fil » dans les paramètres de votre appareil Android ( ). Vous devriez voir un écran avec deux options de couplage.
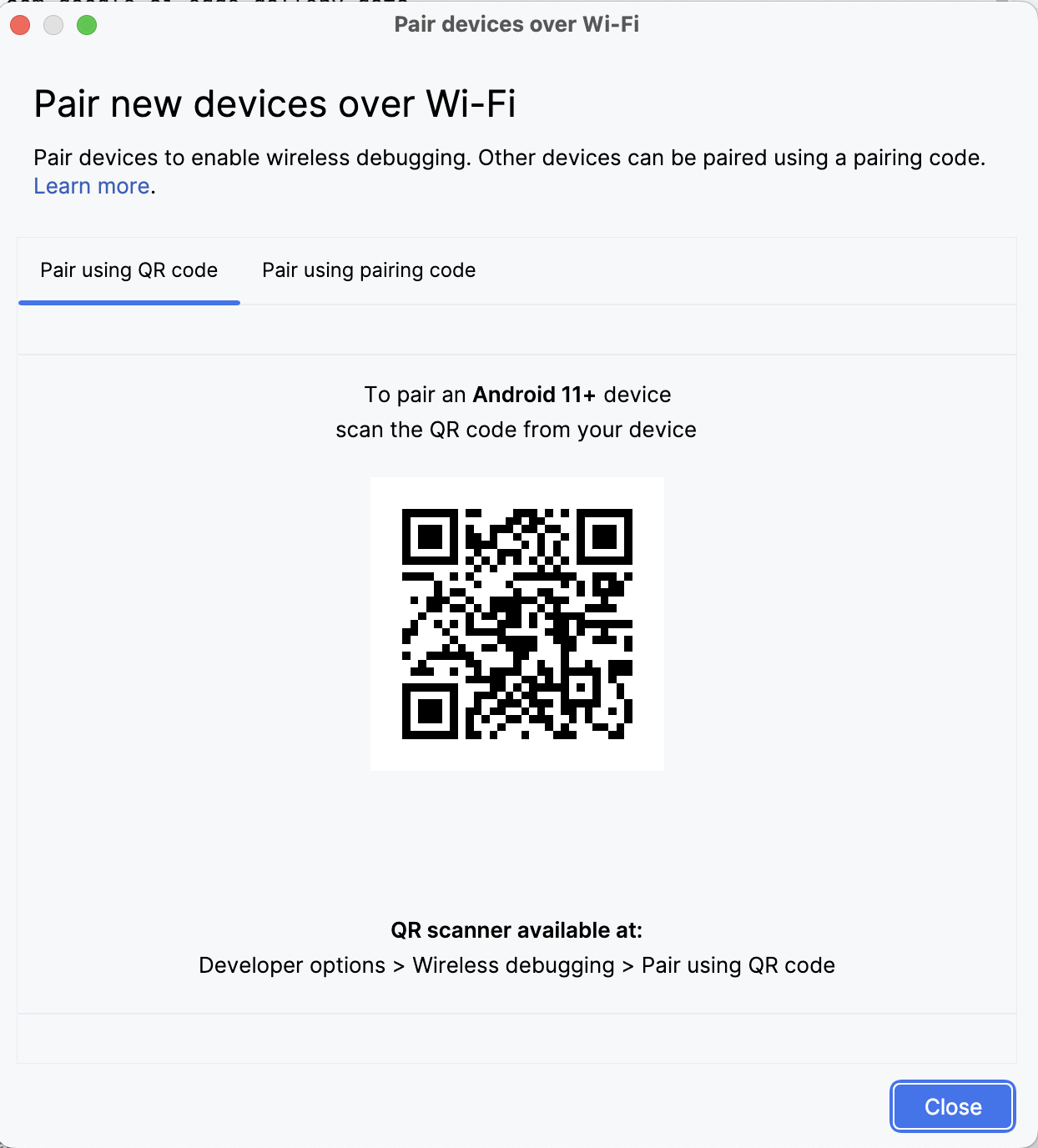
Dans Android Studio, veuillez ouvrir le Gestionnaire de périphériques. Gestionnaire de périphériques (l'icône ressemble à un téléphone avec le logo Android) et cliquez sur Coupler à l'aide d'un code QR.
Veuillez scanner le code QR à l'aide de votre appareil et terminer la configuration du jumelage. Une fois votre appareil connecté, son nom apparaîtra sous Gestionnaire de périphériques. Veuillez vous assurer que votre système et votre appareil Android sont tous deux connectés au même réseau Wi-Fi.
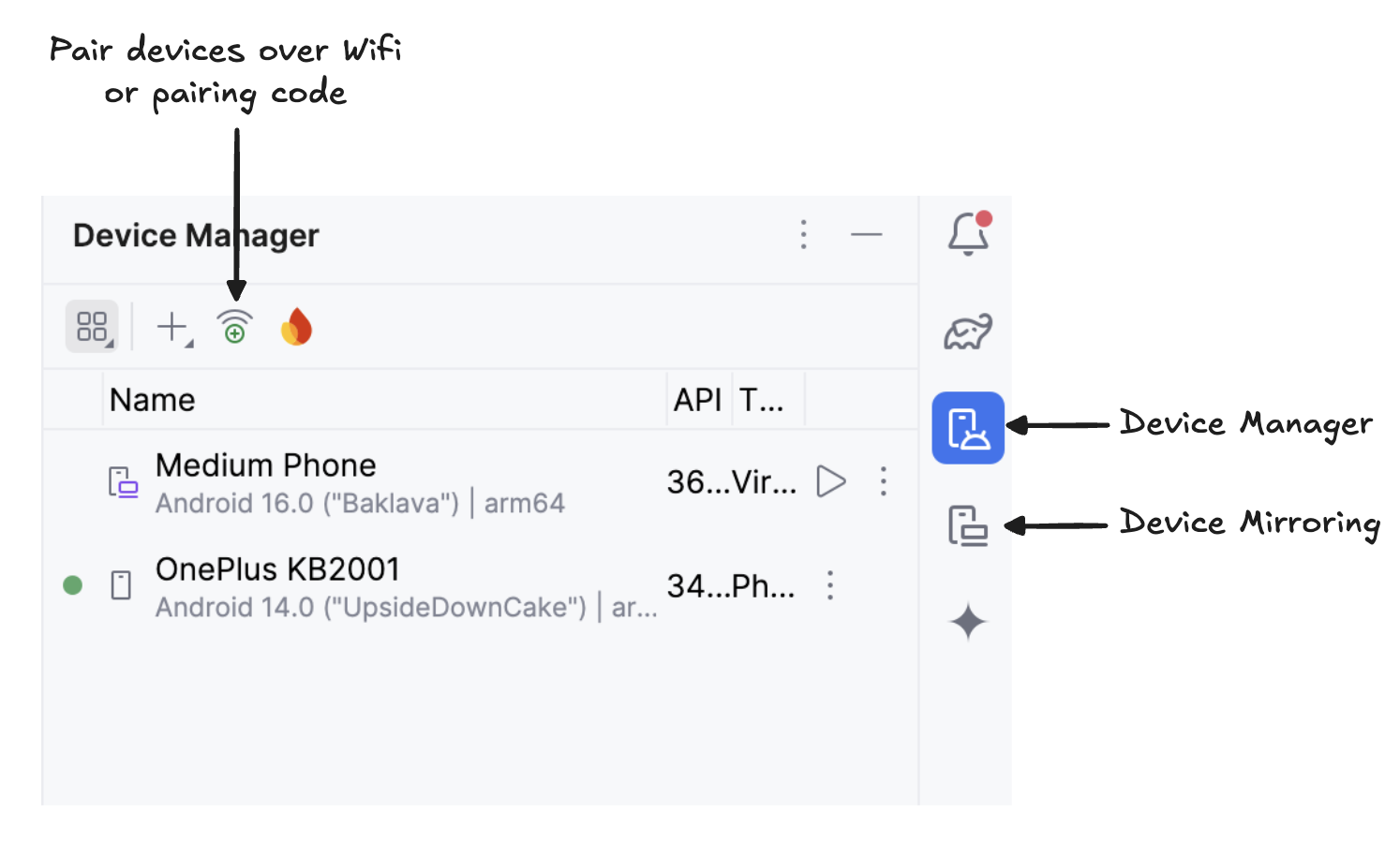
Commencez à dupliquer votre appareil Android en cliquant sur l'icône de l' «Duplication d'appareil » (qui représente un écran d'ordinateur et un écran de téléphone). Une fois que l'écran de votre appareil est dupliqué, veuillez cliquer sur l'icône verte «Exécuter l' » pour déployer l'application sur votre appareil.
L'application se lancera et une fenêtre de navigateur s'ouvrira, vous invitant à vous connecter à Hugging Face à l'aide d'un jeton write afin de télécharger le fichier du modèle en toute sécurité.
Une fois connecté à HuggingFace, veuillez cliquer sur «Démarrer le téléchargement » sur le modèle de votre choix, et le téléchargement commencera. Pour cet exemple, j'utilise le modèle par défaut gemma3-270m-it-q8. Vous pouvez maintenant commencer à expérimenter ce modèle.
Pour les besoins de ce tutoriel, j'ai réalisé quatre expériences :
Dans cette expérience, j'ai demandé au modèle d'écrire une histoire libre, et voici les résultats :
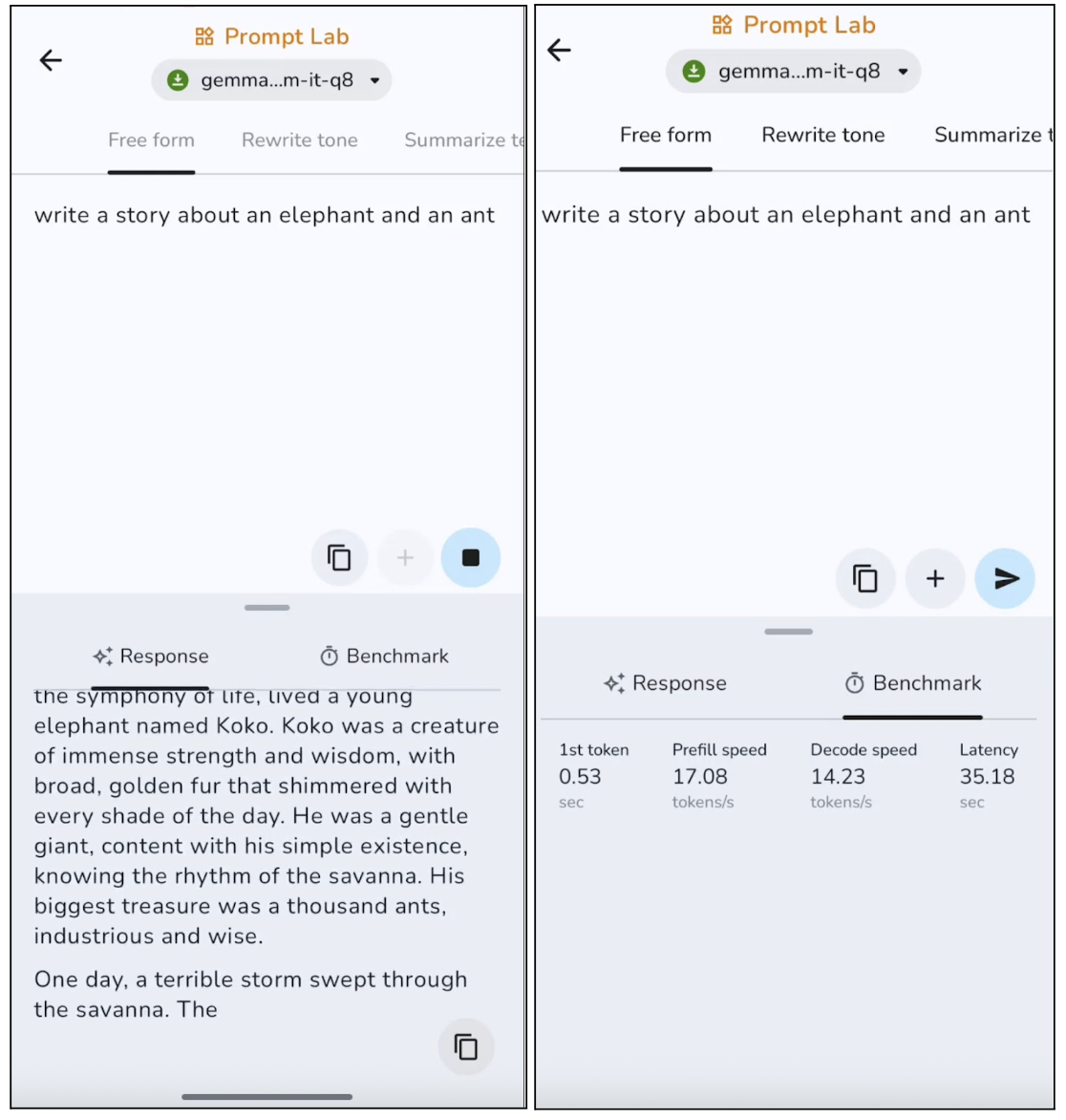
Le modèle produit un texte pertinent, avec une structure claire, bien qu'il ait tendance à privilégier la sécurité et à rester quelque peu générique. Lors de productions plus longues, le modèle répète généralement certaines phrases. Cela le rend particulièrement adapté aux publications courtes, aux descriptions et aux résumés. Cependant, la génération du premier jeton est assez rapide, environ 0,53 seconde, et la vitesse de décodage est également bonne pour l'inférence sur appareil.
Ensuite, j'ai utilisé un paragraphe pré-rédigé et j'ai demandé à Gemma 3 270M de le réécrire dans un ton amical.

La capacité à suivre des instructions est excellente, avec des changements clairs entre les tons formels, informels et amicaux, tout en conservant le sens. La vitesse est quasi instantanée pour les passages courts, ce qui le rend particulièrement adapté à la révision de courriels ou à la conversion de texte entre différents styles.
J'ai également résumé le texte pré-rédigé sous forme de liste à puces. Vous pouvez tester différents formats tels que les résumés, les points clés, les conclusions, etc.
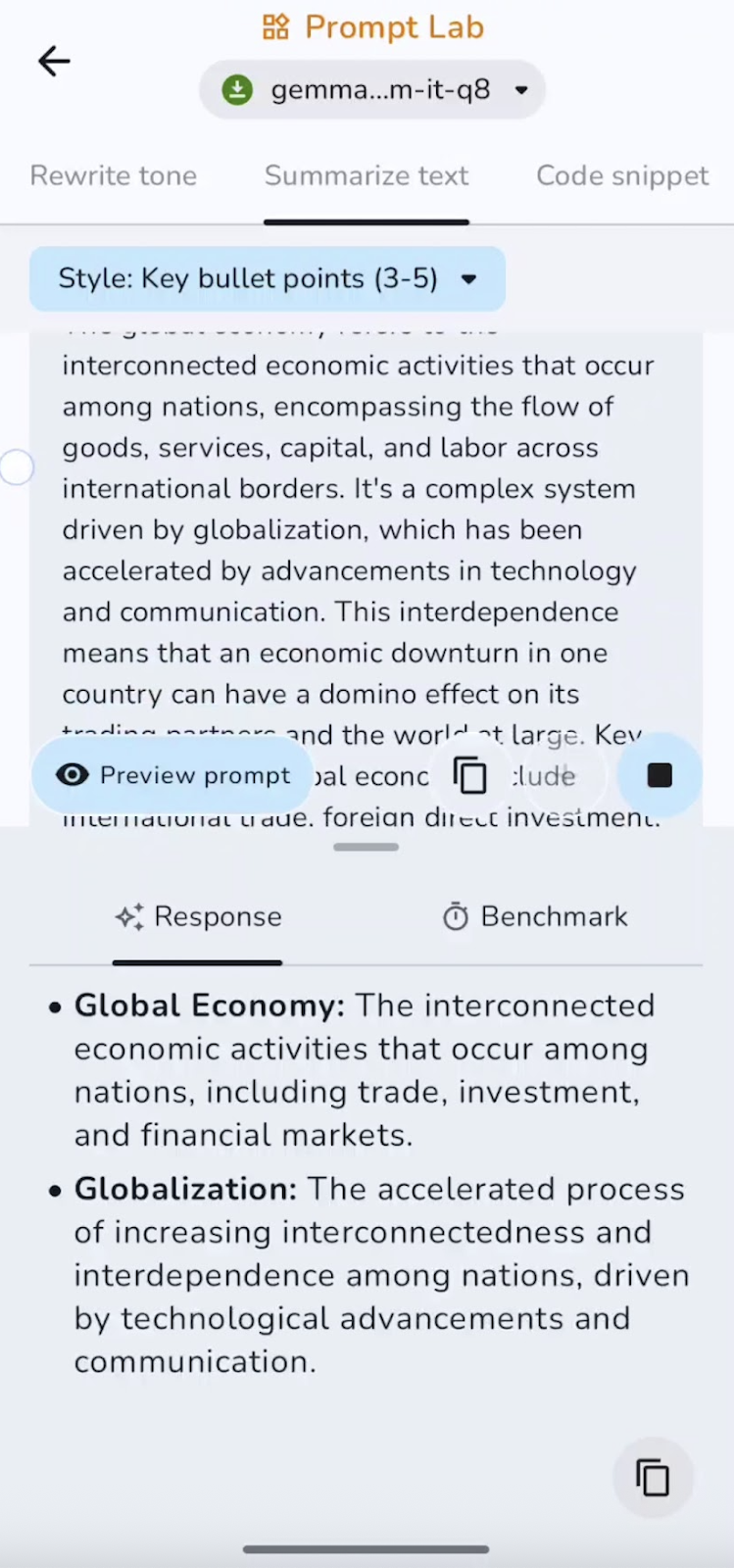
Dans cette expérience, le modèle résume et capture les points essentiels. La vitesse est excellente pour les documents courts et de longueur moyenne. Certains cas d'utilisation peuvent être des résumés exécutifs, des listes à puces ou des résumés TL;DR.
Enfin, j'ai demandé au modèle d'écrire un petit extrait de code. Voici ce que j'ai découvert :
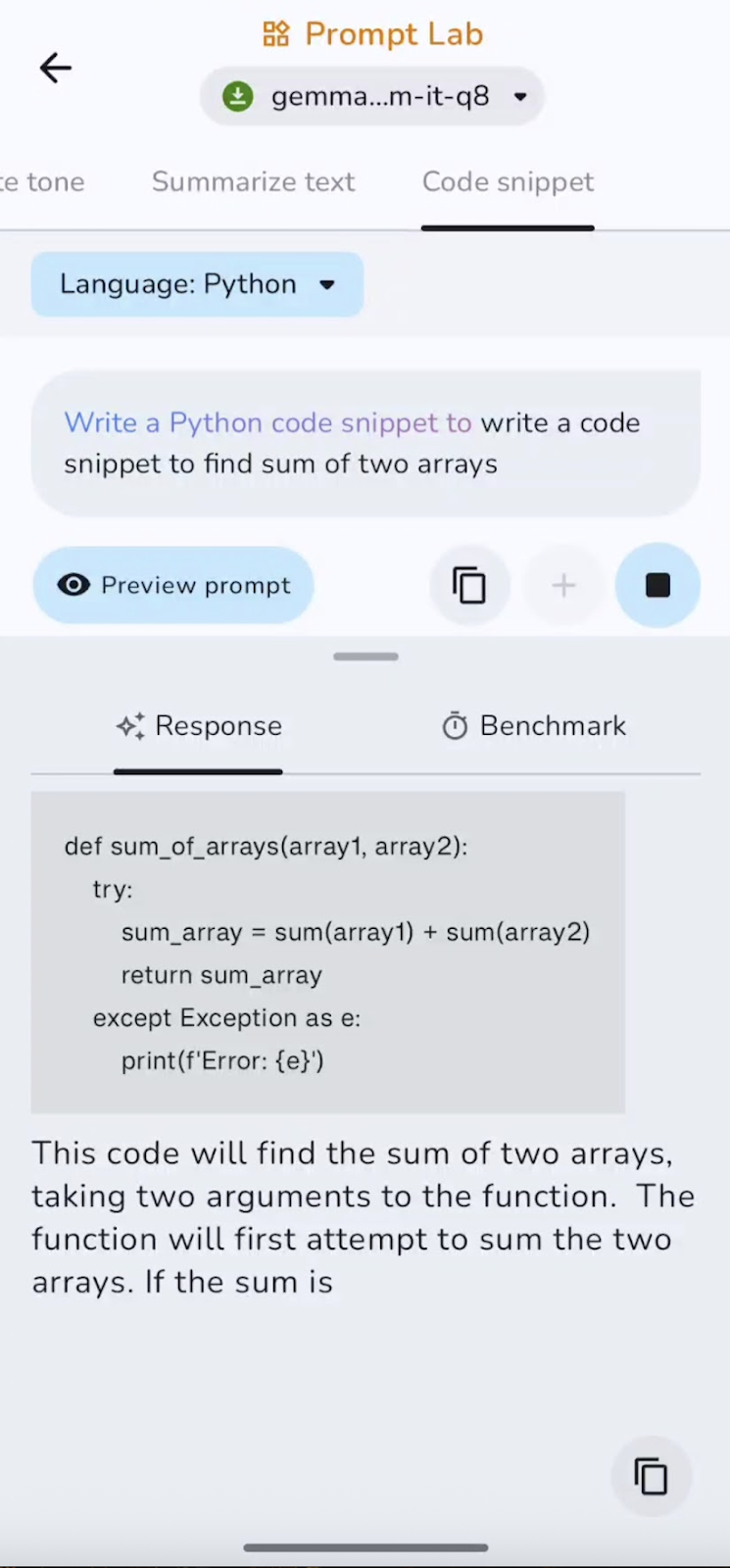
Le modèle est efficace pour générer des éléments standard et de petits utilitaires, mais il peut omettre des importations, des cas particuliers ou des logiques complexes sans aide. Les extraits courts sont générés rapidement, tandis que les complétions plus longues sont légèrement plus lentes à mesure que le contexte s'étoffe. Il est particulièrement adapté aux fonctions d'aide et aux configurations.
J'ai configuré ce référentiel GitHub si vous souhaitez explorer l'intégralité du code du projet.
Dans ce guide, nous avons présenté étape par étape l'exécution du modèle Gemma 3 270M, depuis le téléchargement et le câblage du modèle dans une application Android personnalisée jusqu'à la gestion de la navigation, de la fiabilité et de la sécurité pendant le temps d'inférence.
Gemma 3 offre une inférence rapide avec une faible charge informatique, consomme très peu d'énergie, prend en charge la quantification INT4 avec un impact minimal sur les performances et fonctionne entièrement sur l'appareil afin de préserver la confidentialité.
Apprenez l'IA grâce à ces cours !
Cours
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
Tutoriel
Matt Crabtree