Kurs
Einführung in PySpark
4 Std.
157.5K
PySpark ist eine Schnittstelle für Apache Spark in Python. Mit PySpark kannst du Python- und SQL-ähnliche Befehle schreiben, um Daten in einer verteilten Verarbeitungsumgebung zu manipulieren und zu analysieren. Um die Grundlagen der Sprache zu lernen, kannst du den Kurs Einführung in PySpark von Datacamp besuchen. Dies ist ein Einsteigerprogramm, das dich durch die Bearbeitung von Daten, den Aufbau von Pipelines für maschinelles Lernen und das Tuning von Modellen mit PySpark führt.
Die meisten Data Scientists und Analysten sind mit Python vertraut und nutzen es, um Workflows für maschinelles Lernen zu implementieren. PySpark ermöglicht es ihnen, mit einer vertrauten Sprache an großen, verteilten Datensätzen zu arbeiten.
Apache Spark kann auch mit anderen Data-Science-Programmiersprachen wie R verwendet werden. Wenn du dich dafür interessierst, ist der Kurs Einführung in Spark mit sparklyr in R ein guter Anfang.
Unternehmen, die Terabytes an Daten sammeln, haben ein Big-Data-Framework wie Apache Spark im Einsatz. Um mit diesen großen Datensätzen zu arbeiten, reichen Kenntnisse in Python und R allein nicht aus.
Du musst ein Framework erlernen, das es dir ermöglicht, Datensätze auf einem verteilten Verarbeitungssystem zu bearbeiten, da die meisten datengesteuerten Unternehmen dies von dir verlangen werden. PySpark ist ein großartiger Ort für den Einstieg, denn die Syntax ist einfach und kann leicht erlernt werden, wenn du bereits mit Python vertraut bist.
Der Grund, warum sich Unternehmen für ein Framework wie PySpark entscheiden, ist, dass es große Datenmengen schnell verarbeiten kann. Es ist schneller als Bibliotheken wie Pandas und Dask und kann größere Datenmengen verarbeiten als diese Frameworks. Wenn du zum Beispiel mehr als ein Petabyte an Daten zu verarbeiten hättest, würden Pandas und Dask versagen, aber PySpark würde es problemlos schaffen.
Es ist zwar auch möglich, Python-Code auf einem verteilten System wie Hadoop zu schreiben, aber viele Unternehmen entscheiden sich stattdessen für Spark und nutzen die PySpark-API, weil sie schneller ist und Echtzeitdaten verarbeiten kann. Mit PySpark kannst du Code schreiben, um Daten aus einer Quelle zu sammeln, die ständig aktualisiert wird, während die Daten mit Hadoop nur im Batch-Modus verarbeitet werden können.
Apache Flink ist ein verteiltes Verarbeitungssystem, das eine Python-API namens PyFlink hat und in Bezug auf die Leistung sogar schneller ist als Spark. Apache Spark gibt es jedoch schon länger und wird von der Community besser unterstützt, was bedeutet, dass es zuverlässiger ist.
Außerdem bietet PySpark Fehlertoleranz, d.h. es ist in der Lage, Verluste nach einem Ausfall wiederherzustellen. Das Framework verfügt auch über In-Memory-Berechnungen und wird im Arbeitsspeicher (RAM) gespeichert. Es kann auf einem Rechner laufen, der keine Festplatte oder SSD installiert hat.
Vorraussetzungen:
Bevor du Apache Spark und PySpark installierst, musst du die folgende Software auf deinem Gerät eingerichtet haben:
Wenn du Python noch nicht installiert hast, befolge unsere Anleitung zur Einrichtung von Python für Entwickler, bevor du mit dem nächsten Schritt fortfährst.
Als Nächstes befolgst du diese Anleitung, um Java auf deinem Computer zu installieren, wenn du Windows verwendest. Hier ist eine Installationsanleitung für MacOs, und hier ist eine für Linux.
Ein Jupyter Notebook ist eine Webanwendung, mit der du Code schreiben und Gleichungen, Visualisierungen und Text anzeigen kannst. Er ist einer der am häufigsten von Datenwissenschaftlern verwendeten Programmiereditoren. Wir werden ein Jupyter Notebook verwenden, um den gesamten PySpark-Code in diesem Tutorial zu schreiben.
Du kannst unserer Anleitung folgen , um Jupyter auf deinem lokalen Gerät zum Laufen zu bringen, oder eine cloudbasierte Online-IDE wie DataLab von DataCamp verwenden, auf der PySpark bereits vorinstalliert ist.
Wir werden den E-Commerce-Datensatz von Datacamp für alle Analysen in diesem Lernprogramm verwenden, also stelle sicher, dass du ihn heruntergeladen hast. Wir haben die Datei in "datacamp_ecommerce.csv" umbenannt und im übergeordneten Verzeichnis gespeichert, und du kannst dasselbe tun, damit es einfacher ist, mitzucoden.
Nachdem du nun alle Voraussetzungen geschaffen hast, kannst du mit der Installation von Apache Spark und PySpark fortfahren. Du kannst diesen Schritt überspringen, wenn du DataLab verwendest.
Um Apache Spark einzurichten, rufedie Download-Seite auf und lade die dort angezeigte .tgz-Datei herunter:
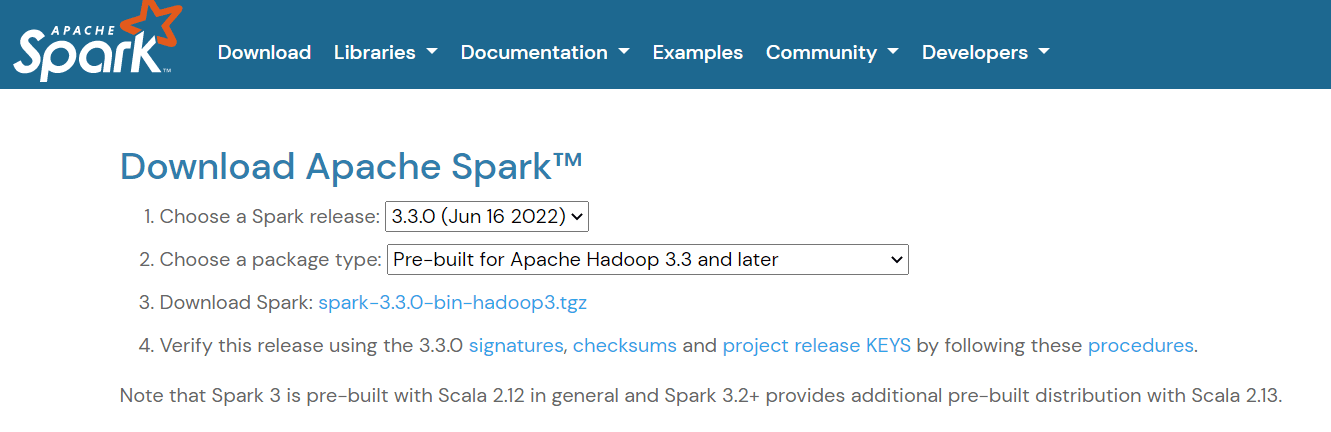
Wenn du Windows verwendest, erstelle dann in deinem C-Verzeichnis einen Ordner namens "spark". Wenn du Linux oder Mac verwendest, kannst du sie in einen neuen Ordner in deinem Home-Verzeichnis einfügen.
Als Nächstes entpackst du die Datei, die du gerade heruntergeladen hast, und fügst ihren Inhalt in den Ordner "spark" ein. So sollte der Ordnerpfad aussehen:

Jetzt musst du deine Umgebungsvariablen setzen. Es gibt zwei Möglichkeiten, wie du das tun kannst:
Methode 1: Ändern von Umgebungsvariablen mit Powershell
Wenn du einen Windows-Rechner verwendest, kannst du deine Umgebungsvariablen zunächst mit der Powershell ändern:
Schritt 1: Klicke auf Start -> Windows Powershell -> Als Administrator ausführen
Schritt 2: Gib die folgende Zeile in die Windows Powershell ein, um SPARK_HOME zu setzen:
setx SPARK_HOME "C:\spark\spark-3.3.0-bin-hadoop3" # change this to your pathSchritt 3: Als Nächstes legst du dein Spark-Bin-Verzeichnis als Pfadvariable fest:
setx PATH "C:\spark\spark-3.3.0-bin-hadoop3\bin"Methode 2: Manuelles Ändern von Umgebungsvariablen
Schritt 1: Navigiere zu Start -> System -> Einstellungen -> Erweiterte Einstellungen
Schritt 2: Klick auf Umgebungsvariablen
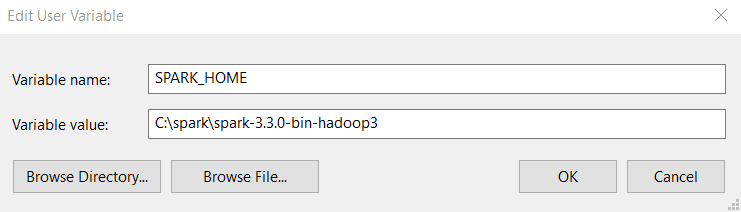
Schritt 3: Klicke auf der Registerkarte Umgebungsvariablen auf Neu.
Schritt 4: Gib die folgenden Werte in Variablenname und Variablenwert ein. Beachte, dass die Version, die du installierst, sich von der unten gezeigten unterscheiden kann, also kopiere den Pfad zu deinem Spark-Verzeichnis und füge ihn ein.
Schritt 5: Klicke auf der Registerkarte "Umgebungsvariablen" auf "Pfad" und wähle "Bearbeiten".
Schritt 6: Klicke auf Neu und füge den Pfad zu deinem Spark-Bin-Verzeichnis ein. Hier ist ein Beispiel dafür, wie das bin-Verzeichnis aussieht:
C:\spark\spark-3.3.0-bin-hadoop3\binHier findest du eine Anleitung zum Setzen deiner Umgebungsvariablen, wenn du ein Linux-Gerät verwendest, und hier eine für MacOS.
Nachdem du Apache Spark und alle anderen notwendigen Voraussetzungen erfolgreich installiert hast, öffne eine Python-Datei in deinem Jupyter Notebook und führe die folgenden Codezeilen in der ersten Zelle aus:
!pip install pysparkAlternativ kannst du auch dieser vollständigen PySpark-Installationsanleitung folgen, um die Software auf deinem Gerät zu installieren.
Jetzt, wo du PySpark zum Laufen gebracht hast, zeigen wir dir, wie du ein vollständiges Kundensegmentierungsprojekt mit der Bibliothek durchführst.
Die Kundensegmentierung ist eine Marketingtechnik, die Unternehmen einsetzen, um Nutzer/innen zu identifizieren und zu gruppieren, die ähnliche Merkmale aufweisen. Wenn du zum Beispiel nur im Sommer zu Starbucks gehst, um kalte Getränke zu kaufen, kannst du als "saisonaler Kunde" segmentiert und mit speziellen Angeboten für die Sommersaison gelockt werden.
Datenwissenschaftler/innen entwickeln in der Regel unüberwachte Algorithmen für maschinelles Lernen wie das K-Means-Clustering oder das hierarchische Clustering, um eine Kundensegmentierung durchzuführen. Diese Modelle sind hervorragend geeignet, um ähnliche Muster zwischen Nutzergruppen zu erkennen, die dem menschlichen Auge oft verborgen bleiben.
In diesem Lernprogramm werden wir das K-Means-Clustering verwenden, um eine Kundensegmentierung auf dem E-Commerce-Datensatz durchzuführen, den wir zuvor heruntergeladen haben.
Am Ende dieses Lernprogramms wirst du mit den folgenden Konzepten vertraut sein:
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenEine SparkSession ist der Einstiegspunkt in alle Funktionen von Spark und wird benötigt, wenn du einen Datenrahmen in PySpark erstellen willst. Führe die folgenden Codezeilen aus, um eine SparkSession zu initialisieren:
spark = SparkSession.builder.appName("Datacamp Pyspark Tutorial").config("spark.memory.offHeap.enabled","true").config("spark.memory.offHeap.size","10g").getOrCreate()Mit den obigen Codes haben wir eine Spark-Sitzung erstellt und einen Namen für die Anwendung festgelegt. Dann wurden die Daten im Off-Heap-Speicher zwischengespeichert, um zu vermeiden, dass sie direkt auf der Festplatte gespeichert werden, und die Größe des Speichers wurde manuell festgelegt.
Wir können jetzt den Datensatz lesen, den wir gerade heruntergeladen haben:
df = spark.read.csv('datacamp_ecommerce.csv',header=True,escape="\"")Beachte, dass wir ein Escape-Zeichen definiert haben, um Kommas in der .csv-Datei beim Parsen zu vermeiden.
Werfen wir mit der Funktion show() einen Blick auf den Kopf des Datenrahmens:
df.show(5,0)Der Datenrahmen besteht aus 8 Variablen:
Nachdem wir nun die Variablen in diesem Datensatz gesehen haben, wollen wir eine explorative Datenanalyse durchführen, um diese Datenpunkte besser zu verstehen:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95 Land kommen die meisten Einkäufe?
Land kommen die meisten Einkäufe?Um das Land zu finden, in dem die meisten Einkäufe getätigt werden, müssen wir die groupBy()-Klausel in PySpark verwenden:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()Die folgende Tabelle wird angezeigt, nachdem du die obigen Codes ausgeführt hast:

Fast alle Käufe auf der Plattform wurden aus dem Vereinigten Königreich getätigt, und nur eine Handvoll aus Ländern wie Deutschland, Australien und Frankreich.
Beachte, dass die Daten in der obigen Tabelle nicht in der Reihenfolge der Käufe dargestellt sind. Um diese Tabelle zu sortieren, können wir die orderBy()-Klausel einfügen:
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()Die angezeigte Ausgabe ist jetzt in absteigender Reihenfolge sortiert:

Um herauszufinden, wann der letzte Kauf auf der Plattform getätigt wurde, müssen wir die Spalte "InvoiceDate" in ein Zeitstempelformat umwandeln und die Funktion max() in Pyspark verwenden:
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
df = df.withColumn('date',to_timestamp("InvoiceDate", 'yy/MM/dd HH:mm'))
df.select(max("date")).show()Nachdem du den obigen Code ausgeführt hast, solltest du die folgende Tabelle sehen:
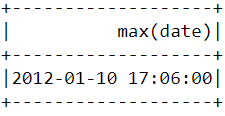
Ähnlich wie oben können wir mit der Funktion min() das früheste Kaufdatum und die früheste Kaufzeit ermitteln:
df.select(min("date")).show()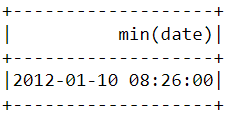
Beachte, dass der jüngste und der früheste Kauf am selben Tag getätigt wurden, nur wenige Stunden auseinander. Das bedeutet, dass der Datensatz, den wir heruntergeladen haben, nur Informationen über Einkäufe enthält, die an einem einzigen Tag getätigt wurden.
Jetzt, wo wir den Datensatz analysiert haben und die einzelnen Datenpunkte besser verstehen, müssen wir die Daten für den maschinellen Lernalgorithmus vorbereiten.
Werfen wir noch einmal einen Blick auf den Kopf des Datenrahmens, um zu verstehen, wie die Vorverarbeitung durchgeführt wird:
df.show(5,0)
Aus dem obigen Datensatz müssen wir mehrere Kundensegmente erstellen, die auf dem Kaufverhalten der einzelnen Nutzer/innen basieren.
Die Variablen in diesem Datensatz haben ein Format, das nicht ohne Weiteres in das Kundensegmentierungsmodell übernommen werden kann. Diese Merkmale allein sagen nicht viel über das Kaufverhalten der Kunden aus.
Deshalb werden wir die vorhandenen Variablen nutzen, um drei neue informative Merkmale abzuleiten - Häufigkeit, Frequenz und Geldwert (RFM).
RFM wird im Marketing häufig verwendet, um den Wert eines Kunden auf der Grundlage seiner Leistungen zu bewerten:
Wir werden nun den Datenrahmen vorverarbeiten, um die oben genannten Variablen zu erstellen.
Berechnen wir zunächst den Wert der Aktualität - das letzte Datum und die letzte Uhrzeit, zu der ein Kauf auf der Plattform getätigt wurde. Dies kann in zwei Schritten erreicht werden:
Wir subtrahieren jedes Datum im Datenrahmen vom frühesten Datum. So erfahren wir, wie lange ein Kunde in dem Datenrahmen zurückliegt. Ein Wert von 0 bedeutet die geringste Aktualität, da sie der Person zugeordnet wird, die am frühesten Datum beim Kauf gesehen wurde.
df = df.withColumn("from_date", lit("12/1/10 08:26"))
df = df.withColumn('from_date',to_timestamp("from_date", 'yy/MM/dd HH:mm'))
df2 = df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long") - col('from_date').cast("long"))Ein Kunde kann mehrere Einkäufe zu verschiedenen Zeiten tätigen. Wir müssen nur das letzte Mal auswählen, als sie beim Kauf eines Produkts gesehen wurden, da dies ein Hinweis darauf ist, wann der letzte Kauf getätigt wurde:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Schauen wir uns den Kopf des neuen Datenrahmens an. Sie hat jetzt eine Variable namens "recency":
df2.show(5,0)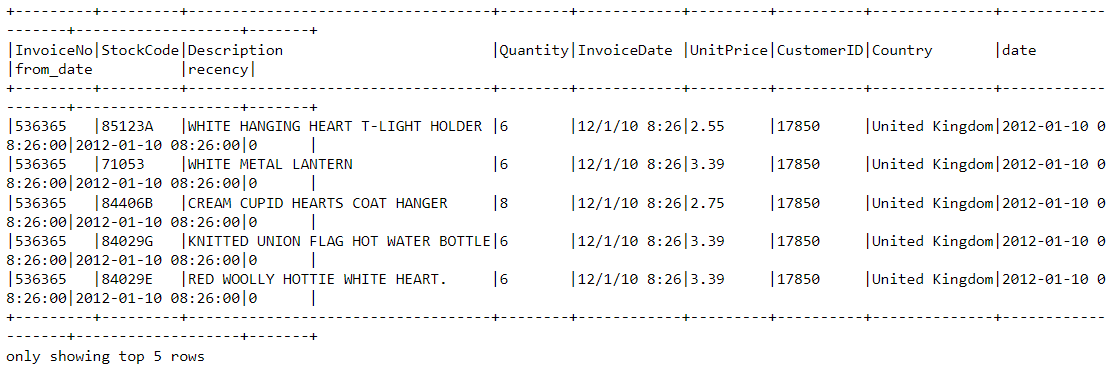
Eine einfachere Möglichkeit, alle Variablen in einem PySpark-Datenframe anzuzeigen, ist die Funktion printSchema(). Dies ist das Äquivalent zur info()-Funktion in Pandas:
df2.printSchema()Die gerenderte Ausgabe sollte wie folgt aussehen:

Berechnen wir nun den Wert der Häufigkeit - wie oft ein Kunde etwas auf der Plattform gekauft hat. Dazu müssen wir nur nach jeder Kunden-ID gruppieren und die Anzahl der gekauften Artikel zählen:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Schau dir den Kopf des neuen Datenrahmens an, den wir gerade erstellt haben:
df_freq.show(5,0)
An jeden Kunden im Datenrahmen wird ein Häufigkeitswert angehängt. Dieser neue Datenrahmen hat nur zwei Spalten, und wir müssen ihn mit dem vorherigen verbinden:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Lass uns das Schema dieses Datenrahmens ausdrucken:
df3.printSchema()
Zum Schluss berechnen wir den Geldwert - den Gesamtbetrag, den jeder Kunde im Datenrahmen ausgegeben hat. Um dies zu erreichen, gibt es zwei Schritte:
Jede Kunden-ID enthält die Variablen "Menge" und "Einzelpreis" für einen einzelnen Kauf:

Um den Gesamtbetrag zu erhalten, den jeder Kunde bei einem Kauf ausgibt, müssen wir "Menge" mit "Einzelpreis" multiplizieren:
m_val = df3.withColumn('TotalAmount',col("Quantity") * col("UnitPrice"))Um den Gesamtbetrag zu ermitteln, den jeder Kunde insgesamt ausgegeben hat, müssen wir nur nach der Spalte CustomerID gruppieren und die Gesamtsumme der Ausgaben addieren:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Führe diesen Datenrahmen mit allen anderen Variablen zusammen:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Nachdem wir nun alle notwendigen Variablen für das Modell erstellt haben, führen wir die folgenden Codezeilen aus, um nur die benötigten Spalten auszuwählen und doppelte Zeilen aus dem Datenrahmen zu entfernen:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Schau dir den Kopf des endgültigen Datenrahmens an, um sicherzustellen, dass die Vorverarbeitung korrekt durchgeführt wurde:

Bevor wir das Kundensegmentierungsmodell erstellen, sollten wir den Datenrahmen standardisieren, um sicherzustellen, dass alle Variablen auf der gleichen Skala liegen:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
assemble=VectorAssembler(inputCols=[
'recency','frequency','monetary_value'
], outputCol='features')
assembled_data=assemble.transform(finaldf)
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
data_scale_output=data_scale.transform(assembled_data)Führe die folgenden Codezeilen aus, um zu sehen, wie der standardisierte Merkmalsvektor aussieht:
data_scale_output.select('standardized').show(2,truncate=False)
Dies sind die skalierten Merkmale, die in den Clustering-Algorithmus eingespeist werden.
Wenn du mehr über die Datenaufbereitung mit PySpark erfahren möchtest, besuche diesen Feature Engineering Kurs auf Datacamp.
Nachdem wir nun alle Daten analysiert und vorbereitet haben, können wir das K-Means-Clustermodell erstellen.
Der Algorithmus wird mit der PySpark-API für maschinelles Lernen erstellt.
Wenn wir ein K-Means-Clustermodell erstellen, müssen wir zunächst die Anzahl der Cluster oder Gruppen bestimmen, die der Algorithmus liefern soll. Wenn wir uns z. B. für drei Cluster entscheiden, haben wir drei Kundensegmente.
Die beliebteste Methode, um zu entscheiden, wie viele Cluster in K-Means verwendet werden sollen, ist die "Ellbogen-Methode".
Dazu lässt du einfach den K-Means-Algorithmus für eine Vielzahl von Clustern laufen und visualisierst die Modellergebnisse für jedes Cluster. Das Diagramm wird einen Wendepunkt haben, der wie ein Ellbogen aussieht, und wir wählen einfach die Anzahl der Cluster an diesem Punkt.
Lies das Datacamp K-Means Clustering Tutorial, um mehr darüber zu erfahren, wie der Algorithmus funktioniert.
Führen wir die folgenden Codezeilen aus, um einen K-Means-Clusteralgorithmus von 2 bis 10 Clustern zu erstellen:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized',metricName='silhouette', distanceMeasure='squaredEuclidean')
for i in range(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
cost[i] = KMeans_fit.summary.trainingCostMit den oben genannten Codes haben wir erfolgreich ein K-Means-Clustermodell mit 2 bis 10 Clustern erstellt und evaluiert. Die Ergebnisse wurden in ein Array eingefügt und können nun in einem Liniendiagramm dargestellt werden:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Mit den obigen Codes wird die folgende Tabelle angezeigt:
Anhand der obigen Grafik können wir sehen, dass es einen Wendepunkt gibt, der wie ein Ellbogen bei vier aussieht. Aus diesem Grund werden wir den K-Means-Algorithmus mit vier Clustern aufbauen:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Verwenden wir das von uns erstellte Modell, um jedem Kunden im Datensatz Cluster zuzuordnen:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Beachte, dass es in diesem Datenrahmen eine Spalte "Vorhersage" gibt, die uns sagt, zu welchem Cluster jede Kunden-ID gehört:

Der letzte Schritt in diesem Tutorial ist die Analyse der Kundensegmente, die wir gerade erstellt haben.
Führe die folgenden Codezeilen aus, um die Häufigkeit, die Häufigkeit und den Geldwert der einzelnen Kunden-IDs im Datenrahmen zu visualisieren:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()Mit den obigen Codes werden die folgenden Diagramme erstellt:
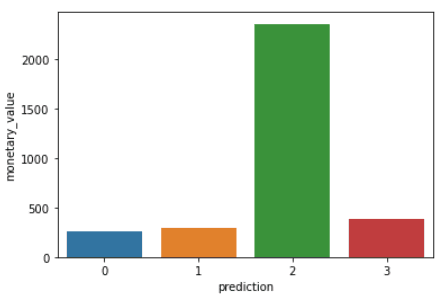
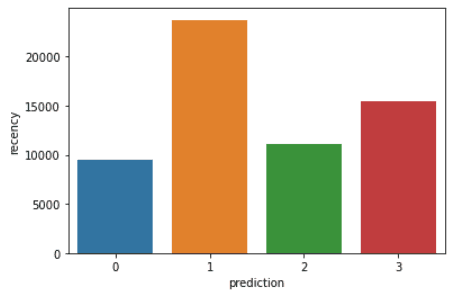
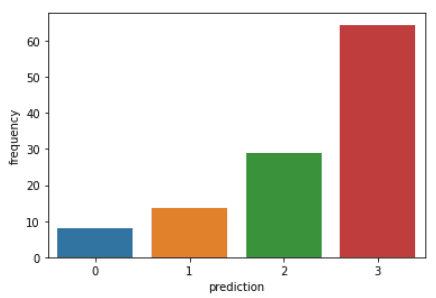
Hier ist ein Überblick über die Merkmale, die die Kunden in den einzelnen Clustern aufweisen:
Um über die in diesem Kurs behandelten Konzepte zur Vorhersagemodellierung hinauszugehen, kannst du den Kurs Maschinelles Lernen mit PySpark auf Datacamp belegen.
Wenn du es geschafft hast, diesem PySpark-Tutorial komplett zu folgen, dann gratuliere ich dir! Du hast PySpark nun erfolgreich auf deinem lokalen Gerät installiert, einen E-Commerce-Datensatz analysiert und mit dem Framework einen Algorithmus für maschinelles Lernen erstellt.
Ein Vorbehalt bei der obigen Analyse ist, dass sie mit 2.500 Zeilen E-Commerce-Daten durchgeführt wurde, die an einem einzigen Tag gesammelt wurden. Das Ergebnis dieser Analyse könnte sich verfestigen, wenn wir eine größere Datenmenge zur Verfügung hätten, denn Techniken wie die RFM-Modellierung werden normalerweise auf monatelange historische Daten angewendet.
Du kannst die in diesem Artikel gelernten Prinzipien jedoch auf eine Vielzahl größerer Datensätze im Bereich des unüberwachten maschinellen Lernens anwenden.
In diesem Spickzettel von Datacamp erfährst du mehr über die Syntax von PySpark und seine Module.
Wenn du über die in diesem Tutorial behandelten Konzepte hinausgehen und die Grundlagen der Programmierung mit PySpark erlernen möchtest, kannst du den Big Data with PySpark Learning Track auf Datacamp besuchen. Dieser Track enthält eine Reihe von Kursen, in denen du lernst, wie du mit PySpark die folgenden Dinge tun kannst:
Wie du in diesem Lernprogramm gesehen hast, ist die Beherrschung von PySpark und verteilter Datenverarbeitung unerlässlich, um große Datenmengen zu verarbeiten, die in der modernen Welt immer häufiger vorkommen. Für Unternehmen, die Terabytes oder sogar Petabytes an Daten verwalten, kann ein Team, das PySpark beherrscht, ihre Fähigkeit, verwertbare Erkenntnisse zu gewinnen und einen Wettbewerbsvorteil zu erzielen, erheblich verbessern.
Es kann jedoch eine Herausforderung sein, mit den neuesten Technologien und Best Practices Schritt zu halten, vor allem für Teams, die in einem schnelllebigen Umfeld arbeiten. Hier kann das DataCamp for Business einen Unterschied machen. Das DataCamp for Business versorgt dein Team mit den Werkzeugen und Schulungen, die es braucht, um auf dem neuesten Stand der Datenwissenschaft und -technik zu bleiben.
Mit maßgeschneiderten Kursen wie "Einführung in PySpark" und "Big Data mit PySpark" können deine Teammitglieder vom Anfänger zum Experten werden und lernen, wie man Big Data mit PySpark bearbeitet, verarbeitet und analysiert. Die interaktiven Lernpfade und realen Projekte der Plattform sorgen dafür, dass dein Team nicht nur die Theorie lernt, sondern auch praktische Erfahrungen sammelt, die es sofort bei seiner Arbeit anwenden kann.
Wenn du das DataCamp in die Lernstrategie deines Teams einbeziehst, ist dein Unternehmen immer mit den neuesten Fähigkeiten ausgestattet, die es braucht, um die komplexen Herausforderungen von Big Data zu meistern. Egal, ob es um den Aufbau von Pipelines für maschinelles Lernen oder die Durchführung umfangreicher Datenanalysen geht, dein Team wird auf alles vorbereitet sein. Fordere noch heute eine Demo an, um mehr zu erfahren.
Kurse für Datenvisualisierung
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Matt Crabtree
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal
Tutorial
Aditya Sharma