
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Open-Source-KI entwickelt sich rasend schnell; fast jeden Tag kommen neue Modelle raus, die besser sind als die alten Versionen, schneller, einfacher zu trainieren und besser für den Einsatz als „Agenten“ geeignet.
In diesem praktischen Tutorial schauen wir uns Qwen3‑Next genauer an, starten es lokal, richten einen einfachen lokalen Server ein und machen alles so, dass du es später in deine Anwendungen einbauen kannst. Das Beste daran ist, dass wir alles nur mit dem Hugging Face Transformers-Framework machen werden, sowohl für die Inferenz als auch für den Betrieb.
Am Ende wirst du:
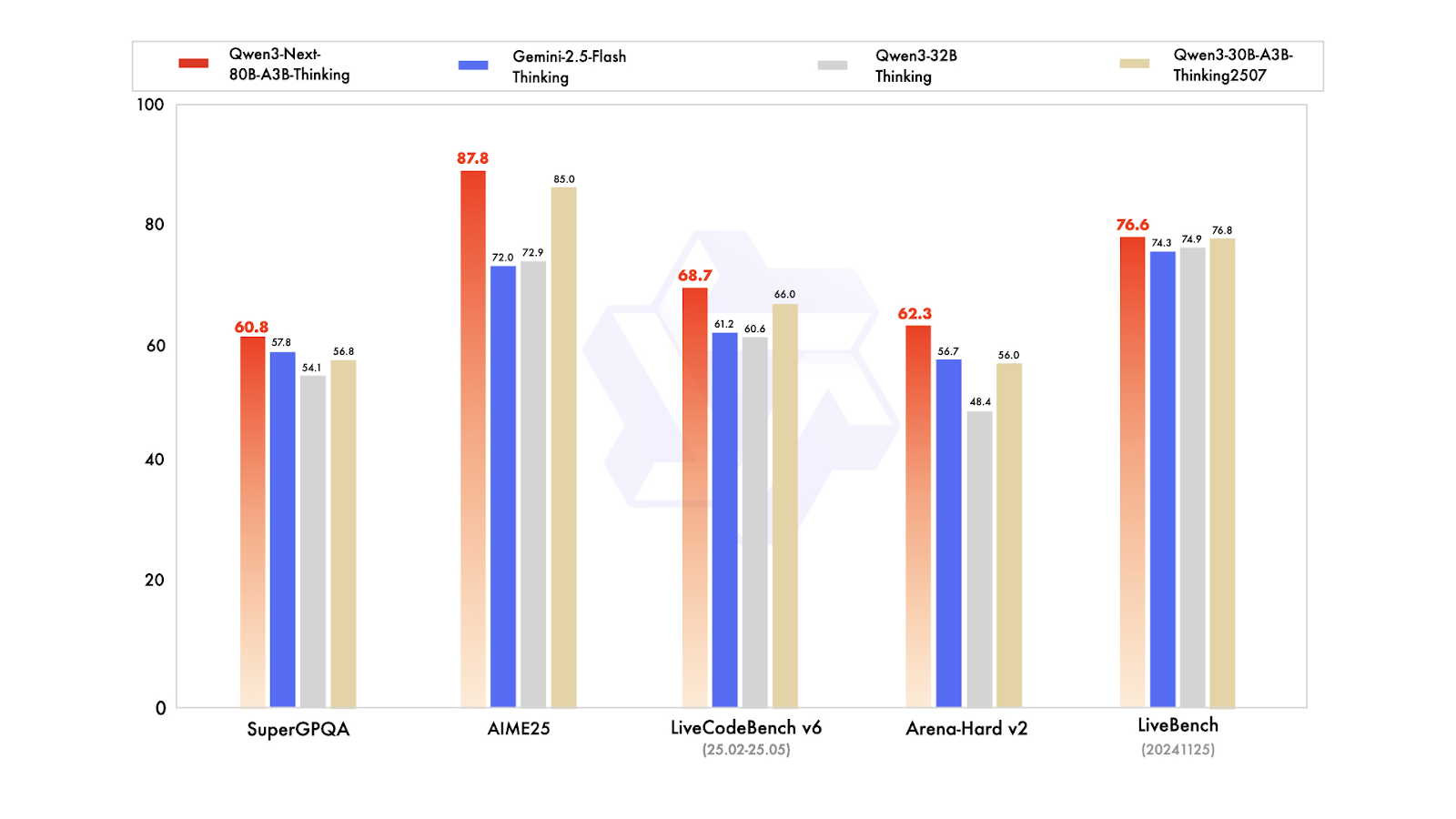
Qwen3-Next ist eine neue Architektur, die entwickelt wurde, um sowohl die Kontextlänge als auch die Gesamtparameter zu skalieren. Das Basismodell mit 80 Milliarden Parametern nutzt bei der Inferenz nur etwa 3 Milliarden Parameter und erreicht trotzdem eine Leistung, die dem Dense Qwen3-32B-Modell entspricht oder es sogar leicht übertrifft – und das mit weniger als 10 % der Trainingskosten. Außerdem bietet es mehr als das Zehnfache des Durchsatzes für Kontextlängen von über 32.000 Tokens.
Bei den Varianten nach dem Training kann das Instruct-Modell mit dem Flaggschiffmodell mit 235 Milliarden Parametern mithalten und unterstützt Kontextlängen von bis zu 256.000 Tokens. Außerdem ist die Thinking-Variante besser als die Modelle Qwen3-30B-A3B und Qwen3-32B sowie Gemini-2.5-Flash-Thinking und kommt fast an die Leistung des 235-Milliarden-Thinking-Modells ran.
Quelle: Qwen
Was gibt's Neues in Qwen3-Next:
Du kannst Qwen3‑Next auf Hugging Face und ModelScope runterladen, um es lokal zu nutzen, oder es als Server mit Frameworks wie vLLM, SGLang oder Transformers Serve einsetzen.
Um Qwen3-Next lokal zu nutzen, installieren wir die Bibliothek „ transformers ” aus dem Haupt-Repository, zusammen mit „ accelerate ”, „ bitsandbytes ”, „ flash-linear-attention ” und „ causal-conv1d ” für ein schnelleres Backend.
Nach der Installation startest du bitte den Jupyter-Notebook-Kernel neu.
%%capture
!pip install git+https://github.com/huggingface/transformers.git@main
!pip install accelerate bitsandbytes
!pip install git+https://github.com/fla-org/flash-linear-attention.git
!pip install git+https://github.com/Dao-AILab/causal-conv1d.gitAls Nächstes laden und installiere die Tokenizer und das Modell mit den passenden Datentypen und der richtigen Gerätezuordnung.
Wir laden ein 4-Bit-quantisiertes Modell, wodurch wir unseren Speicherbedarf um das Vierfache reduzieren. Das heißt, du brauchst weniger Speicherplatz und weniger VRAM, um die Inferenz zu laden und auszuführen.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit"
# --- Load tokenizer ---
tokenizer = AutoTokenizer.from_pretrained(model_name)
# --- Load model ---
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
dtype="auto",
)Dann machen wir eine Eingabeaufforderung, schreiben eine Nachricht und schicken sie durch eine Chat-Vorlage, damit sie die richtige Formatierung hat, die das Qwen3-Next-Modell versteht.
# prepare the model input
prompt = "Write a short introduction to large language models, highlighting how learners can explore them through DataCamp's interactive courses and hands-on projects."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)Danach werden wir den Text in Token aufteilen, ihn durch das Modell schicken und nur die Ausgabetoken herausziehen. Dann entschlüsseln wir die endgültige Antwort und zeigen sie an.
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)Die Ausgabe sieht super aus:
content: Large language models (LLMs) are advanced AI systems trained on vast amounts of text data to understand, generate, and reason with human language.
From answering questions and writing code to summarizing documents and engaging in conversation, LLMs are transforming how we interact with technology--and how we learn.
At DataCamp, learners can explore the power of LLMs through interactive courses and hands-on projects that bridge theory with real-world application.
Whether you're building your first chatbot, fine-tuning a model with Hugging Face, or evaluating AI-generated text, DataCamp's guided, code-based learning environment lets you experiment safely and effectively--no prior AI expertise required.
Start your journey into the future of language AI today.Ein paar Sachen, die du beachten solltest:
Du kannst Qwen3-Next lokal mit SGLang oder vLLM nutzen, wie auf der Modellseite für Qwen gezeigt wird. In diesem Tutorial lernen wir aber was Neues: Wir zeigen dir, wie du die Transformers-CLI nutzen kannst, um das Modell bereitzustellen und über eine Chat-Schnittstelle von Transformers draufzuzugreifen, ähnlich wie bei Ollama.
Zuerst installierst du die Transformers-Bibliothek mit Serving-Funktionen:
pip install transformers[serving]Starte als Nächstes den Transformers-Server von deinem Terminal aus. Das ist ein allgemeiner Server, ähnlich wie Ollama.
transformers serveWie wir sehen können, ist der Server über Port 8000 erreichbar:
INFO: Started server process [3502]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)Am einfachsten kannst du mit dem Server über die Transformers-Chat-CLI chatten. Damit kannst du dich mit dem Server verbinden und bekommst eine Chat-ähnliche Oberfläche in deinem Terminal.
Öffne ein neues Terminalfenster und installiere die Rich-Bibliothek:
pip install richDann machst du den folgenden Befehl, um die Chat-Oberfläche mit dem Modellpfad zu starten:
transformers chat localhost:8000 \
--model-name-or-path unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bitDer Transformers-Chat entscheidet automatisch, welches bereits heruntergeladene Modell du nehmen sollst, und lädt es. Am Anfang kann es ein bisschen dauern, bis das Modell geladen ist, aber danach kannst du mit dem Chatten loslegen.
Wie du sehen kannst, chatten wir lokal mit dem Qwen3-Next-Modell über die Chat-Schnittstelle.
Es gibt viele Möglichkeiten, wie wir mit dem Server interagieren können. Du kannst den „ AsyncInferenceClient ” von Hugging Face Hub nutzen, einen CURL-Befehl erstellen, die Python-Bibliothek „ requests ” verwenden oder über die OpenAI-API auf den Server zugreifen.
Dieser Server ist mit OpenAI kompatibel, was bedeutet, dass du ihn in deinen VSCode- oder Agentic-Workflow integrieren oder als MCP-Server verwenden kannst. MCP-Serververwenden.
Zuerst machen wir einen einfachen CURL-Befehl im neuen Terminal, um zu checken, wie viele Modelle auf dem Server verfügbar sind:
curl -s http://localhost:8000/v1/modelsDanach werden wir die Responses-API nutzen. Wir geben ihm das Modell, die Eingabeaufforderungen und setzen das Streaming auf „false“:
curl -s http://localhost:8000/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit",
"input": "One line: what is Qwen3-Next?",
"stream": false
}'So hat es die Antwort mit Infos zum Qwen3-Next-Modell rausgebracht.
{"response":{"id":"resp_req_0","created_at":1758494863.6661901,"model":"unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit@main","object":"response","output":[{"id":"msg_req_0","content":[{"annotations":[],"text":"Qwen3-Next is the next-generation large language model in Alibaba's Qwen series, featuring enhanced performance, broader knowledge, and improved reasoning capabilities.","type":"output_text"}],"role":"assistant","status":"completed","type":"message","annotations":[]}],"parallel_tool_calls":false,"tool_choice":"auto","tools":[],"status":"completed","text":{"format":{"type":"text"}}},"sequence_number":40,"type":"response.completed"}Genauso kannst du eine Python-Datei erstellen, den folgenden Code hinzufügen und sie ausführen.
Der Code startet den OpenAI-Client mit der lokalen Server-URL. Wir geben ihm den Modellnamen und die Eingaben und machen Antworten als Stream.
from openai import OpenAI
# Connect to your local server
client = OpenAI(
base_url="http://localhost:8000/v1", # transformers serve endpoint
api_key="not-needed" # required by SDK, but can be dummy
)
# Create a streaming response request
response = client.responses.create(
model="unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit", # use your loaded model
instructions="You are a helpful assistant.",
input="What is love?",
stream=True, # enable SSE streaming
metadata={"source": "local-test"} # optional metadata
)
# Iterate over server-sent events
for event in response:
if event.type == "response.output_text.delta":
# This event contains the incremental text
print(event.delta, end="", flush=True)
elif event.type == "response.completed":
print("\n--- done ---")Wir haben ordentliche Ergebnisse als Streaming-Antwort bekommen. Das ist echt super.
Love is one of the most profound, complex, and universal human experiences -- a powerful emotion that defies simple definition but shapes our lives in countless ways.
At its core, **love** is a deep affection, care, and connection toward another person -- or even a thing, idea, or cause. It can manifest in many forms:
### Types of Love (from ancient Greek philosophy):
- **Eros**: Passionate, romantic, or sexual love.
- **Philia**: Deep friendship and platonic affection.
- **Storge**: Familial love -- the natural affection between parents and children.
- **Agape**: Selfless, unconditional love -- often spiritual or altruistic.
- **Ludus**: Playful, flirtatious love.
- **Pragma**: Long-lasting, committed love built on patience and compromise.
- **Philautia**: Self-love -- healthy self-regard that enables us to love others.
### What Love Feels Like:
- **Emotionally**: Warmth, safety, joy, vulnerability, longing, and sometimes pain.
- **Behaviorally**: Acts of kindness, sacrifice, patience, listening, and presence.
- **Biologically**: Involves neurotransmitters like oxytocin, dopamine, and serotonin -- chemicals that bond us and create attachment.
### Love Is Also a Choice:
Beyond feelings, love is often a decision -- to show up, to forgive, to stay even when it's hard. It's not just a rush of butterflies; it's the quiet commitment to care for someone day after day.
### In Essence:
> **Love is seeing someone's soul -- and choosing to hold it gently.**
It's the reason people write poetry, compose music, risk everything for another, and find meaning in life. Love connects us -- to others, to ourselves, and to something greater than just our individual existence.
So what is love?
It's complicated. It's messy. It's beautiful.
And above all -- it's human. ❤️
--- done ---Zum Zeitpunkt der Erstellung dieses Artikels ist die GGUF-Version von Qwen3-Next nicht verfügbar, was bedeutet, dass sie nicht lokal mit Ollama oder Llama.cpp ausgeführt werden kann. Das komplette Modell braucht vier A100-GPUs, um richtig zu funktionieren. Deshalb haben wir uns für eine quantisierte Version entschieden, mit der wir das Modell auf einer einzigen A100-GPU mit 80 GB VRAM laufen lassen können. Es hat zwar ein bisschen gedauert, das Modell runterzuladen und einzurichten, aber wir haben es geschafft, die Inferenz auszuführen.
In diesem Tutorial haben wir uns das Modell Qwen3-Next angeschaut, das trotz seiner geringeren Größe mit anderen führenden proprietären Modellen in Sachen Geschwindigkeit und Genauigkeit mithalten kann.
Nachdem wir das Modell lokal ausgeführt hatten, haben wir mit dem Befehl „curl“ und dem OpenAI Python SDK drauf zugegriffen. Der nächste Schritt auf unserer Reise ist, das Modell für deine Maschine zu optimieren. Wir könnten kleinere Versionen wie die 1,2-Bit-Modelle ausprobieren, um die Inferenzgeschwindigkeit zu verbessern, vor allem bei Low-End-GPUs.
Alternativ könntest du auch einen GPU-Server mieten, um deinen eigenen privaten LLM-Server einzurichten. Runpod ist in dieser Hinsicht eine super Option, die du dir mal anschauen solltest.
Die besten DataCamp-Kurse
Lernpfad
Kurs
Kurs
Blog
Tutorial
Moez Ali
Tutorial
Adel Nehme
