
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
A IA de código aberto está avançando a uma velocidade impressionante; novos modelos surgem quase diariamente, superando as versões anteriores e se tornando mais rápidos, fáceis de treinar e mais “prontos para agentes”.
Neste tutorial prático, vamos mergulhar no Qwen3‑Next, rodá-lo localmente, lançar um servidor local simples e configurar tudo para que você possa integrá-lo às suas aplicações mais tarde. E o melhor de tudo é que vamos fazer tudo usando só a estrutura Hugging Face Transformers, tanto para inferência quanto para serviço.
No final, você vai:
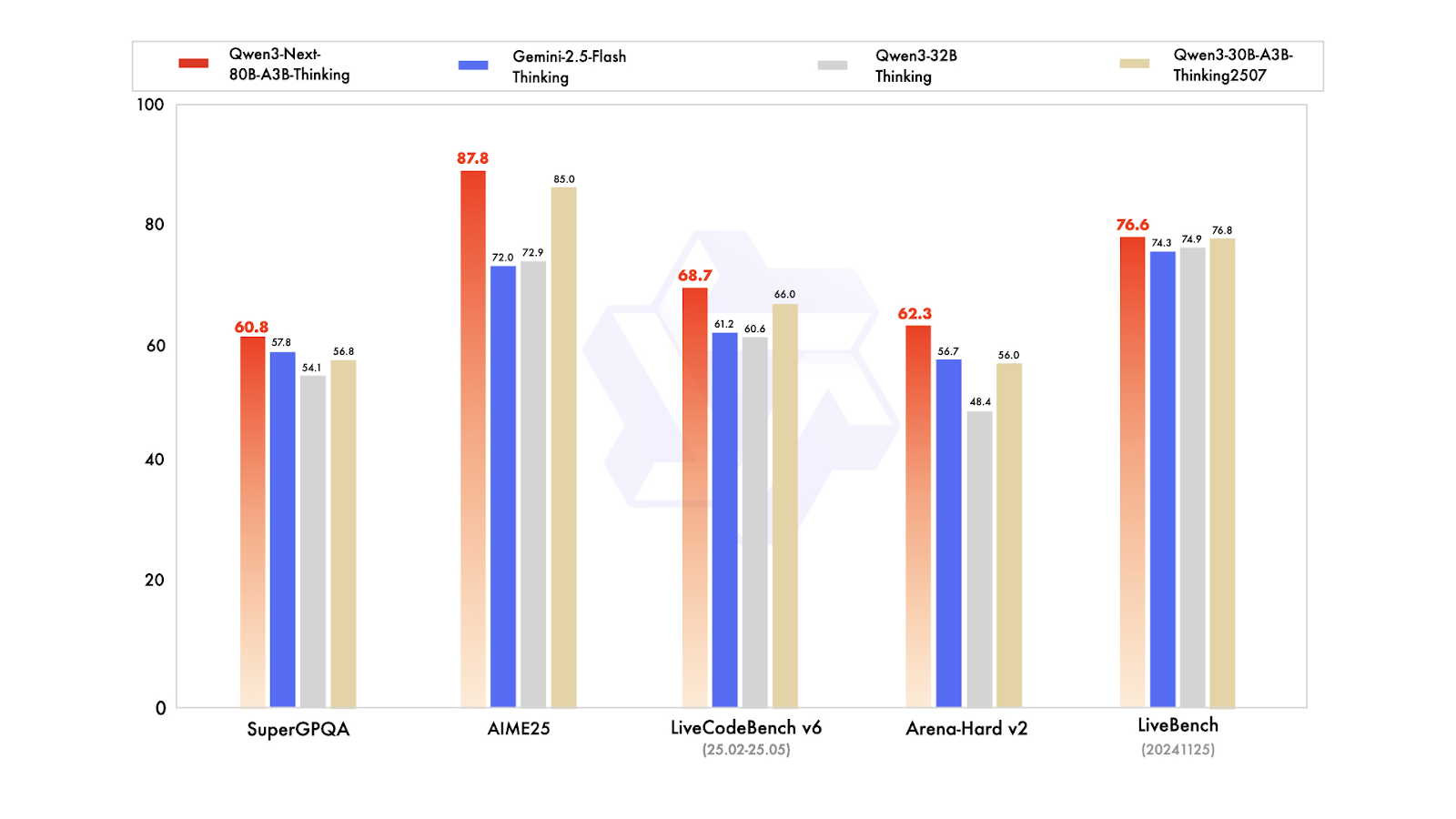
Qwen3-Next é uma nova arquitetura projetada para escalar tanto o comprimento do contexto quanto o total de parâmetros. O modelo básico de 80 bilhões de parâmetros só usa cerca de 3 bilhões de parâmetros durante a inferência, mas consegue um desempenho que iguala ou até passa um pouco do modelo Dense Qwen3-32B, tudo isso com menos de 10% do custo de treinamento. Ele também oferece mais de 10 vezes a taxa de transferência para comprimentos de contexto que ultrapassam 32.000 tokens.
Em termos de variantes pós-treinamento, o modelo Instruct compete com o modelo principal de 235 bilhões de parâmetros e suporta comprimentos de contexto de até 256.000 tokens. Além disso, a variante Thinking supera os modelos Qwen3-30B-A3B e Qwen3-32B, bem como o Gemini-2.5-Flash-Thinking, aproximando-se do desempenho do modelo Thinking de 235 bilhões.
Fonte: Qwen
O que há de novo no Qwen3-Next:
Você pode pegar o Qwen3-Next no Hugging Face e no ModelScope pra baixar e usar localmente, ou usar como servidor com frameworks como vLLM, SGLang ou Transformers Serve.
Para rodar o Qwen3-Next localmente, vamos instalar a biblioteca transformers do repositório principal, junto com accelerate, bitsandbytes, flash-linear-attention e causal-conv1d para um backend mais rápido.
Depois de instalar, reinicie o kernel do Jupyter notebook.
%%capture
!pip install git+https://github.com/huggingface/transformers.git@main
!pip install accelerate bitsandbytes
!pip install git+https://github.com/fla-org/flash-linear-attention.git
!pip install git+https://github.com/Dao-AILab/causal-conv1d.gitDepois, baixa e carrega os tokenizadores e o modelo usando os tipos de dados e o mapa de dispositivos certos.
Vamos carregar um modelo quantizado de 4 bits, o que reduz nosso consumo de memória em quatro vezes. Isso quer dizer que você vai precisar de menos espaço de armazenamento e menos VRAM para carregar e executar a inferência.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit"
# --- Load tokenizer ---
tokenizer = AutoTokenizer.from_pretrained(model_name)
# --- Load model ---
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
dtype="auto",
)Depois, vamos criar um prompt, escrever uma mensagem e passar por um modelo de chat pra garantir que ela tenha a formatação necessária reconhecida pelo modelo Qwen3-Next.
# prepare the model input
prompt = "Write a short introduction to large language models, highlighting how learners can explore them through DataCamp's interactive courses and hands-on projects."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)Depois disso, vamos tokenizar o texto, passar pelo modelo e extrair só os tokens de saída. Depois, vamos decodificar e mostrar a resposta final.
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)A saída parece perfeita:
content: Large language models (LLMs) are advanced AI systems trained on vast amounts of text data to understand, generate, and reason with human language.
From answering questions and writing code to summarizing documents and engaging in conversation, LLMs are transforming how we interact with technology--and how we learn.
At DataCamp, learners can explore the power of LLMs through interactive courses and hands-on projects that bridge theory with real-world application.
Whether you're building your first chatbot, fine-tuning a model with Hugging Face, or evaluating AI-generated text, DataCamp's guided, code-based learning environment lets you experiment safely and effectively--no prior AI expertise required.
Start your journey into the future of language AI today.Algumas coisas para ter em mente:
Você pode usar o Qwen3-Next localmente usando SGLang ou vLLM, como mostrado na página do modelo do Qwen. Mas, nesse tutorial, vamos aprender uma coisa nova: usar a CLI do Transformers para servir o modelo e acessá-lo por meio de uma interface de chat fornecida pelo Transformers, parecida com o Ollama.
Primeiro, instale a biblioteca Transformers com recursos de serviço:
pip install transformers[serving]Depois, dá um start no servidor Transformers pelo seu terminal. Esse é um servidor geral, parecido com o Ollama.
transformers serveComo dá pra ver, o servidor vai estar acessível na porta 8000:
INFO: Started server process [3502]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)A maneira mais fácil de interagir com o servidor é usando a CLI do chat do Transformers. Isso permite que você se conecte ao servidor e oferece uma interface tipo chat dentro do seu terminal.
Abra uma nova janela do terminal e instale a biblioteca Rich:
pip install richDepois, execute o seguinte comando para iniciar a interface de chat com o caminho do modelo:
transformers chat localhost:8000 \
--model-name-or-path unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bitO chat do Transformers vai escolher automaticamente qual modelo já baixado usar e carregá-lo. No começo, pode demorar um pouco para carregar o modelo, mas depois disso, você pode começar a conversar.
Como você pode ver, estamos interagindo com o modelo Qwen3-Next localmente usando a interface de chat.
Tem várias maneiras de interagir com o servidor. Você pode usar o AsyncInferenceClient do Hugging Face Hub, criar um comando CURL, usar a biblioteca requests do Python ou acessar o servidor pela API OpenAI.
Esse servidor é compatível com OpenAI, o que significa que você pode integrá-lo ao seu VSCode, fluxo de trabalho Agentic ou usá-lo como um servidor MCP. servidor MCP.
Primeiro, vamos rodar um comando CURL simples no novo terminal pra ver quantos modelos estão disponíveis no servidor:
curl -s http://localhost:8000/v1/modelsDepois disso, vamos usar a API de respostas. Vamos fornecer o modelo, as instruções e definir o streaming como falso:
curl -s http://localhost:8000/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit",
"input": "One line: what is Qwen3-Next?",
"stream": false
}'Como resultado, gerou a resposta com informações sobre o modelo Qwen3-Next.
{"response":{"id":"resp_req_0","created_at":1758494863.6661901,"model":"unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit@main","object":"response","output":[{"id":"msg_req_0","content":[{"annotations":[],"text":"Qwen3-Next is the next-generation large language model in Alibaba's Qwen series, featuring enhanced performance, broader knowledge, and improved reasoning capabilities.","type":"output_text"}],"role":"assistant","status":"completed","type":"message","annotations":[]}],"parallel_tool_calls":false,"tool_choice":"auto","tools":[],"status":"completed","text":{"format":{"type":"text"}}},"sequence_number":40,"type":"response.completed"}Da mesma forma, você pode criar um arquivo Python, adicionar o código a seguir e executá-lo.
O código vai inicializar o cliente OpenAI com a URL do servidor local. Nós fornecemos o nome do modelo, as entradas e geramos respostas como um fluxo.
from openai import OpenAI
# Connect to your local server
client = OpenAI(
base_url="http://localhost:8000/v1", # transformers serve endpoint
api_key="not-needed" # required by SDK, but can be dummy
)
# Create a streaming response request
response = client.responses.create(
model="unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit", # use your loaded model
instructions="You are a helpful assistant.",
input="What is love?",
stream=True, # enable SSE streaming
metadata={"source": "local-test"} # optional metadata
)
# Iterate over server-sent events
for event in response:
if event.type == "response.output_text.delta":
# This event contains the incremental text
print(event.delta, end="", flush=True)
elif event.type == "response.completed":
print("\n--- done ---")Recebemos os resultados certos como resposta de streaming. Isso é demais.
Love is one of the most profound, complex, and universal human experiences -- a powerful emotion that defies simple definition but shapes our lives in countless ways.
At its core, **love** is a deep affection, care, and connection toward another person -- or even a thing, idea, or cause. It can manifest in many forms:
### Types of Love (from ancient Greek philosophy):
- **Eros**: Passionate, romantic, or sexual love.
- **Philia**: Deep friendship and platonic affection.
- **Storge**: Familial love -- the natural affection between parents and children.
- **Agape**: Selfless, unconditional love -- often spiritual or altruistic.
- **Ludus**: Playful, flirtatious love.
- **Pragma**: Long-lasting, committed love built on patience and compromise.
- **Philautia**: Self-love -- healthy self-regard that enables us to love others.
### What Love Feels Like:
- **Emotionally**: Warmth, safety, joy, vulnerability, longing, and sometimes pain.
- **Behaviorally**: Acts of kindness, sacrifice, patience, listening, and presence.
- **Biologically**: Involves neurotransmitters like oxytocin, dopamine, and serotonin -- chemicals that bond us and create attachment.
### Love Is Also a Choice:
Beyond feelings, love is often a decision -- to show up, to forgive, to stay even when it's hard. It's not just a rush of butterflies; it's the quiet commitment to care for someone day after day.
### In Essence:
> **Love is seeing someone's soul -- and choosing to hold it gently.**
It's the reason people write poetry, compose music, risk everything for another, and find meaning in life. Love connects us -- to others, to ourselves, and to something greater than just our individual existence.
So what is love?
It's complicated. It's messy. It's beautiful.
And above all -- it's human. ❤️
--- done ---No momento em que escrevo, a versão GGUF do Qwen3-Next não está disponível, o que significa que não pode ser executada localmente usando Ollama ou Llama.cpp. O modelo completo precisa de quatro GPUs A100 pra funcionar bem, então a gente escolheu uma versão quantizada que dá pra rodar o modelo numa única GPU A100 com 80 GB de VRAM. Embora tenha demorado um pouco para baixar e configurar o modelo, conseguimos aprender como fazer a inferência.
Neste tutorial, a gente explorou o modelo Qwen3-Next, que compete com outros modelos proprietários líderes em termos de velocidade e precisão, apesar de ser menor.
Depois de rodar o modelo localmente, a gente acessou ele usando o comando curl e o OpenAI Python SDK. O próximo passo na nossa jornada é otimizar o modelo para a sua máquina específica. Podemos explorar versões menores, como os modelos de 1,2 bits, para melhorar a velocidade de inferência, especialmente em GPUs de gama baixa.
Como alternativa, você pode pensar em alugar um servidor GPU para montar seu próprio servidor LLM privado. O Runpod é uma ótima opção para explorar nesse sentido.
Cursos mais populares do DataCamp
Programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Arjun Sarkar
Tutorial
Tutorial
Moez Ali
Tutorial
Ryan Ong



