
programa
Desarrollar grandes modelos lingüísticos
16 h
La IA de código abierto avanza a una velocidad vertiginosa; casi a diario aparecen nuevos modelos que superan a las versiones anteriores, son más rápidos, más fáciles de entrenar y están más preparados para actuar como agentes.
En este tutorial práctico, nos sumergiremos en Qwen3‑Next, lo ejecutaremos localmente, iniciaremos un servidor local sencillo y lo configuraremos para que puedas integrarlo en tus aplicaciones más adelante. Lo mejor de todo es que haremos todo utilizando únicamente el marco Hugging Face Transformers, tanto para la inferencia como para el servicio.
Al finalizar, tú:
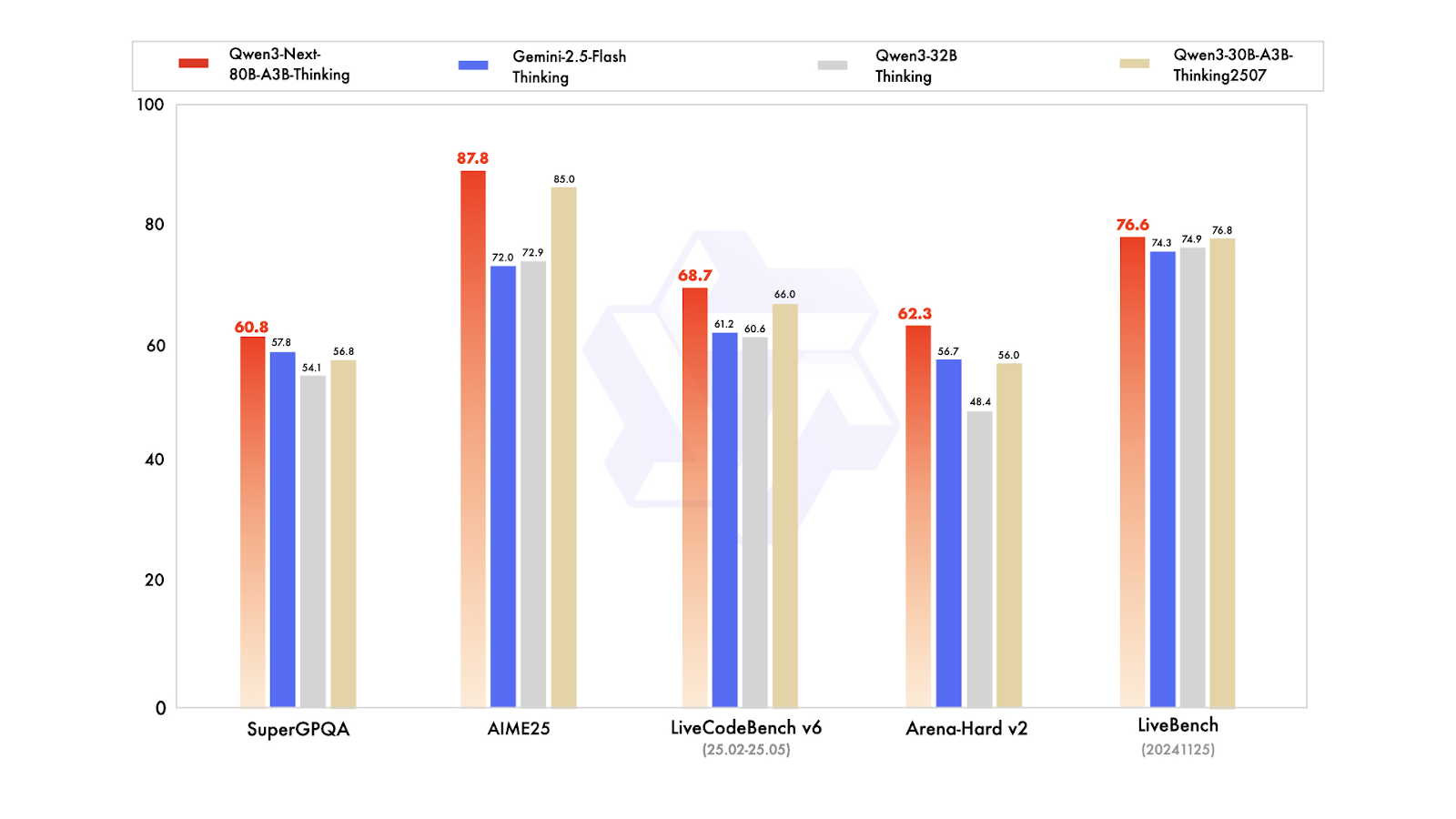
Qwen3-Next es una nueva arquitectura diseñada para escalar tanto la longitud del contexto como el total de parámetros. El modelo base de 80 000 millones de parámetros activa solo unos 3000 millones de parámetros durante la inferencia, al tiempo que alcanza un rendimiento que iguala o supera ligeramente al del modelo Dense Qwen3-32B, todo ello con menos del 10 % del coste de entrenamiento. También proporciona más de 10 veces el rendimiento para longitudes de contexto que superan los 32 000 tokens.
En cuanto a las variantes posteriores al entrenamiento, el modelo Instruct compite con el modelo insignia de 235 000 millones de parámetros y admite longitudes de contexto de hasta 256 000 tokens. Además, la variante Thinking supera a los modelos Qwen3-30B-A3B y Qwen3-32B, así como a Gemini-2.5-Flash-Thinking, acercándose al rendimiento del modelo Thinking de 235 000 millones.
Fuente: Qwen
Novedades de Qwen3-Next:
Puedes obtener Qwen3-Next en Hugging Face y ModelScope para descargarlo y utilizarlo localmente, o implementarlo como servidor con marcos como vLLM, SGLang o Transformers Serve.
Para ejecutar Qwen3-Next localmente, instalaremos la biblioteca transformers desde el repositorio principal, junto con accelerate, bitsandbytes, flash-linear-attention y causal-conv1d para un backend más rápido.
Después de la instalación, reinicia el kernel del cuaderno Jupyter.
%%capture
!pip install git+https://github.com/huggingface/transformers.git@main
!pip install accelerate bitsandbytes
!pip install git+https://github.com/fla-org/flash-linear-attention.git
!pip install git+https://github.com/Dao-AILab/causal-conv1d.gitA continuación, descarga y carga los tokenizadores y el modelo utilizando los tipos de datos y el mapa de dispositivos adecuados.
Cargaremos un modelo cuantificado de 4 bits, lo que reducirá vuestra huella de memoria en cuatro veces. Esto significa que necesitarás menos espacio de almacenamiento y menos VRAM para cargar y ejecutar la inferencia.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit"
# --- Load tokenizer ---
tokenizer = AutoTokenizer.from_pretrained(model_name)
# --- Load model ---
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
dtype="auto",
)A continuación, crearemos una indicación, redactaremos un mensaje y lo pasaremos por una plantilla de chat para asegurarnos de que tiene el formato necesario reconocido por el modelo Qwen3-Next.
# prepare the model input
prompt = "Write a short introduction to large language models, highlighting how learners can explore them through DataCamp's interactive courses and hands-on projects."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)A continuación, tokenizaremos el texto, lo pasaremos por el modelo y extraeremos solo los tokens de salida. A continuación, decodificaremos y mostraremos la respuesta final.
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)El resultado parece perfecto:
content: Large language models (LLMs) are advanced AI systems trained on vast amounts of text data to understand, generate, and reason with human language.
From answering questions and writing code to summarizing documents and engaging in conversation, LLMs are transforming how we interact with technology--and how we learn.
At DataCamp, learners can explore the power of LLMs through interactive courses and hands-on projects that bridge theory with real-world application.
Whether you're building your first chatbot, fine-tuning a model with Hugging Face, or evaluating AI-generated text, DataCamp's guided, code-based learning environment lets you experiment safely and effectively--no prior AI expertise required.
Start your journey into the future of language AI today.Algunas cosas que debes tener en cuenta:
Puedes utilizar Qwen3-Next de forma local con SGLang o vLLM, tal y como se muestra en la página del modelo de Qwen. Sin embargo, en este tutorial aprenderemos algo nuevo: utilizar la CLI de Transformers para servir el modelo y acceder a él a través de una interfaz de chat proporcionada por Transformers, similar a Ollama.
En primer lugar, instala la biblioteca Transformers con capacidades de servicio:
pip install transformers[serving]A continuación, inicia el servidor Transformers desde tu terminal. Este es un servidor general, similar a Ollama.
transformers serveComo podemos ver, se podrá acceder al servidor en el puerto 8000:
INFO: Started server process [3502]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)La forma más fácil de interactuar con el servidor es utilizando la CLI del chat de Transformers. Esto te permite conectarte al servidor y te proporciona una interfaz similar a un chat dentro de tu terminal.
Abre una nueva ventana de terminal e instala la biblioteca Rich:
pip install richA continuación, ejecuta el siguiente comando para iniciar la interfaz de chat con la ruta del modelo:
transformers chat localhost:8000 \
--model-name-or-path unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bitEl chat de Transformers decidirá automáticamente qué modelo ya descargado elegir y lo cargará. Al principio, puede que el modelo tarde un poco en cargarse, pero después podrás empezar a chatear.
Como puedes ver, estamos interactuando con el modelo Qwen3-Next de forma local utilizando la interfaz de chat.
Hay muchas formas de interactuar con el servidor. Puedes utilizar el AsyncInferenceClient de Hugging Face Hub, crear un comando CURL, utilizar la biblioteca requests de Python o acceder al servidor a través de la API de OpenAI.
Este servidor es compatible con OpenAI, lo que significa que puedes integrarlo en tu VSCode, flujo de trabajo Agentic o utilizarlo como un servidor MCP.
En primer lugar, ejecutaremos un sencillo comando CURL en la nueva terminal para comprobar cuántos modelos hay disponibles en el servidor:
curl -s http://localhost:8000/v1/modelsDespués, utilizaremos la API de respuestas. Te proporcionaremos el modelo, las indicaciones y configuraremos la transmisión en falso:
curl -s http://localhost:8000/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit",
"input": "One line: what is Qwen3-Next?",
"stream": false
}'Como resultado, ha generado la respuesta que contiene información sobre el modelo Qwen3-Next.
{"response":{"id":"resp_req_0","created_at":1758494863.6661901,"model":"unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit@main","object":"response","output":[{"id":"msg_req_0","content":[{"annotations":[],"text":"Qwen3-Next is the next-generation large language model in Alibaba's Qwen series, featuring enhanced performance, broader knowledge, and improved reasoning capabilities.","type":"output_text"}],"role":"assistant","status":"completed","type":"message","annotations":[]}],"parallel_tool_calls":false,"tool_choice":"auto","tools":[],"status":"completed","text":{"format":{"type":"text"}}},"sequence_number":40,"type":"response.completed"}Del mismo modo, puedes crear un archivo Python, añadir el siguiente código y ejecutarlo.
El código inicializará el cliente OpenAI con la URL del servidor local. Te proporcionamos el nombre del modelo, las entradas y generamos respuestas como un flujo.
from openai import OpenAI
# Connect to your local server
client = OpenAI(
base_url="http://localhost:8000/v1", # transformers serve endpoint
api_key="not-needed" # required by SDK, but can be dummy
)
# Create a streaming response request
response = client.responses.create(
model="unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit", # use your loaded model
instructions="You are a helpful assistant.",
input="What is love?",
stream=True, # enable SSE streaming
metadata={"source": "local-test"} # optional metadata
)
# Iterate over server-sent events
for event in response:
if event.type == "response.output_text.delta":
# This event contains the incremental text
print(event.delta, end="", flush=True)
elif event.type == "response.completed":
print("\n--- done ---")Recibimos los resultados adecuados como respuesta de streaming. Esto es increíble.
Love is one of the most profound, complex, and universal human experiences -- a powerful emotion that defies simple definition but shapes our lives in countless ways.
At its core, **love** is a deep affection, care, and connection toward another person -- or even a thing, idea, or cause. It can manifest in many forms:
### Types of Love (from ancient Greek philosophy):
- **Eros**: Passionate, romantic, or sexual love.
- **Philia**: Deep friendship and platonic affection.
- **Storge**: Familial love -- the natural affection between parents and children.
- **Agape**: Selfless, unconditional love -- often spiritual or altruistic.
- **Ludus**: Playful, flirtatious love.
- **Pragma**: Long-lasting, committed love built on patience and compromise.
- **Philautia**: Self-love -- healthy self-regard that enables us to love others.
### What Love Feels Like:
- **Emotionally**: Warmth, safety, joy, vulnerability, longing, and sometimes pain.
- **Behaviorally**: Acts of kindness, sacrifice, patience, listening, and presence.
- **Biologically**: Involves neurotransmitters like oxytocin, dopamine, and serotonin -- chemicals that bond us and create attachment.
### Love Is Also a Choice:
Beyond feelings, love is often a decision -- to show up, to forgive, to stay even when it's hard. It's not just a rush of butterflies; it's the quiet commitment to care for someone day after day.
### In Essence:
> **Love is seeing someone's soul -- and choosing to hold it gently.**
It's the reason people write poetry, compose music, risk everything for another, and find meaning in life. Love connects us -- to others, to ourselves, and to something greater than just our individual existence.
So what is love?
It's complicated. It's messy. It's beautiful.
And above all -- it's human. ❤️
--- done ---En el momento de redactar este artículo, la versión GGUF de Qwen3-Next no está disponible, lo que significa que no se puede ejecutar localmente con Ollama o Llama.cpp. El modelo completo requiere cuatro GPU A100 para funcionar con eficacia, por lo que optamos por una versión cuantificada que nos permite ejecutar el modelo en una sola GPU A100 con 80 GB de VRAM. Aunque nos llevó algún tiempo descargar y configurar el modelo, hemos aprendido con éxito cómo ejecutar la inferencia.
En este tutorial, hemos explorado el modelo Qwen3-Next, que compite con otros modelos propietarios líderes en términos de velocidad y precisión, a pesar de ser más pequeño.
Después de ejecutar el modelo localmente, accedimos a él utilizando el comando curl y el SDK de Python de OpenAI. El siguiente paso en nuestro viaje es optimizar el modelo para tu máquina específica. Podemos explorar versiones más pequeñas, como los modelos de 1,2 bits, para mejorar la velocidad de inferencia, especialmente en GPU de gama baja.
Como alternativa, puedes considerar alquilar un servidor GPU para configurar tu propio servidor LLM privado. Runpod es una excelente opción a tener en cuenta en este sentido.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Moez Ali
Tutorial
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Arjun Sarkar



