
Cursus
Développer des LLM
16 h
L'IA open source évolue à une vitesse fulgurante ; de nouveaux modèles apparaissent presque quotidiennement, surpassant les versions précédentes tout en étant plus rapides, plus faciles à former et plus « prêts à l'emploi ».
Dans ce tutoriel pratique, nous explorerons Qwen3-Next, l'exécuterons localement, lancerons un serveur local simple et effectuerons les configurations nécessaires afin que vous puissiez l'intégrer ultérieurement à vos applications. De plus, nous réaliserons l'ensemble du processus en utilisant uniquement le framework Hugging Face Transformers, tant pour l'inférence que pour le service.
À la fin, vous serez en mesure de :
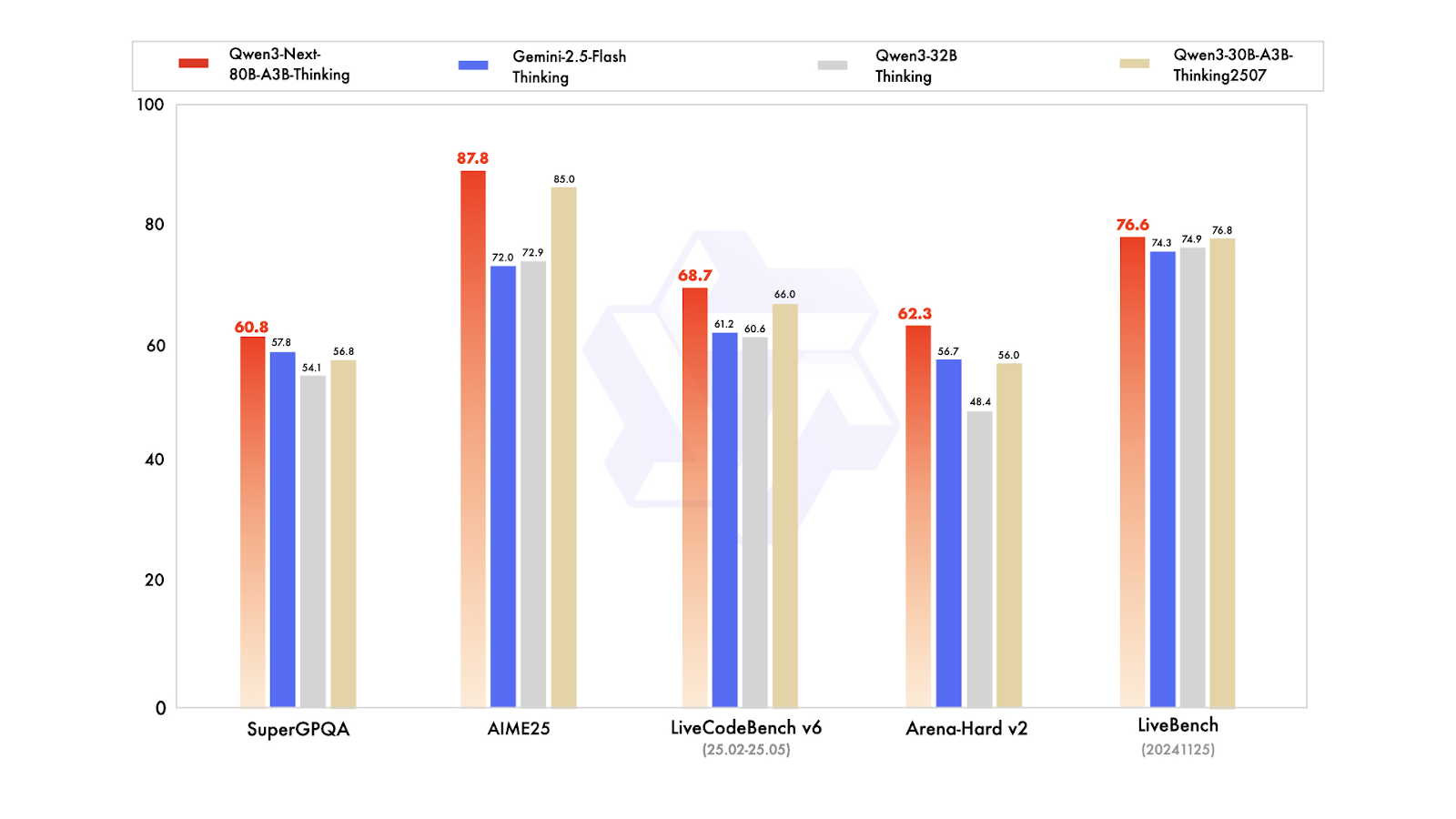
Qwen3-Next est une nouvelle architecture conçue pour adapter à la fois la longueur du contexte et le nombre total de paramètres. Le modèle de base à 80 milliards de paramètres n'active qu'environ 3 milliards de paramètres pendant l'inférence, tout en atteignant des performances équivalentes ou légèrement supérieures à celles du modèle Dense Qwen3-32B, le tout avec moins de 10 % du coût de formation. Il offre également un débit plus de 10 fois supérieur pour les longueurs de contexte supérieures à 32 000 jetons.
En termes de variantes post-formation, le modèle Instruct rivalise avec le modèle phare de 235 milliards de paramètres et prend en charge des longueurs de contexte allant jusqu'à 256 000 tokens. De plus, la variante Thinking surpasse les modèles Qwen3-30B-A3B et Qwen3-32B, ainsi que Gemini-2.5-Flash-Thinking, se rapprochant des performances du modèle Thinking de 235 milliards.
Source : Qwen
Quelles sont les nouveautés dans Qwen3-Next ?
Vous pouvez obtenir Qwen3-Next sur Hugging Face et ModelScope pour le télécharger et l'utiliser localement, ou le déployer en tant que serveur avec des frameworks tels que vLLM, SGLang ou Transformers Serve.
Pour exécuter Qwen3-Next localement, nous installerons la bibliothèque transformers à partir du référentiel principal, ainsi que accelerate, bitsandbytes, flash-linear-attention et causal-conv1d pour un backend plus rapide.
Après l'installation, veuillez redémarrer le noyau Jupyter Notebook.
%%capture
!pip install git+https://github.com/huggingface/transformers.git@main
!pip install accelerate bitsandbytes
!pip install git+https://github.com/fla-org/flash-linear-attention.git
!pip install git+https://github.com/Dao-AILab/causal-conv1d.gitEnsuite, veuillez télécharger et charger les tokeniseurs et le modèle en utilisant les types de données et la carte des appareils appropriés.
Nous allons charger un modèle quantifié sur 4 bits, ce qui réduit notre empreinte mémoire de quatre fois. Cela signifie que vous aurez besoin de moins d'espace de stockage et de moins de VRAM pour charger et exécuter l'inférence.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit"
# --- Load tokenizer ---
tokenizer = AutoTokenizer.from_pretrained(model_name)
# --- Load model ---
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
dtype="auto",
)Nous allons ensuite créer une invite, formuler un message et le faire passer par un modèle de chat afin de nous assurer qu'il présente le formatage nécessaire reconnu par le modèle Qwen3-Next.
# prepare the model input
prompt = "Write a short introduction to large language models, highlighting how learners can explore them through DataCamp's interactive courses and hands-on projects."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)Ensuite, nous procéderons à la tokenisation du texte, le transmettrons au modèle et n'extrairons que les tokens de sortie. Nous décoderons et afficherons ensuite la réponse finale.
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)Le résultat est parfait :
content: Large language models (LLMs) are advanced AI systems trained on vast amounts of text data to understand, generate, and reason with human language.
From answering questions and writing code to summarizing documents and engaging in conversation, LLMs are transforming how we interact with technology--and how we learn.
At DataCamp, learners can explore the power of LLMs through interactive courses and hands-on projects that bridge theory with real-world application.
Whether you're building your first chatbot, fine-tuning a model with Hugging Face, or evaluating AI-generated text, DataCamp's guided, code-based learning environment lets you experiment safely and effectively--no prior AI expertise required.
Start your journey into the future of language AI today.Quelques points à garder à l'esprit :
Vous pouvez utiliser Qwen3-Next localement à l'aide de SGLang ou vLLM, comme indiqué sur la page du modèle de Qwen. Cependant, dans ce tutoriel, nous allons acquérir de nouvelles connaissances : l'utilisation de l'interface CLI de Transformers pour servir le modèle et y accéder via une interface de chat fournie par Transformers, similaire à Ollama.
Tout d'abord, veuillez installer la bibliothèque Transformers avec des capacités de service :
pip install transformers[serving]Ensuite, veuillez démarrer le serveur Transformers depuis votre terminal. Il s'agit d'un serveur général, similaire à Ollama.
transformers serveComme nous pouvons le constater, le serveur sera accessible sur le port 8000 :
INFO: Started server process [3502]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)La manière la plus simple d'interagir avec le serveur est d'utiliser l'interface CLI du chat Transformers. Cela vous permet de vous connecter au serveur et fournit une interface de type chat au sein de votre terminal.
Veuillez ouvrir une nouvelle fenêtre de terminal et procéder à l'installation de la bibliothèque Rich :
pip install richVeuillez ensuite exécuter la commande suivante pour démarrer l'interface de chat avec le chemin d'accès au modèle :
transformers chat localhost:8000 \
--model-name-or-path unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bitLe chat Transformers déterminera automatiquement quel modèle déjà téléchargé choisir et le chargera. Au début, le chargement du modèle peut prendre un certain temps, mais une fois celui-ci terminé, vous pouvez commencer à discuter.
Comme vous pouvez le constater, nous interagissons avec le modèle Qwen3-Next localement à l'aide de l'interface de chat.
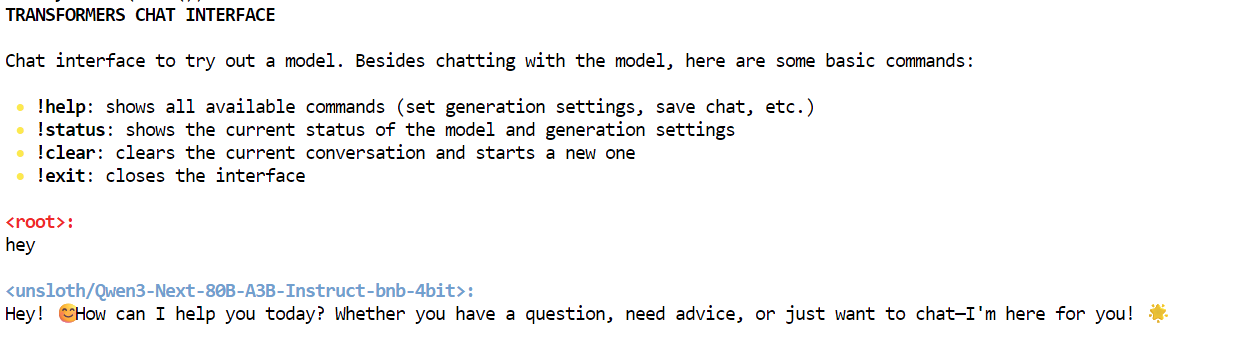
Il existe plusieurs façons d'interagir avec le serveur. Vous pouvez utiliser le AsyncInferenceClient de Hugging Face Hub, créer une commande CURL, utiliser la bibliothèque Python requests ou accéder au serveur via l'API OpenAI.
Ce serveur est compatible avec OpenAI, ce qui signifie que vous pouvez l'intégrer à votre VSCode, à votre flux de travail Agentic ou l'utiliser comme serveur MCP. serveur MCP.
Tout d'abord, nous exécuterons une commande CURL simple dans le nouveau terminal afin de vérifier combien de modèles sont disponibles sur le serveur :
curl -s http://localhost:8000/v1/modelsPar la suite, nous utiliserons l'API de réponses. Nous lui fournirons le modèle, les invites et définirons le streaming sur faux :
curl -s http://localhost:8000/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit",
"input": "One line: what is Qwen3-Next?",
"stream": false
}'En conséquence, cela a généré une réponse contenant des informations sur le modèle Qwen3-Next.
{"response":{"id":"resp_req_0","created_at":1758494863.6661901,"model":"unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit@main","object":"response","output":[{"id":"msg_req_0","content":[{"annotations":[],"text":"Qwen3-Next is the next-generation large language model in Alibaba's Qwen series, featuring enhanced performance, broader knowledge, and improved reasoning capabilities.","type":"output_text"}],"role":"assistant","status":"completed","type":"message","annotations":[]}],"parallel_tool_calls":false,"tool_choice":"auto","tools":[],"status":"completed","text":{"format":{"type":"text"}}},"sequence_number":40,"type":"response.completed"}De même, vous pouvez créer un fichier Python, ajouter le code suivant et l'exécuter.
Le code initialisera le client OpenAI avec l'URL du serveur local. Nous lui fournissons le nom du modèle, les entrées, et générons des réponses sous forme de flux.
from openai import OpenAI
# Connect to your local server
client = OpenAI(
base_url="http://localhost:8000/v1", # transformers serve endpoint
api_key="not-needed" # required by SDK, but can be dummy
)
# Create a streaming response request
response = client.responses.create(
model="unsloth/Qwen3-Next-80B-A3B-Instruct-bnb-4bit", # use your loaded model
instructions="You are a helpful assistant.",
input="What is love?",
stream=True, # enable SSE streaming
metadata={"source": "local-test"} # optional metadata
)
# Iterate over server-sent events
for event in response:
if event.type == "response.output_text.delta":
# This event contains the incremental text
print(event.delta, end="", flush=True)
elif event.type == "response.completed":
print("\n--- done ---")Nous avons reçu des résultats appropriés en tant que réponse de streaming. C'est remarquable.
Love is one of the most profound, complex, and universal human experiences -- a powerful emotion that defies simple definition but shapes our lives in countless ways.
At its core, **love** is a deep affection, care, and connection toward another person -- or even a thing, idea, or cause. It can manifest in many forms:
### Types of Love (from ancient Greek philosophy):
- **Eros**: Passionate, romantic, or sexual love.
- **Philia**: Deep friendship and platonic affection.
- **Storge**: Familial love -- the natural affection between parents and children.
- **Agape**: Selfless, unconditional love -- often spiritual or altruistic.
- **Ludus**: Playful, flirtatious love.
- **Pragma**: Long-lasting, committed love built on patience and compromise.
- **Philautia**: Self-love -- healthy self-regard that enables us to love others.
### What Love Feels Like:
- **Emotionally**: Warmth, safety, joy, vulnerability, longing, and sometimes pain.
- **Behaviorally**: Acts of kindness, sacrifice, patience, listening, and presence.
- **Biologically**: Involves neurotransmitters like oxytocin, dopamine, and serotonin -- chemicals that bond us and create attachment.
### Love Is Also a Choice:
Beyond feelings, love is often a decision -- to show up, to forgive, to stay even when it's hard. It's not just a rush of butterflies; it's the quiet commitment to care for someone day after day.
### In Essence:
> **Love is seeing someone's soul -- and choosing to hold it gently.**
It's the reason people write poetry, compose music, risk everything for another, and find meaning in life. Love connects us -- to others, to ourselves, and to something greater than just our individual existence.
So what is love?
It's complicated. It's messy. It's beautiful.
And above all -- it's human. ❤️
--- done ---Au moment de la rédaction de cet article, la version GGUF de Qwen3-Next n'est pas disponible, ce qui signifie qu'elle ne peut pas être exécutée localement à l'aide d'Ollama ou de Llama.cpp. Le modèle complet nécessite quatre GPU A100 pour fonctionner efficacement. Nous avons donc opté pour une version quantifiée qui nous permet d'exécuter le modèle sur un seul GPU A100 avec 80 Go de VRAM. Bien que le téléchargement et la configuration du modèle aient pris un certain temps, nous avons réussi à apprendre comment exécuter l'inférence.
Dans ce tutoriel, nous avons examiné le modèle Qwen3-Next, qui rivalise avec d'autres modèles propriétaires de premier plan en termes de vitesse et de précision, malgré sa taille plus réduite.
Après avoir exécuté le modèle localement, nous y avons accédé à l'aide de la commande curl et du SDK Python OpenAI. La prochaine étape de notre démarche consiste à optimiser le modèle pour votre machine spécifique. Nous pourrions envisager des versions plus compactes, telles que les modèles 1,2 bits, afin d'améliorer la vitesse d'inférence, en particulier sur les GPU d'entrée de gamme.
Vous pouvez également envisager de louer un serveur GPU pour configurer votre propre serveur LLM privé. Runpod est une excellente option à explorer à cet égard.
Meilleurs cours DataCamp
Cursus
Cours
Cours